Le but de la BAO 4 est de représenter les relations de dépendances avec des graphiques en utilisant l'interface PadaGraph.
Pour cela, on repart du script Python de la BAO 3 pour l'extraction des relations de dépendance. Au lieu d'écrire nos relations dans un fichier, on les fait afficher sur le terminal et on envoie l'affichage de Bash sur l'interface PadaGraph avec la commande "curl".
| LANGAGE INFORMATIQUE | MODE D'EMPLOI DU LANCEMENT DU SCRIPT DANS LE TERMINAL | TELECHARGEMENT DU SCRIPT ENTIER COMMENTE |
|---|---|---|
| Python | python3 bao4_graphes_v2.py nom_fichier_udpipe.xml nom_relation | curl -X POST -H 'Content-Type: text/csv' --data-binary @- "https://padagraph.magistry.fr/post_csv/DelphineNguyenD" |
bao4_graphes_V2.py |
On repart du script en Python. Dans la BAO 3, on extrayait les relations de dépendance et on les écrivait dans un fichier TXT. On passait par un ensemble pour stocker nos couples (gouverneur - dépendant) tout au long du parcours.
Le programme de la BAO 4 va prendre en entrée :
- un nom de relation
- un fichier étiqueté avec UDpipe et reformaté en XML
En sortie, on a l'URL d'une page PadaGraph dans laquelle se trouve notre graph.
Pour pouvoir attribuer plus ou moins de poids aux relations entre deux sommets selon s'ils apparaissent souvent ensemble ou non, on va échanger notre ensemble de la BAO 3 pour un dictionnaire.
Chaque clé de notre dictionnaire va être un tuple de gouverneur-dépendant et chaque valeur va être le nombre d'occurrences de ce tuple dans notre corpus.
for dep_lemma, position_gouv in relation_buf:
dico_couples[nettoyage_lemme(sent_buf[position_gouv]),nettoyage_lemme(dep_lemma)]=dico_couples.get((sent_buf[position_gouv],dep_lemma),0)+1Avant d'écrire nos lemmes de dépendant-gouverneur dans notre dictionnaire, on les fait passer par une fonction de nettoyage. Cette fonction nettoyage_lemme() va enlever toutes les virgules et remplacer les espaces par des tirets du bas. Nous sommes obligés de passer par cette étape car sinon ces caractères vont poser problèmes dans le csv. Quand on fera les prints, on se servira des valeurs de ce dictionnaire dans la ligne qui va indiquer les paramètres du lien "relation".
On profite de cette boucle pour écrire ces mêmes lemmes dans une liste nommée wordcloud qu'on aura créée avant le lancement de la fonction extract_relation(). On va plus tard utiliser cette liste pour générer un wordcloud.
wc.generate(wordcloud)
wc.to_file(f"wordcloud_{relation}_{rubrique}.png")Pour la BAO 4, on veut envoyer l'affichage de notre terminal sur PadaGraph. On va donc remplacer l'écriture du fichier par des print().
Les affichages doivent être formatés comme un fichier csv avec la syntaxe de PadaGraph :
- on met "@" pour créer un type de sommets
- "_" pour créer des liens
- "#id" indique un identifiant unique pour un sommet
- "--" pour créer une barre
- "#label" pour donner un nom à un sommet
- "shape" dans la colonne propriété pour attribuer une forme à un sommet
- "weight" pour attribuer un poids à élement (les sommets vont être plus ou moins éloignés selon le poids)
Les prints au format .csv qui sont envoyés sur PadaGraph vont donc ressembler à ça :
@Gouv: #id, label, shape
g_avancer,avancer,triangle
g_coûter,coûter,triangle
g_discriminer,discriminer,triangle
@Dep: #id, label
d_s’il,s’il
d_Russie,Russie
d_fébrilité,fébrilité
_obj,weight:
g_encaisser,--,d_perte,40
g_sidéré,--,d_l’Union,40
g_faire,--,d_preuve,90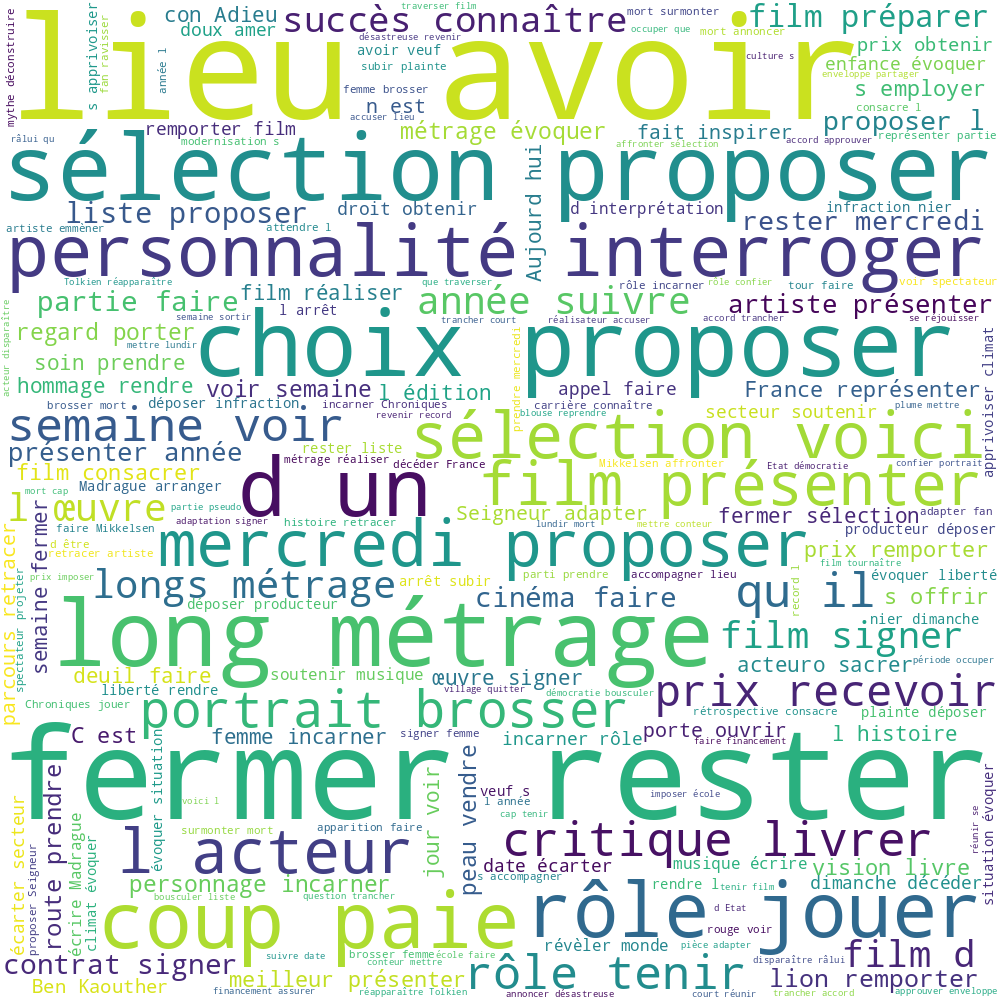
En regardant le graph de PadaGraph, on peut voir qu'il y a, sans aucune surprise, un gros cluster autour du lemme "film". On s'attendrait à ce que le poids de la relation (touner - film) soit très élevé. Cependant il n'est que de 40.
Si on regarde le WordCloud, on peut voir que "fermer" et "rester" font partie des mots les plus gros. Si on cherche "fermer" dans PadaGraph, on voit qu'en effet, le poids de la relation entre les deux est de 840.
Au final, cela n'est pas très étonant compte tenu de la situation sanitaire qui a grandement impacté les salles de cinéma. D'après Le Parisien, la fréquentation des salles de cinéma reste en baisse, même maintenant.

Dans la rubrique "Europe", le plus gros cluster est "gouvernement".
Dans le WordCloud, nous pouvons voir le lemme "covid" en gros. Si on va sur PadaGraph et qu'on explore les dépendants et gouverneurs en rapport avec cela, on peut voir, de façon non surprenante, les avis clivés sur le vaccin. On a d'un côté beacoup de lemmes par rapport au fait de "suspendre" et d'"interdire", et d'un autre ceux par pour le "défendre", l'"autoriser" et l'"imposer".
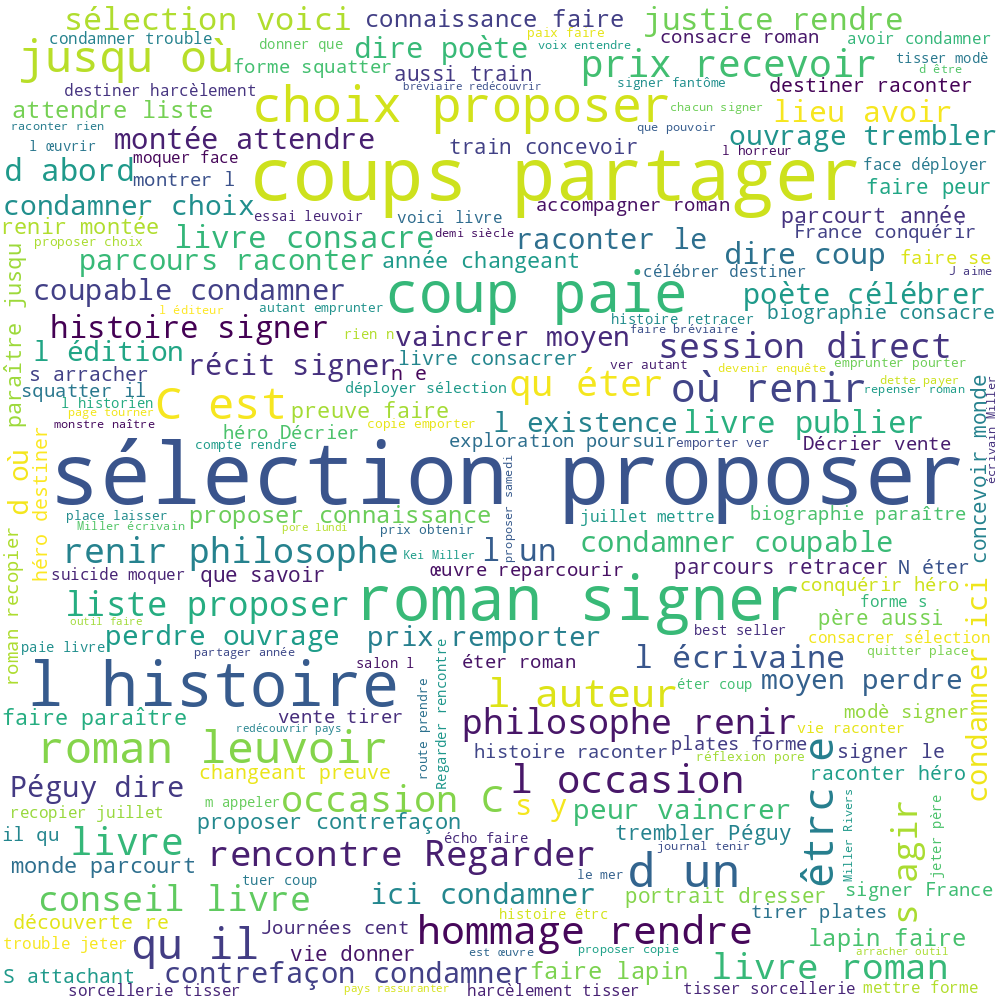
Le graphique des relations "obj" de la rubrique "Livres" est beaucoup plus petit que celui des deux autres rubriques. On peut voir trois gros clusters : "livre", "roman" et "vie". Il aurait sûrement été plus intéressant de choisir une autre rubrique pour les graphes.