Plurital Fukushima
A travers ce site nous vous présentons notre projet : élaborer un programme qui permet, grâce à des informations tirées du web, de répondre à notre problématique. La vision du nucléaire a-t-elle changé après la catastrophe de Fukushima ?
Nucléaire : vision d'hier et d'aujourd'hui
Un nuage de mots c'est quoi?
Selon Wikipédia :
"Le nuage de mots-clefs (tag cloud en anglais)
est une représentation visuelle des mots-clés (tags)les plus
utilisés sur un site web. Généralement, les mots s'affichent dans
des polices de caractères d'autant plus grandes qu'ils sont utilisés
ou populaires."
Ces nuages vont permettre de répondre graphiquement à notre
problématique. Les mots les plus gros seront ceux qui apparaissent
logiquement le plus souvent dans le contexte de "nucléaire". Les
nuages nous donneront une idée de l'évolution des collocations du
mot nucléaire dans la période avant-après Fukushima.
Dans cette partie nous vous présentons 4 outils qui permettent de
présenter visuellement des résultats mais de manière différente :
Nuages : Outils en ligne
Nous avons testé pour vous Wordle et Tagxedo.
Dans les logiciels en ligne, nous insérons les fichiers contextes
globaux.
Premier essai : les contextes anglais avec
Tagxedo
Avant Fukushima

Après Fukushima

Vue dynamique
Deuxième essai : les contextes français
avec Wordle :
Avant Fukushima

Après Fukushima

Troisième essai : les contextes japonais
avec Tagxedo
Avant Fukushima

Après Fukushima

Remarques générales :
On remarque que ces outils ne prennent pas en compte les mots de la
même famille. "sortie" et "sortir" par exemple sont comptés comme
deux mots différents alors qu'ils ont le même lexème. Il aurait été
intéressant de les regrouper ensemble pour obtenir une fréquence
plus élevée.
Le constat est le même pour les mots avec et sans apostrophe :
Exemple : "énergie" et "lénergie".
Egalement pour les signes : Exemple : "UK" et "United"
"Kingdom"
Retour sur Wordle
Wordle est très facile à utiliser. Il suffit de coller son texte
dans l'espace prévu à cet effet ou taper une adresse URL dans la
barre juste en dessous. Une fois le texte transmis, Wordle affiche
un nuage de mots. Il est possible de changer la couleur, le sens
d'écriture etc. Tout ce qui est attrait au design. Le plus
intéressant est l'option l'onglet Language. Dedans nous trouvons
plusieurs options utiles :
Exemple : les pronoms, les déterminants, les modaux en anglais...
Ils ne sont pas pertinents pour l'analyse et au contraire, parasitent les résultats car leur fréquence est très élevée.
Retour sur Tagxedo
En plus des deux moyens que proposent Wordle pour soumettre du texte, Tagxedo en met un troisième à disposition. Nous avons la possibilité de télécharger un fichier texte de notre ordinateur. Point de vue design, Tagxedo propose un choix beaucoup plus large que Wordle. Nous nous intéressons maintenant à ses options.
Dans le menu Option Word, Tagxedo donne la possibilté d'ignorer la ponctuation, les nombres, les mots communs et les mots outils.
De plus, aspect non négligeable, Tagxedo propose d'analyser les caractères non Latins. Nous travaillons sur du japonais donc cette option est pour nous indispensable. Le découpage opéré par Tagxedo pour le japonais peut d'ailleurs paraître surprenant. En effet, s'il reconnaît très bien les composés sino-japonais (noms composés de caractères chinois), on observe quelques couacs avec des mots comme enerugî (dérivé de l'anglais et écrit en katakana エネルギー) : il distingue enerugî seul de enerugî to et no enerugî (to et no étant des particules grammaticales). Il aurait été plus judicieux de laisser de côté ces particules pour augmenter la fréquence de enerugî, d'autant que Tagxedo a prouvé être capable de distinguer les particules puisqu'il nous a fallu supprimer du nuage manuellement les cinq grandes particules du japonais (no, o, ni, wa, ga) dont les fréquences étaient très élevées. De plus, on remarque que Tagxedo fait le choix de regrouper des expressions composées telles que とはされないどころか (towa sarenai dokoro ka), ou encore をめぐってどんなことがあったでしょう (o megutte donna koto ga atta deshô), qui se compose par exemple d'une particule objet (o, qui est censé marqué comme objet ce qui le précède), d'un verbe (meguru sous sa forme suspensive megutte), d'un groupe nominal (donna koto), d'une particule sujet (ga) et d'un autre verbe (aru sous sa forme accomplie atta + deshô). Il n'y a aucun caractère chinois dans cette séquence, et il semble que Tagxedo soit un peu "perdu" pour distinguer les particules des verbes et des noms, ce qui donne comme résultat ce genre de formation un peu maladroite.
Tree Cloud
Tree
Cloud est un outil 2 en 1. Il combine les fonctions d'un nuage
de mots avec le principe d'un arbre
phylogénétique. Cette association permet de visualiser la
thématique d'un texte de deux façons:
Cet outil utilise Python et SplitsTree. Pour plus d'explications, un tour sur le blog de J. Véronis où il expose dans un article son premier nuage arboré.
Tree Cloud : Philippe Gambette, Jean Véronis : Visualising a Text with a Tree Cloud, IFCS'09 (matériel supplémentaire).
A nous de jouer !
Nous avons testé cet outil avec les fichiers Dumps et Contextes globaux français après Fukushima.
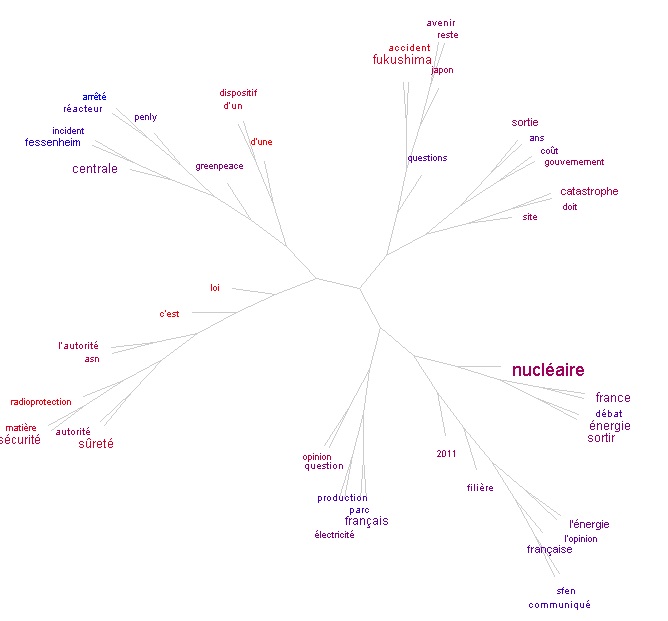
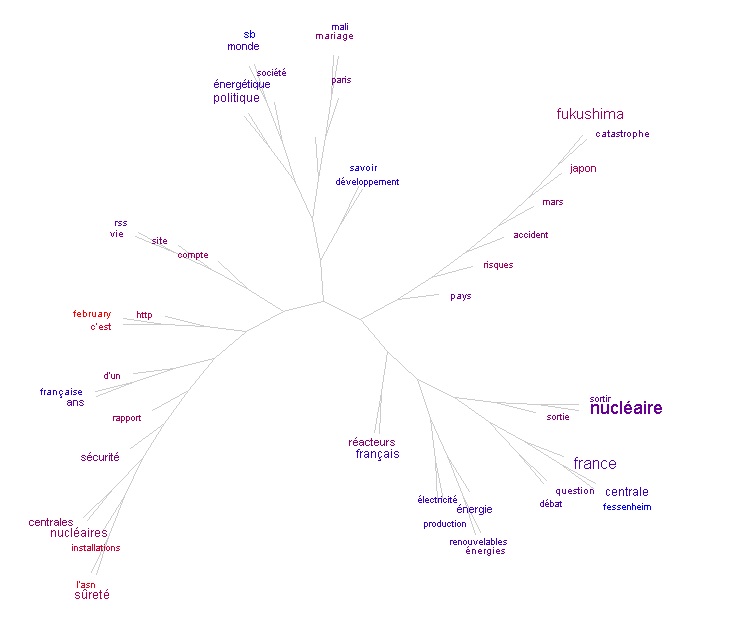
