Pour obtenir le résultat ci-dessus, il existe deux programmations Perl ayant extrait des informations BAO 1 puis on les transforme par XSLT des sorties XML en format HTML.
En étape BAO 1, le but est d'extraire les titres et les descriptions contenus dans chaque fichier XML de l’arborescence. On aura deux types de sorties : un fichier TXT et un fichier XML. Sachant que les fils RSS appartiennent à différentes rubriques du journal, un fichier de chaque type est produit pour chaque rubrique. Les expressions régulières et le module XML:: RSS vont nous aider à les extraire.
Pour traiter chacun de ces fichiers dans dossier “2014”, le programme doit identifier quels objets de l'arborescence sont des dossiers et lesquels sont des fichiers. Le parcours d'arborescence se fait avec 'if (-d $file)' , pour identifier les dossiers, 'id (-f $file)' pour les fichiers.
Identification:
L'expressions régulières peuvent parcourir la structure arborescente des fichiers et arriver dans certains textes et de les extraire. Cette expression ci-dessus cherche les parties du texte qui contiennent les balises <title></title> et <description></description> directement sous la balise <item>, et les parenthèses isolent le contenu dans chacune de ces balises, le stockant respectivement dans les variables $1 et $2.
Cette deuxième solution utilise XML::RSS, un module désigné spécifiquement pour les fichiers RSS.XML::RSS est un module spécialement pour RSS. Il faut parcourir l'arborescence du dossier, en traitant tous les fichiers XML. Les sorties sont pareilles que celles de l’expression régulière. Ce qui change est la manière d'extraire ces informations. XML::RSS permet d'exploiter la structure arborescente pour atteindre les nœuds et de produire un objet hiérarchique au lieu de l'objet plat produit par la méthode qui utilise l’expression régulière.
Ce qui change est la manière d'extraire ces informations. Faire du fichier un objet XML::RSS permet d'exploiter la structure arborescente pour atteindre les nœuds et de produire un objet hiérarchique au lieu de l'objet plat produit par la méthode qui utilise les regex.
La première ligne crée un nouvel objet XML::RSS dont la référence est stockée dans la variable $rss et la deuxième signifie que l'objet à analyser en forme RSS. Le fichier est situé au chemin indiqué par $path.
L'avantage avec cette méthode est qu'il n'est pas nécessaire de faire la normalisation, c'est à dire la suppression des sauts de lignes, le traitement des encodages différents. C'est le module XML::RSS qui va gérer, et rend aussi la tâche de parcourir l'arborescence RSS plus facile. Cette méthode prend un peu plus de temps que les regex pour l'extraction.
Une fois les informations extraites, il faut veiller à leur bon affichage et à la non-duplication de ces informations.
Une étape importante est le nettoyage des rubriques, des titres et des descriptions, parce qu'ils contiennent certaines suites de caractères étranges et des entités XML. Le premier traitement se fait avec le module Unicode::String qw(utf8) permettant d'encoder des chaînes en utf-8. Un second module, HTML::Entities, est utilisé pour convertir les caractères en entités HTML pour éviter des problèmes de codage lors de la création des nouveaux fichiers. La fonction nettoyage qui permet de supprimer les balises non pertinentes intégrées aux titres et descriptions, ainsi qu'à filtrer certains caractères.
