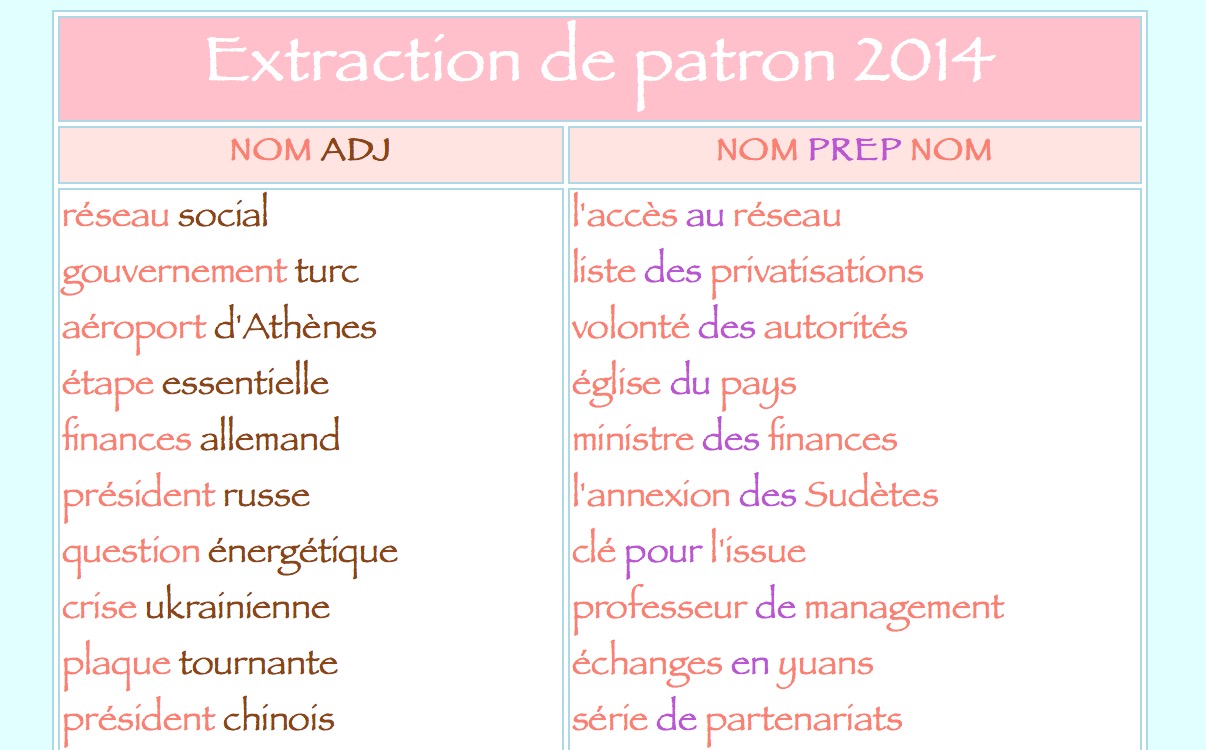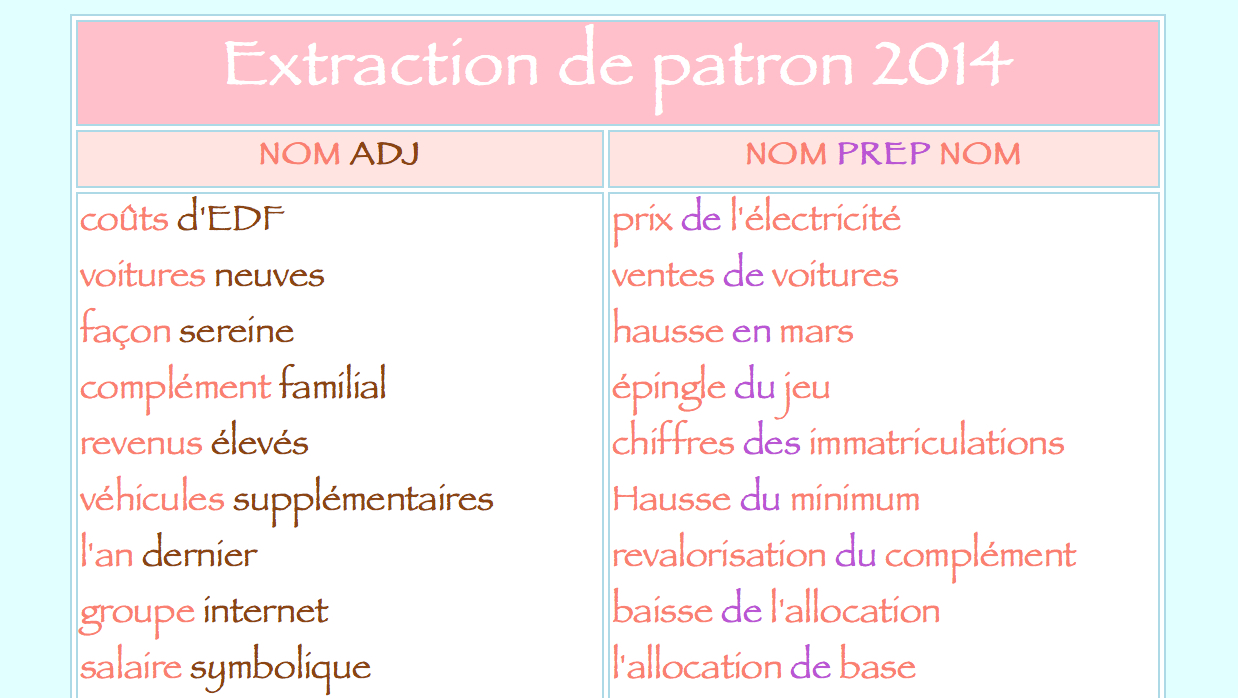
Pour obtenir le résultat ci-dessus, il faut extraire les patrons "NOM ADJ" et "NOM PREP NOM" des sorties XML de BAO 2 par le programme puis les transforme par XSLT en format HTML.
Cette étape de BAO 3 est l'extraction de patrons syntaxiques des fichiers obtenus à la BAO2. Il s'agit de repérer les suites “NOM ADJ” et “NOM PREP NOM”. On dispose de plusieurs méthodes:
Traitement des sorties TXT Cordial: 2 méthodes Perl utilisant des listes patrons
Traitement des sorties XML: le module XML::LibXML de Perl
Cette méthode consiste à lire le fichier étiqueté par Cordial jusqu'à trouver une ponctuation forte. Le programme lit le fichier ligne par ligne (forme, lemme et catégorie syntaxique). En utilisant l'étiquette "PCTFORTE" comme indicateur à la fin d'une phrase. Il traite phrase par phrase, en stockant dans trois tableaux différents (@tokens, @lemmes et @catégories) les informations pour chaque mot de la phrase. Quand on rencontre une "PCTFORTE", on effectue le traitement sur les trois listes, et ensuite on les reinitialise pour traiter la phrase suivante.
En prenant des motifs "NOM ADJ" et "NOM PREP NOM", les formes dans les listes patrons sont:
NC[A-Z]+ ADJ[A-Z]+
NC[A-Z]+ PREP NC[A-Z]+
Le script se trouve ci-dessous:
Ce programme parcourt la liste des catégorie et des tokens en parallèle. Si une catégorie correspond au premier catégorie d'un patron, alors il vérifie s’il y a les catégories suivantes correspondant à la suite du patron. Si c'est le cas, il extrait les tokens correspondant aux catégories repérées. Ce programme est aussi le principe de fonctionnement du Trameur.
Bis: Alors, on a manipulé un motif de recherche croisée de patrons NOM ADJ (forme 1) dans la section PATRON de Trameur avec la sortie rubrique POLITIQUE. Il extrait tous les séquences de NOM ADJ. On a fait un graphe avec un motif "\bélections\b" pour visualiser le résultat:
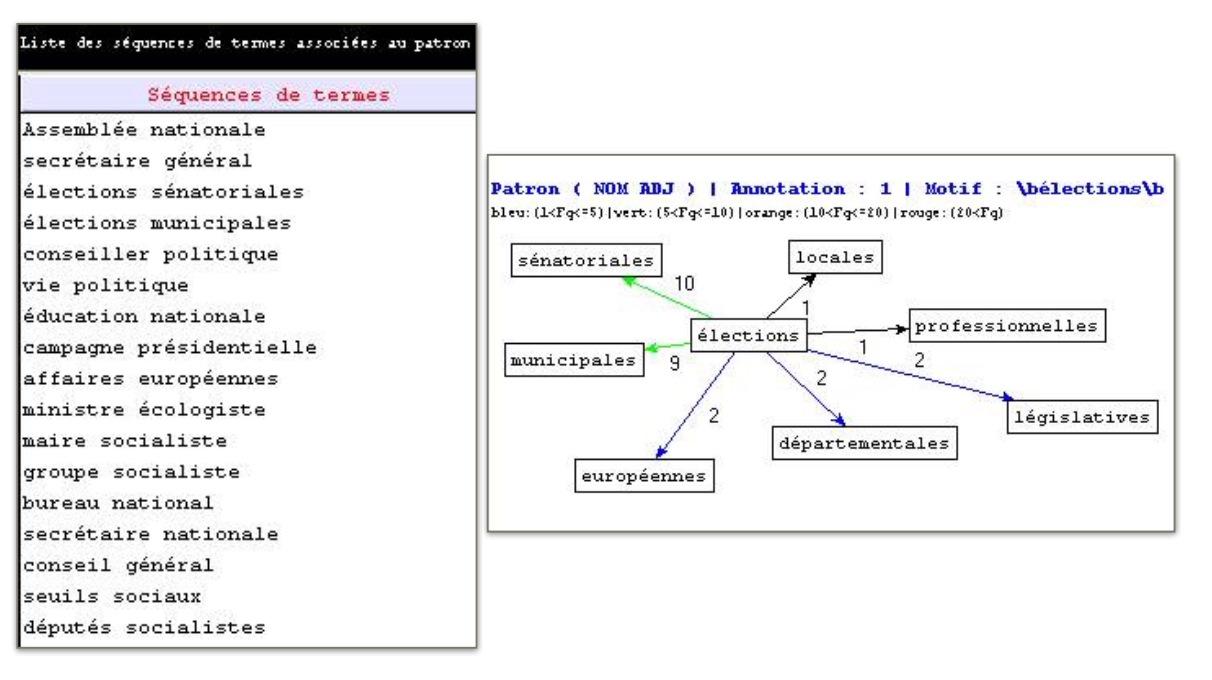
Les patrons dans la liste sont en forme ci-dessous:
NC[A-Z]+ ADJ[A-Z]+
NC[A-Z]+ PREP NC[A-Z]+
Le script complet pour extraire "NOM ADJ" est comme suit:
Le script complet pour extraire "NOM PREP NOM" est comme suit:
Comme les deux méthodes ci-dessus ne prennent en entrée qu'un seul fichier à la fois, on peut utiliser "subprocess" de Python à gérer:
Selon la même technique utilisée pour le parcours d'arborescence écrit en Perl (BAO 1, BAO 2), on peut aussi d'automatiser cette tâche, ça commence à peu près:
Créer le chemin d'entrée, récupérer le variable, puis transferer les fichiers lus dans un tableau:
Création d'un fichier de sortie pour tous les fichiers, suppression de ".cnr" des noms de fichiers de sorties, exécution du programme:
Concernant l’extraction des patrons, vu que des fois les fichiers finaux sont trop gros pour executer le script fournis par le professeur, celui de monsieur Rachid Belmouhoub par exemple, on a fait appel à un script bash pour les couper en plusieurs fichiers plus petits si bien que le script peut être exécuter sans difficulté, le code comme suit:
XPATH exprime des chemins via la barre oblique et on peut aussi contenir des prédicats pour imposer des conditions aux noeuds sélectionnés. Cette méthode consiste à intégrer des requêtes XPath dans un programme Perl, via le module XML::XPath.
Lecture du fichier de patrons (correspondant à un motif chaque fois). Pour chaque ligne du fichier, un appel à la procédure &extract_pattern, avec le motif comme argument. La procédure &extract_pattern prend le motif actuel et produit une sortie pour ce motif. La construction du chemin se fait via la procédure &construit_XPath qui prend comme argument la ligne du patron, qu'elle transforme en liste pour pouvoir la parcourir. On a dit que ce programme n'exécute pas bien avec des fichiers gros, mais sous Mac OS, on en a utilisé à traiter "ALAUNE" (rubrique ayant le plus de contenu) qui extrait très rapidement.
Ce chemin est récupéré par la procédure &extract_pattern. L'exploration de l'arborescence XML a besoin de la création d'un nouvel objet XML::XPATH et il est possible de récupérer les noeuds qui correspondent au chemin créé en faisant une requête sur cet objet via “findnoedes”.
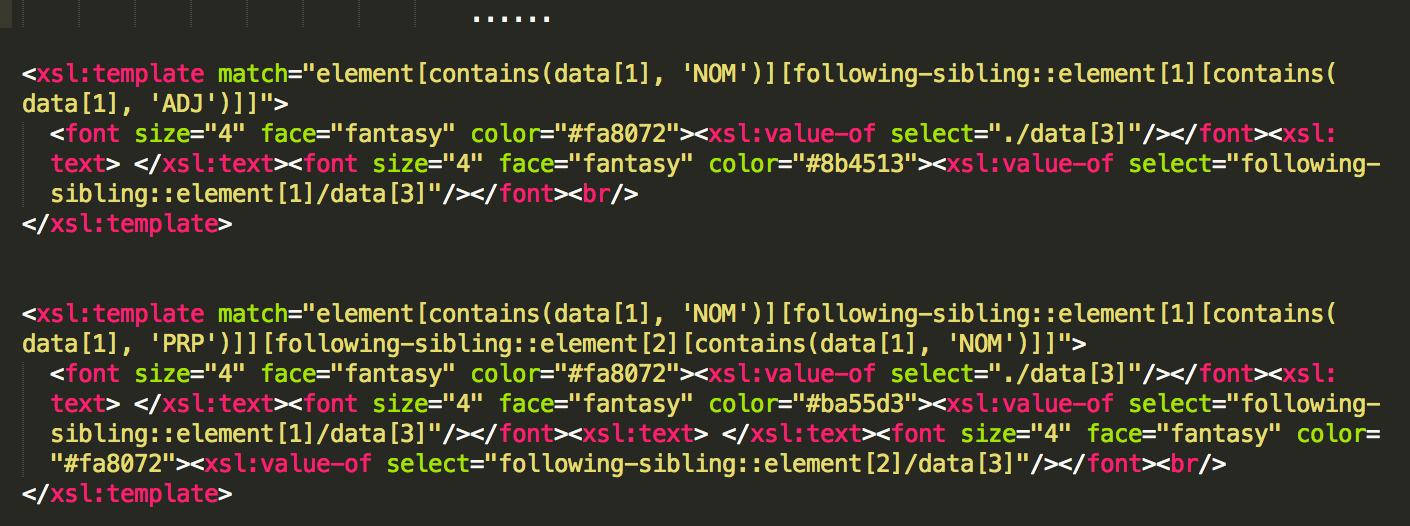
Comme dans la BAO 1, BAO 2, on peut visualiser les sorties au format XML, avec une feuille de styles XSLT pour le transformer. Les balises
NOM ADJ: //element[contains(data[1], ‘NOM')][following-sibling::element[1] [contains(data[1], ‘ADJ')]]
NOM PREP NOM: //element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'PRP')]][following-sibling::element[2][contains(data[1], ‘NOM')]]
Une partie de code, les "chemins" sont dans les balises:
Un exemple d'extraction de patrons da la rubrique EUROPE: