
 BAO 3
BAO 3
Ici nous extrayons les patrons syntaxiques et les relations de dépendance des fichiers xml étiquetés par Treetagger et Udpipe.
Perl (patrons)
Le code ci-dessous est commenté. La version téléchargeable : ici
#!/usr/bin/perl
# utilisation : perl bao3.pl corpus-titre-description.xml (fichier treetagger ou udpipe) patronqu'onsouhaite
use utf8;
binmode STDOUT,":utf8";
my $fichereatraiter=shift @ARGV; #on enlève le nom du fichier xml de la liste et on la met dans une variable
my @patron=@ARGV; #on met le patron dans un liste
open my $input, "<:encoding(utf-8)",$fichereatraiter; #on ouvre le fichier xml étiqueté à lire
my @liste=<$input>; #on envoit l'xml dans une liste
close($input); #on ferme le fichier xml
while (my $ligne=shift @liste) { #on va lire la liste en la vidant et on va parcourir la liste jusqu'à ce qu'elle soit vide
my $terme=""; #variable qui contiendra les mots correspondant au patron cherché
if ($ligne=~/<element><data type="type">$patron[0]<\/data><data type="lemma">[^<]+?<\/data><data type="string">([^<]+?)<\/data><\/element>/) { #on vérifie que la ligne = $patron[0] (le premier élément du patron) et si c'est bon alors on lit autant de lignes qu'il y a d'éléments dans le patron
$terme=$terme.$1; #je stocke le mot gardé comme variable entre () que je récupère de ma ligne (qui a été extraite de ma liste)
my $longueur=1; #variable qui permettra le contrôle de la longueur du patron
my $indice=1; #permet de gérer la "boucle"
while (($liste[$indice-1]=~/<element><data type="type">($patron[$indice])<\/data><data type="lemma">[^<]+?<\/data><data type="string">([^<]+?)<\/data><\/element>/) and ($indice <= $#patron)) { #indice-1 car la ligne qu'on extrait a indice 1 mais la ligne d'avant a indice 0 car est dans la liste
$indice++; #on avance dans la liste
$terme.=" ".$2; #j'ajoute le nouveau mot qui correspond au patron dans la variable
$longueur++; #on avance dans le patron
}
if ($longueur == $#patron + 1) { #si la longueur est égale à la longueur du patron
$dicoPatron{$terme}++; #on ajoute la variable contenant les mots qui correspondent au patron dans un dictionnaire
$nbTerme++; #on ajoute +1 au nombre de patrons trouvés
}
}
}
open my $resume,">:encoding(UTF-8)","resume.txt"; #on créé un fichier qui contiendra le résultat final
print $resume "$nbTerme éléments trouvés\n\n"; #on affiche dans le fichier le nombre de patrons trouvés
foreach my $patron (sort {$dicoPatron{$b} <=> $dicoPatron{$a} } keys %dicoPatron) { #pour chaque élément du dictionnaire j'affiche le patron dans mon fichier
print $resume "$dicoPatron{$patron}\t$patron\n";
}
close($resume); #on ferme le fichier final
Voici les deux fichiers txt par rubrique et par patron en output : - rubrique à la une :
Patron Udpipe NOM PREP NOM PREP (NOUN ADP NOUN ADP) et Patron Treetagger NOM PREP NOM PREP (NOM PRP NOM PRP).
Patron Udpipe VERBE DET NOM (VERB DET NOUN) et Patron Treetagger VERBE DET NOM (VER:pres DET:ART NOM).
Patron Udpipe NOM ADJ (NOUN ADJ) et Patron Treetagger NOM ADJ (NOM ADJ).
Patron Udpipe ADJ NOM (ADJ NOUN) et Patron Treetagger ADJ NOM (ADJ NOM).
- rubrique livres :
Patron Udpipe NOM PREP NOM PREP (NOUN ADP NOUN ADP) et Patron Treetagger NOM PREP NOM PREP (NOM PRP NOM PRP).
Patron Udpipe VERBE DET NOM (VERB DET NOUN) et Patron Treetagger VERBE DET NOM (VER:pres DET:ART NOM).
Patron Udpipe NOM ADJ (NOUN ADJ) et Patron Treetagger NOM ADJ (NOM ADJ).
Patron Udpipe ADJ NOM (ADJ NOUN) et Patron Treetagger ADJ NOM (ADJ NOM).
- rubrique cinema :
Patron Udpipe NOM PREP NOM PREP (NOUN ADP NOUN ADP) et Patron Treetagger NOM PREP NOM PREP (NOM PRP NOM PRP).
Patron Udpipe VERBE DET NOM (VERB DET NOUN) et Patron Treetagger VERBE DET NOM (VER:pres DET:ART NOM).
Patron Udpipe NOM ADJ (NOUN ADJ) et Patron Treetagger NOM ADJ (NOM ADJ).
Patron Udpipe ADJ NOM (ADJ NOUN) et Patron Treetagger ADJ NOM (ADJ NOM).
Extrait de résultat des fichiers txt Treetagger et Udpipe :
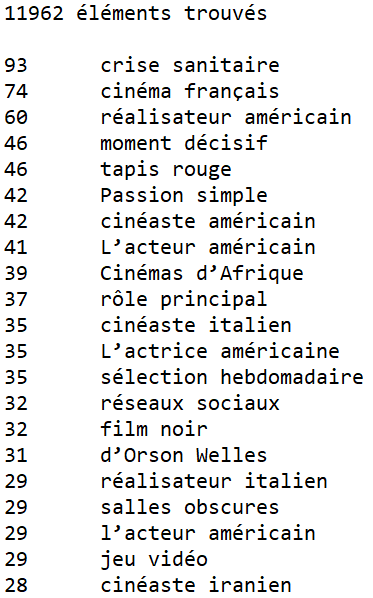
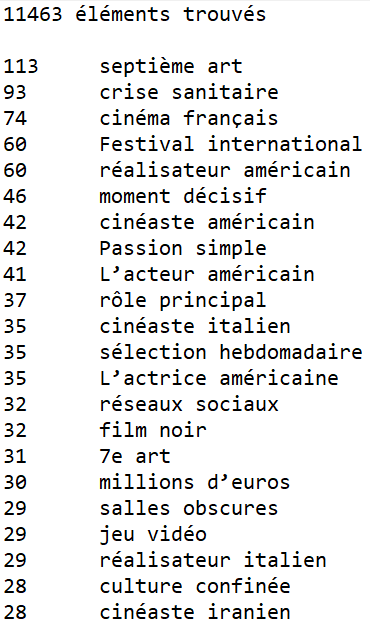
On peut remarquer quelques différences de résultat en Treetagger et Udpipe.
Perl (relations de dépendance)
Le code ci-dessous est commenté. La version téléchargeable : ici.
Nous allons utiliser le fichier perl bao3bis.pl afin d'extraire les informations de relations étiquetées par Udpipe au format xml.
#!/usr/bin/perl
#utilisation : perl bao3bis.pl corpus_titre-description.udpipe
my $first=0;
my $lastposition="";
open(INPUT,"<:encoding(utf-8)",$ARGV[0]); #on récupère le nom du fichier à transformer
open(OUTPUT,">:encoding(utf-8)","$ARGV[0].xml"); #on créé le fichier de sortie avec le nom récupéré
print OUTPUT "<?xml version=\"1.0\" encoding=\"utf-8\"?>\n"; #on créé le début de sortie xml
print OUTPUT "<baseudpipe>\n";
my $first=0;
my $tempvar = "";
while (my $ligne=<INPUT>) {
next if ($ligne=~/^$/);
$ligne=~s/\r//;
if ($ligne=~/^([^\t]*) ([^\t]*) ([^\t]*) ([^\t]*) ([^\t]*) ([^\t]*) ([^\t]*) ([^\t]*) ([^\t]*) ([^\t]*)$/) { #on va mettre dans une variable chacun des termes sauvegardés entre parenthèses
my $a1=$1;
my $a2=$2;
my $a3=$3;
my $a4=$4;
my $a5=$5;
my $a6=$6;
my $a7=$7;
my $a8=$8;
my $a9=$9;
my $a10=$10;
chomp($a1);chomp($a2);chomp($a3);chomp($a4);chomp($a5);chomp($a6);chomp($a7);chomp($a8);chomp($a9);chomp($a10);
$a1=~s/&/&/g;
$a2=~s/&/&/g;
$a3=~s/&/&/g;
$a4=~s/&/&/g;
$a5=~s/&/&/g;
$a6=~s/&/&/g;
$a7=~s/&/&/g;
$a8=~s/&/&/g;
$a9=~s/&/&/g;
$a10=~s/&/&/g;
if (($a1 == 1 and ($lastposition ne "1-2")) or ($a1 eq "1-2")) {
if ($first > 0) {print OUTPUT "</p>\n";}
print OUTPUT "<p>\n";
}
$first++;
print OUTPUT "<item><a>$a1</a><a>$a2</a><a>$a3</a><a>$a4</a><a>$a5</a><a>$a6</a><a>$a7</a><a>$a8</a><a>$a9</a><a>$a10</a></item>\n"; #on écrit chacune des valeurs analytiques dans le fichier xml
$tempvar = $a1;
$lastposition=$a1;
}
}
close(INPUT);
print OUTPUT "</p>\n</baseudpipe>\n";
close(OUTPUT);
Voici les fichiers par rubrique en output :
- rubrique à la une : fichier xml contenants les étiquettes de dépendance.
- rubrique livres : fichier xml contenants les étiquettes de dépendance.
- rubrique cinema : fichier xml contenants les étiquettes de dépendance.
Un aperçu du résultat :
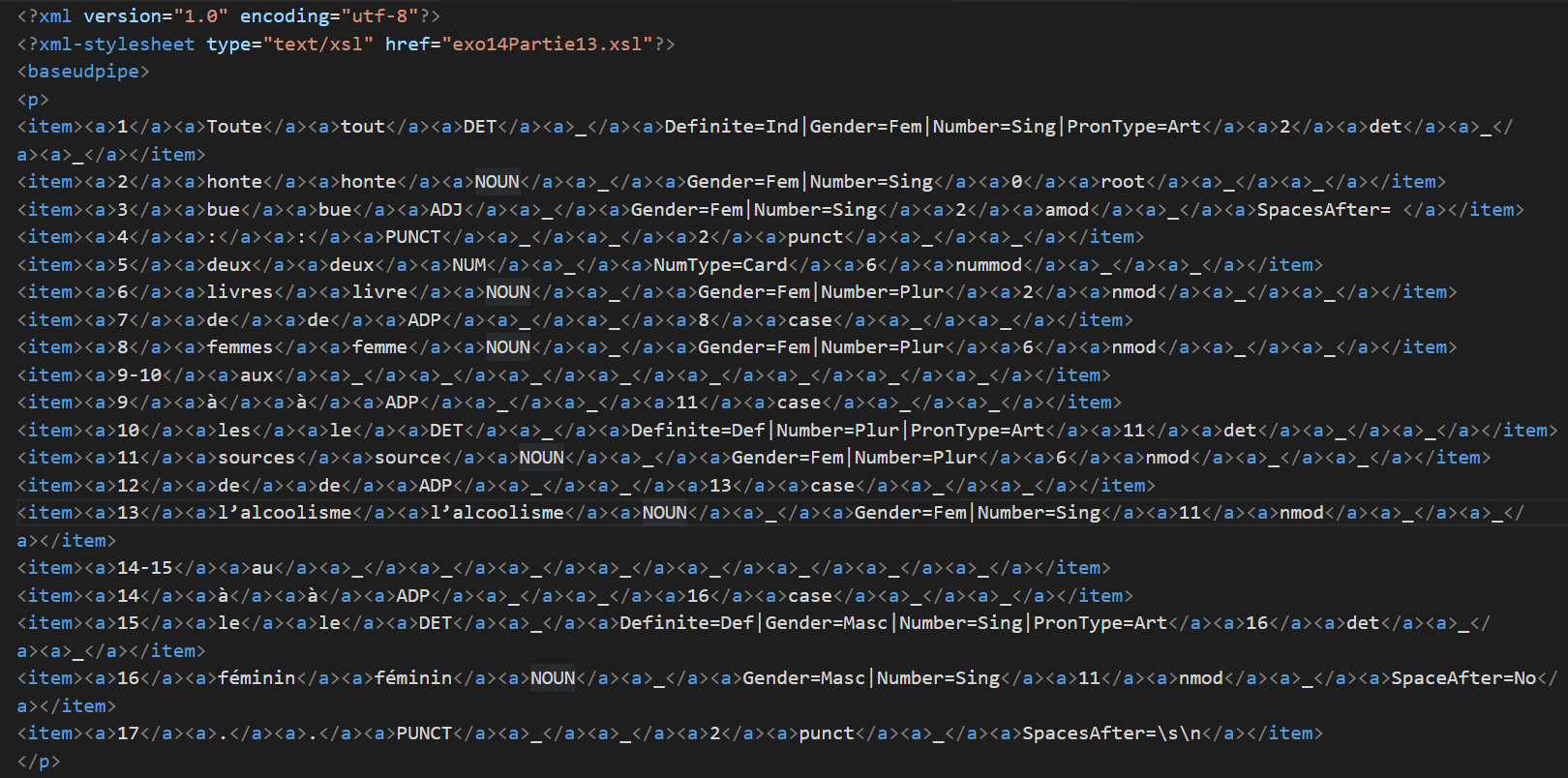
Maintenant que nous avons les fichiers xml contant les informations de relations de dépendance, nous allons pouvoir utiliser un autre script perl pour extraire les type de relations qui nous intéressent.
Le code ci-dessous est commenté. La version téléchargeable : ici.
#!/usr/bin/perl
#----------------------------------------------------------------------------------
# utilisation : perl bao3bisbis.pl corpus_titre-description.udpipe.xml "obj" > relations_obj.txt
# En entrée : sortie UDPIPE formatée en XML + une relation syntaxique
# En sortie la liste triée des couples Gouv,Dep en relation
#----------------------------------------------------------------------------------
use strict;
use utf8;
binmode STDOUT, ':utf8';
#-------------------------------------------------------------------------------------
my $rep="$ARGV[0]"; #le fichier udpipe à traiter (1er argument)
my $relation="$ARGV[1]"; #la relation à extraire (2eme argument)
my %dicoRelation=(); #dictionnaire pour le comptage
#-------------------------------------------------------------------------------------
# on découpe le texte par phrase (liste d'items annotés et potentiellement dépendants)
$/="</p>";
open my $IN ,"<:encoding(utf8)","$ARGV[0]"; #on ouvre le fichier xml à traiter
while (my $phrase=<$IN>) {
# on traite chaque "paragraphe" en le decoupant en "items"
my @LIGNES=split(/\n/,$phrase);
for (my $i=0;$i<=$#LIGNES;$i++) {
# si la ligne lue contient la relation, on ira chercher le dependant puis le gouverneur
if ($LIGNES[$i]=~/<item><a>([^<]+)<\/a><a>([^<]+)<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>([^<]+)<\/a><a>[^<]*$relation[^<]*<\/a><a>[^<]+<\/a><a>[^<]+<\/a><\/item>/i) {
my $posDep=$1; #id du dépendant
my $posGouv=$3; #id du gouverneur
my $formeDep=$2; #forme du mot qui est dépendant
# affichage selon que le gouv soit avant le dependant, soit après
if ($posDep > $posGouv) { #si le dépendant est après le gouverneur
for (my $k=0;$k<$i;$k++) {
if ($LIGNES[$k]=~/<item><a>$posGouv<\/a><a>([^<]+)<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><\/item>/) {
my $formeGouv=$1;
$dicoRelation{"$formeGouv $formeDep"}++; #on ajoute dans le dictionnaire le gouverneur puis lui dépendant
}
}
}
else { #sinon on affiche d'abord le dépendant puis le gouverneur
for (my $k=$i+1;$k<=$#LIGNES;$k++) {
if ($LIGNES[$k]=~/<item><a>$posGouv<\/a><a>([^<]+)<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><a>[^<]+<\/a><\/item>/) {
my $formeGouv=$1;
$dicoRelation{"$formeGouv $formeDep"}++;
}
}
}
}
}
}
close ($IN); #on ferme le fichier
# on print la liste des couples Gouv,Dep et leur fréquence en faisant une boucle dans le dictionnaire
foreach my $relation (sort {$dicoRelation{$b}<=>$dicoRelation{$a}} (keys %dicoRelation)) {
print "$relation\t$dicoRelation{$relation}\n";
}
Voici les fichiers par rubrique en output :
- rubrique à la une : fichier txt contenant le dépendant et le gouverneur (ou vice-versa) en relation "objet".
- rubrique livres : fichier txt contenant le dépendant et le gouverneur (ou vice-versa) en relation "objet".
- rubrique cinema : fichier txt contenant le dépendant et le gouverneur (ou vice-versa) en relation "objet".
Un aperçu du résultat :

Python (patrons)
Le code ci-dessous est commenté. La version téléchargeable : ici.
#!/usr/bin/python3
#utilisation : python3 bao3_alternative.py ./corpus-titre-descriptionbao2.xml NOM PRP NOM PRP > patronT_NPNP.txt
from typing import List
import re
import sys
from pathlib import Path
def extract(corpus_file: str, patron: List[str]) :
buf = ["-"] * len(patron) # * len(patron) --> la liste sera aussi longue que la longueur du patron (on fait autant de "-" que d'éléments dans le patron)
#buf = principe de fenêtre glissante
with open(corpus_file) as corpus : #on ouvre le fichier à traiter
for line in corpus :
buf.pop(0) #on fait glisser la fenêtre
buf.append(line)
#comparaison entre mon buffer et le patron
ok = True
terme = ""
for i, tag in enumerate(patron) : #enumerate : retourne l'indice du i (la position dans la liste)
match = re.match(f'<element><data type="type">{tag}</data><data type="lemma">[^<]+?</data><data type="string">([^<]+?)</data></element>', buf[i]) #on match chaque ligne (le mot donc)
if match :
terme += match.group(1) + f"/{tag} " #group(0) = totalité de la chaîne matché
#on regarde si le pos est le même ou pas
else :
ok = False #terme ne sera donc pas printé
break
if ok : #revient à dire if ok == True
print (terme)
if __name__ == "__main__" :
corpus_file = sys.argv[1] #1er argument : le fichier à lire
patron = sys.argv[2:] #à partir du 2eme argument c'est le patron
extract(corpus_file, patron) #on appelle la fonction extract
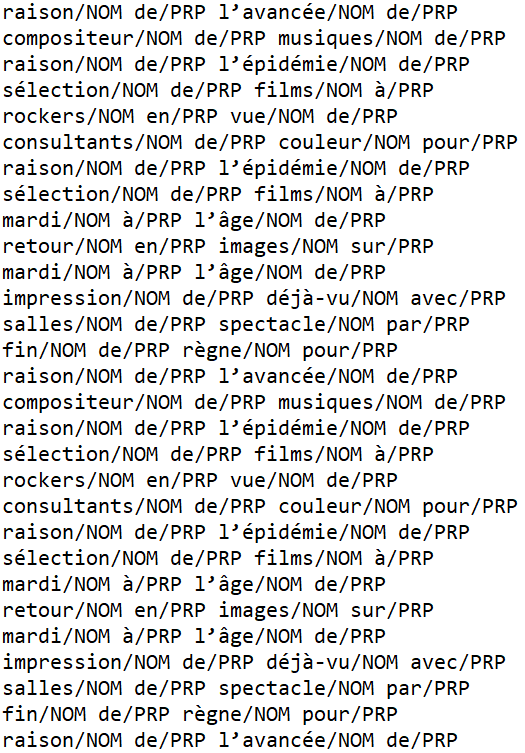
Voici les fichiers par rubrique en output pour le patron NOM PREP NOM PREP :
- rubrique à la une : Patron Treetagger NOM PREP NOM PREP (NOM PRP NOM PRP).
- rubrique livres : Patron Treetagger NOM PREP NOM PREP (NOM PRP NOM PRP).
- rubrique cinema : Patron Treetagger NOM PREP NOM PREP (NOM PRP NOM PRP).
Un aperçu du résultat :
Python (relations de dépendance)
Nous allons aborder ce programme dans la boîte à outil 4 car le programme va aussi nous servir à créer un graphe.