Pour télécharger le script par ce lien
Attention ! Pour faire fonctionner le script il faut avoir d'abord télécharger les programmes detect-encoding.pl, minigrepmultilingue.pl sur icampus et stanford-segmenter.
Avant de procéder à la description étape par étape du script, il est nécessaire de préciser ici que nous avons rencontré des problèmes dus à nos différents systèmes d’exploitation. Alice utilise macOS, He est sur Windows, et Laurine sur la machine virtuelle Ubuntu. Notre script final fonctionne sur Windows et Ubuntu. Les adaptations d’Alice pour Mac sont accessibles sur notre Blog.
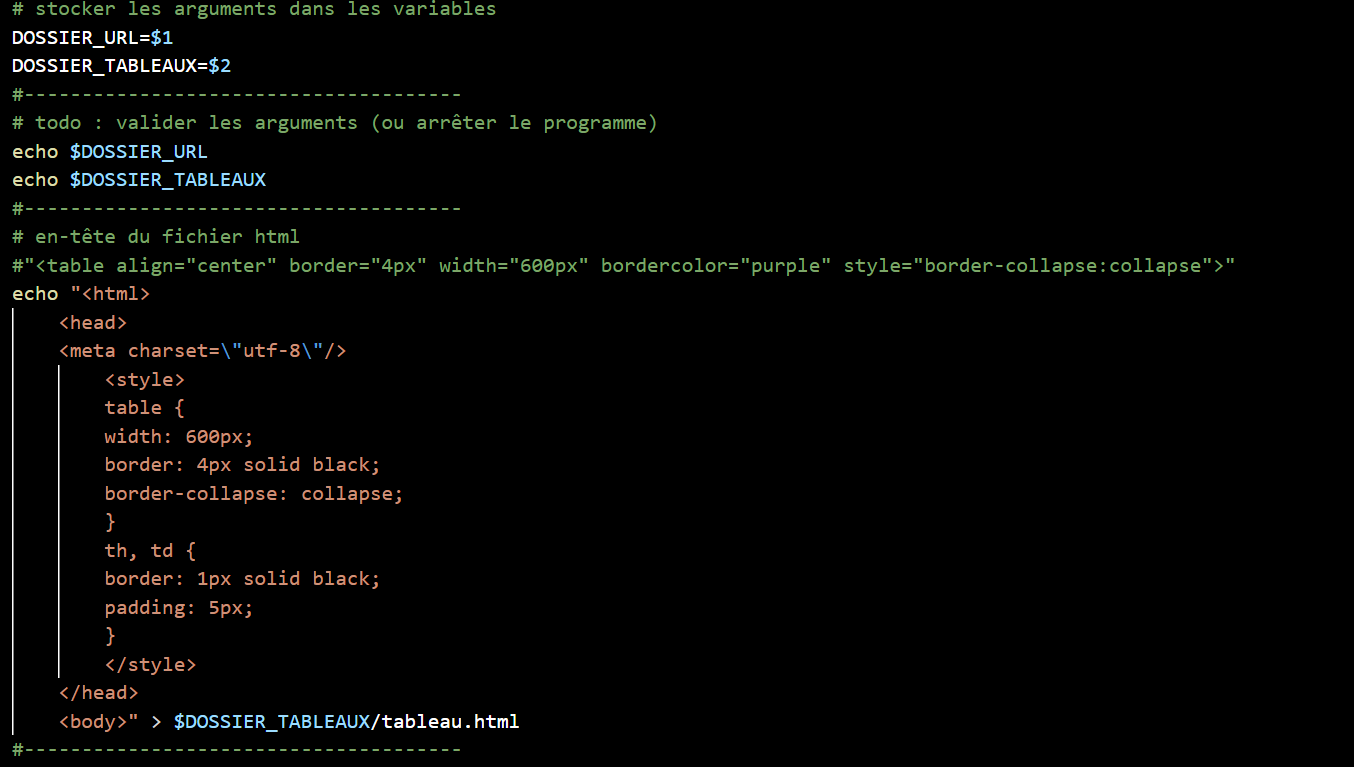
Le script que nous avons rédigé est destiné à élaborer un tableau html dans lequel plus de 50 URLS sont collectés par chacune de nous dans sa langue de travail (français, coréen et chinois). Ces urls sont issus de la recherche de pages internet contenant le mot diplôme dans chacune des langues. Nous vous présentons ci-dessous le déroulement général du script. En premier lieu, nous enregistrons tous les URLs dans un fichier au format texte, et le stockons dans une variable ($DOSSIER_URL). Nous avons ensuite commencé à créer l’en-tête de notre tableau html.
