







Pour obtenir le résultat ci-dessus, il faut étiqueter les sorties XML de BAO 1 par TreeTagger puis on les transforme par XSLT en format HTML.
Dans l’étape BAO 2, il s'agit d'utiliser des outils d'annotation afin d'étiqueter les sorties textuelles de la BAO 1. L'étiquetage morphosyntaxique nécessite d'avoir déjà segmenté le texte en tokens. Chaque forme est associée à un lemme et une catégorie syntaxique. Les deux logiciels à notre disposition sont Cordial et TreeTagger
Notez que Cordial ne supporte pas les fichiers au-dessus d’une certaine taille, et les fichiers à traiter sont uniquement avec les sorties TXT. Les fichiers doivent être en ISO-8859-1, c’est à dire qu’on doit convertir notre fichiers (UTF-8) en ISO.
Il y a 3 méthodes simples mais manuels que l’on a essayé, la première été conseillée par notre professeur en utilisant Word sous Windows. Deuxième , sous Mac OS l’éditeur TextWrangler peut convertir l’encodage au moment que l’on fait copy-coller et sauvegarder. Troisième, une ligne de commande Perl, il suffit de taper le code ci-dessous:
Pour étiqueter avec Cordial : ouvrir le fichier TXT à étiqueter, puis Syntaxe --> étiquetage de texte. Ensuite, il faut appliquer les paramètres de l'étiquetage avant de lancer le programme :
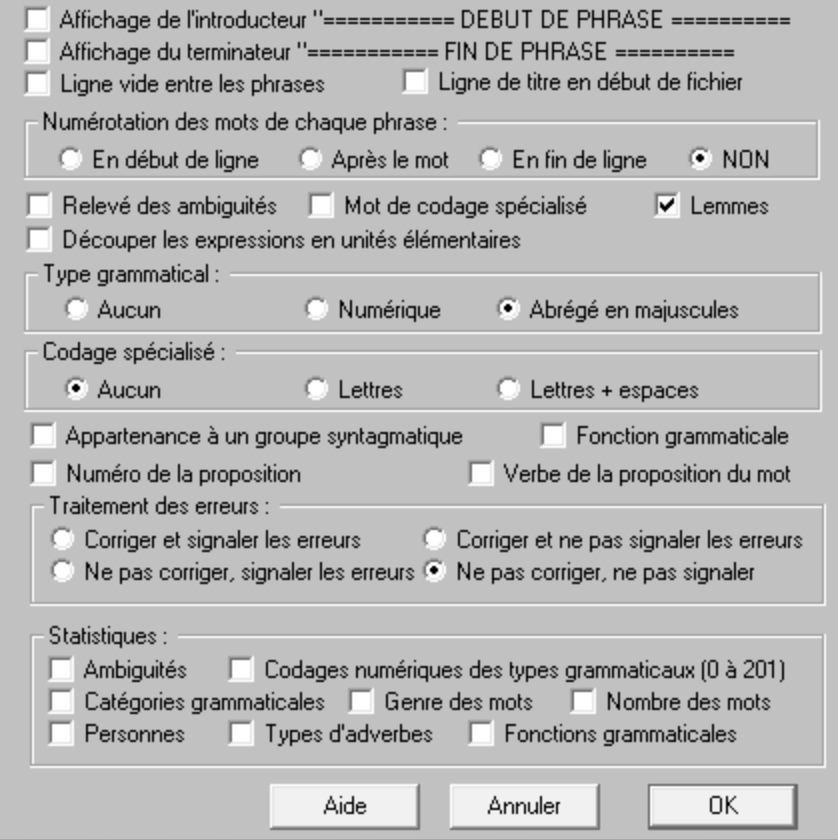
Tout processus d'étiquetage ne comprend qu’une étape de segmentation de texte en tokens et une étape d'étiquetage de ces tokens. La segmentation est automatiquement effectuée par le logiciel Cordial avant l'étiquetage à proprement dit. Le résultat est un fichier au format .cnr présentant sous forme de tableau le token suivi de son lemme et de sa catégorie syntaxique :
Notez que ça arrive souvent des erreurs, par exemple: mauvais choix de catégorie syntaxique.
TreeTagger est un “open source” qui sert à annoter du texte pour les catégories syntaxiques et les lemmes en beaucoup de langues. Il est disponible en ligne de commande qui permet d’intégrer l’étiquetage du corpus dans le programme du BAO1.
Il faut passer 2 étapes pour étiqueter les textes:
Etape 1: Segmenter en utilisant le programme tokenise-fr.pl :
perl tokenise-fr.pl toto.txt > toto_segmente.txt
Etape 2: Etiqueter le fichier segmenté, dans l'ordre : tree-tagger [fichier Lib] [options] [fichier segmenté] :
tree-tagger french-utf8.par -lemma -token -no-unknown -sgml fichier_segmente.txt > fichier_etiquete.txt
L'option-lemma sert à indiquer les lemmes, -token à afficher les tokens, -no-unknown à ne pas indiquer si le token est inconnu, et -sgml à ne pas traiter les balises.
Le fichier en sortie contient un mot par ligne. Chaque mot, comme avant, est décrit par trois colonnes, mais l'ordre des colonnes est différent : la forme, la catégorie syntaxique et le lemme.
On peut intégrer TreeTagger dans le script de la BAO 1 pour produire une sortie XML avec chaque mot étiqueté pour sa catégorie syntaxique et son lemme. La méthode est la même pour les deux programmes.
La création d'un fichier temporaire pour stocker le texte:
Intégration:
Convertir les fichier en XML via le script "treetagger2xml-utf8.pl' fourni :
Lecture du fichier étiqueté + le renvoie de contenu :
Les Sorties_bao2 contient les fichiers XML produits par treetagger2xml.pl, les titres et descriptions étiquetés sont comme suit:
Ces fichiers XML étiquetés peuvent être transformés en HTML à l'aide d'une feuille de styles ci-dessous (une partie):
Un exemple de rubrique ECONOMIE étiqueté:
