BAO 2
BAO 2
Les contenus textuels extraits doivent être étiquetés automatiquement (Treetagger et UDpipe : annotation en morpho-syntaxe et en dépendances)
Quel est le but de cette boîte à outil?
A partir du programme de la boîte à outil 1, on va annoter les titres et les descriptions avec deux outils : Treetagger et Udpipe. Il nous suffira donc de rajouter les lignes des étiqueteurs au programme.
Selon l'étiqueteur le type de sortie ne sera pas le même. Treetagger va sortir en output un fichier xml alors qu'Udpipe va sortir un fichier txt (avec des colonnes).
A partir du programme de la boîte à outil 1, on va annoter les titres et les descriptions avec deux outils : Treetagger et Udpipe. Il nous suffira donc de rajouter les lignes des étiqueteurs au programme.
Selon l'étiqueteur le type de sortie ne sera pas le même. Treetagger va sortir en output un fichier xml alors qu'Udpipe va sortir un fichier txt (avec des colonnes).

Perl
Le code ci-dessous est commenté. La version téléchargeable : ici
#/usr/bin/perl
# utilisation : perl bao2.pl ./2021 3208
# Il prend en arguments 2 éléments : (1) le nom de l'arborescence 2021 contenant les fils RSS de l'année 2021, (2) le nom de la rubrique à traiter (ici 3208 pour la rubrique A la une)
#-----------------------------------------------------------
use utf8;
use strict;
binmode(STDOUT, ":encoding(UTF-8)");
#-----------------------------------------------------------
if ($#ARGV != 1) {print "Il manque un argument à votre programme....\n";exit;} # on s'assure qu'il ne manque aucun argument
my $rep="$ARGV[0]"; #le répertoire 2021 sera le premier argument
my $RUBRIQUE="$ARGV[1]"; #la rubrique choisie est le deuxième argument
$rep=~ s/[\/]$//;# on s'assure que le nom du répertoire ne se termine pas par un "/"
#ouverture des fichiers#
open my $output, ">:encoding(UTF-8)","corpus-titre-description.txt"; #on créé un fichier txt qui recevra les titres et descriptions
open my $output2, ">:encoding(UTF-8)","pre-corpus-titre-description.xml"; #on créé un fichier xml qui recevra les titres et descriptions
print $output2 "<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<corpus>\n"; #on écrit le début de notre fichier xml final
#----------------------------------------
&parcoursarborescencefichiers($rep); #on appelle notre fonction de récursivité
#----------------------------------------
print $output2 "</corpus>\n"; #on écrit la fin de notre fichier xml final
#fermeture des fichiers#
close $output;
close $output2;
#----------------------------------------
#on annote avec udpipe sur le fichier txt
&etiquetageUP;
#on annote avec treetagger sur le fichier xml
&etiquetageTT;
#----------------------------------------------
#suprression des fichiers qui ne serviront plus
unlink("toto.txt");
unlink("toto2.txt");
unlink("pre-corpus-titre-description.xml");
#----------------------------------------------
exit;
#----------------------------------------------
# définition des fonctions #
sub etiquetageUP { #fonction pour étiqueter avec udpipe
system("./distrib-udpipe-1.2.0-bin/udpipe-1.2.0-bin/bin-win64/udpipe.exe --tokenize --tag --parse ./distrib-udpipe-1.2.0-bin/modeles/french-sequoia-ud-2.5-191206.udpipe corpus-titre-description.txt > corpus_titre-description.udpipe"); # on va pas utiliser --tokenizer=presegmented pour qu'udpipe tokénise lui même
}
#----------------------------------------------
sub etiquetageTT { #fonction pour étiqueter avec treetagger
system("./treetagger/treetagger.exe -lemma -token -no-unknown -sgml ./treetagger/french-utf8.par pre-corpus-titre-description.xml > corpus-titre-description ");
system("perl ./treetagger/treetagger2xml-utf8.pl corpus-titre-description UTF8");
}
#----------------------------------------------
sub parcoursarborescencefichiers { #même fonction que dans la bao1 sauf pour l'ajout des étiqueteurs
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
print "On entre dans le REPERTOIRE : $file \n";
&parcoursarborescencefichiers($file);
print "On sort du REPERTOIRE : $file \n";
}
if (-f $file) {
if ($file =~ /$RUBRIQUE.+\.xml$/) {
print "Traitement du fichier $file \n";
open my $input, "<:encoding(UTF-8)",$file;
$/=undef;
my $ligne=<$input> ;
close($input);
while ($ligne=~/<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/gs) {
my $titre=&nettoyage($1);
my $description=&nettoyage($2);
print $output "$titre \n";
print $output "$description \n";
# segmentation titre et description avec le programme tokenize offert par treetagger (on appelle la fonction)
my ($titreSEG,$descriptionSEG)=&segmentationTD($titre,$description);
print $output2 "<item><titre>\n$titreSEG\n</titre><description>\n$descriptionSEG\n</description></item>\n";
}
}
}
}
}
#----------------------------------------------
sub segmentationTD { #fonction qui tokenize les phrases
my ($arg1,$arg2)=@_; #on prend les valeurs des deux fichiers
#déroulement du traitement :
# 1. ecriture des données textuelles dans un fichier TOTO
# 2. tokenisation de TOTO
# 3. récupération des données
open my $tmp, ">:encoding(UTF-8)","toto.txt"; #on ouvre le fichier temporaire
print $tmp $arg1; #on écrit la valeur textuelle à tokeniser
close $tmp; #on ferme le fichier
system("perl ./treetagger/tokenise-utf8.pl toto.txt > toto2.txt"); #on tokenise et on ecrit le resultat dans un autre fichier
undef $/; #on enlève le \n
open my $tmp2, "<:encoding(UTF-8)","toto2.txt"; #on ouvre le fichier temporaire qui a la tokenisation
my $titresegmente=<$tmp2>; #on garde la tokenisation dans une valeur
close $tmp2; #on ferme le fichier
#-----------------------------------------------
#on fait de même pour la description
open $tmp, ">:encoding(UTF-8)","toto.txt";
print $tmp $arg2;
close $tmp;
system("perl ./treetagger/tokenise-utf8.pl toto.txt > toto2.txt");
open $tmp2, "<:encoding(UTF-8)","toto2.txt";
my $descriptionsegmente=<$tmp2>;
close $tmp2;
$/="\n"; #on réaffecte le saut de ligne
#-----------------------------------------------
return $titresegmente,$descriptionsegmente;
}
#----------------------------------------------
sub nettoyage { #même fonction de nettoyage que dans la bao1
my $texte=shift @_; #on peut aussi faire $TIT = $_[0]
$texte=~s/(^<!\[CDATA\[)|(\]\]>$)//g;
$texte.=".";
$texte=~s/\.+$/\./;
return $texte;
}
#----------------------------------------------
Lorsqu'on lance le programme voici ce qui s'affiche dans le terminal :
Voici les deux fichiers par rubrique en output : - rubrique à la une : fichier CONLL avec l'étiquetage udpipe et fichier xml avec l'étiquetage treetagger.
- rubrique livres : fichier CONLL avec l'étiquetage udpipe et fichier xml avec l'étiquetage treetagger.
- rubrique cinema : fichier CONLL avec l'étiquetage udpipe et fichier xml avec l'étiquetage treetagger.
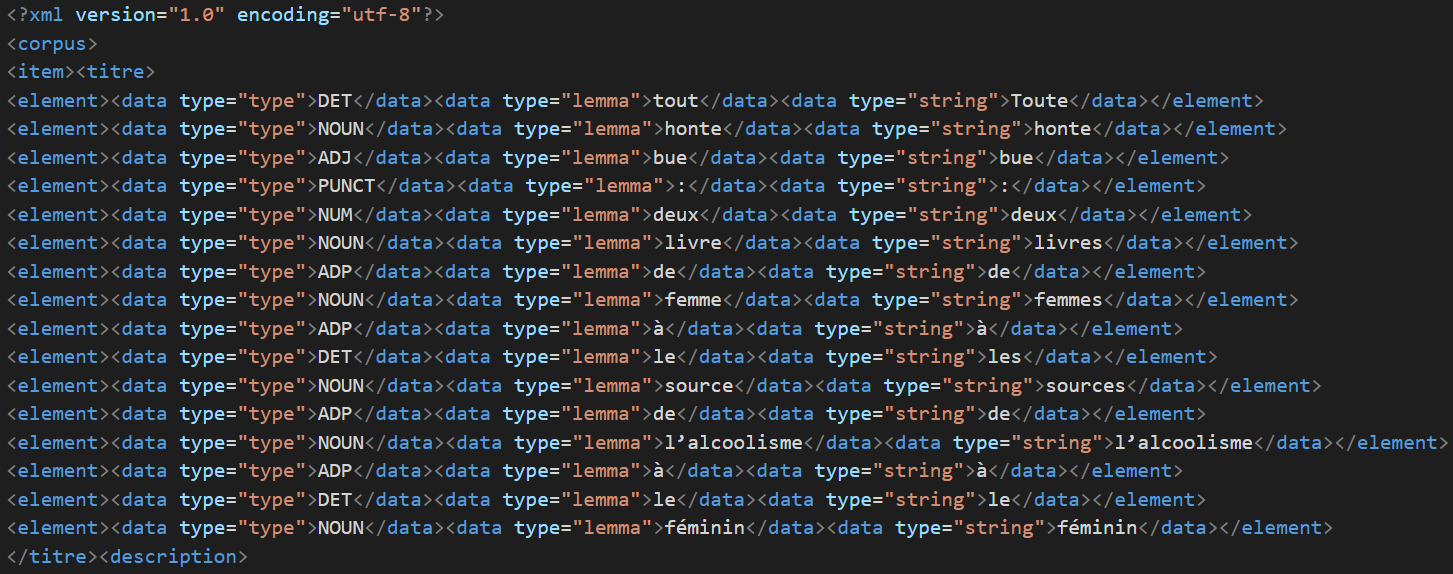
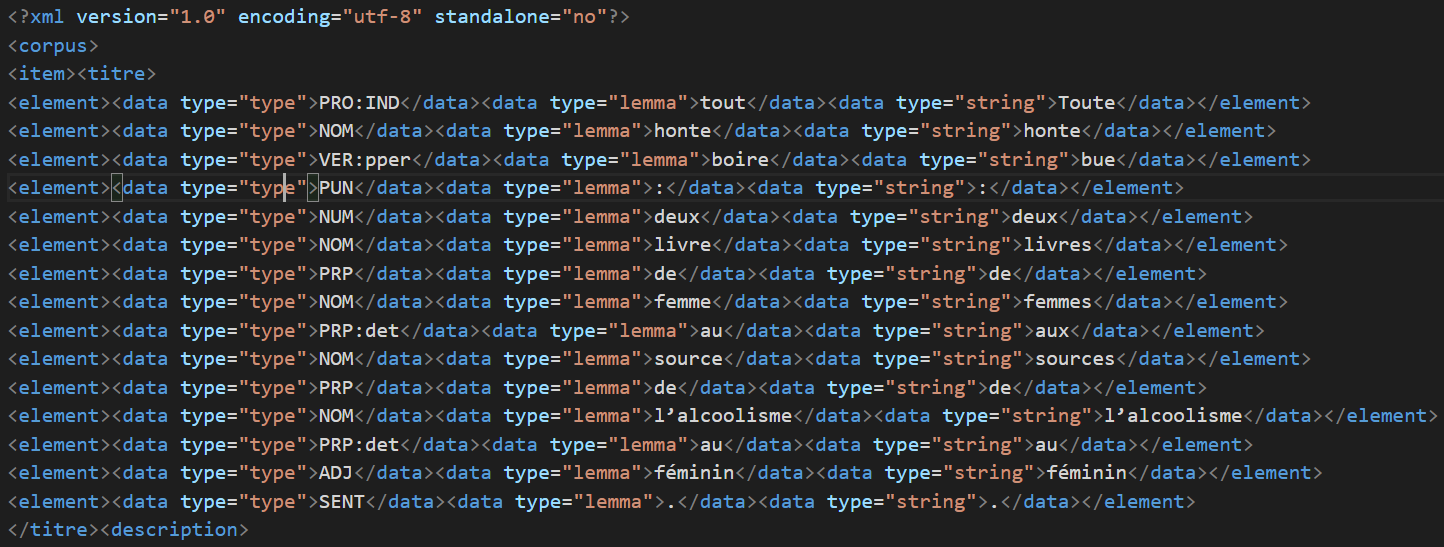
Un aperçu des résultats Udpipe et Treetagger :
Etiquetage de Udpipe :
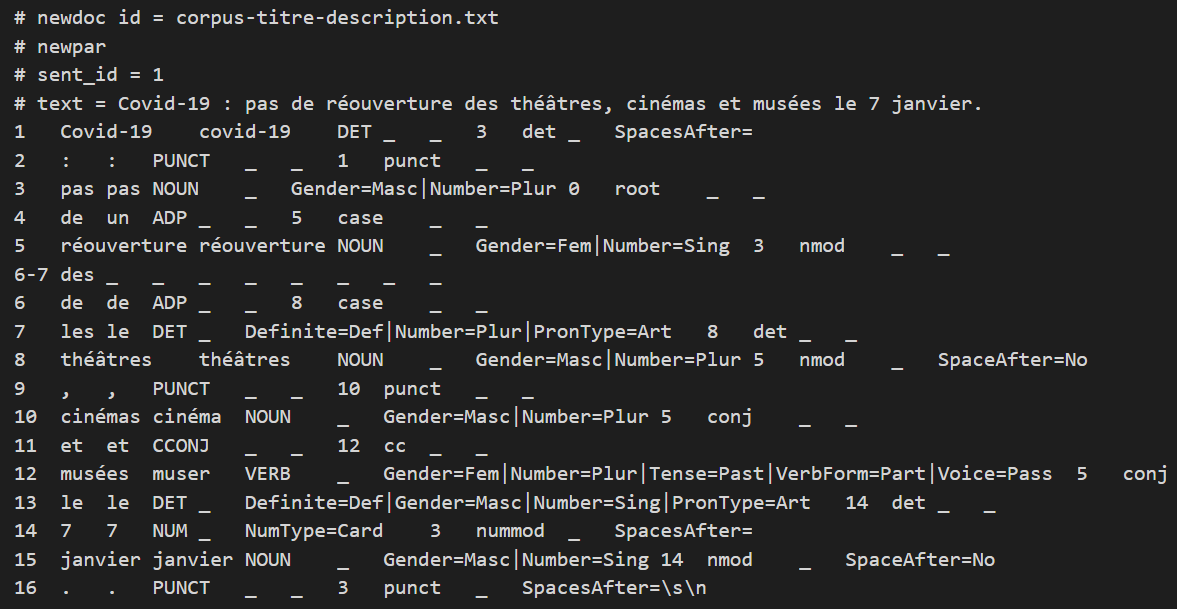
Etiquetage de Treetagger :
Python
Le code ci-dessous est commenté. La version téléchargeable : ici et ici.
#!/usr/bin/python3
import sys
from pathlib import Path
from bao2bis import extract_un_fil #on importe une fonction d'un autre programme python
#utilisation : python3 bao2.py ./2021 corpus-titre-descriptionbao2py.xml corpus-titre-descriptionbao2py.txt 3208
def parcours(dossier: Path, fichier_xml, fichier_txt, rubrique): #fonction de récursivité qui récupère les fichiers xml voulus
print(f"on traite {dossier}") #on affiche la phase de traitement dans laquelle on se trouve
for fichier in sorted(dossier.iterdir()): #pour chaque fichier dans le chemin de la variable dossier (qu'on trit par ordre croissant)
if fichier.is_dir(): #si le fichier est en réalité un dossier
parcours(fichier, fichier_xml, fichier_txt, rubrique) #on récursive
if fichier.is_file() and fichier.name.endswith(".xml") and rubrique in fichier.name : #si le fichier est véritablement un fichier, est un fichier xml et qu'il contient la rubrique souhaitée dans son nom
extract_un_fil(fichier, fichier_xml, fichier_txt) #on appelle la fonction d'extraction des titres et descriptions
def main(): #écriture des titres et descriptions dans les fichiers finaux
dossier = Path(sys.argv[1]) #le chemin qui est le premier argument est sauvegardé dans une variable
rubrique = sys.argv[4] #la rubrique choisie qui est le quatrième argument est sauvegardée dans une variable
with open(sys.argv[2], "w") as fichier_xml: #on ouvre le fichier xml final
with open(sys.argv[3], "w") as fichier_txt: #on ouvre le fichier txt final
fichier_xml.write("<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<corpus>\n") #on écrit le début du fichier xml
parcours(dossier, fichier_xml, fichier_txt, rubrique) #on appelle la fonction parcours
fichier_xml.write("</corpus>\n") #on écrit la fin du fichier xml
if __name__ == "__main__": #si le nom du programme python est bien celui dans le terminal alors on appelle la fonction main
main()
########################################
# 2ème programme #
########################################
#!/usr/bin/python3
import sys
import re
import spacy_udpipe
spacy_udpipe.download("fr-sequoia") #on télécharge l'un des modèles d'entraînements français de spacy-udpipe
udpipe = spacy_udpipe.load("fr-sequoia") #on charge le modèle d'entraînement français
regex_item = re.compile("<item><title>(.*?)<\/title>.*?<description>(.*?)<\/description>") #on sauvegarde la regex pour trouver les titres et les descriptions. Cette regex sauvegarde grâce aux parenthèses le texte du titre (1) et le texte de la description (2)
def analyse_txt(texte): #fonction qui applique l'analyse udpipe
doc = udpipe(texte) #on applique l'analyse udpipe sur le texte
resultat = "" #variable qui aura les étiquettes de chaque mot
for token in doc: #pour chaque mot du texte analysé
resultat += f"{token.text}\t{token.lemma_}\t{token.pos_}\n" #on écrit dans la variable resultat la forme du mot, son lemme et sa catégorie
return resultat
def token2xml(token): #fonction qui transforme une analyse de mot en fichier xml
return f'<element><data type="type">{token.pos_}</data><data type="lemma">{token.lemma_}</data><data type="string">{token.text}</data></element>\n' #on écrit dans le fichier xml final les balises de début et de fin de mot/phrase ainsi que la catégorie de chaque mot, son lemme et sa forme
def analyse_xml(texte): #fonction qui transforme le résultat de l'analyse udpipe en fichier xml
doc = udpipe(texte) #on applique l'analyse udpipe sur le texte
resultat = ""
for token in doc: #pour chaque mot du texte
resultat += token2xml(token) #on appelle la fonction token2xml sur le mot
return resultat
def nettoyage(texte): #fonction qui permet de ne récupérer que le véritable texte
texte_net = re.sub("<!\[CDATA\[(.*?)\]\]>", "\\1", texte)
return texte_net
def extract_un_fil(fichier_rss, output_xml, output_txt): #fonction qui récupère chaque titre et description du fichier
with open(fichier_rss, "r") as input_rss: #on ouvre le fil rss
texte = "".join(input_rss.readlines()) #on garde les lignes dans une variable
for m in re.finditer(regex_item, texte): #on cherche le titre et la description dans chaque ligne
titre_net = nettoyage(m.group(1)) #on applique la fonction de nettoyage au titre
description_net = nettoyage(m.group(2)) #on applique la fonction de nettoyage à la description
output_txt.write(f"{analyse_txt(titre_net)}\n") #on écrit dans le fichier txt final l'analyse udpipe du titre grâce à l'appel de la fonction analyse_txt
output_txt.write(f"{analyse_txt(description_net)}\n\n") #on écrit dans le fichier txt final l'analyse udpipe de la description grâce à l'appel de la fonction analyse_txt
output_xml.write(f"<item><titre>\n{analyse_xml(titre_net)}</titre><description>\n{analyse_xml(description_net)}</description></item>\n") #on écrit dans le fichier xml final l'analyse udpipe des titres et des descriptions grâce à l'appel de la fonction analyse_xml
if __name__ == "__main__": #si le nom du programme dans le terminal est celui du programme
fichier_rss = sys.argv[1] #on récupère le nom du fil rss
fichier_xml = sys.argv[2] #on récupère le nom du fichier xml final
fichier_txt = sys.argv[3] #on récupère le nom du fichier txt final
extract_un_fil(fichier_rss, fichier_xml, fichier_txt) #on appelle la fonction extract_un_fil sur les 3 fichiers récupérés
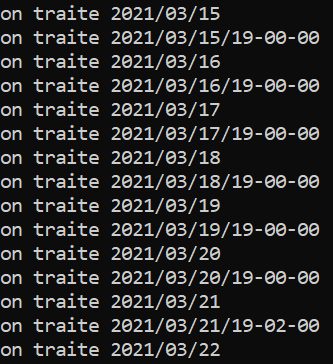
Lorsqu'on lance le programme voici ce qui s'affiche dans le terminal :
Voici les deux fichiers par rubrique en output : - rubrique à la une : fichier txt étiqueté par spacy-udpipe et fichier xml étiqueté par spacy-udpipe.
- rubrique livres : fichier txt étiqueté par spacy-udpipe et fichier xml étiqueté par spacy-udpipe.
- rubrique cinema : fichier txt étiqueté par spacy-udpipe et fichier xml étiqueté par spacy-udpipe.
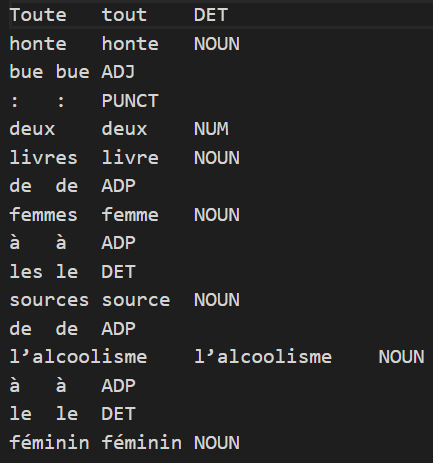
Un aperçu des résultats Spacy-Udpipe :
Fichier txt :
Fichier xml :