Un fichier de fil RSS est un fichier XML qui ressemble à l'image ci-dessous. Il faut extraire le contenu textuel des balises <title> et <description>.

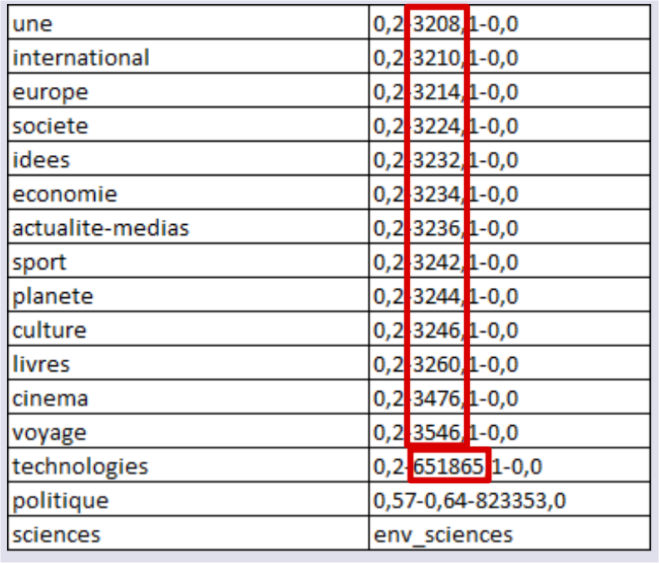
Pour chaque jour, il y a un fichier RSS par rubrique. Chaque rubrique est identifiée par un numéro :
L'arborescence des fils RSS est structurée comme suit :
> 2021
> un dossier par mois
> un dossier par jour
> un fil RSS par rubrique.
Pour récupérer le contenu textuel de chaque fil RSS, on va donc utiliser un programme récursif qui va parcourir toute l'arborescence de fichiers.
Notre programme va prendre en entrée :
- le nom du dossier de l'arborescence
- le numéro de la rubrique de notre choix
En sortie, on aura :
- un fichier de texte brut (TXT)
- et un fichier XML
par rubrique.
Le texte aura été nettoyé grâce à un sous-programme.
Pour récupérer le contenu des balises, on va utiliser des expressions régulières.
On va faire un programme en Perl et un programme en Python.
| LANGAGE INFORMATIQUE | MODE D'EMPLOI DU LANCEMENT DU SCRIPT DANS LE TERMINAL | TELECHARGEMENT DU SCRIPT ENTIER COMMENTE |
|---|---|---|
| Perl | perl bao1_parcours_arborescence_nettoyage.pl nom_dossier numero_rubrique | bao1_parcours_arborescence_nettoyage.pl |
| Python | python3 bao1_parcours_arborescence_nettoyage.py nom_dossier numero_rubrique | bao1_parcours_arborescence_nettoyage.py |
Le programme prend en entrée le numéro de la rubrique ainsi que le nom du dossier d'où part l'arborescence des fichiers RSS.
On ouvre deux fichiers en écriture :
- un fichier de texte brut qui contiendra les titres et les descriptions
- un fichier XML avec le même contenu que le fichier TXT mais formaté en XML.
On lance le sous-programme &parcourarborescencefichiers sur le dossier. C'est une fonction récursive car elle fait appel à elle-même. En effet, le programme met tous les noms des éléments contenus dans le dossier dans une liste.
Chaque élément est renommé, à chaque fois qu'on descend d'un niveau dans l'arborescence, par son chemin relatif par rapport au dossier pris en entrée au tout début du programme.
foreach my $file (@files) {
$file = $path."/".$file;On examine chacun des éléments :
- si c'est un dossier, on relance le sous-programme sur cette fois-ci le nouveau dossier, pour pouvoir descendre encore d'un niveau.
- si c'est un fichier, on le lit dans sa globailité, on récupère tout ce qui se trouve dans les balises <title>...</title> et <description>...</description> grâce à une expression régulière.
Notre expression régulière précise qu'il faut que la balise <title> soit précédée de la balise <item>. En effet, le fichier RSS contient un autre titre qui est lui précédé de la balise <channel> et qui correspond au titre de la rubrique.
while ($ligne=~/<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/gs) {
my $titre=&nettoyage($1);
my $titre=&nettoyage($1);On passe les titres et descriptions par un sous-programme de nettoyage pour enlever tous les <![CDATA[]]> qui étaient présents pour ne pas que le fichier RSS interprète des caractères comme des balises XML.
sub nettoyage {
my $texte=shift @_;
$texte=~s/(^<!\[CDATA\[)|(\]\]>$)//g;
#on rajoute un . à la fin de la description ou du titre. ça va permettre à aider UDpipe à segmenter dans la BAO2
$texte.=".";
#si le titre ou la description se finissait déjà par un point, on va avoir deux points d'affilé. on remplace donc les .. par .
$texte=~s/\.+$/\./;
return $texte;On écrit les titres et descriptions dans le fichier de texte brut. Dans le fichier XML, tous les titres seront écrits dans des balises <titre>...</titre> et les descriptions dans des balises <description>...</description>. Le couple titre-description est enfin mis dans des balises <item>.
print $txt "$titre \n";
print $txt "$description \n";
print $txt "----------------------------\n";
print $xml "<item><titre>$titre</titre><description>$description</description></item>\n";Le fichier TXT ressemble à ça :
Brexit : comment l’Europe a encaissé la perte du Royaume-Uni.
La sortie des Britanniques a d’abord sidéré l’Union européenne, qui a su faire preuve de résilience pour éviter un effet domino. Mais, sur bien des sujets, l’Europe est encore au milieu du gué.
----------------------------
Brexit : des premiers contrôles douaniers à Calais et en gare du Nord.
Près de 200 camions ont emprunté le tunnel sous la Manche « sans aucun problème » dans la nuit, après la sortie du Royaume-Uni du marché unique européen et le rétablissement des formalités douanières.
----------------------------Le fichier XML ressemble à ça :
<item><titre>Brexit : comment l’Europe a encaissé la perte du Royaume-Uni.</titre><description>La sortie des Britanniques a d’abord sidéré l’Union européenne, qui a su faire preuve de résilience pour éviter un effet domino. Mais, sur bien des sujets, l’Europe est encore au milieu du gué.</description></item>
<item><titre>Brexit : des premiers contrôles douaniers à Calais et en gare du Nord.</titre><description>Près de 200 camions ont emprunté le tunnel sous la Manche « sans aucun problème » dans la nuit, après la sortie du Royaume-Uni du marché unique européen et le rétablissement des formalités douanières.</description></item>Grâce à la commande "time" dans bash, on sait que le programme prend environ 7 secondes pour le traitement d'une rubrique.
Le programme en Python se déroule globalement de la même façon. Il est juste segmenté un peu différemment.
On crée deux fichiers :
- un fichier TXT
- un fichier XML
Puis, on lance la fonction qui va parcourir l'arborescence. On examine chaque élément qui se trouve dans le dossier :
- si c'est un dossier, on relance le parcours à partir de ce nouveau dossier
- si c'est un fichier, on lance la fonction "extract_un_fil()" qui va permettre d'extraire le contenu textuel du fil RSS.
Dans extract_un_fil(), on utilise ici aussi des expressions régulières pour trouver les titres et les descriptions. Ils sont passés dans la fonction nettoyage() qui fait la même chose que le sous-programme de Perl.
On écrit les titres et descriptions nettoyés dans le TXT et dans le XML formaté au format XML.
Le programme prend environ 5 secondes pour le traitement d'une rubrique. Il semble donc être plus rapide que le programme en Perl.