Description
Le but de cette boîte à outils est d'utiliser le fichier de sortie étiqueté par UDPipe(avec les dépendances) puis transformé en xml et de produire un fichier csv ayant un format spécifique, et enfin de poster ce fichier sur une application en ligne.
Ensuite, l'application en ligne va construire un graphe à partir du fichier envoyé. Enfin, nous devons observer et analyser les graphes créés pour chaque rubrique.
Les éléments nécessaires pour la construction de graphes Classificaton des données
Pour construire un graphe, l'application en ligne demande deux éléments principaux. Il s'agit d'abord des catégories où on range les mots avec leurs attributs (id, lemme, fréquence). Il s'agit ensuite des relations : un lien entre les mots classés dans les différentes catégories.
En cours, nous nous sommes entraînés sur les catégories "Gouverneur" et "Dépendants", et les relations de type "obj".
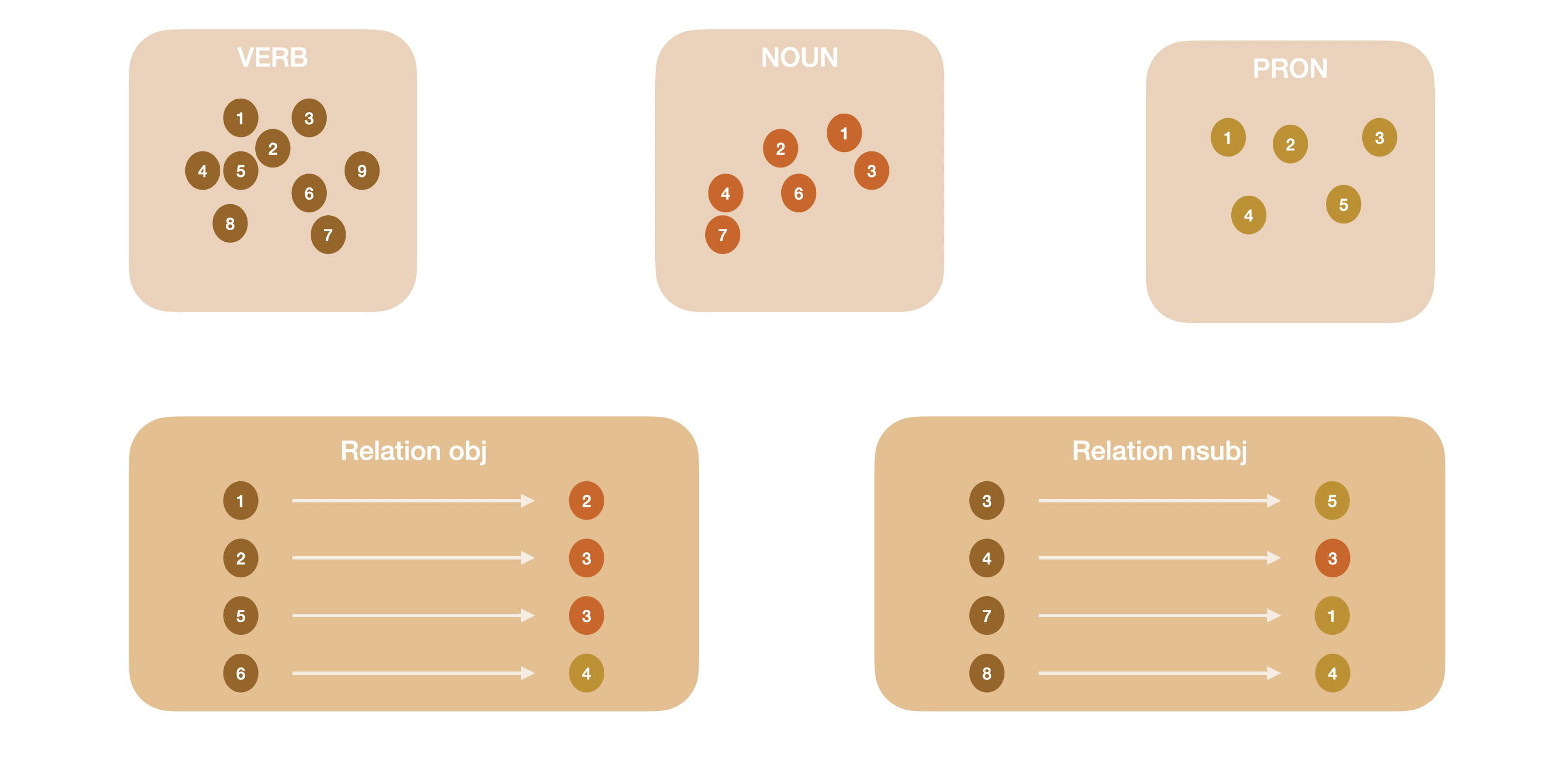
Afin d'avoir un résultat plus précis et plus efficace, j'ai décidé d'établir les catégories par pos et d'ajouter une relation "nsubj".
