Phase 2: nuages
Nous entrons à présent dans la phase 2 du projet. Après avoir fait le traitement de nos 200 URLs, nous avons obtenu des résultats sous forme de fichiers (dump-text) dans lesquels on retrouve le mot "rêve" et tous ses contextes, extraits des pages que nous avons travaillées.
Nous avons eu recours à divers outils d'analyse de nos résultats. Ce sont des outils qui comptent les occurrences du mot "rêve" et des mots de son contexte (présents dans le fichier). Nous verrons que ces outils renvoient comme résultat différentes représentations que nous allons développer plus loin.
Tagcloud builder
Tout d'abord, nous avons utilisé l'outil Tagcloud Builder, un petit outil gratuit à installer sur Windows, qui fonctionne à partir du Dico de Jean Véronis, un utilitaire pour l'extraction du lexique d'un texte et qui fabrique un nuage de mots faisant apparaître les mots d'un corpus selon leur fréquence.
Voyez plutôt:

On remarque en effet une classification selon le nombre d'occurences de chaque mot. Les mots apparaîssent en ordre alphabétique, plus les mots sont en gros caractères, et plus la couleur approche du orange, plus ils sont fréquents, tandis que plus leur taille est petite et leur couleur claire, plus ils sont rares dans le corpus étudié.
TreeCloud
Nous avons également utilisé Treecloud, programme qui permet de représenter des nuages arborés.
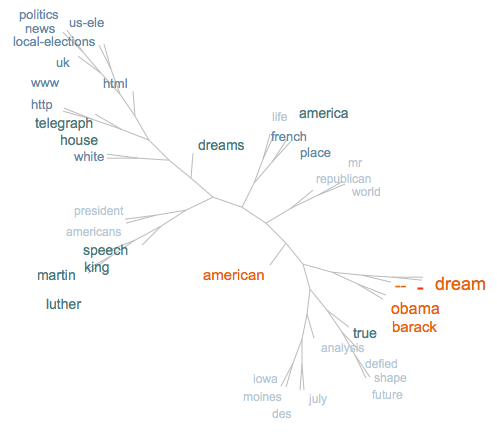
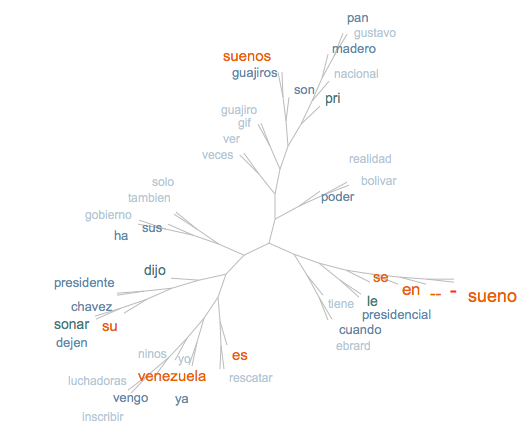
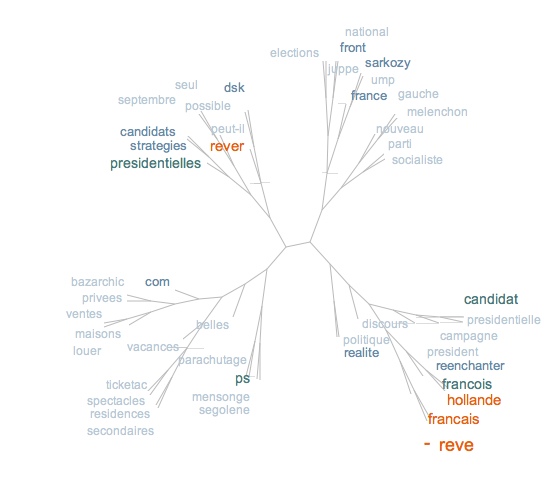
Le nuage arboré est organisé de façon à mettre en évidence les co-occurrences des mots du corpus. Dans l'exemple en français, on trouve rassemblés des mots comme "front", "national", "ump", "parti", "socialiste", "sarkozy", "melenchon", "gauche", ce qui montre une proximité sémantique mise en évidence par le logiciel. De même qu'avec Tagcloud, les mots les plus fréquents apparaissent en plus gros caractères oranges. C'est pourquoi ce nuage arboré nous montre la fréquence, ainsi que la co-occurrence des mots "rêve", "français", "hollande". En effet, sachant que pour les présidentielles, le candidat Hollande parle beaucoup du "rêve français", il n'y a rien d'étonnant à retrouver ce type de représentation pour notre corpus.
Wordle
Nous avons aussi testé notre corpus sur le programme Wordle, où, sur le même principe que précédemment, apparaisent en gros caractères les mots les plus fréquents dans le corpus, et nous avons obtenu les nuages suivants:
Pour l'anglais:
Pour le coréen:
Pour l'espagnol:
Pour le français:




On remarque que le mot "꿈" (accompagné de la particule objet), "rêve" en coréen, est bien mis en évidence. C'est le mot le plus fréquent du corpus coréen.




Ce programme ludique donne encore une représentation de notre corpus selon la fréquence des mots, en effet on retrouve dans ce dernier nuage les co-occurrences de "rêve", "français", "françois", et de "hollande".
Tagxedo
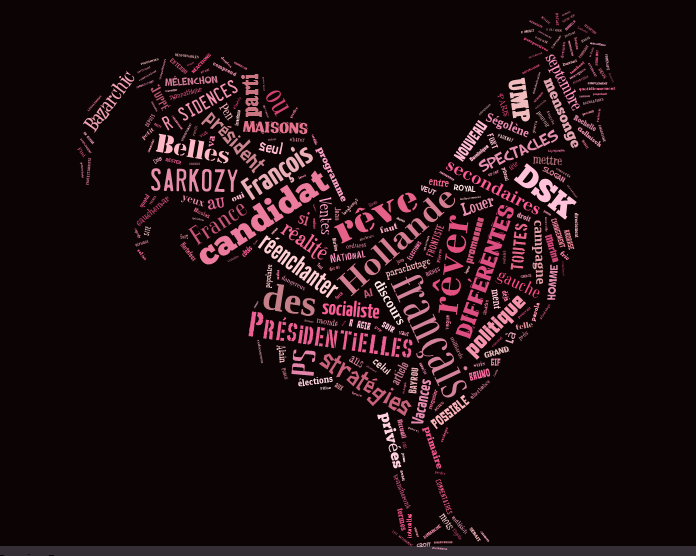
Nous avons aussi travaillé sur un programme de nuage de mots, Tagxedo, qui fonctionne sur le même principe que Wordle:



Le Trameur
Ce projet a également été l'occasion d'utiliser le programme Le Trameur, un outil informatique qui permet entre autres de faire des calculs textométriques à partir d'un corpus transformé en "trame" accompagné d'un "cadre". Il peut donc potentiellement fournir les mêmes informations que les autres programmes cités ci-dessus, c'est-à-dire la fréquence des mots, et une représentation visuelle de cette donnée.
Malencontreusement, il se trouve que nous n'avons pas réussi à obtenir une page xml correcte pour l'affiche du nuage de mots fourni par Le Trameur. Nous avons cependant pu utiliser d'autres fonctions comme la mise au jour des cooccurrents et même des polyoccurrents du mot "rêve" dans notre corpus de contextes français. Voici les résultats:
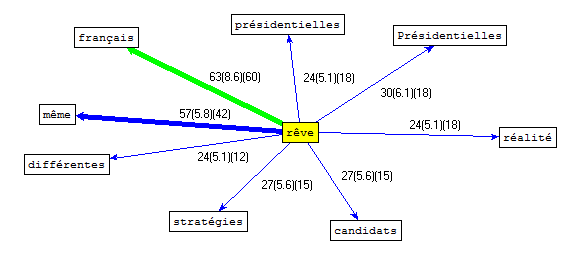
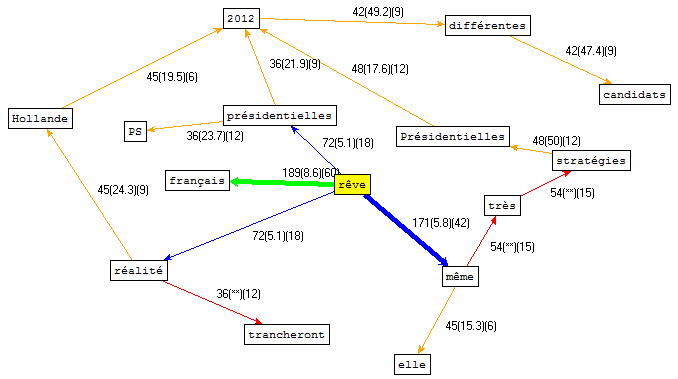
On constate l'importance des adjectifs "français" (lié à François Hollande) et "même" (indiquant soit une unité soit une régularité), très pertinents dans notre thématique politique. Le nuage des polyoccurrents montre en plus un petit cercle rêve-présidentielles-2012-Hollande-PS-réalité qui donne une idée plus précise du thème principal des articles en français.
On note aussi la possibilité d'obtenir les instances d'un patron défini par des expressions régulières. Ici nous avons utilisé le patron: .* NOM .* autour du nom "rêve" pour voir ce qui se trouve avant et après notre mot:
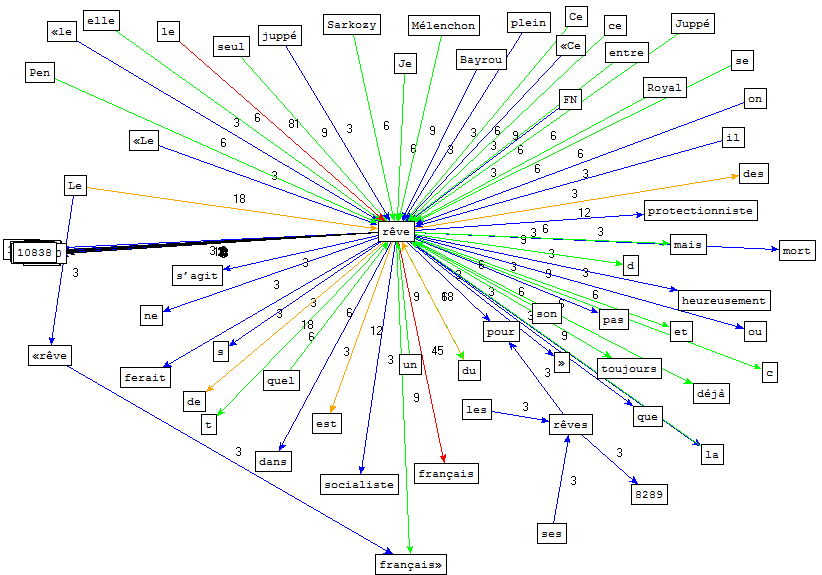
La présence de pronoms personnels sujets et autres syntagmes nominaux ayant des flèches en direction de "rêve" montre que la catégorisation du mot rêve est quelque peu erronée, mais l'analyse reste intéressante. En effet ce schéma nous permet de voir quels sont les sujets récurrents du verbe "rêve" et quels en sont les objets.
Il était également possible de faire des analyses dans d'autres langues que le français, mais il faudrait pour cela fournir au Trameur un corpus en ISO-8859-1 (sauf pour le russe, le bulgare et l'italien qui peuvent disposent d'une table utf-8 pour treetagger).