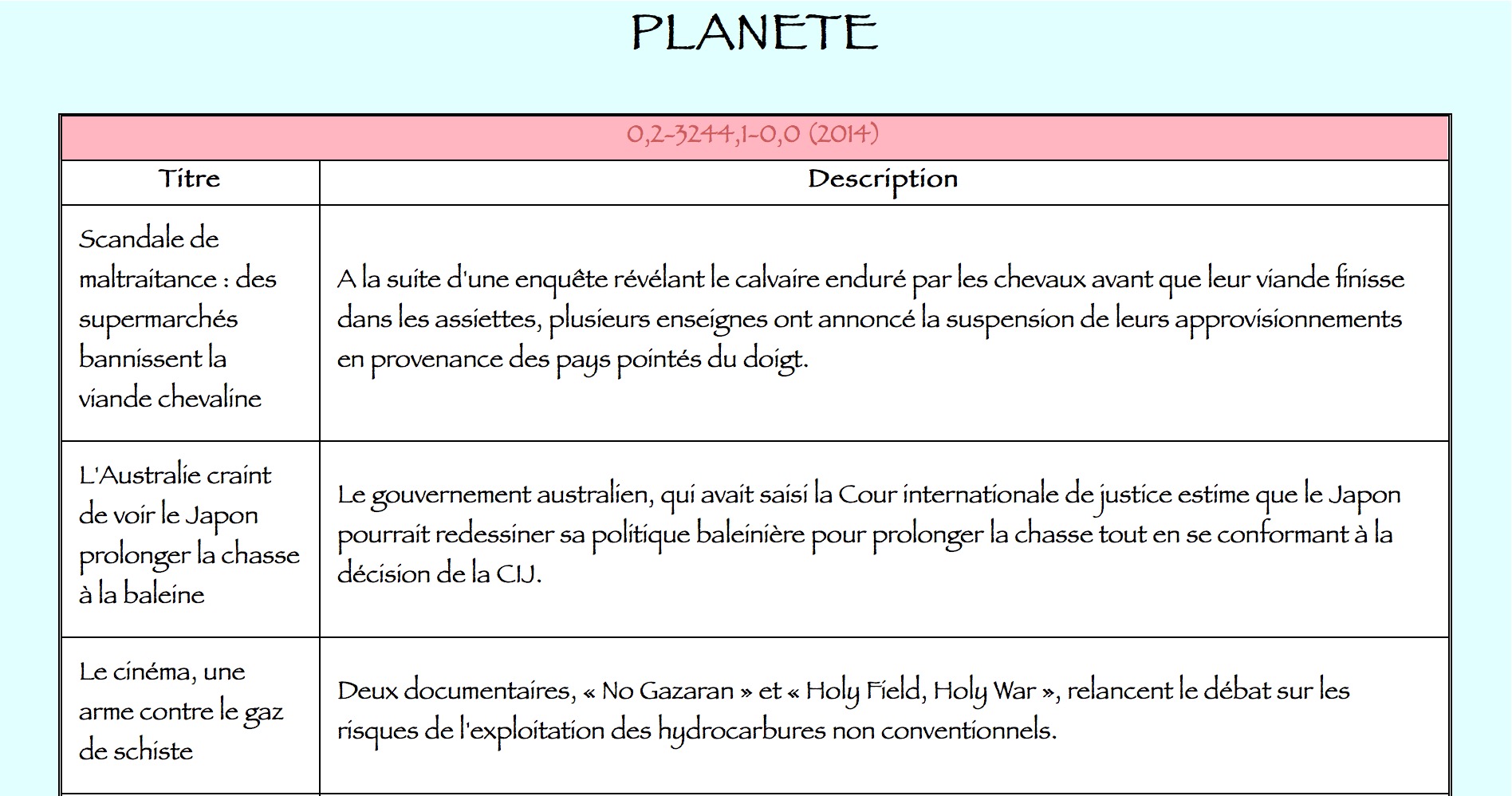
Les sorties en format TXT ne contiennent aucune balise, c'est simplement une liste des titres et des descriptions. Les sorties en format XML doivent être bien structurées avec des balises XML qui peuvent organiser les informations appropriées. La structuration des données sont mises en forme par des balises : “name”, “date” (pour identifier) “item” contient son titre et sa description (pour délimiter)…
La fin du traitement du fichier :
Chaque paire titre-description est écrite sous une balise <item> et chacune entourée de une balise adaptée si: if (!(exists $dicoTitres{$titre}) and (!(exists $dicoDescrip{$descrip}))) [vérifier les doublons], puis
Mettre les balise: $texteXML.="<item>\n<title>$titre</title>\n<description>$descrip</description>\n</item>\n";
Fermer les sorties avec des balises: $texteXML.="</items>\n</file>\n";
La clôture:
Les fichiers en année 2014, la rubrique “Sciences” a la structure un peu particulière que les autres, du coupe, il faut faire attention à notre programme si notre méthode peut le récupérer ou pas. A noter que la méthode par XML::RSS prend plus de temps que celle par expressions régulières.
Pour séparer le contenu par la rubrique, on a aussi essayer de conduire des sorties d'un script (script Perl issu du 2e cours, qui fait sortir tous les contenu sans classement) dans XML Copy Editor, puis on a utilisé Xpath pour extraire le contenu selon rubrique, et on les a stocké séparemment dans les dizaine de fichiers xml au nom de leur rubrique. Sur la base de fichiers xml, on a employé les expressions régulières pour supprimer les balises pour, finalement, stocker des fichiers sous forme txt;
On a transformé les résultats de BAO 1 en format HTML après une application de XSLT des sorties XML. Voilà une partie de codes et un exemple de rubrique PLANETE rangé par titre et description: