|
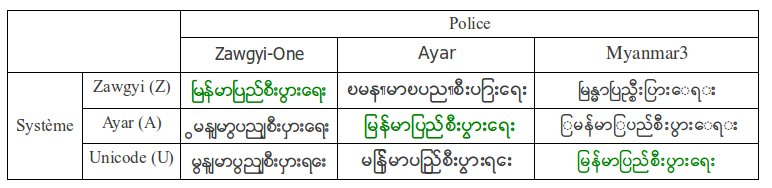
Zawgyi, la police la plus répandue, utilisée notamment par la VOA, la Voice of America. Ayar, pour les pages de la DVB, la Democratic Voice of Burma, une chaîne radio-tv clandestine créée en Norvège par des exilés proches d’Aung San Suu Kyi. Myanmar3, pour les pages de la BBC Burmese service. (Télécharger l'archive de ces polices). Mais pourquoi faut-il des polices différentes pour pouvoir visualiser correctement les différentes pages ? Sont-elles toutes de véritables polices Unicode ?
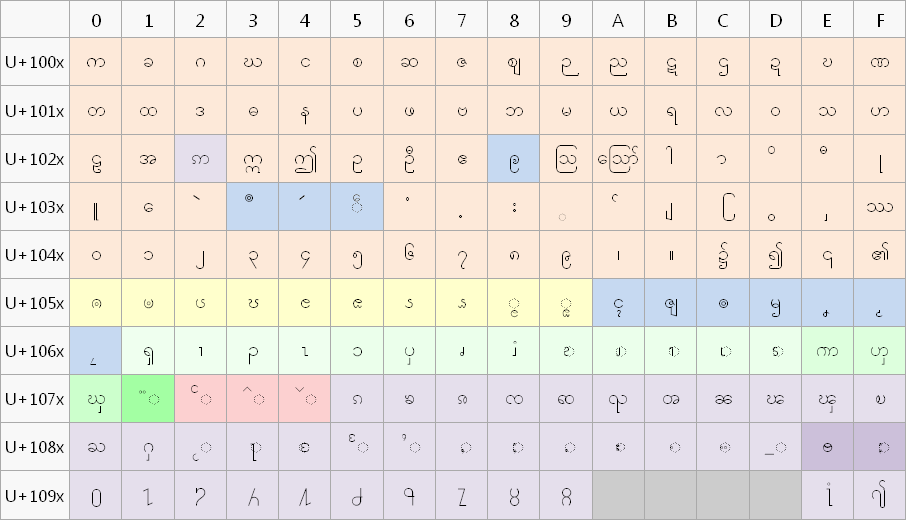
Les
colonnes sont chacune dans une police différente, les lignes
distinguent les
différents systèmes d'encodage. Seules les chaînes de caractères en vert s'affichent correctement. Nous avons donc un petit problème de vocabulaire. On parle de polices et des systèmes derrière ces polices comme si c'était la même chose, mais si ce ne sont pas toutes des polices du système Unicode, comment nommer ces systèmes ? Faute de mieux, nous appelons l'encodage affiché par la police Zawgyi-One, "le système Zawgyi" (Z), et celui affiché par la police Ayar "le système Ayar" (A). La police Myanmar3, elle, s'utilise pour afficher le vrai Unicode (U). C'est la seule qui soit complètement Unicode compliant. Toutes ces polices se veulent des polices Unicode, mais regardons de plus près... Que
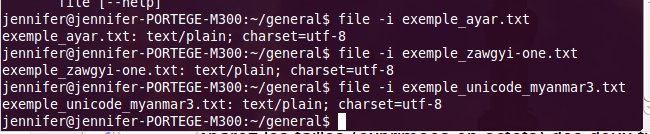
dit la commande file
? Nous avons créé des fichiers test avec le même motif (économie
du Myanmar, comme dans le tableau ci-dessus), chacun tapé dans un
système différent. (Télécharger l'archive de tous les fichiers test ici.)
Selon
file, tout est de
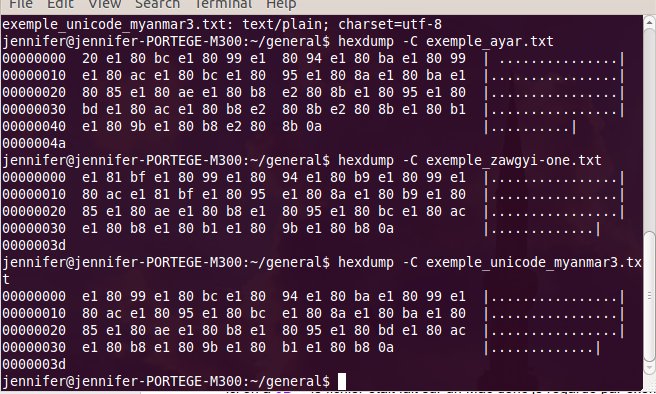
l'UTF-8. Regardons les octets de plus près avec hexdump :
On constate que les caractères sont bel et bien encodés sur trois octets, le codeblock réservé pour les langues du Myanmar allant de U+1000 (e18080 en hexa UTF-8) à U+109F (e1829f en hexa UTF-8), chaque triplet pour les caractères birmans commence par e1, c'est logique. En fait, le standard Unicode précise davantage que l'encodage en UTF-8 et le codeblock à utiliser. Regardons des échantillons plus petits, l'encodage des syllabes :
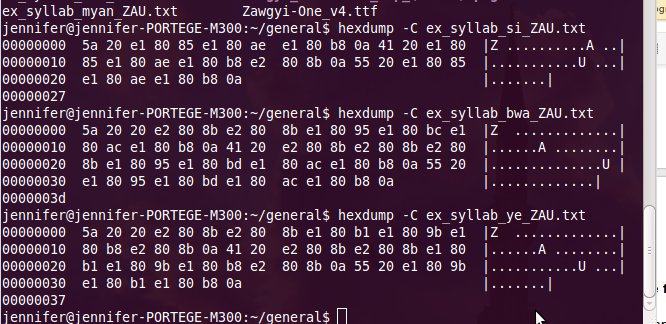
5a 20
représente le début de la chaîne de caractères en Zawgyi (Z majuscule,
espace) Le premier fichier ex_syllab_si_ZAU.txt
contient la syllabe Z
: 5a 20 e1
80 85 e1 80 ae e1 80 b8
0a
L'encodage est identique (sauf l'espace invisible en Ayar). Le
deuxième fichier
ex_syllab_bwa_ZAU.txt contient la syllabe Z
: 5a 20
20
e2 80 8b e2 80 8b e1 80 95 e1 80 bc e1 80 ac e1 80 b8 0a On note en passant l'usage des
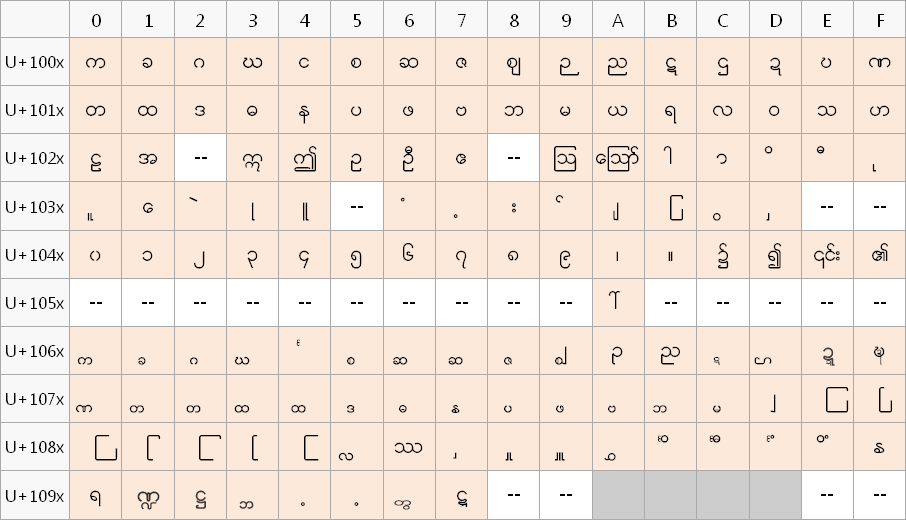
espaces non-visibles en Ayar et en Zawgyi. Le caractère MYANMAR CONSONANT SIGN MEDIAL WA (un petit cercle souscrit) n'est pas encodé avec le même code en Zawgyi qu'en Ayar et en Unicode. Zawgyi ne respecte pas les règles Unicode de correspondance glyphe-code, les codepoints. Ces règles sont détaillées dans ce document du Unicode Consortium. Le bloc Unicode Myanmar, contient une partie pour le birman (officiellement appelé Myanmar) et d'autres parties pour les lettres supplémentaires des autres langues du Myanmar qui utilisent le même script.
On note que la police Myanmar3 ne couvre pas toutes les
langues, il faut utiliser la police Padauk,
que l'on peut télécharger sur le site de SIL. Le système Zawgyi (tableau suivant, les carrés
en rose) utilise la partie du bloc réservée pour le Myanmar
mais aussi des parties réservées pour les autres langues. Ce qui
n'était pas très problématique quand l'informatique n'était pas très
répandue, et le birman la langue dominante.
Le système Zawgyi n'est toujours pas gênant si l'on veut écrire uniquement en birman, son encodage en UTF-8 fait qu'il s'intègre très bien dans tous les logiciels et tous les systèmes informatiques, d'où son succès. Le système de segmentation que nous avons trouvé ne fonctionne qu'en Zawgyi, nous-mêmes avons été contraintes d'utiliser le Zawgyi au lieu d'Unicode. Si nous voulons travailler avec d'autres langues du pays, il va falloir concevoir des logiciels de segmentation pour ces langues et probablement pour le birman aussi, car il faudrait prendre en compte la birmanisation de ces langues, tant au niveau du vocabulaire que de la syntaxe. C'est en exploitant l'usage de la
deuxième partie du bloc Myanmar par le système Zawgyi que nous avons pu
écrire un miniprogramme pour
identifier si un fichier est encodé ou non en Zawgyi.
A ce stade, le programme ne fait qu'identifier si un fichier utilise
ou non la deuxième partie du bloc réservée pour les langues autres que
le birman (le Myanmar) et il
est clair que si l'on y passe un fichier qui n'est pas écrit en birman
(comme celui-ci
en môn), le miniprogram va le reconnaître comme du Zawgyi. Nous
envisageons d'améliorer ce programme pour qu'il soit plus fiable. Le troisème fichier ex_syllab_ye_ZAU.txt contient la
syllabe Z
: 5a 20 20 e2 80 8b e2 80
8b e1 80 b1 e1 80 9b
e1 80 b8 e2 80 8b 0a Les caractères MYANMAR LETTER RA et MYANMAR SIGN VISARGA sont encodés avec les mêmes codes, mais pas dans le même ordre. Les systèmes Ayar et Zawgyi ne respectent pas donc les règles Unicode pour l'ordre des caractères. Cela veut dire que en pratique que l'utilisateur tape les lettres dans un ordre différent. En voici une illustration :  Ne voyant pas comment distinguer entre Ayar et Unicode standard de façon simple nous avons écarté les pages en Ayar de notre corpus dès le début. Réflexion faite, nous constatons que cette lettre MEDIAL RA nous donne peut-être une piste pour identifier les pages en Ayar, car dans cet encodage la lettre MEDIAL RA est sans exception suivie d'une consonne (la consonne qu'elle entoure) et en Unicode, elle suit une consonne. La distinction doit être faite avant la segmentation des mots, il faut donc faire très attention à l'environnement du mot. Nous n'avons pas encore exploré cette piste. Les trois systèmes se résument ainsi : 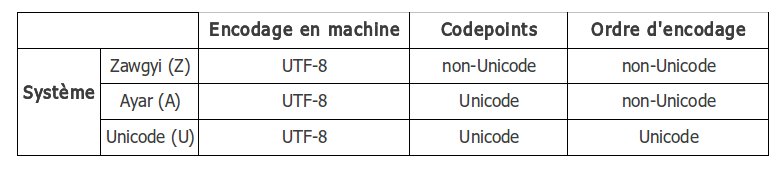 On note aussi l'usage abondant
des espaces non-visibles en Ayar ainsi qu'en Zawgyi, ce qui facilite
sûrement la segmentation. Les commandes de conversion en Perl (Encode) et BASH (iconv) ne sont pas (encore) capables de convertir entre les différents systèmes d'encodage du birman, nous avons utilisé le logiciel KaNaung, discuté précédemment. Nous avons constaté que notre fichier de mots segmenté (encodé en Zawgyi) fonctionne dans le Trameur, mais, faute de temps, nous n'avons malheureusement pas pu explorer les possibilités d'utilisation de ce logiciel. Il serait notamment utile dans un premier temps d'explorer la fréquence des mots encodés différemment en combinant trois versions d'un même corpus encodées dans les trois encodages que nous avons vus ici dans un même fichier. Les mots les plus fréquents pourraient constituer un motif de recherche pour différencier les encodages d'une manière définitive et fiable. Il sera également utile de constituer une liste de mots vides, car force est de constater que le nuage des résultats de notre analyse est "pollué" par ces mots.
|
|
 Lors de notre recherche de pages,
nous avons rencontré des pages en birman nécessitant le téléchargement
de différentes polices pour les visualiser :
Lors de notre recherche de pages,
nous avons rencontré des pages en birman nécessitant le téléchargement
de différentes polices pour les visualiser :