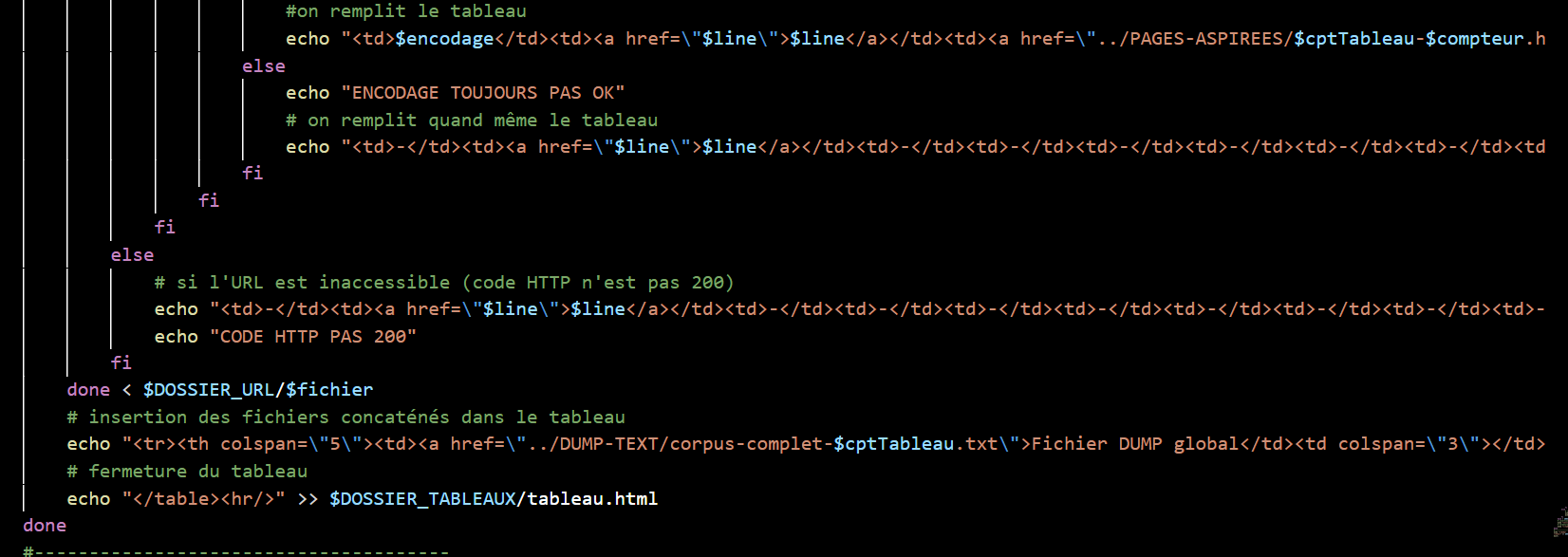
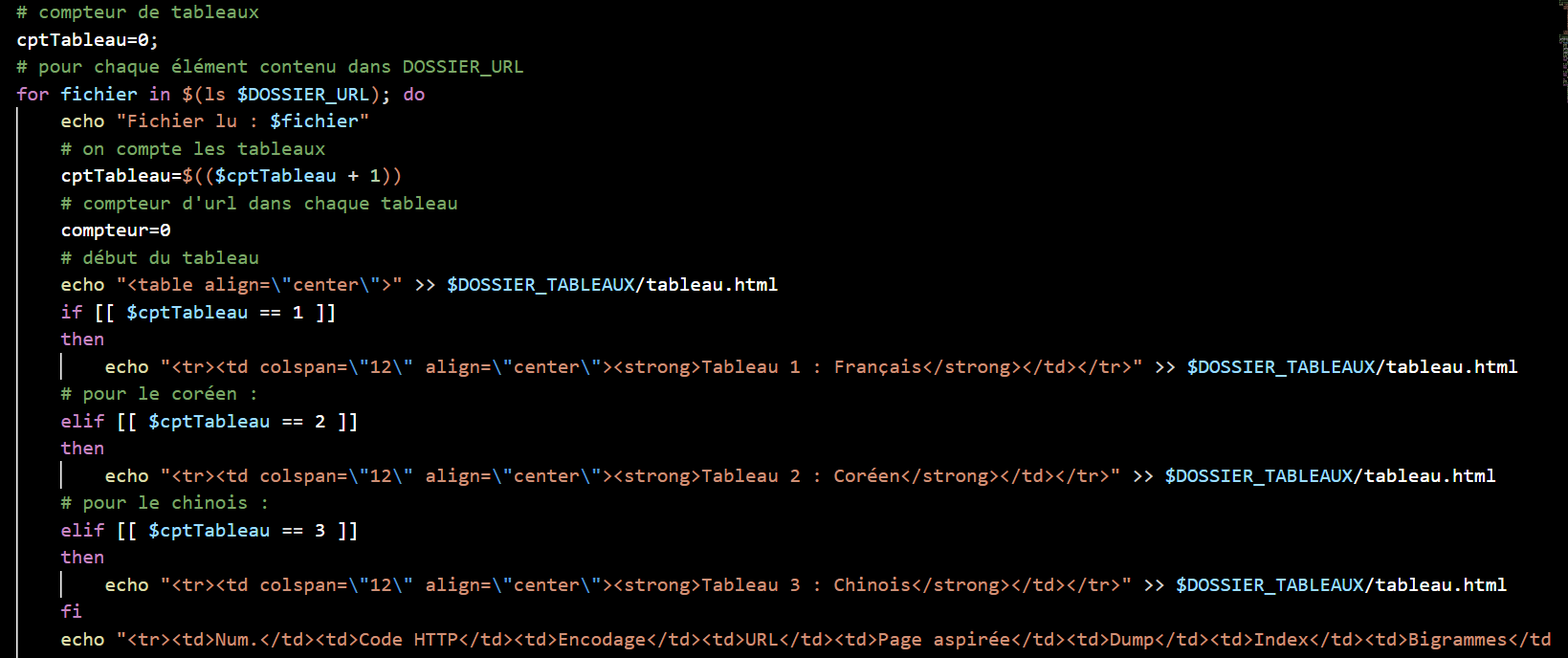
Au moyen d'une boucle for, chaque url est parcourue, ligne par ligne. Pour aspirer localement les pages au format HTML, à l'aide de la commande curl qui nous permet de vérifier si le code HTTP de la page est bien 200. Si c'est le cas, curl aspire la page et l'enregistre dans le dossier PAGES-ASPIREES. Comme nous travaillons sur trois langues, on crée trois tableaux (un par langue : français, coréen et chinois), voir ci-dessous.
Par contre, si le code n'est pas 200, nous ne traiterons pas ce ficher.

Si le code est égal à 200, on relance la commande curl pour détecter l'encodage de la page. L'encodage détecté est bien UTF-8 ? Alors la commande Lynx est lancée, elle permet d'obtenir le texte brut des pages aspirées et de les sauvegarder dans le dossier ./DUMP-TEXT. Ensuite, on nettoie les fichiers textes qui viennent d'être dumpés avec la commande sed.
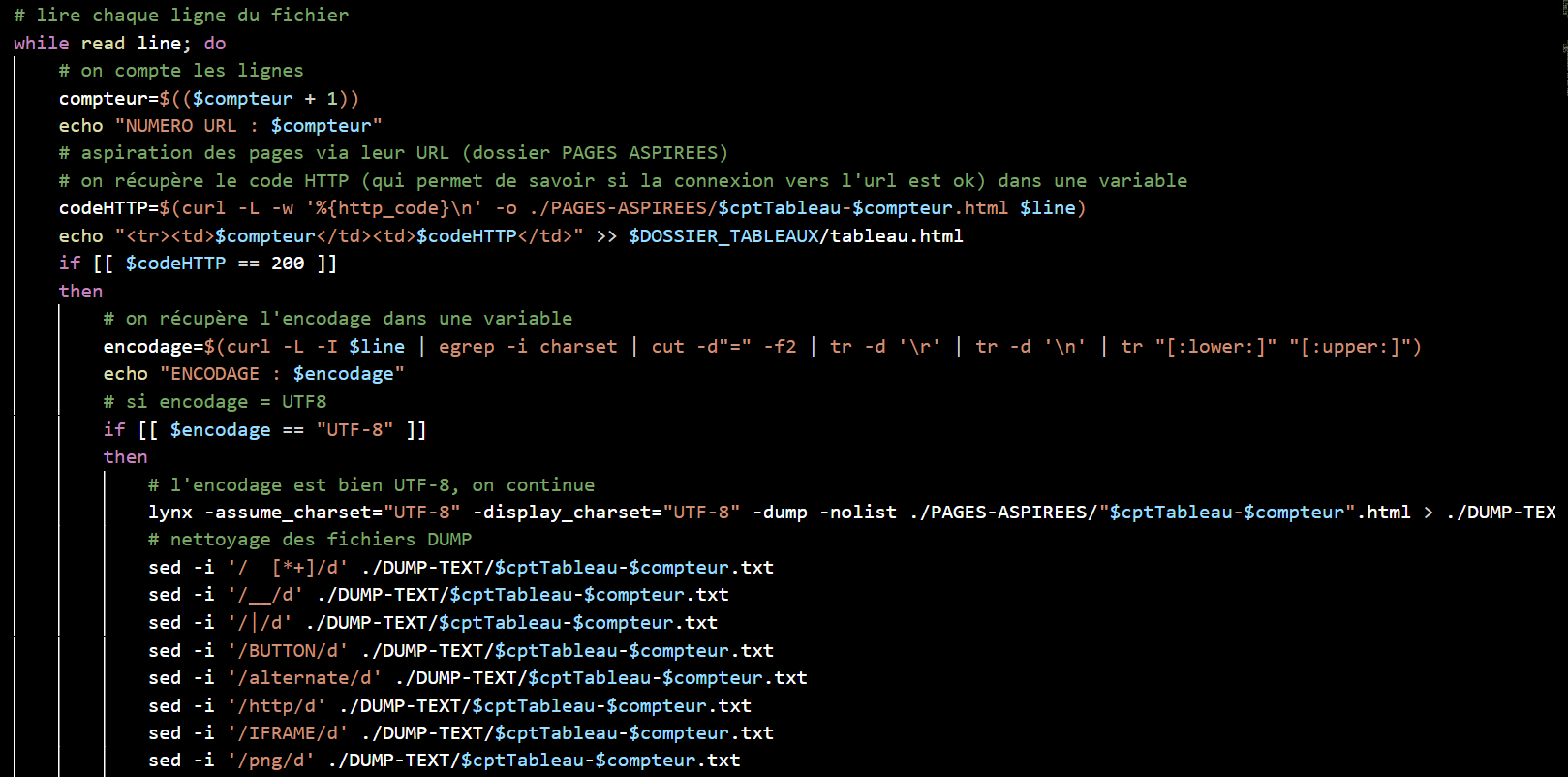
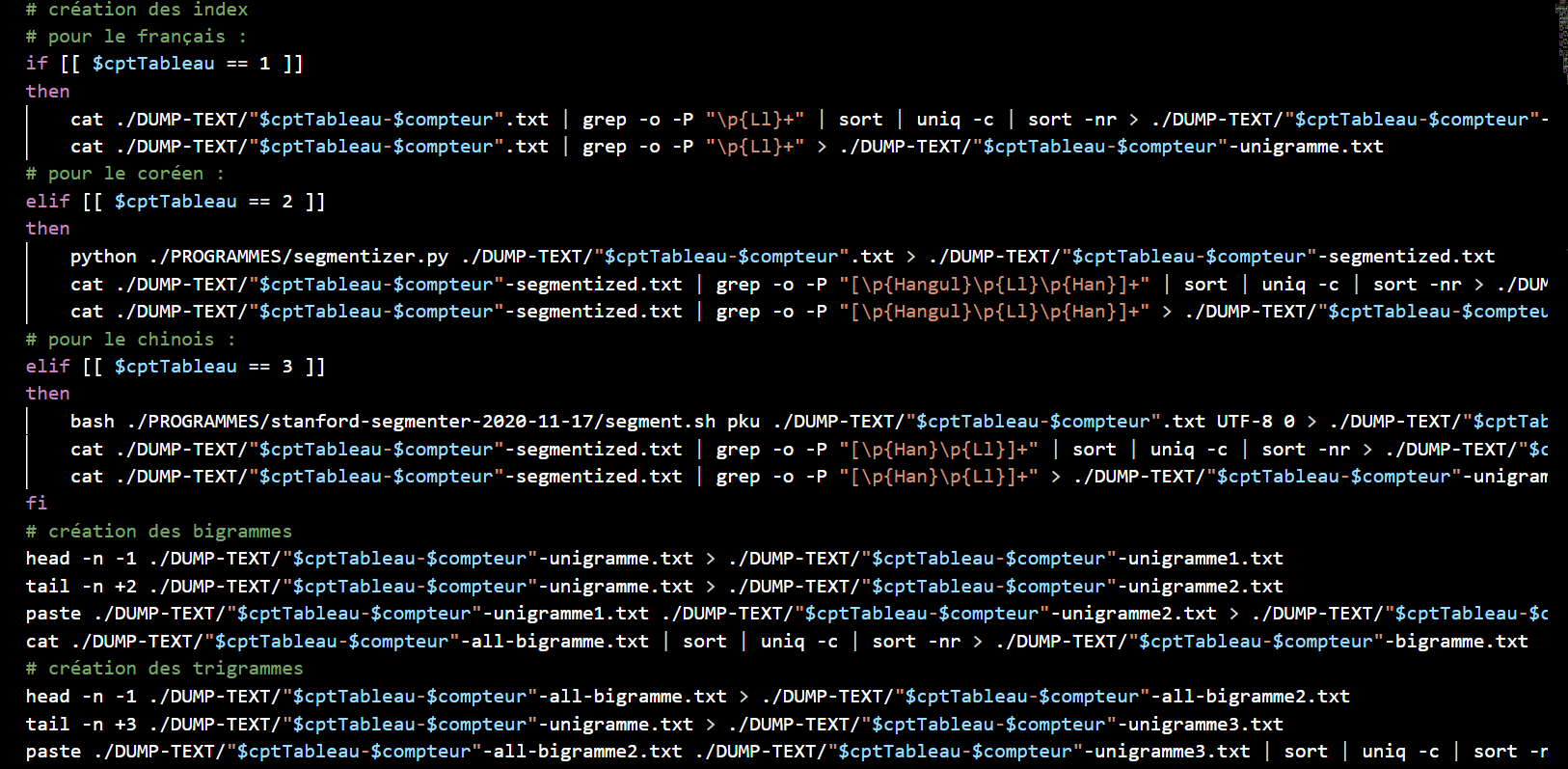