Première chose à noter : TreeCloud possède un anti-dictionnaire français et anglais. Cet anti-dictionnaire répertorie globalement les mots-outils car ils n'ont aucune pertinence sémantique. TreeCloud peut ainsi les neutraliser en utilisant cette liste. Le résultat n'est pas parfait masi très satisfaisant.
Deuxième constat : le nuage arboré du fichier Dumps contient des branches qui sont inexistantes dans le nuage arboré du fichier Contextes. Ces deux petites branches situées sur la gauche contiennent des mots du champ lexical du site web "rss", "site", "compte", "http", "february" (sûrment pour les archives).
Cette représentation en arbre phylogénétique permet de comprendre que ces mots sont souvent utilisés ensemble. Ces mots ne sont pas utlisés dans les articles de presse mais dans la page web en général. C'est pourquoi ils apparaissent dans le nuage arboré des Dumps et pas dans celui des Contextes. En effet, dans le fichier Contexte global, on retrouve les contextes de notre mot-clé qui ont tous probablement été extraits de l'article. Par conséquent ce fichier ne contiendrait pas de mots utilisés uniquement en dehors de l'article.
Troisième constat : même remarque que pour les outils en ligne, ce sont les mots qui sont pris en compte et non les lexèmes. (exemple : "question" et "questions", "énergétique" et "énergie"). Il en est de même pour la remarque sur les apostrophes.
Tag Cloud Builder
Voici un autre outil qui permet de visualiser le thème d'un texte
: Tag
Cloud Builder. Les mots les plus fréquents sont mis
en avant par leur couleur et leur taille. Ce programme a été élaboré
par P. Gambette. Vous retrouverez ici
sa page dédiée à cet outil.
Principe : dans cet utilitaire, on charge un fichier au format txt
et encodé en iso-8859-1 qui contient une liste de mots avec leur
fréquence. Le fichier se présente sous cette forme :
Forme Fréquence
NUCLEAR 299
POWER 296
STATIONS 42
ENERGY 16
L'espace entre le mot et sa fréquence est une tabulation. Il est
possible d'obtenir automatique cette liste mot-fréquence avec
l'outil dico
de J. Véronis. L'avantage de cet outil c'est qu'on peut utiliser un
anti-dictionnaire. Nous avons rajouté l'anti-dictionnaire de
l'anglais fourni dans TreeCloud à l'anti-dictionnaire français inclu
dans l'outil dico. Nous avons ainsi traité les fichier anglais avant
Fukushima DumpsGlobaux et ContextesGlobaux.
Voici ce que nous obtenons :
Fichier Contexte anglais avant Fukushima
1600 1600mw 2008 2010 2020 21st accept accustomed ahead ailing alternative announce answer attempt bad belleville blazes blow britain brown build building built buried called carbon case century change china clean clean' climate coalition construction costly dangerous dangers debate economic electricity emissions energy environment existing fact favour fears feed feel france future gas generate generation global government governments green greenpeace hear includes industry money nuclear opposing opposition option outweigh people photograph plans plant plants power produce produces public reactors reality renewable renewables risks role rss snp solution source station stations support turbines uk viable warming waste wind world wrong year
C:\Users\Asceline\Desktop\contexteGlobalUTF8_anglaises_avant_Fukushima-dic.TXT
Ce nuage de mots a été construit par le logiciel Freecorp
TagCloud Builder.
Le code HTML et donc le style du nuage sont copiés du Nébuloscope
de Jean Véronis
Fichier Dump anglais avant Fukushima
ã article baby blog britain british business carbon change click climate close coal comments contact content cookies cost costs don' earth edinburgh electricity email emissions energy environment features feed find fuel future gas generation global government green greenpeace guardian health home i' industry january jobs life light london low mail money news nuclear offers oil party people plant plants policy politics power price public radiation reactors read renewable renewables report reviews rss science scotland search share show site solar sponlink sport star stations stories technology terms top transport travel tv twitter uk view warming waste we' wind work world year
