Annotation du contenu textuel. On utiliser TreeTagger sur les fichiers .xml et Udpipe sur les fichiers .txt
On lance le script depuis le répertoire PROJET-ENCADRE.
pour télécharger le script : ![]()

Il y a quatre argument à saisir pour ce script : le dossier contenant l'arborescence, la nom-rubrique.xml, la sortie.txt et le nom de la rubrique. Etant donné que l'on doit passer par des fichiers tampon pour l'annotation TreeTagger, il faut impérativement mettre le nom de la rubrique pour la sortie.xml. On lance le script pour chaque rubrique à traiter.
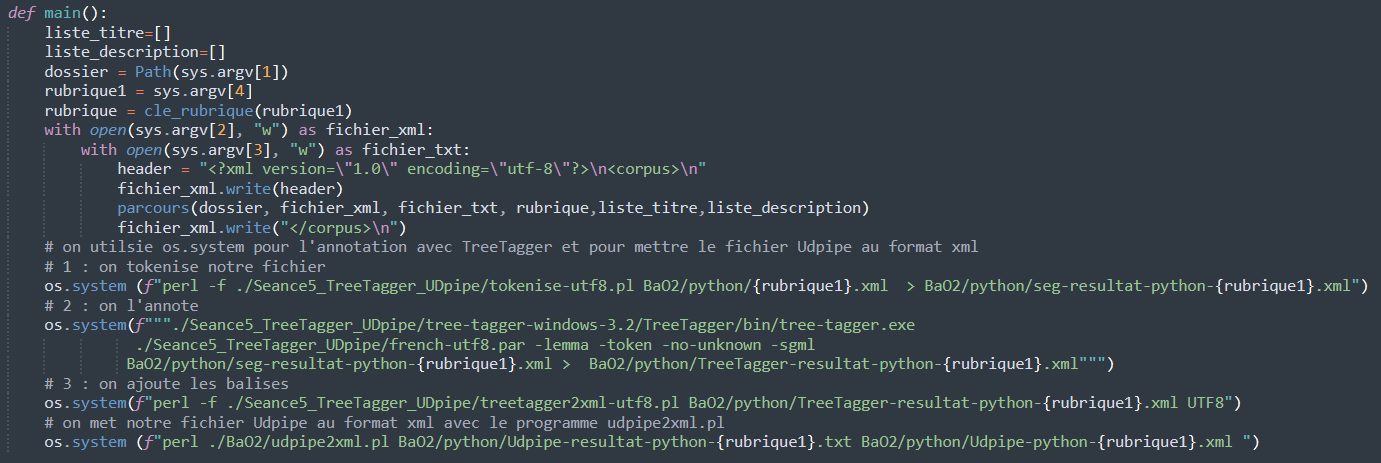
Une fois la fonction d'extraction lancé et les contenus textuels récupérés sous le format .xml et .txt annoté par Udpipe (cf extraction d'un fil ci-dessous), on va pouvoir faire l'annotation avec TreeTagger des fichiers .xml. Pour cela, on va utiliser os.system qui na nous permettre de lancer des programmes extérieurs à python. Ces programmes sont les mêmes que pour le script perl.
pour télécharger le script : ![]()
Ce script python reprend le script de la BaO1. On y ajoute l'analyse au fur et à mesure du contenu textuel avec udpipe
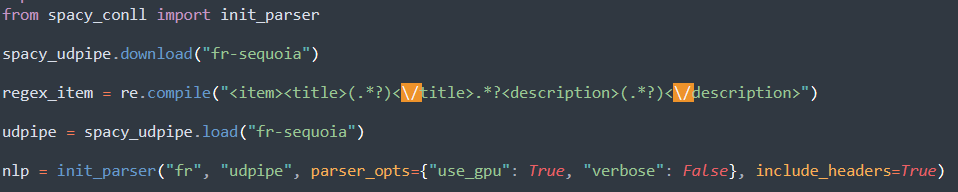
On importe le module spacy_udpipe pour notre script. On va également utiliser init_parser de spacy_conll pour avoir une sortie au format connl de notre contenu textuel. Pour cela, j'ai eu besoin d'initialiser le parser afin de pouvoir utiliser udpipe. J'ai trouvé ces informations sur spacy. Il faut également charger le modèle fr-sequoia pour l'annotation.
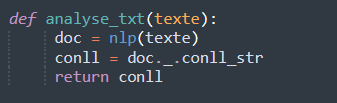
La fonction analyse_txt() permet d'annoter le texte avec udpipe et donne en sortie un format connl (.txt).
| Rubrique | Sortie Udpipe (CoNNL) | Sortie Udpipe (xml) | Sortie TreeTagger (xml) |
|---|---|---|---|
| France | resultat-france.txt | resultat-france.xml | resultat-france.xml |
| Europe | resultat-europe.txt | resultat-europe.xml | resultat-europe.xml |
| International | resultat-international.txt | resultat-international.xml | resultat-international.xml |