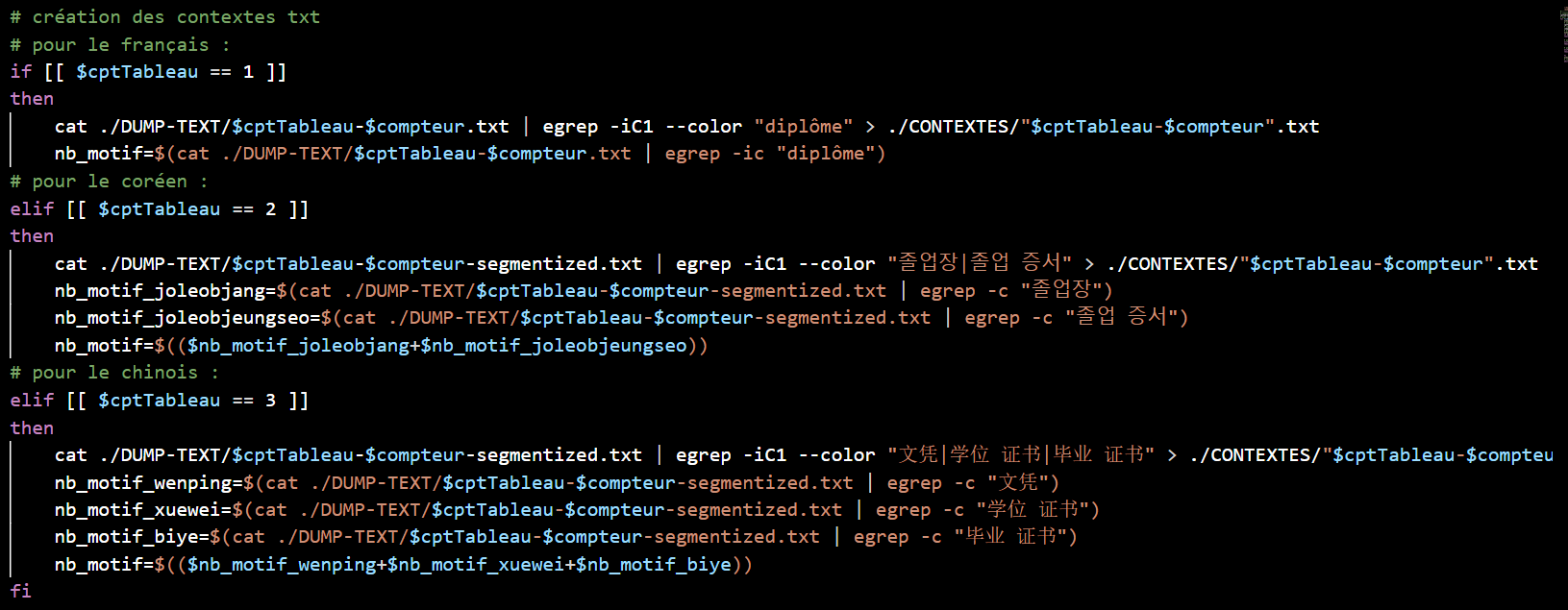
A ce stade, nous allons récupérer les index hiérarchiques, puis les bigrammes et les trigrammes pour chaque fichier. Nous utilisons ici un programme python et le stanford-segmenter pour segmenter le coréen et le chinois, enfin, nous recherchons les contextes des mots au format .txt et au format .html.