C:\Users\Asceline\Desktop\PROJET\dumpGlobalUTF8_anglaises_avant_Fukushima-dic.TXT
Ce nuage de mots a été construit par le logiciel Freecorp
TagCloud Builder.
Le code HTML et donc le style du nuage sont copiés du Nébuloscope
de Jean Véronis
Noux constatons que les deux nuages sont différents. Encore une fois
le fichier Dump contient des informations en "trop". Il faudrait
trouver un moyen de neutraliser le lexique typique des sites web de
presse comme "email", "search", "click", "news". Une solution serait
d'ajouter ce lexique à l'anti-dictionnaire mais nous n'avons pas les
moyens pour le moment de le déterminer.
Le problème de la flexion des mots n'est pas non plus résolue dans
cet utilitaire (exemple : "plant" et "plants")
1600 1600mw 2008 2010 2020 21st accept accustomed ahead ailing alternative announce answer attempt bad belleville blazes blow britain brown build building built buried called carbon case century change china clean clean' climate coalition construction costly dangerous dangers debate economic electricity emissions energy environment existing fact favour fears feed feel france future gas generate generation global government governments green greenpeace hear includes industry money nuclear opposing opposition option outweigh people photograph plans plant plants power produce produces public reactors reality renewable renewables risks role rss snp solution source station stations support turbines uk viable warming waste wind world wrong year
C:\Users\Asceline\Desktop\contexteGlobalUTF8_anglaises_avant_Fukushima-dic.TXTCe nuage de mots a été construit par le logiciel Freecorp TagCloud Builder.
Le code HTML et donc le style du nuage sont copiés du Nébuloscope de Jean Véronis
ã article baby blog britain british business carbon change click climate close coal comments contact content cookies cost costs don' earth edinburgh electricity email emissions energy environment features feed find fuel future gas generation global government green greenpeace guardian health home i' industry january jobs life light london low mail money news nuclear offers oil party people plant plants policy politics power price public radiation reactors read renewable renewables report reviews rss science scotland search share show site solar sponlink sport star stations stories technology terms top transport travel tv twitter uk view warming waste we' wind work world year
C:\Users\Asceline\Desktop\PROJET\dumpGlobalUTF8_anglaises_avant_Fukushima-dic.TXTCe nuage de mots a été construit par le logiciel Freecorp TagCloud Builder.
Le code HTML et donc le style du nuage sont copiés du Nébuloscope de Jean Véronis
Le Trameur
Le Trameur est un logiciel de textométrie qui va nous permettre de faire apparaître dans un graph les cooccurrents d'une forme-pôle donnée (ici en jaune). La documentation de ce logiciel est disponible ici (chapitre 18 pour le paramétrage des cooccurrents). Nous avons tout d'abord utilisé les fichiers de contexte en bloquant chaque contexte avec le caractère #. Nous avons appliqué un seuil minimum afin d'obtenir davantage de résultats. Le Trameur applique des couleurs et des épaisseurs distinctes aux flèches qui relient les cooccurrents au pôle selon leur spécificité et le nombre de contextes associés. La légende, ainsi que le seuil et la co-fréquence choisis, sont visibles au dessus de chaque graphe.
Fichier français avant Fukushima

Fichier français après Fukushima

Fichier anglais avant Fukushima

Fichier anglais après Fukushima

Puis nous avons utilisé les fichiers dump, avec comme seul délimiteur le point. Les contextes étant donc plus larges, nous avons augmenté le seuil à 5.
Fichier français avant Fukushima

(Le Trameur refuse de prendre en charge le fichier
dump français après Fukushima, qui n'est pourtant pas erroné)

Fichier anglais avant Fukushima

Fichier anglais après Fukushima