Bilan
Pour mener à bien ce projet, nous avons rencontré diverses difficultés1. Installation de Linux
Pour avoir le système Linux sur notre ordinateur sous Windows, nous avons installé le logiciel Oracle VirtualBox.Or, nous avons rencontré quelques problèmes après l’installation : fonctionnement lent, détection d’USB port, transmission de fichier ou de répertoire de Windows à Ubuntu.
Après avoir mis à jour vers la dernière version d’Oracle VirtualBox, nous avons pu détecter la clé USB sous Ubuntu en séparant les ports d’USB en deux systèmes. C’est-à-dire, un port utilisé uniquement sous Windows et l’autre sous Ubuntu.
Pourtant, transmettre des fichiers de Windows reste toujours un rêve.
2. Nuage de mot
Wordle ne marche pas pour les caractères asiatiques. Il ne traite que les langues en ISO-8859, donc, c’est plutôt un problème de codage car dans le résultat on voit des carrés à la place des mots chinois. Tagul, il ne traite pas les langues en caractères comme ceux du chinois ou du japonais, ceux que nous traitons dans notre projet.Worditout, il est impossible de choisir de supprimer les mots vides, donc, dans le résultat, ce n’est pas le mot « écriture » en chinois qui apparaît le plus gros.
WordSift pour avoir le nuage de mot en japonais, nous avons trouvé beaucoup de mots anglais dans le résultat, parce que dans les contextes, nous avons aussi des mots anglais. En plus, on ne peut pas les supprimer avec les options de Wordsift. Donc, le résultat nous plaît moins que celui de Taxgedo en chinois et en japonais. En revanche, Tagexdo ne traite pas le hindi, tout cela est en suspens…
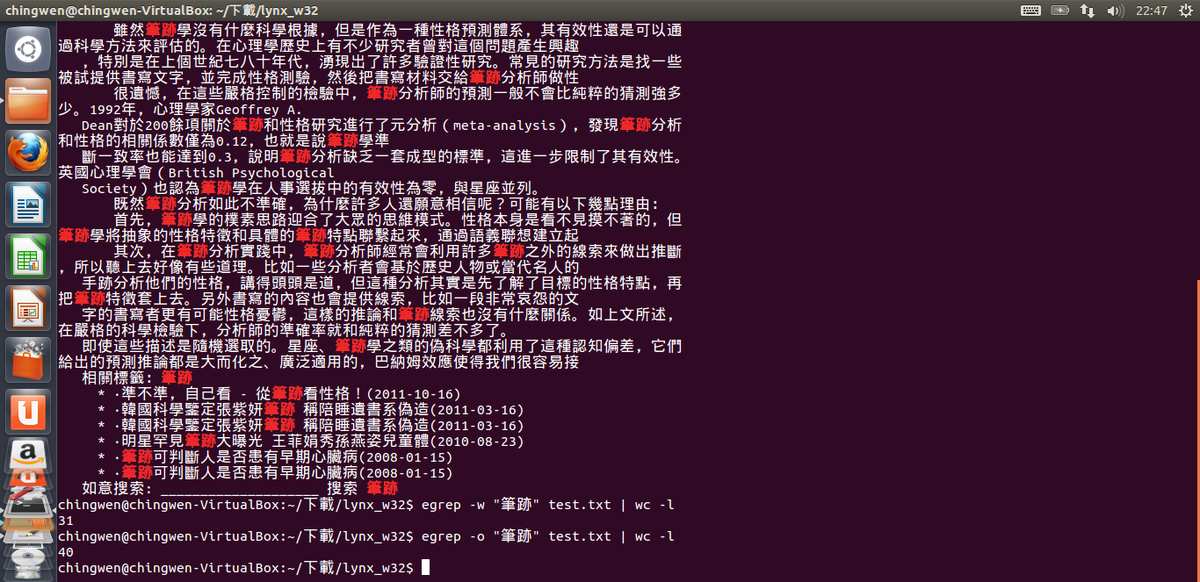
3. Egrep
Pour chercher les mots clés en chinois, au début, nous ne savions que chercher un mot à la fois. Mais nous avons trouvé la solution : taper manuellement le pipe ‘|’ chaque fois après un mot chinois dans le script ; au lieu de faire copier-coller ou glisser. En plus, pour chercher et compter correctement l’équivalent de « écriture » en chinois, nous avons changé la syntaxe dans le script pour traiter le chinois.La voici : nbOccur = $(egrep -o "$motif"../DUMP-TEXT/$i-utf8.txt | sort | uniq -c) à la place de nbOccur =`egrep -o -i "\b$motif\b"../DUMP-TEXT/$i-utf8.txt | wc -l` pour le français et l’anglais.
En plus, on obtient un résultat différent en utilisant egrep – w et – o. Après interrogation du professeur, l’explication est trouvée : avec – w, on compte simplement le mot même si le motif apparaît plusieurs fois dans une ligne, il ne compte qu’une fois. Tandis qu’avec – o, cela compte le nombre des occurrences, donc à chaque fois que le motif apparaît, il est compté. Ainsi, les résultats avec – o et – w sont différents.
Sur Mac, egrep veut bien accepter l’option –i (sans souci de la casse) et l’option –o (les occurrences) mais refuse catégoriquement de faire –io. Il a donc fallu faire un pipe de plus pour transformer les minuscules en majuscules, seule forme reconnue par iconv.
4. BIG-5
Premièrement, File ne détecte pas Big-5 (chinois traditionnel) donc, nous ne pouvons pas lui indiquer de convertir en UTF-8.Au début, dans le tableau obtenu après avoir exécuté notre programme, File affichait ISO-8859-1 à la pace de BIG-5, ce qui n’est pas l’encodage réel du fichier. Si File ne trouve rien dans la zone des caractères accentués, il considère automatiquement que c’est du ISO-8859-1. Ainsi, nous n’avons rien eu de lisible dans le dump texte. Pour résoudre ce problème, nous avons modifié le script en ajoutant une partie de traitement pour chercher uniquement BIG-5. S’il le trouve, le programme le convertit en UTF-8 puis cherche le motif. Donc, pour traiter le chinois, nous avons écrit 3 étapes dans le script : 1. Si c’est en UTF-8, on continue. 2. Si c’est BIG-5, on le convertit en UTF-8, puis continue le processus. 3. Si c’est un autre codage, on le convertit en UTF-8 aussi, puis on continue.
5. Wikipédia
Les pages de Wikipédia ne s'aspirent pas correctement et on récupère un fichier vide dans la page aspirée.Il faudrait donc lui réserver un traitement spécial.
Liens :
- Notre Blog par Florence, Ching Wen et Bonnee Li
- TAL par Serge Fleury, Jean-Michel Daube et Rachid Belmouhoud
- Tout sur les Encodages par Jean-François Perrot
- Manuel Linux
- Initiation Perl
- ZenGarden pour les styles et placements CSS