Si l'encodage reconnu n'est pas UTF-8, nous appliquons un autre traitement. On vérifie si le résultat de la recherche de l'encodage correspond ou non à un encodage connu du système, c'est-à-dire apparaissant dans la liste iconv. Si c'est le cas on convertit l'encodage avec iconv et et on répète ensuite les étapes ci-dessus.
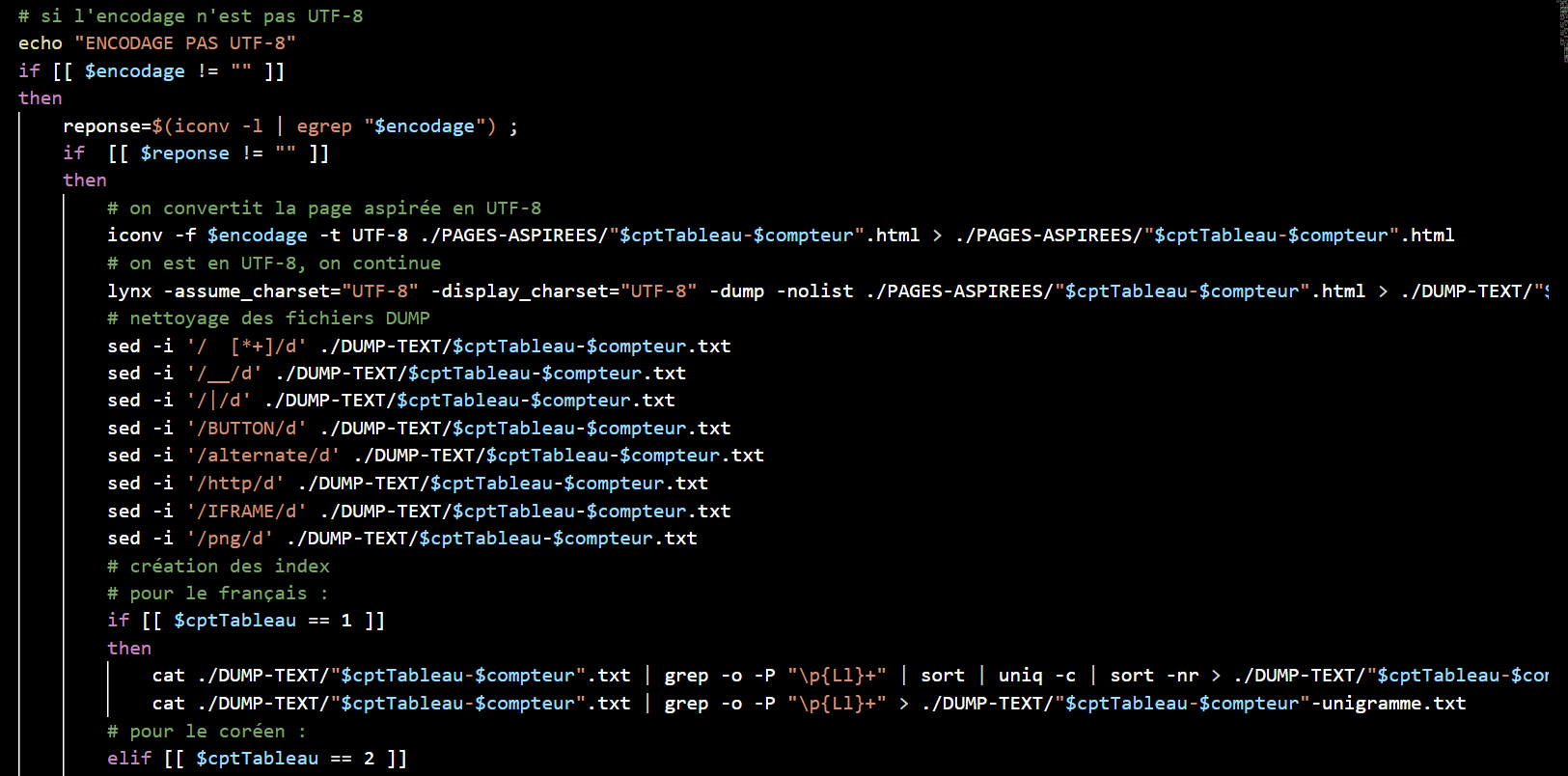
Cependant, au cours du processus, on peut constater le résultat de la détection de l'encodage de certaines pages est vide. Nous utilisons alors le programme detect-encoding.pl pour identifier leur encodage et ensuite, nous convertissons les encodages qui ne sont pas utf-8.