L'image ci-dessous illustre la relation entre les catégories pos et les dépendances des mots classés selon leur pos.
Le déroulement principal du script se trouve ci-dessous, j'ai gardé la structure principale de celle du script qui extrait la dépendance dans la boîte à outils 3.
import re
from pathlib import Path
import sys
########################################################################
## graphe : catégorie par pos, deux relation en même temps : obj et nsubj
## mettre en place un seuil de fréquence pour filtrer les bruits
#######################################################################
fic = sys.argv[1]
#nettoyage dans le fichier udpipe
def clean(s :str):
s=re.sub("’","'", s)
s=re.sub(",","",s)
s=re.sub("°","", s)
s=re.sub("ᵉ","", s)
s=re.sub("@","", s)
return s
sent_buf = {}
rel_buf = []
couples = set()
# on chercheles relations obj et nsubj
# construire un dictionnaire qui stocke les occurences de la relation obj et de la relation
relations = {"obj": set(), "nsubj": set()}
# dictionnaire
dicPos = dict()
for line in Path(fic, encoding='utf-8').read_text().split("\n"):
if line.startswith("<item>"):
fields = re.findall("<a>([^<]+)</a>", line)
idx, word, lemma, pos, _, _, head, rel, _, _ = fields
lemma = clean(lemma)
# enregistrer le lemma et le pos pour chaque item dans le dictionnaire
sent_buf[idx] = (lemma,pos)
if rel in relations :
# pour les items dépendants qui indique une relation ciblée, enregistrer le lemma, le pos, l'index de gouverneur ainsi que la relation.
rel_buf.append((lemma, head, pos, rel))
if line == "</p>":
# parcourir la liste ou on peut trouver tous les dépendants indiquant une des relations ciblées
for cible_lemma, head, cible_pos, rel in rel_buf:
# trouver le lemma et le pos du gouverneur
source_lemma = sent_buf[head][0]
source_pos = sent_buf[head][1]
# pour vérifier si les lemmes song vides après le nettoyage
# (parfois les lemmes sont seulement un caractères spéciaux, après le nettoyage, le lemme peut être vide)
if len(source_lemma) > 0 and len(cible_lemma) > 0:
# ajouter le gouverneur et le dépendant dans le dictionnaire de relation qui repère le type de relation par le variable rel
relations[rel].add((f"{source_lemma}", f"{cible_lemma}"))
# mettre le lemme du dépendant dans le dictionnaire pos selon le pos du dépendant
# à l'intérieur du dictionnaire pos, chaque pos est la clé d'un sous-dictionnaire lemmes dont les lemmes sont les clés, et la fréquence de lemme est la valeur
if source_pos not in dicPos :
dicPos[source_pos] = {source_lemma: 1}
else :
# compter la fréquence pour chaque lemme
if source_lemma not in dicPos[source_pos]:
dicPos[source_pos][source_lemma] = 1
else :
dicPos[source_pos][source_lemma] += 1
# mettre le lemme du gouverneur dans le dictionnaire pos selon le pos du gouverneur
if cible_pos not in dicPos :
dicPos[cible_pos] = {cible_lemma: 1}
else :
# compter la fréquence pour chaque lemme
if cible_lemma not in dicPos[cible_pos]:
dicPos[cible_pos][cible_lemma] = 1
else :
dicPos[cible_pos][cible_lemma] += 1
# vider le dictionnaire et la liste pour la phrase prochaine
rel_buf = []
sent_buf = {}
filtre = []
# normer les catégories en écrivant les éléments en formats demandés
# écrire les catégories pos et les items dans chaque catégorie
for pos in dicPos :
if len(dicPos[pos]) > 0:
print(f"@{pos}:, #id, label, weight")
for lemme in dicPos[pos] :
# écrire les élément ayant fréquence supérieure à 4 seulement pour la rubrique 3246
# pour la rubrique 3210 et 3244, la fréquence doit être supérieure à 15 pour avoir moin de bruit.
if dicPos[pos][lemme] > 4 :
print(f'{lemme}, {lemme}, {dicPos[pos][lemme]}')
else:
filtre.append(lemme)
# écrire pour chaque relation le gouverneur et le dépendant
for cat in relations :
print(f"_{cat}:")
for gouv, dep in relations[cat]:
# ne pas écrire les relations dont le gouverneur ou le dépendant est parmi les mots dont la fréquence est inférieure à 4
if gouv not in filtre and dep not in filtre:
print(f"{gouv},--,{dep}")
Exemple de l'affichage
