
 |
 |
 |
 |
|
|
||||
|
|
*** BOITE A OUTILS, SERIE 1 *** Objectif : parcourir l'arborescence des fils RSS du corpus et en extraire les contenus textuels Le corpus de travail est constitué de l'ensemble des fils RSS du journal Le Monde recueillis tous les jours de l'année 2013 à 19h : Corpus_RSS_LeMonde. Il existe deux méthodes pour extraire l'information: une solution dite "pure Perl" avec des expressions régulières et une extraction avec le module XML::RSS. Chaque méthode doit produire deux types de sortie: une sortie pour un traitement du corpus intégral et une sortie pour un traitement du corpus par rubriques. Et chaque méthode doit aussi produire deux formats de sortie : une version TXT brute et une version XML contenant les titres et les descriptions des fils (et éventuellement les dates). # PARCOURS DE L'ARBORESCENCE # Les fichiers sont rangés dans des dossiers et organisés par date de mise à jour et rubriques, pour traiter le corpus, le programme parcourt l'arborescence en identifiant les dossiers et les fichiers. 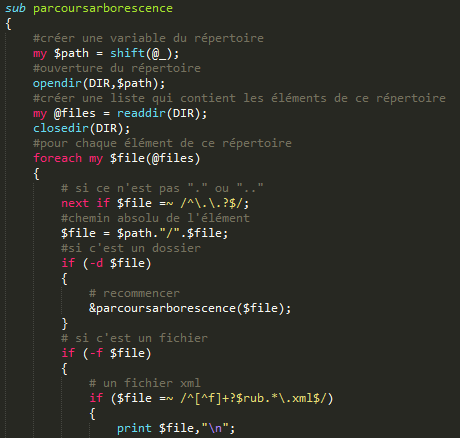
# PRE-TRAITEMENT POUR LA METHODE PURE PERL # La solution pure Perl à la différence de la solution XML::RSS nécessite une phase de pré-traitement, les fichiers étant issus de sources différentes, il faut pouvoir les ouvrir dans leur encodage d'origine. De même, il est préférable d'harmoniser le formatage des fichiers du corpus pour leur traitement ultérieur. Extraction de l'encodage à partir du fichier : la première ligne du fichier RSS contient normalement une déclaration du type du fichier et de l'encodage. Il y a deux manières d'extraire l'encodage lorsqu'il est précisé, avec une commande Unix ou avec une expression régulière. 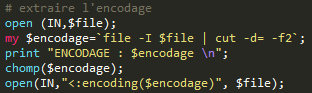

Il est recommandé que les contenus des fichiers de sortie soient dans le même encodage, si l'encodage extrait n'est pas en UTF-8, il est converti : 

Harmonisation du formatage : elle permet de mettre tout le contenu sur une seule ligne afin d'en faciliter le traitement. Pour supprimer les éventuels sauts de ligne et faire suivre les balises : 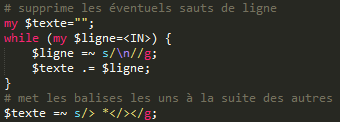
# OUVERTURE DES FICHIERS # Les fichiers de sortie sont ouverts avant toute modification, respectivement les sorties globales et les sorties par rubrique sont de la forme suivante : 

La seule différence entre les deux types de sortie dans les codes ci-dessus est que les noms de fichier pour les sorties rubriques sont stockés au préalable dans les variables $OUTPUT1 et $OUTPUT2, étant donné que ces noms de fichier sont composés d'une autre variable $rub, que l'on décrira plus bas. # EXTRACTION EN PURE PERL # Une boucle parcourt les fichiers et cherche le motif spécifié par l'expression régulière pour en extraire les contenus et les stocker dans des variables. Voici pour les titres et les descriptions : 
De la même manière, les expressions régulières permettent aussi d'extraire les dates et les rubriques : 

# EXTRACTION AVEC XML::RSS # La méthode est presque similaire à celle avec les expressions régulières dans la mesure où il s'agit de parcourir l'arborescence et d'en extraire les titres, les descriptions et les dates. Au lieu d'extraire les contenus à partir d'expressions régulières, on fait des fichiers des objets XML::RSS pour exploiter directement leur structure arborescente. 
Une boucle cherche tous les noeuds fils "titre" et "description" des noeuds parents "item" pour les extraire et les stocker dans des variables : 
On peut procéder de la même manière pour extraire les dates et les rubriques : 

En réalité, dans les deux méthodes, ce ne sont pas tout à fait les rubriques qui sont extraites des noeuds parents mais les titres, comme on va le voir dans la section de nettoyage des contenus extraits. # NETTOYAGE DES CONTENUS EXTRAITS # Une fois l'essentiel des contenus extraits du corpus par "filtrage", on doit les "nettoyer" avant de les écrire dans les fichiers de sortie. Le contenu extrait des titres va être seulement partiellement réutilisé pour nommer les fichiers de sortie de type "par rubrique". On conservera uniquement le nom de rubrique contenu dans le titre sans l'adresse du site Web, les espaces, les caractères accentués et toute ponctuation autre que le tiret (ce dernier sera utilisé dans le nom de fichier). Pour faciliter la lecture des fichiers, les noms des fichiers seront écrits en casse majuscule, au cas où les noms de rubriques comportent des caractères accentués par exemple. 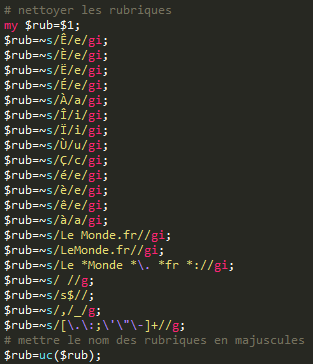
Les flux RSS étant des fichiers XML, il faut également penser à nettoyer les contenus des titres et des descriptions en remplaçant toutes les entités nommées XML par leurs équivalents, puisque XML possède des caractères réservés. Il en va de même pour tout ce qui est spécifique à XML (les balises par exemple) ou tout ce qui ne relève pas du contenu textuel pur (symboles, images, etc.). En voici un extrait : 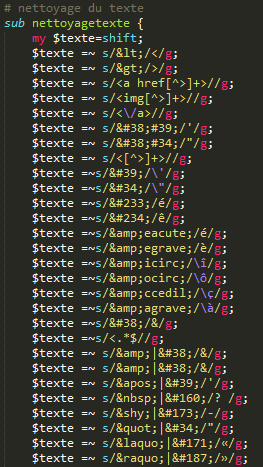
Enfin, il faut veiller à éviter des doublons de contenus à l'intérieur d'une même rubrique en raison des mises à jour des fils RSS. Pour cela, on crée en Perl des tableaux associatifs qui associent les contenus avec leur structure et les comparent entre eux. 
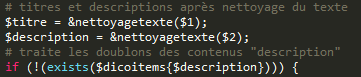
# ECRITURE DES CONTENUS # Après les processus de nettoyage, les contenus extraits du corpus sont concaténés dans les fichiers de sortie qui sont ensuite fermés. 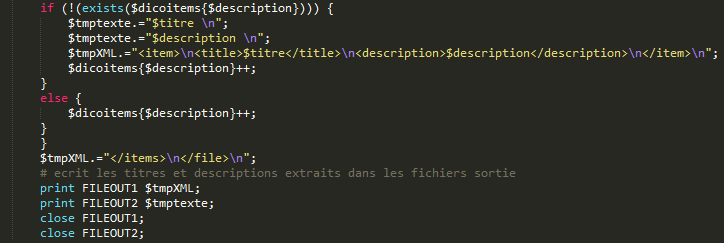
# SORTIES # La sortie au format XML nécessite quelques ajouts au niveau de la déclaration de l'encodage et des balises : 




En revanche, la sortie au format TXT n'a pas besoin de toutes ces balises. De plus, elle ne récupère que les contenus du titre et de la description alors que la sortie XML récupèrent aussi les contenus du nom et de la date. Ceci engendre la création d'un fichier temporairement vide pour la sortie TXT : 
Comme on peut le voir à titre de comparaison, après extraction du titre et de la description, les fichiers TXT et XML en récupèrent tous deux les contenus mais les fichiers XML ont leurs contenus entourés de balises. 
Quant à la sortie par rubrique, les fichiers récupèrent les noms de rubrique extraits : 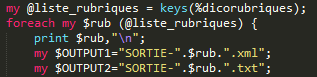
# RESULTATS # Les résultats au format TXT ont cette forme: 
Les résultats au format XML ont cette forme : 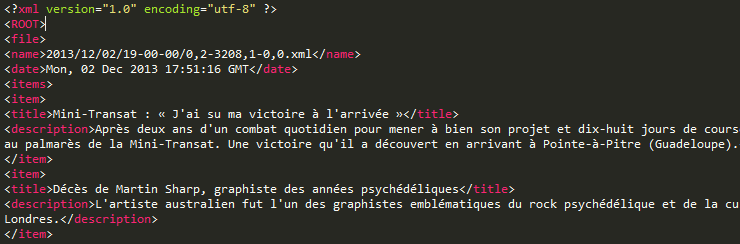
Et bien sûr, quel que soit la méthode d'extraction choisie, il y a un résultat TXT et un résultat XML pour tout le corpus et un résultat TXT et un résultat XML pour chaque rubrique (il y en a 17 dans notre corpus).
|
|
|