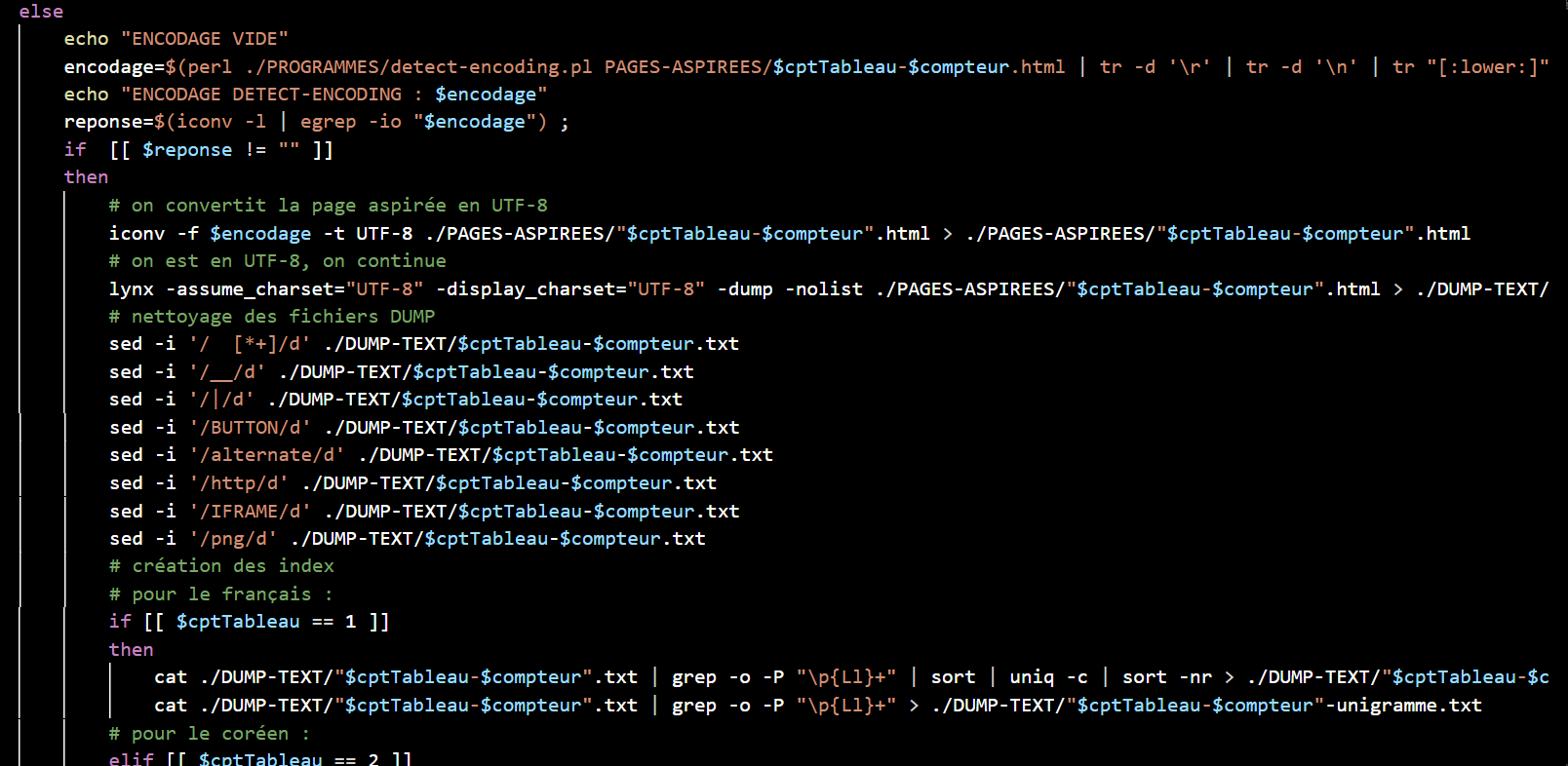
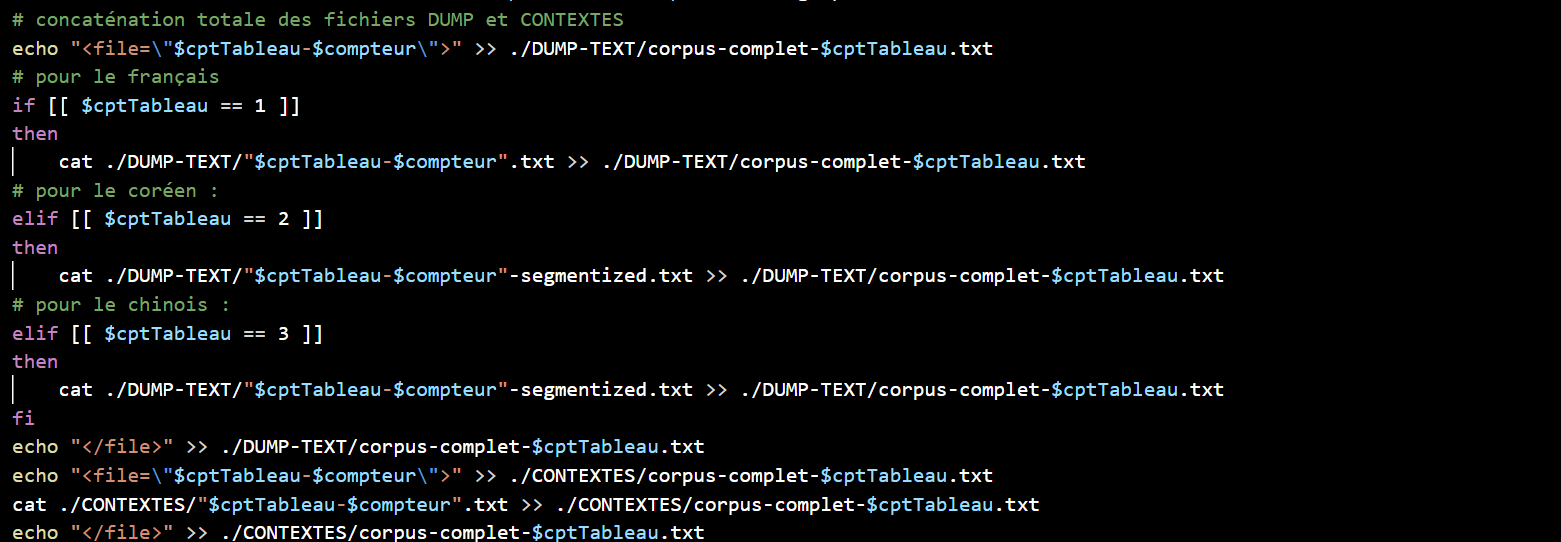
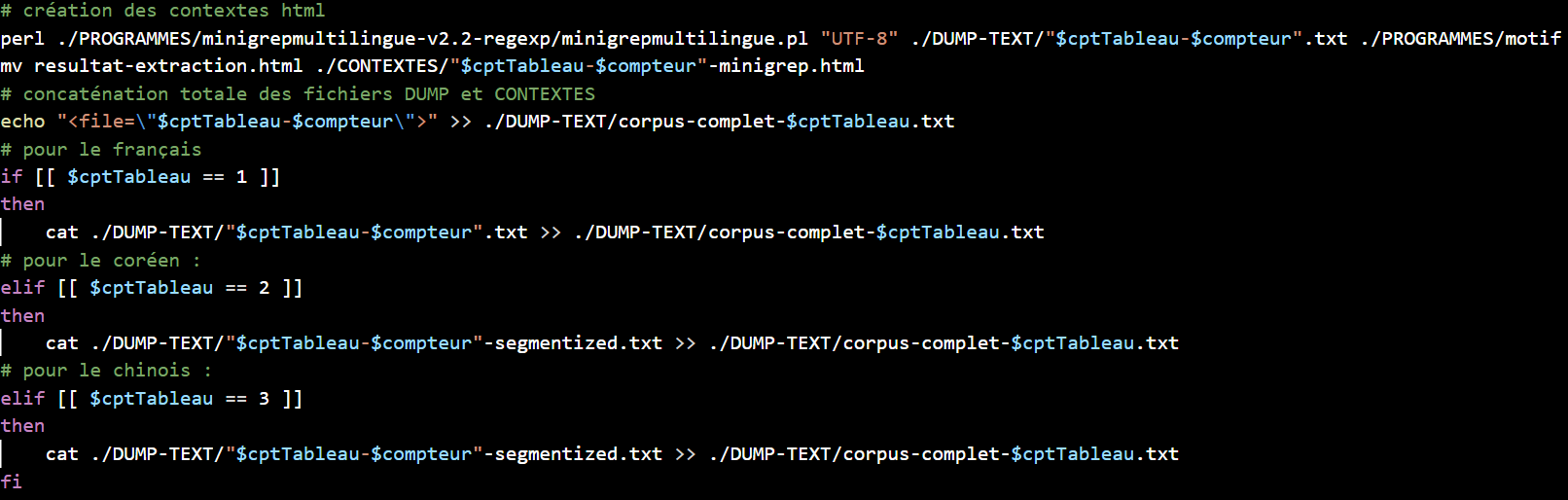
Nous concaténons ensuite le contenu de nos fichiers dump dans un fichier, puis celui de nos fichiers contextes et nous pouvons terminer le tableau.