Plurital Fukushima
A travers ce site nous vous présentons notre projet : élaborer un programme qui permet, grâce à des informations tirées du web, de répondre à notre problématique. La vision du nucléaire a-t-elle changé après la catastrophe de Fukushima ?
Nucléaire : vision d'hier et d'aujourd'hui
Script bash
Script entier
Pour réaliser notre projet, nous avons utilisé le langage de scripts BASH. BASH est une version du shell proposé par le système UNIX, utilisé par les distributions Linux.
Nous avons travaillé avec la distribution UBUNTU 12.04 (différentes versions existent). La version a son importance quant à l'écriture du script. En effet, certaines versions d'UBUNTU
interprètent ou non de la même manière les mêmes commandes. Nous verrons plus bas un cas concret qu'est l'interprétation de la commande 'LET'. Nous allons présenté ici notre script BASH
en y expliquant les différentes étapes et les choix du code utilisé (pourquoi telle commande, telle conditions, ...).
Une petite astuce avant de débuter la lecture dans le cas où les images présentées ci-dessous seraient trop petites pour être lisibles : pour agrandir l'image, appuyer sur la touche "CTRL" puis en même temps, tourner la molette.
Le Commencement
Tout d'abord, nous avons appris à utiliser les différentes commandes essentielles de l'environnement UNIX pour optimiser notre traitement. Nous avons eu recours à de nombreuses commandes (ainsi qu'à leur(s) option(s))
afin de satisfaire nos objectifs. L'énumération serait quelque peu fastidieuse, cependant, vous pouvez y avoir accès en cliquant ICI
ou en allant visiter notre blog où vous trouverez quelques exemples d'utilisation.
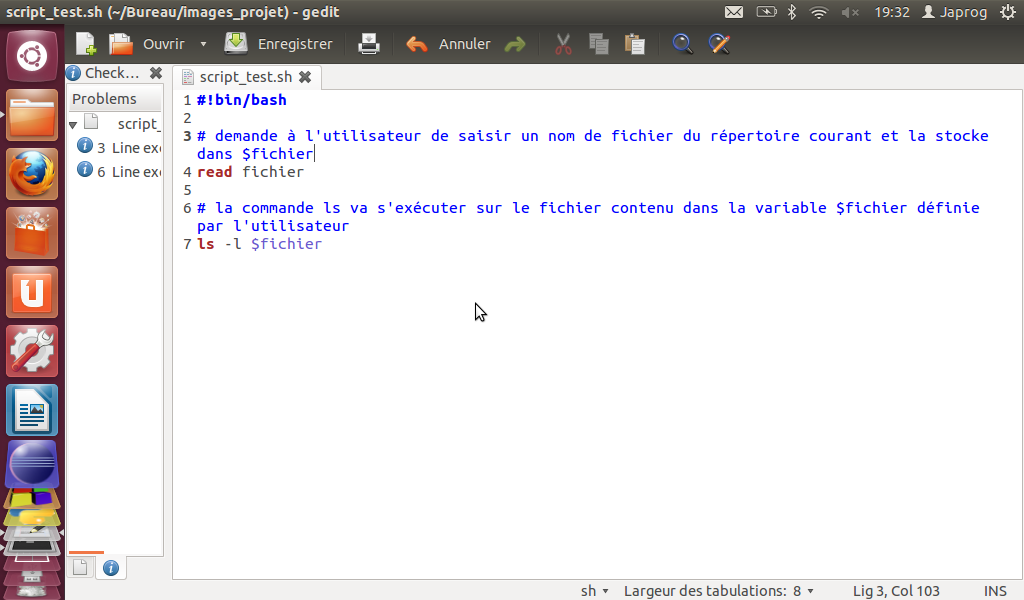
En ce qui concerne les commandes UNIX, il est donc possible d'exécuter ces dernières via un script BASH :
produit le même résultat que :
Problème rencontré :
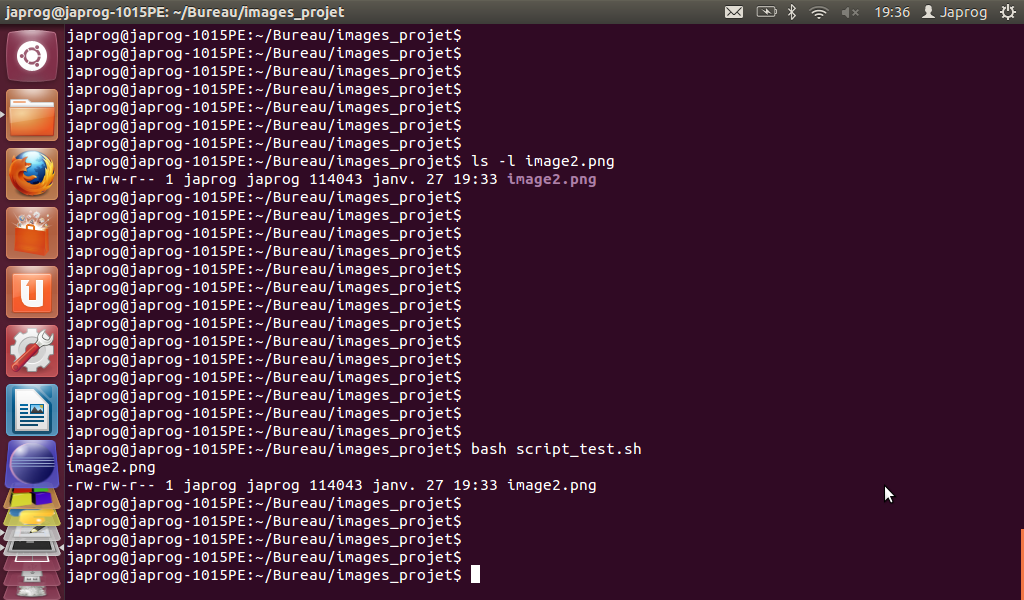
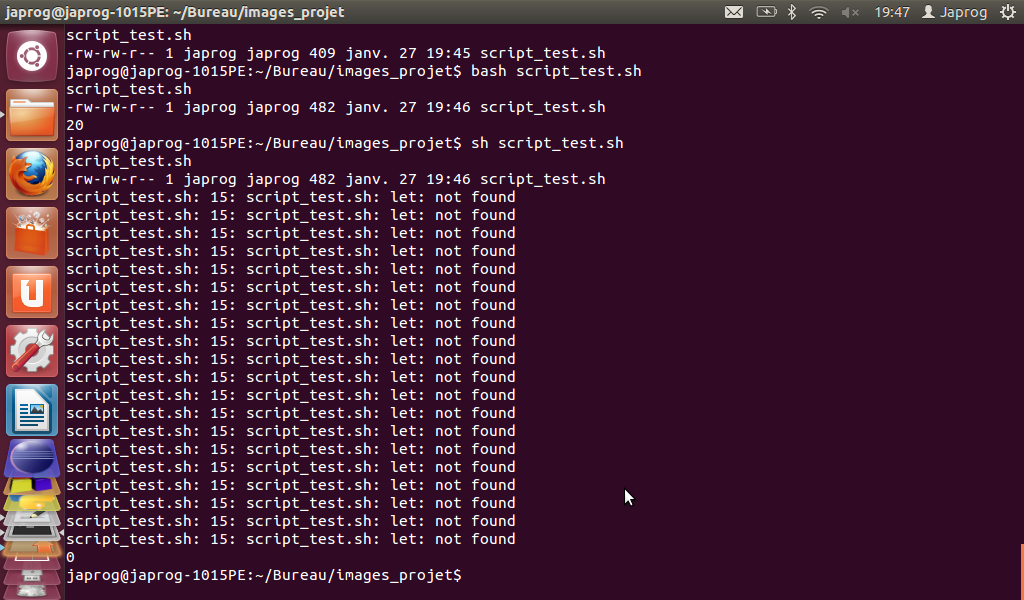
- Lors de nos débuts dans l'apprentissage de ce merveilleux langage, nous avons rencontré quelques problèmes lors de l'exécution d'un script BASH contenant la commande 'LET'.
En effet, en utilisant cette commande avec la version de UBUNTU 12.04 LTS de Linux, si l'on tape dans le shell les lignes suivantes, on rencontre un problème lors de la seconde exécution :
d'après le code source suivant :
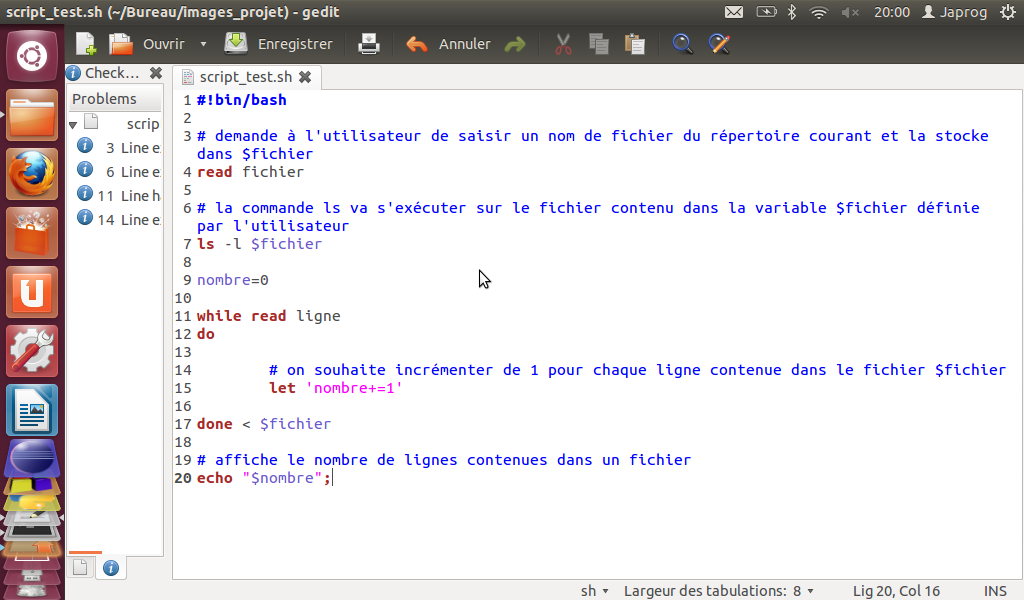
Solution :
Après quelques recherches sur la toile, nous avons appris qu'il fallait taper la commande 'BASH nom_du_script' et non pas simplement 'SH nom_du_script'.
Donc, il faut se renseigner sur la version du shell que l'on utilise ainsi qu'à la version de la distribution de Linux utilisée.
Voilà pour les bases ... Passons à présent à la première phase du projet : l'aspiration ...
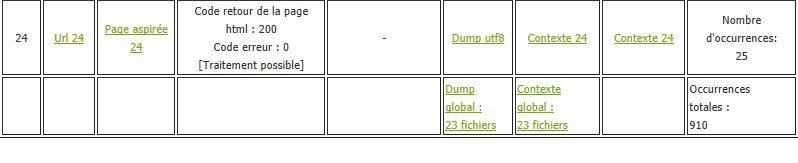
L'objectif du projet est de pouvoir créer un tableau en html comportant plusieurs colonnes : le lien de l'url, le lien de la page aspirée, le lien de la page aspirée dumpée avec le codage initial s'il est différent de l'utf-8, le lien de la page aspirée dumpée et encodée en utf-8 si elle n'y était pas déjà, le lien de la page dumpée contextualisée autour d'un motif recherché via la commande 'egrep',
un lien de la page dumpée contextualisée autour d'un motif recherché via le script minigrep en Perl. Enfin, nous avons mis les liens vers le fichier du dump global et du contexte global pour chaque langue par période qui nous servirons pour la création de nuages de mots et pour un traitement dans le trameur. En bonus, nous avons intégré une colonne avec les retours du code html et d'erreur de la commande 'CURL' pour identifier les
problèmes puis nous avons ajouté une colonne avec le nombre d'occurrences du motif recherché et une case dans le tableau qui compte la totalité des occurrences du motif dans toutes les pages pour une période dans une langue donnée.
Vous pouvez observer une partie du résultat ICI.
d'après le code source suivant :
Solution :
Après quelques recherches sur la toile, nous avons appris qu'il fallait taper la commande 'BASH nom_du_script' et non pas simplement 'SH nom_du_script'.
Les Urls (par période et par langue)
Nous avons choisi de travailler sur deux périodes différentes (avant et après les catastrophes de Fukushima) et cela dans trois langues différentes (français, anglais et japonais). Ainsi, nous avons sélectionné environ une cinquantaine d'urls par langue avec moitié moitié pour chaque période (à peu de choses près). Nous avons créé au préalable (via le script) des dossiers nommés en fonction de la période et de la langue grâce à la première ligne des fichiers d'urls :
Ensuite, nous avons récupéré le nom du tableau en lisant la première ligne du fichier texte contenant les urls (donc cette ligne ne sera pas traitée dans le tableau html).
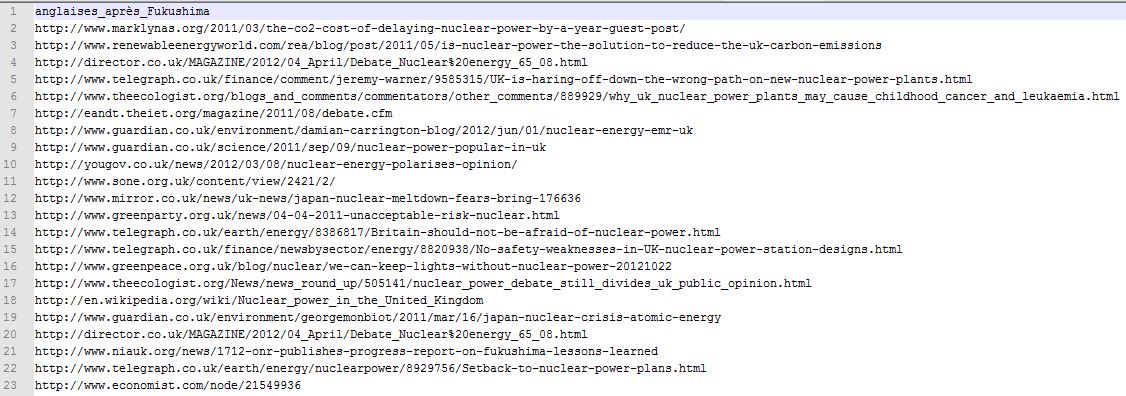
Vous trouverez les informations concernant la création des dossiers et les chemins d'accès aux fichiers sur notre blog (articles du 14/11/2012). Vous y trouverez également des informations préliminaires à la création du tableau.
L'Aspiration
L'aspiration des pages trouvées sur le web va nous permettre de pouvoir travailler en local sur notre machine afin d'éviter d'avoir accès à l'internet de façon permanente et indispensable. Ainsi, nous pouvons travailler avec ces contenus où et quand nous le souhaitons. L'aspiration des pages urls de chaque langue et de périodes différentes constitue la première étape concrète du projet. Grâce à la commande 'CURL' (il est également possible d'utiliser la commande 'WGET' à la place mais moins performante à notre goût; avis personnels...) et à ses nombreuses options bien sympathiques que vous pouvez dès à présent retrouver sur notre blog. Voici un petit aperçu du script portant sur l'aspiration :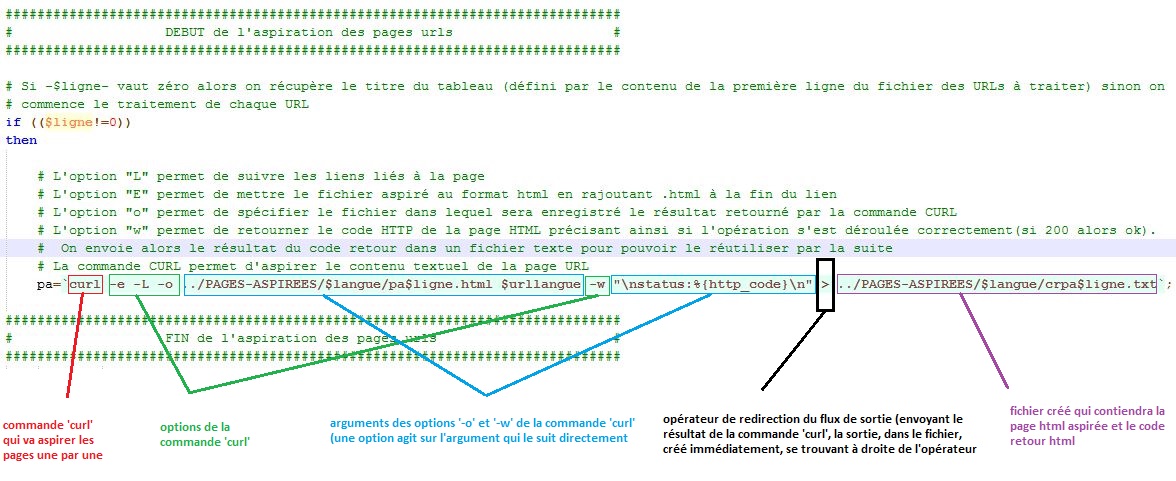
A présent, compte tenu de cette phase d'aspiration, à cette époque, notre tableau comportait 3 colonnes et ressemblait à peu près à ceci :

Une fois l'aspiration effectuée, nous pouvions passé à l'étape suivante mais quelques problèmes sont apparus ... En effet, les codes retour html et curl nous ont permis de constater que certaines pages n'ont pas été traitées correctement.
- Problèmes rencontrés :
- Accès impossible à certaines pages aspirées. On a pu les détecter grâce au code retour html et/ou curl (liste des codes erreur html):
Code html retour 302 : La page existe mais a été déplacé temporairement et son accès est restreint aux membres (par exemple) donc il faut s'inscrire sur le site pour pouvoir la consulter comme certaines pages anglaises pour la période d'après Fukushima (urls 31, 32 et 33).
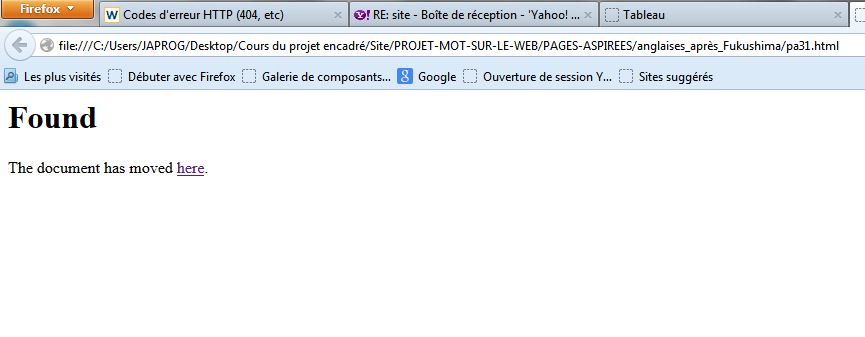
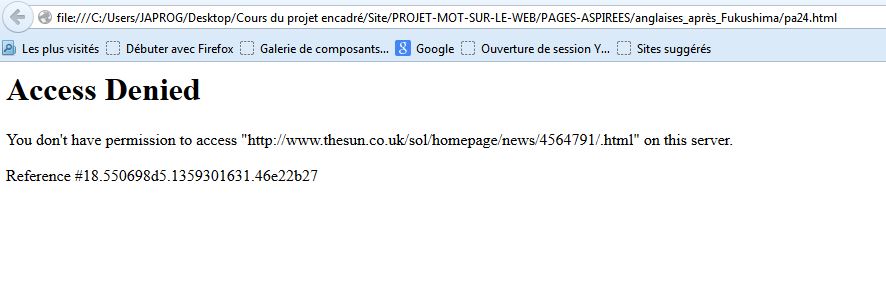
Code html retour 403 : L'accès à la page est refusé car l'internaute n'a pas les droits nécessaires pour accéder aux serveurs comme pour certaines pages anglaises pour la période d'après Fukushima (urls 1 et 24).
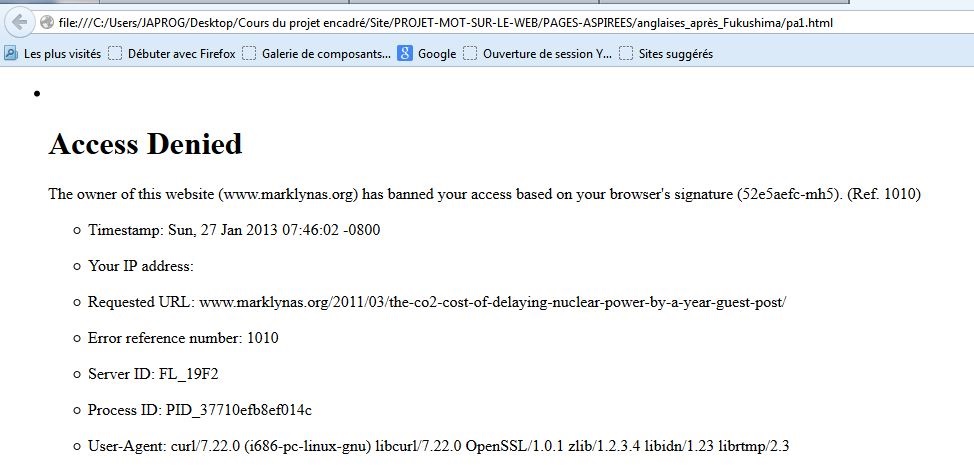
Code html retour 404 : La page correspondante au lien indiqué dans nos fichiers d'urls n'existe plus comme pour une url japonaise pour la période d'après Fukushima (url 14).
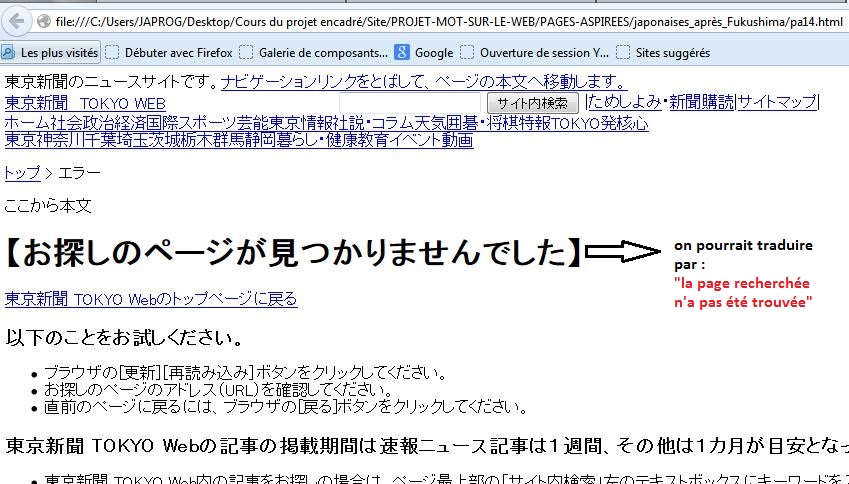
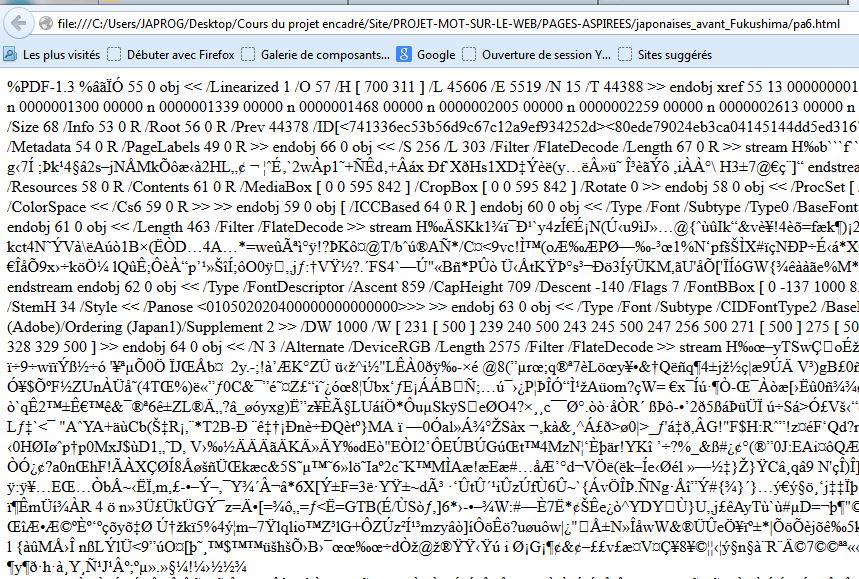
- L'aspiration donne une page contenant des caractères indéchiffrables : L'aspiration a été faite sur une page au format "PDF" (url japonaise d'avant Fukushima, la 6).
Le Dumping
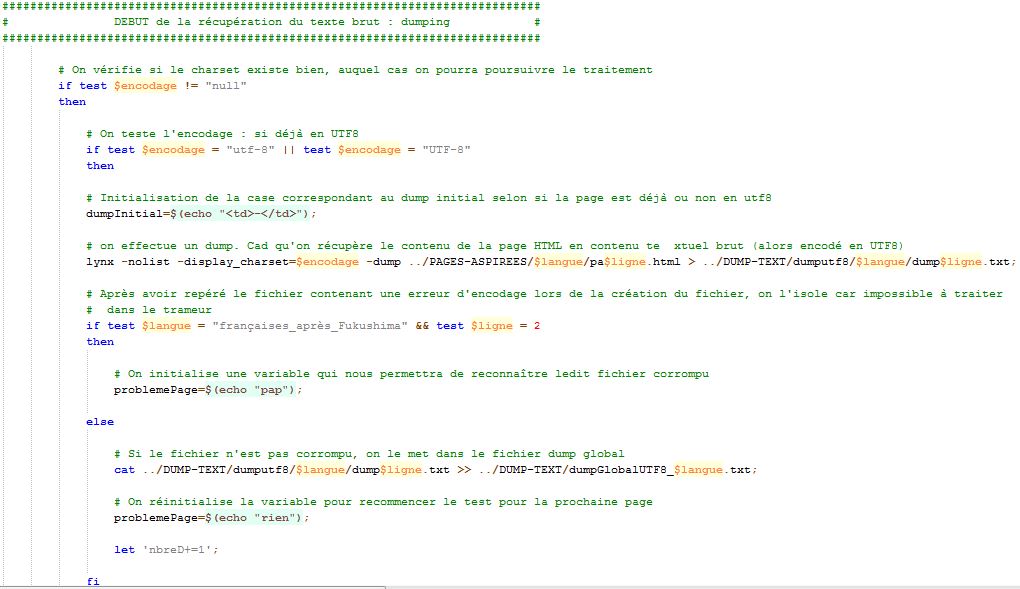
Le dumping va nous permettre de transformer le contenu textuel des pages aspirées en texte brut. C'est-à-dire sans lien, sans image, sans champ textuel, ... mais que du texte. Ainsi, cela va nous permettre de traiter facilement et efficacement les données de ces contenus. En effet, grâce à la commande 'LYNX' et à ses options très puissantes (display_charset, qui définit l'encodage utilisé pour les caractères dans le document; assume_charset, qui va permettre de pallier aux déficiences de l'option précédente et agit à peu près de la même façon; nous verrons plus tard un cas concret). Le principe de cette étape est de tout transformer (si nécessaire) en fichiers textes encodés en utf-8 afin d'éviter les problèmes d'encodage entre les fichiers de langue différentes puis de les concaténer dans un fichier dump global qui nous servira pour les nuages de mots. Grâce à l'utf-8, on va pouvoir traiter toutes ces informations textuelles qu'elles soient françaises, japonaises ou anglaises afin de pouvoir effectuer une analyse sur les résultats obtenus après tous ces traitements et ces mises en formes des données informatiques.Voici la partie du script qui exécute le traitement du dumping. Vous pouvez également retrouvez des informations plus détaillées sur cette phase de traitement sur notre blog.
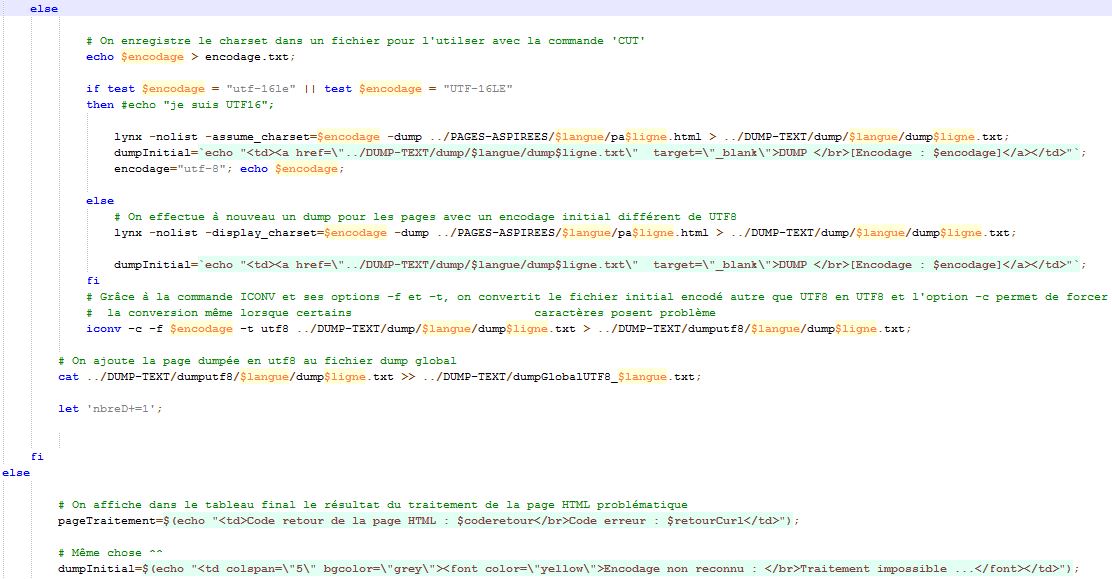

Cette phase de traitement implique l'utilisation de la commande 'ICONV' (avec ses options '-f' (from) et '-t' (to)) qui va (dans la mesure de ses capacités) convertir l'encodage initial, défini par l'option '-f', d'un fichier en un autre défini par l'option '-t'. Cependant, la conversion peut rencontrer des petits soucis comme une "séquence d'échappement non permise à la position ...". En effet, ce message signifie que la conversion s'arrête à cette position et ne se poursuit pas car l'encodage de ce caractère n'est pas convertible ("correctement") par la commande. Mais la magie de l'option '-c' "force" à poursuivre la conversion malgré les caractères "défectueux". Ainsi, on évite de perdre des informations textuelles et cela ne nuit pas au traitement des informations ainsi récupérées. Voici la portion du script qui utilise cette commande :

- Problème rencontré :
- Certaines pages en japonais rencontrent un problème de traitement de certains caractères (dans la page dumpée 1 japonaise d'avant Fukushima, les caractères japonais des chiffres entourés ne sont pas convertibles en utf-8 et la conversion s'arrête même s'il reste des caractères convertibles). Ce problème arrête effectivement l'exécution de la commande 'ICONV' au premier caractère non convertible rencontré.
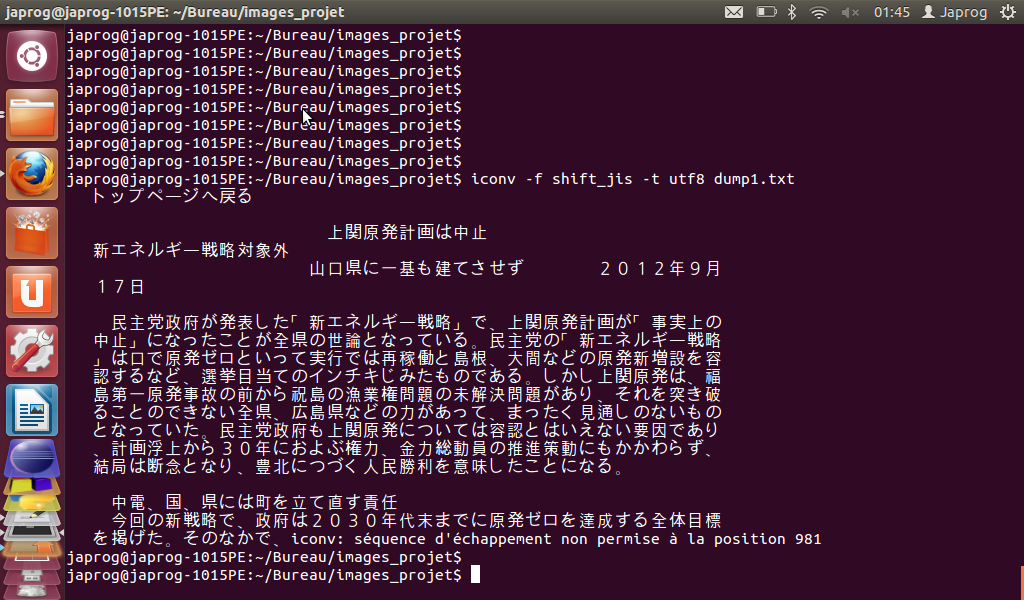
Solution :
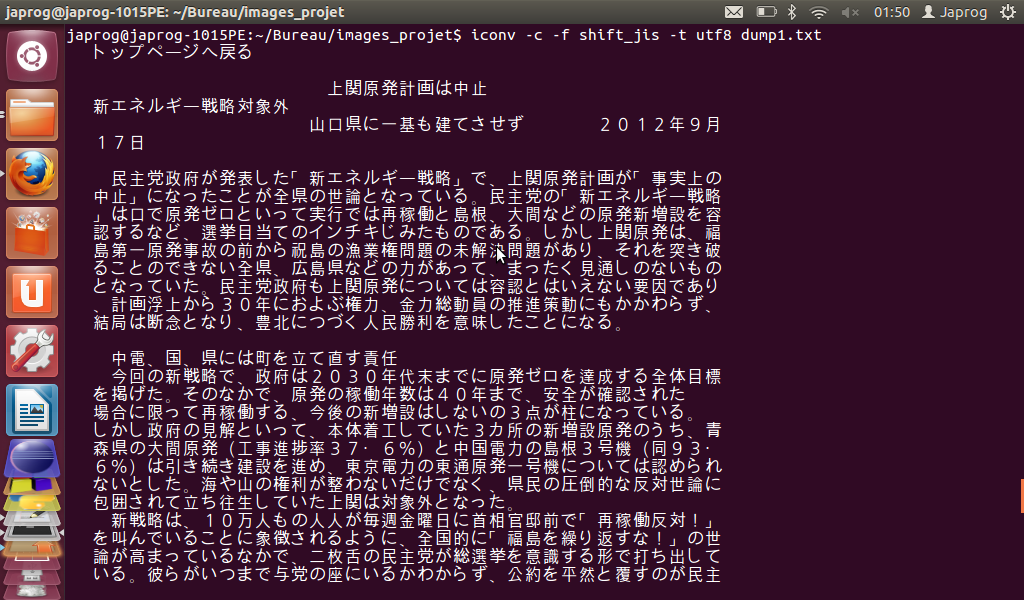
Il suffit d'ajouter l'option '-c' à la commande 'ICONV' pour ignorer les caractères non convertibles et poursuivre alors la conversion des caractères restants.
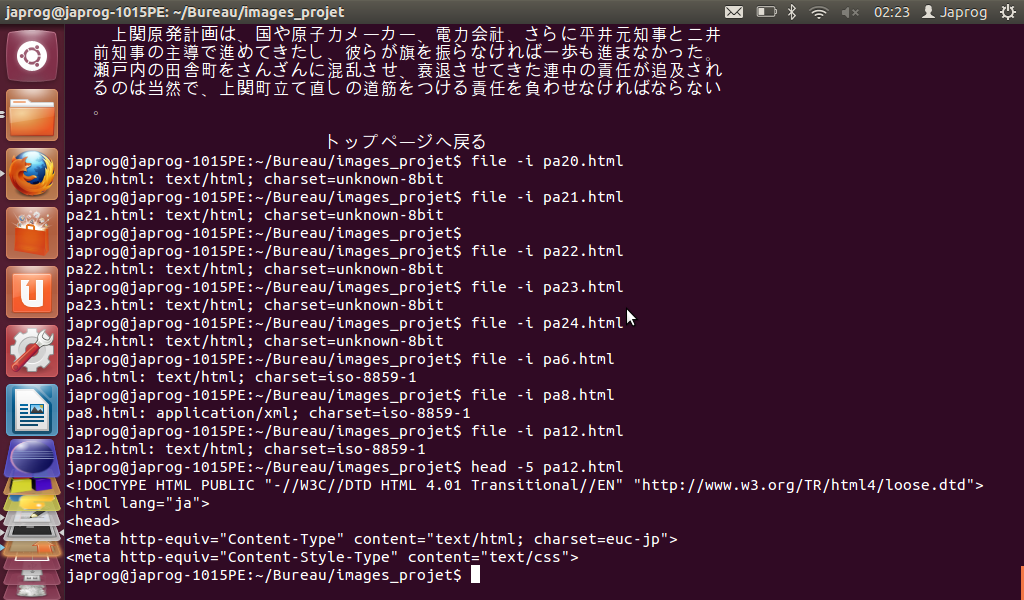
Pour finir, on utilisera la commande "FILE" accompagnée de son option '-i' qui permet d'obtenir l'encodage du fichier sous certaines conditions mais pas toujours très fiable. En effet, cette commande peut afficher l'encodage (ou charset) d'un fichier s'il est reconnu dans la liste des encodages donnée par la commande 'ICONV' avec l'option '-l' (mais ce n'est pas toujours vrai). L'intérêt de cette commande est de pouvoir extraire l'encodage des fichiers dumpés pour savoir s'il sera nécessaire de les convertir en utf-8 plus tard. Cependant, les informations résultant de cette commande sont parfois très étonnantes dans le sens où elles sont totalement incohérentes ... En effet, il nous est arrivé que cette commande nous renvoie un charset inconnu (unknown 8-bit) alors que l'encodage défini dans la balise 'META' de la page html est du latin 1 (iso-8859-1), qui est bien reconnu par 'ICONV' et donc devrait être une information qui pourrait être traitée par 'FILE -i'. Il nous est aussi arrivé d'obtenir un résutat tel qu'un encodage latin 1 pour une page en japonais (encodées la plupart du temps en shift_jis ou euc-jp). Voici un aperçu :
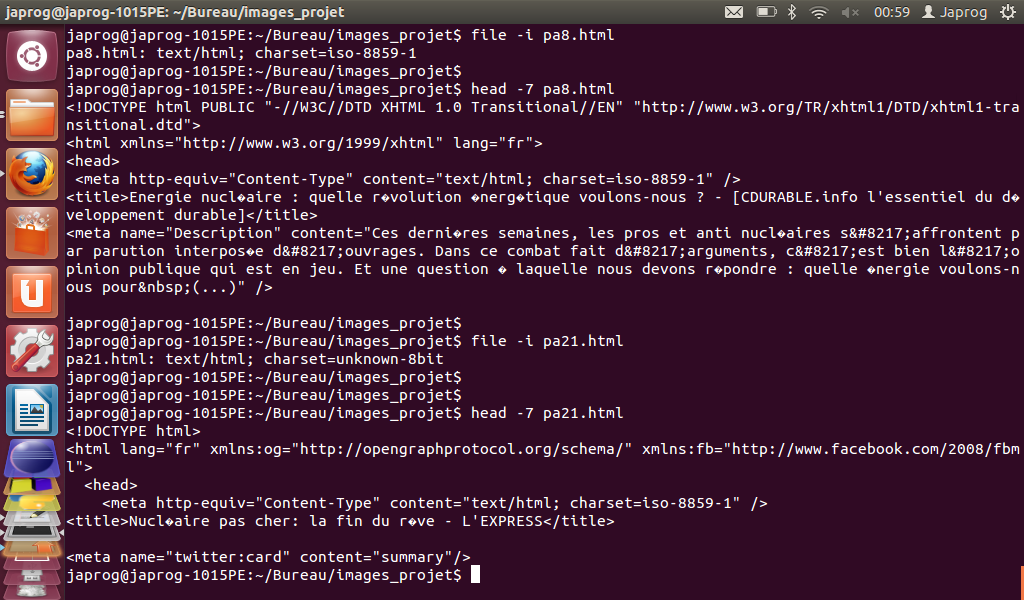
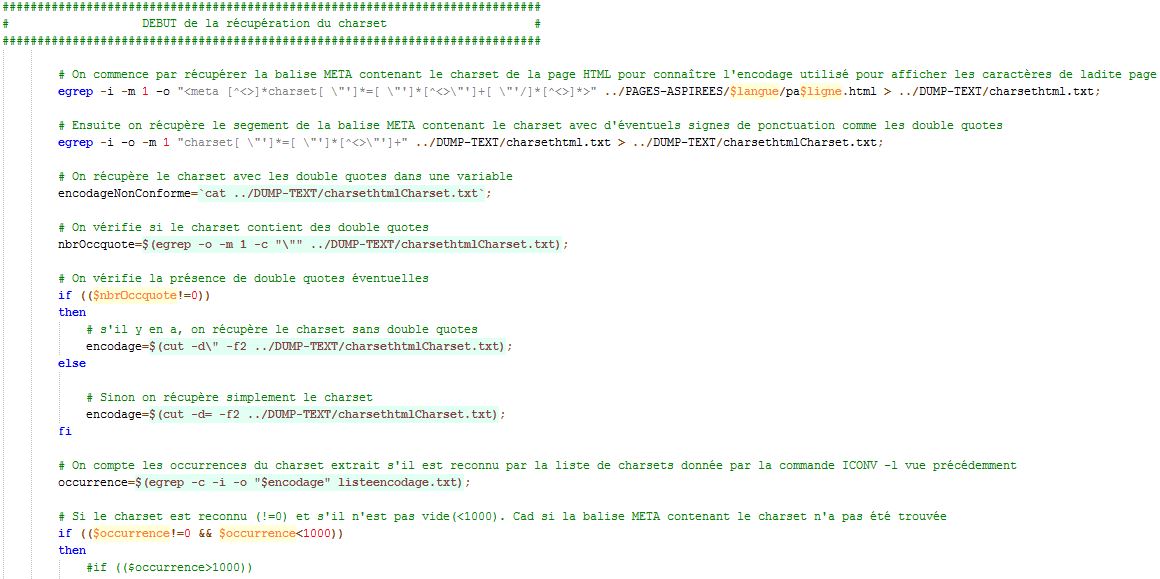
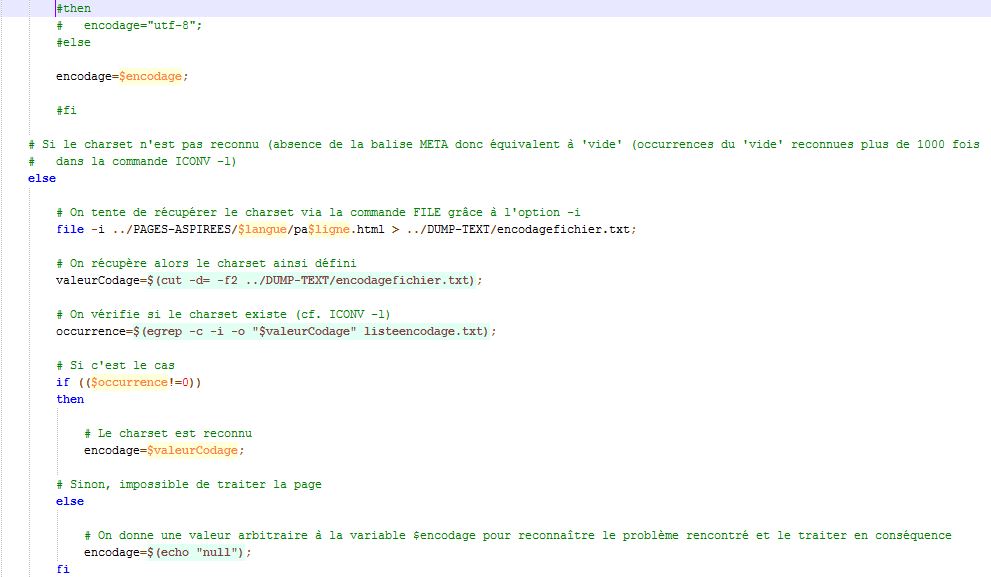
Solution :
Utiliser la commande 'EGREP' pour effectuer une recherche et une extraction de charset dans les pages html via une balise 'META' et tout ça grâce aux fabuleuses expressions régulières (pour les détails concernant la description des opérateurs utilisés dans les expressions régulières suivantes, se reporter à notre blog :

Informations utiles :
L'option '-i' sert à ne pas respecter la casse (majuscule/minuscule), l'option '-o' indique que le résultat de la recherche doit correspondre uniquement au motif recherché (sans affichage avant ni après le motif) puis l'option '-m 1' signifie que l'on veut comme résultat uniquement la première occurrence correspondant au motif recherché.
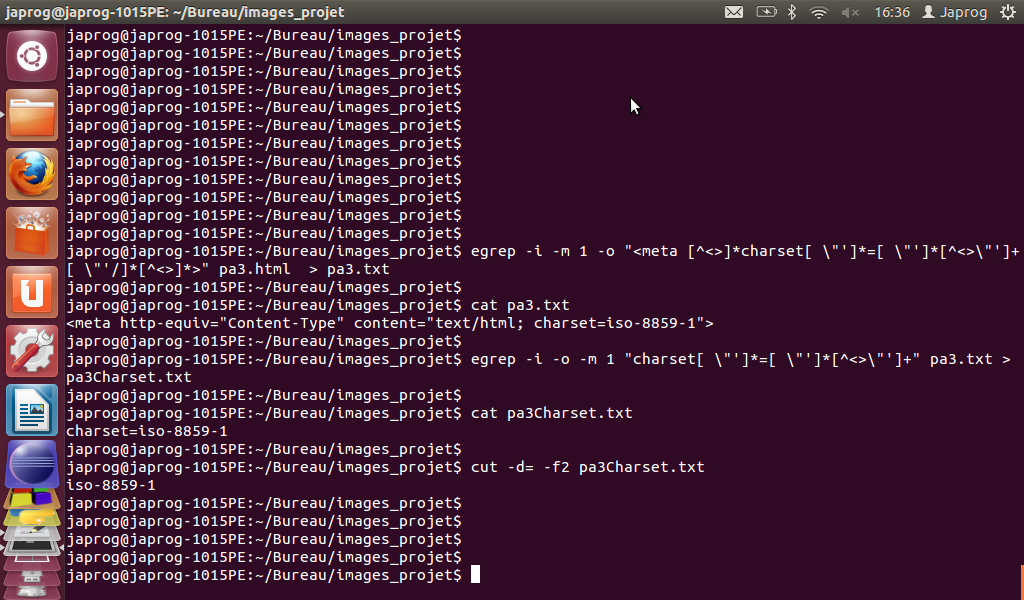
Cependant, il faut rester vigilant quant à cette extraction. En effet, la configuration de la balise 'META' définissant le charset varie en fonction de la norme html utilisée. Voici un exemple visuel de la manipulation pour la norme html 4 :
Et en voici une pour la norme html 5 :
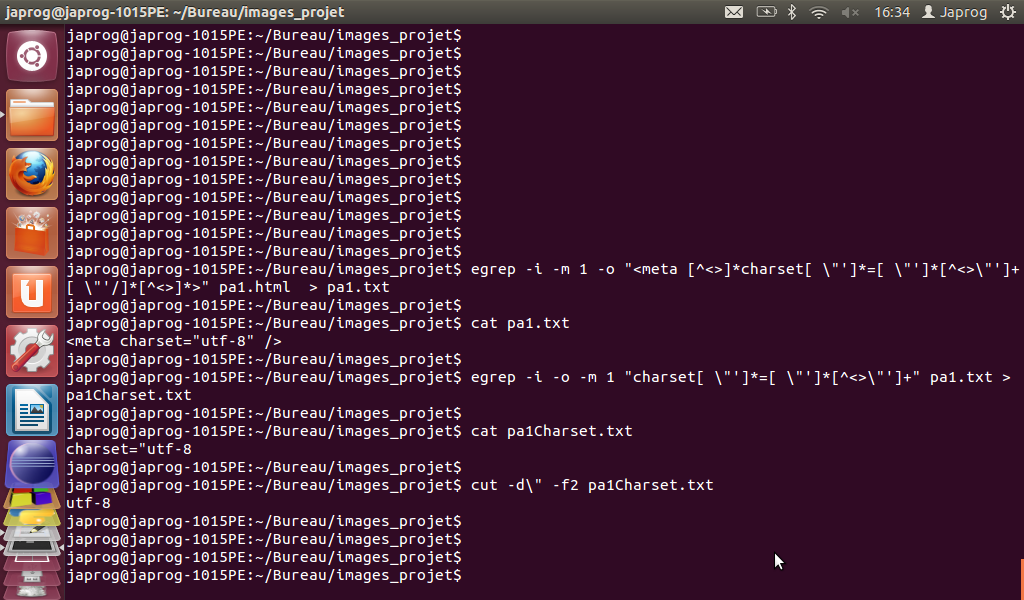
Cependant ... problèmes ! Et oui, là encore un petit souci (à s'en cogner la tête contre les murs...).
- Problème rencontré :
- Malgré la puissance de ces expressions régulières, la commande 'EGREP' ne gère pas (ou très difficilement) les caractères de contrôle (ou caractères non imprimables). En effet, l'url française 14 avant Fukushima n'a pas pu être traitée dans nos analyses via le trameur et les nuages car malgré le fait que son fichier html associé possède bien une balise 'META' définissant le charset (utf-8), ni la recherche via la commande 'EGREP'
(le problème vient du fait que le début de cette balise - "<meta" - et le reste de la balise - "http-equiv="content-type" content="text/html; charset=UTF-8" />" - se trouvent sur deux lignes différentes séparées par un saut de ligne) ni celle via la commande 'FILE -i' (qui renvoie le résultat "unknown-8bit")
ne nous donnent de résultat :
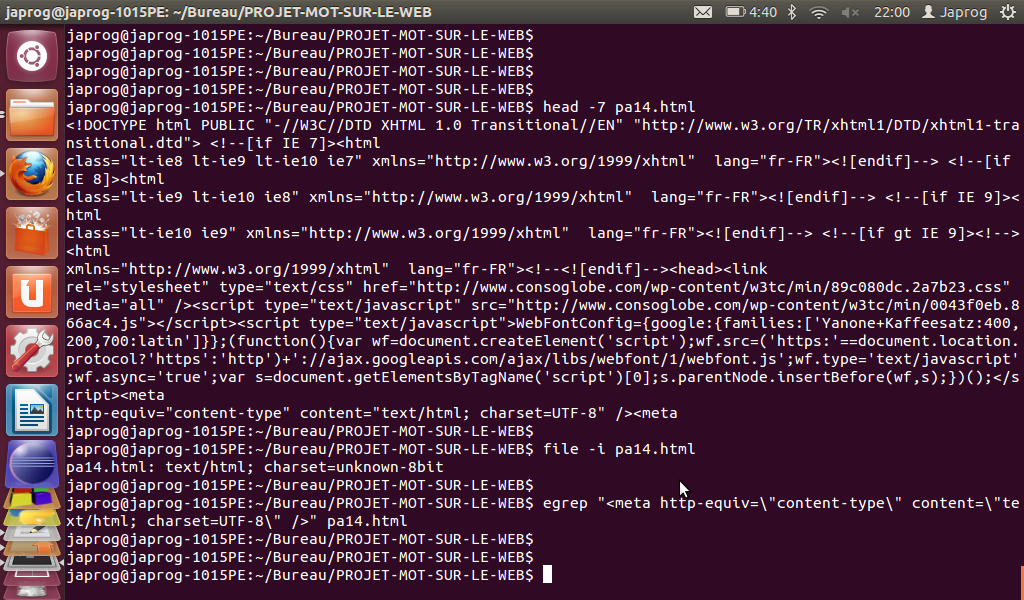
Voici maintenant le code source avec les fins de ligne (ou sauts de ligne) qui sont représentés par "LF" (représentation des fins de ligne sous les systèmes Linux) et la balise 'META' sur deux lignes (fin de la 3 et 4) :

Solution :
Il suffirait d'isoler ce fichier en ajoutant une condition supplémentaire au script (si url = française avant Fukushima n°14 alors charset=utf-8).
A présent, compte tenu de cette phase de dumping, à cette époque, notre tableau comportait 6 colonnes et ressemblait à peu près à ceci :
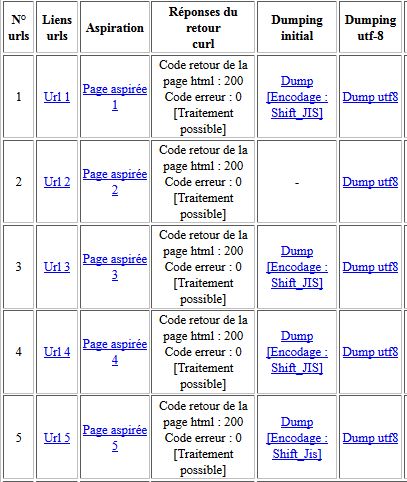
Une fois le dumping effectué, nous pouvions passé à l'étape suivante mais quelques problèmes sont (à nouveau) apparus ... En effet, des problèmes de format d'encodage nous ont quelques peu donner du fil à retordre. Comme par exemple le cas de l'encodage d'une page en utf-16le ("le" pour Little Endian; plus d'information ICI).
- Problème rencontré :
- L'encodage utilisé par une certaine page en japonais (url 25 pour la période avant Fukushima) a été encodée en utf-16le (alors que le charset défini dans une balise 'META' du code source de cette page est 'SHIFT_JIS'). Or, la commande 'LYNX' ne traite pas cet encodage via l'option '-display_charset' :
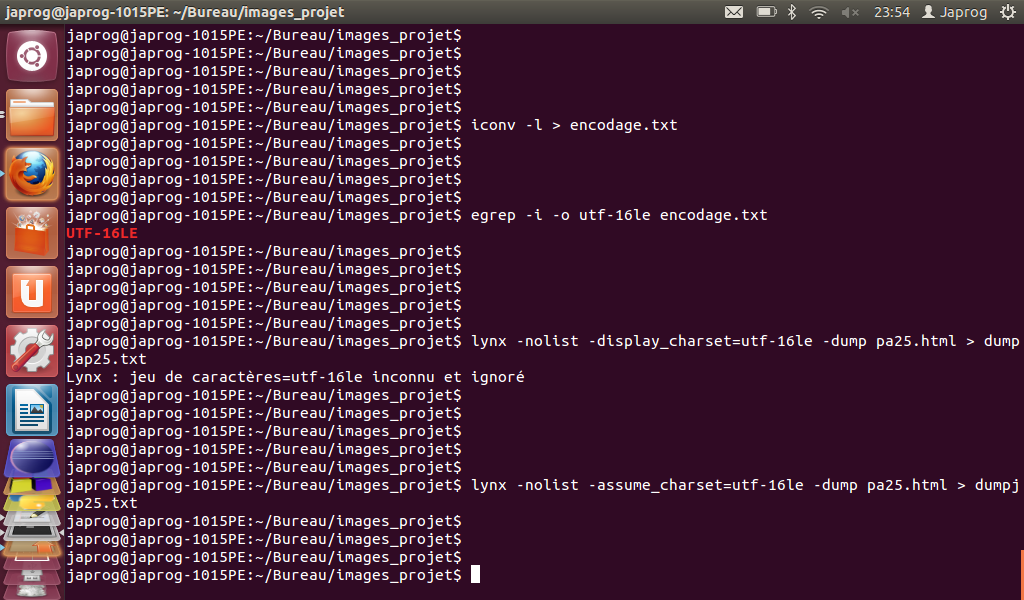
Solution :
Utiliser l'option '-assume_charset' à la place de '-display_charset'. Ainsi, il n'y aura plus d'erreur dans le traitement de la page et on pourra alors traiter le fichier problématique pour notre analyse.
La Contextualisation
Cette phase a tout d'abord besoin d'un motif, d'une forme, pour définir un domaine d'analyse. Ainsi, nous avons utilisé le fichier texte contenant le motif utilisé pour le script Perl afin d'en extraire que le motif (ici "原子力"):
puis l'extraction :

La mise en contexte du motif recherché dans chacune de nos pages par période et par langue a pu se faire grâce à la commande 'EGREP' qui nous a permis d'effectuer une recherche d'un motif (ou mot) via son option '-w' qui permet de rechercher les lignes dans lesquelles apparaissent le mot recherché. Ensuite, l'option '-i' permet de rechercher toutes les occurrences de ce motif sans tenir compte de la casse (majuscule/minuscule). Pour finir, l'option '-c' va nous permettre de compter le nombre d'occurrences du motif recherché, ce qui nous servira pour la colonne bonus "motif recherché" (affichant le nombre d'occurrence du motif pour chaque fichier selon la période et la langue).
Voici un aperçu de la portion du script portant sur cette étape :
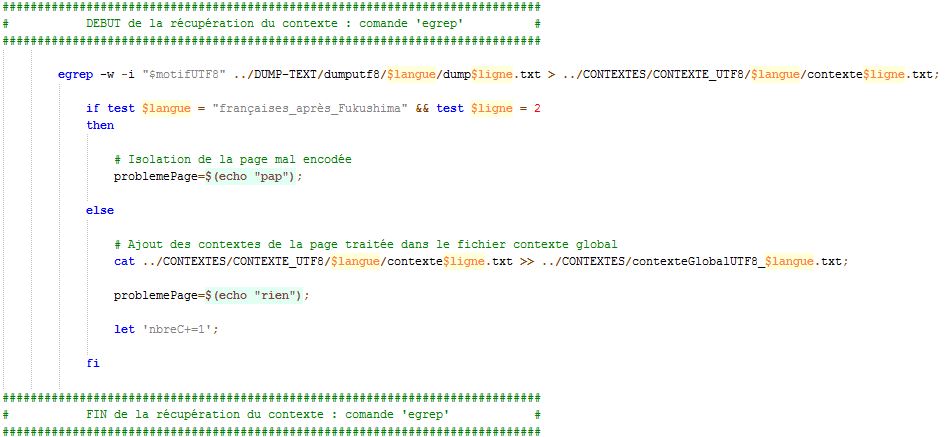
Ainsi, grâce à cette commande, on a pu récupérer les différents contextes pour le motif recherché pour chaque période et pour chaque langue. Enfin, ces contextes seront concaténés (mis bout à bout) dans un seul et unique fichier contexte global pour le réutiliser lors de son traitement ultérieur pour le "trameur et arbres contextuels".
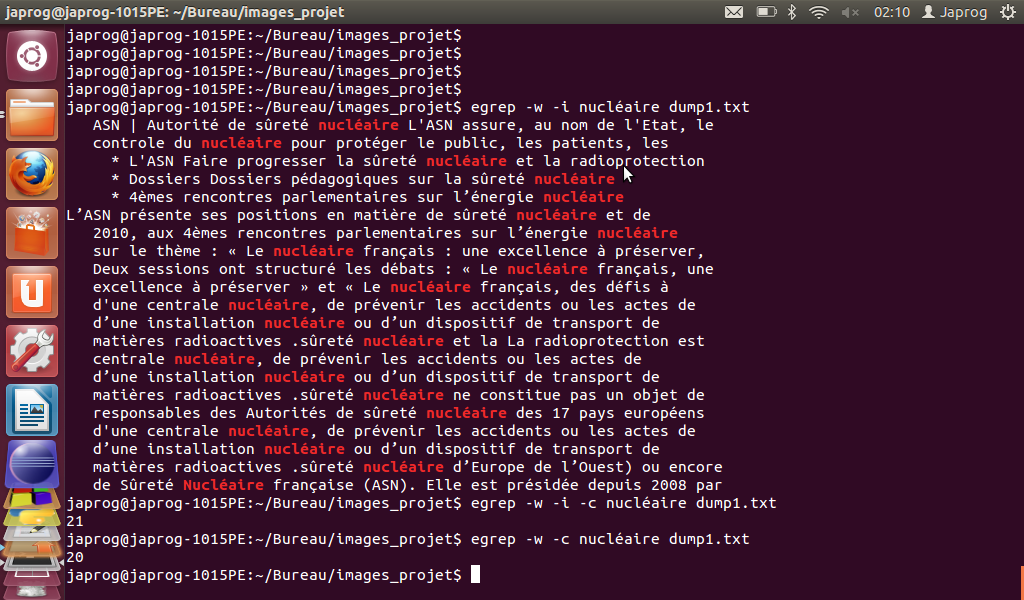
Voici un petit exemple d'utilisation de la commande "EGREP" :
Ensuite, nous avons utilisé un script Perl (minigrep-multilingue) pour extraire les contextes avec une mise en forme dans une page html par page contextualisée. Vous pouvez retrouver toutes les informations concernant cette étape (bis) ICI et sur notre blog. C'est grâce à ce script que nous avons pu identifier d'où provenait l'erreur (voir un peu plus bas).
A présent, compte tenu de cette phase de contextualisation, à cette époque, notre tableau comportait 8 colonnes et ressemblait à peu près à ceci :
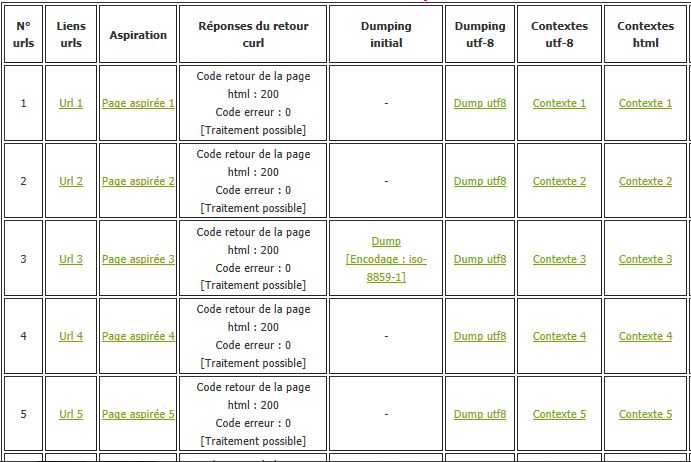
Une fois la contextualisation effectuée, nous pouvions passer à l'étape suivante mais, pour changer un peu, quelques problèmes sont (une fois de plus) apparus ...
- Problème rencontré :
- En effet, un problème dans l'encodage d'un fichier nous a posé quelques difficultés car lors de sa création, il y a eu des erreurs dans l'encodage (url française 2 après Fukushima).
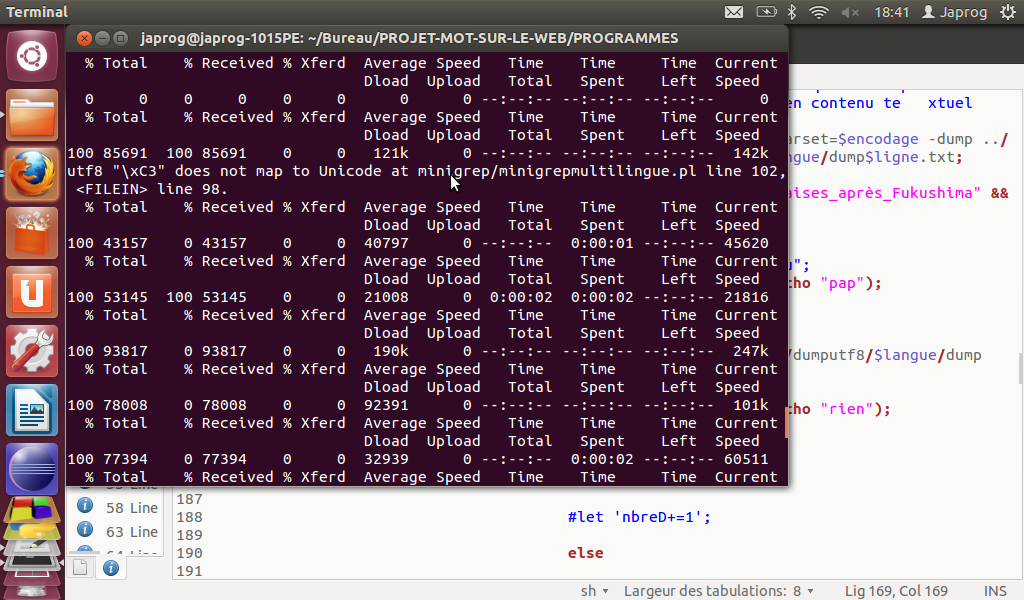
Solution :
Ne pas l'inclure dans les fichiers dump global et contexte global (sinon inutilisable pour le trameur) car l'erreur ne peut être traitée à notre niveau : l'erreur remonte lors de la création du fichier html.
Les Bonus
Nous avons ajouté une colonne avec le nombre d'occurrences du motif recherché dans chacune des pages puis à la fin du tableau, une case est dédiée au nombre total d'occurrences de ce motif pour chaque période et pour chaque langue. Puis nous avons également intégré deux cases contenant le nombre de fichiers "dump en utf-8" concaténés et la même chose pour les fichiers "contexte (en utf-8)" (ceux créés lors du traitement avec la commande 'EGREP') :
Pour voir le résultat final, cliquez ici.