Récupérer les contenus textuels des titres et des descriptions des rubriques France, Europe et International avec python
On lance le script depuis le répertoire PROJET-ENCADRE.
pour télécharger le script : ![]()
Temps : real 0m27.455s
Le script Perl est presque trois fois plus rapide que le script Python

Il y a quatre argument à ajouter : le dossier contenant l'arborescence, la sortie.xml, la sortie.txt et le nom de la rubrique. On lance le script pour chaque rubrique à traiter.

On utilise la fonction d'extraction crée dans un autre script (présenté ci dessous)

J'ai trouvé cela plus simple de pouvoir utiliser directement le nom des rubriques pour lancer la commande. J'ai donc créée un dictionnaire poru associer au nom des rubriques leur numéro.

On parcours l'arborescence grâce à la fonction iterdir(). Dès que l'on arrive sur un fichier .xml qui correspond à notre rubrique, on peut lancer la fonction extract_un_fil()
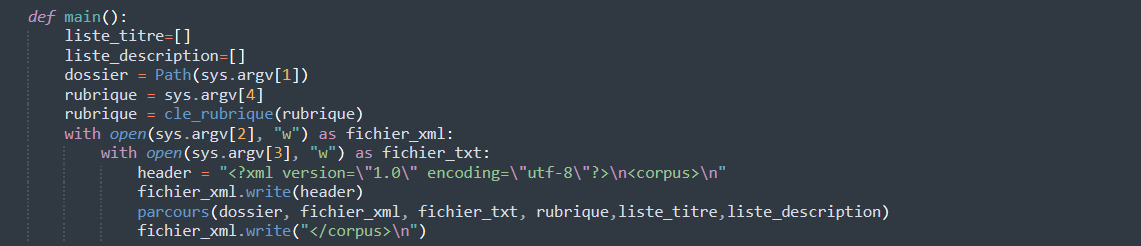
On crée deux liste vide, une pour les titres et une pour les descriptions. Cela va nous permettre d'éviter les doublons en vérifiant si le titre ou la description ont déjà été traité.e.s On récupère les arguments grâce au module sys.argv[]. Enfin, on va écrire le résultat de la fonction parcours() dans nos fichiers de sortie.xml et sortie.txt.
pour télécharger le script : ![]()

Cette expression régulière permet de repérer les informations qui nous interesse dans les fils RSS

La fonction nettoyage() permet de récupérer du texte propre (nettoyé de certains attributs comme CDATA etc.)
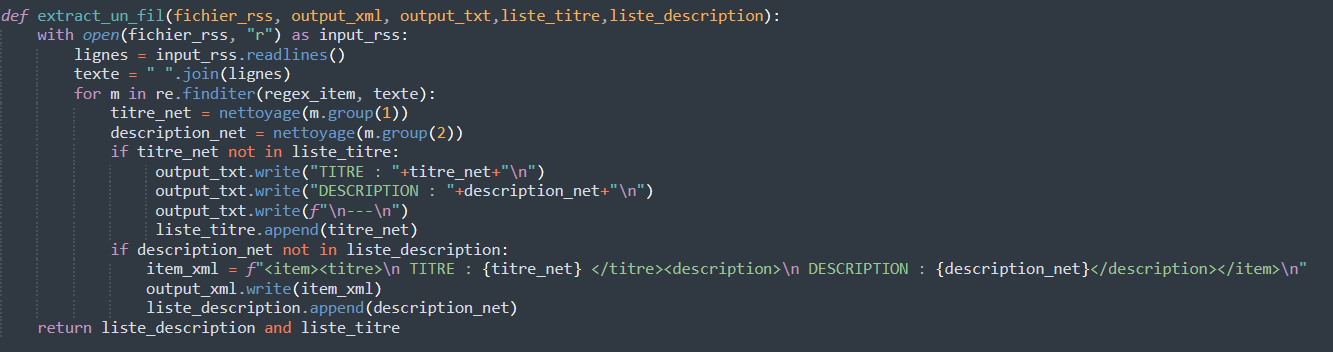
Cette fonction retourne la liste de descriptions et de titres qui permet d'éviter les doublons. C'est également cette fonction qui permet d'écrire les titres et les descriptions dans les fichiers de sortie.
Les sorties sont présentées par rubrique et par format dans le tableau ci-dessous.
| Rubrique | Sortie.txt | Sortie.xml |
|---|---|---|
| France | resultat-france.txt | resultat-france.xml |
| Europe | resultat-europe.txt | resultat-europe.xml |
| International | resultat-international.txt | resultat-international.xml |