
 |
 |
 |
 |
|
|
||||
|
|
*** BOITE A OUTILS, SERIE 3 *** Objectif : extraire des patrons sur les sorties de l'étiquetage Cordial et TreeTagger. Deux méthodes seront présentées pour l'extraction des patrons. Comme pour la BàO2 qui s'appuyait sur les scripts et les sorties de la BàO1, la BàO3 s'appuie sur les sripts et les sorties de la BàO2. La première extraction de patrons se fait sur les sorties "brutes" de l'étiquetage Cordial via un script Perl. La deuxième extraction de patrons se fait sur les sorties XML de l'étiquetage TreeTagger via un script Perl utilisant la bibliothèque XML::XPath. Enfin, la troisième extraction de patrons se fait aussi sur les sorties XML de l'étiquetage TreeTagger mais via une requête XPath dans une feuille de styles XSLT. Les motifs cherchés sont "NOM PRP NOM" (nom-préposition-nom) et "NOM ADJ" (nom-adjectif). Le script stocke les résultats obtenus pour chaque motif dans un fichier différent, il y aura donc en sortie un fichier par motif cherché. # EXTRACTION SUR LES SORTIES BRUTES # L'extraction des patrons sur les sorties brutes de l'étiquetage Cordial peut se résumer en trois étapes : - la segmentation de la sortie sous forme tabulaire en trois colonnes formant des listes respectives pour les tokens, les lemmes et les catégories syntaxiques (POS) : 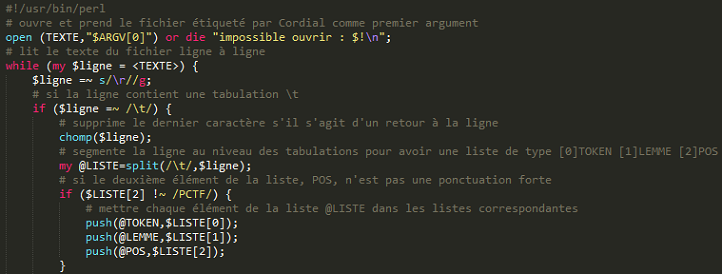
- la mise en correspondance du patron cherché avec une suite de POS : 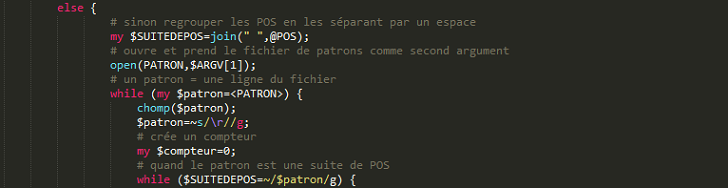
- le cas échéant, l'affichage des tokens correspondants : 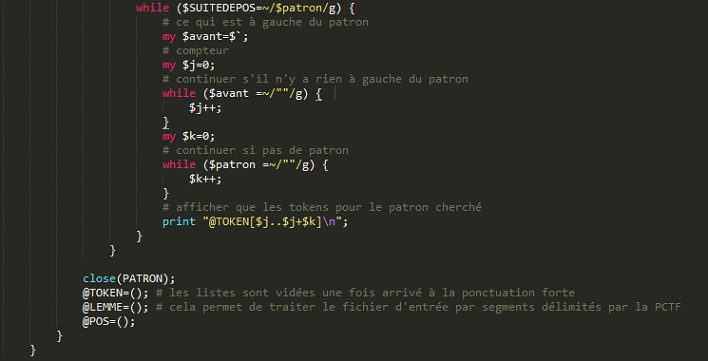
Le traitement se fait sur les trois listes créées (@TOKEN, @LEMME, @POS). Ces listes sont réinitialisées à chaque ponctuation forte, ce qui permet un traitement du fichier d'entrée en partitions. Le programme sélectionne une ligne, autrement dit un patron, dans le fichier contenant une liste de patrons et vérifie s'il est présent dans la suite de catégories syntaxiques $SUITEDEPOS. Au fur et à mesure que le patron est rencontré dans la suite, les tokens correspondants sont extraits et écrits dans le fichier de sortie sous forme de liste (\n).
# EXTRACTION SUR LES SORTIES XML AVEC XML::XPATH # A la différence de la méthode précédente réalisée en pure Perl, l'extraction sur les sorties XML s'appuie sur le module XML::XPath de Perl. XPath permet de parcourir les noeuds des fichiers XML et de sélectionner les noeuds qui nous intéressent pour l'extraction. Il suffit donc d'indiquer un chemin d'extraction. Pour le motif "NOM ADJ" par exemple, on veut que deux "element" frères qui se suivent aient un "data" de type "type" qui soit pour le premier "element" un nom et pour le deuxième "element" un adjectif. Ce que le programme renvoie, ce sont les "data" de type "string" de chaque "element". Pour mieux visualiser le parcours dans l'arborescence XML, l'exemple de sortie de l'étiquetage TreeTagger de la BàO2 : 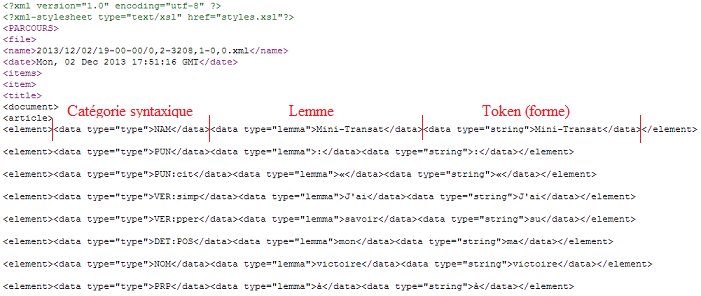
Les chemins XPath sont les suivants pour les motifs cherchés : NOM ADJ : NOM PRP NOM : Entre chaque pipe (|), l'examen de la catégorie syntaxique d'un "element". Cela donnerait donc pour le motif "NOM ADJ" : "je cherche parmi les éléments un "element" qui a un "type" de valeur "NOM" et dont le noeud frère qui suit est un "element" qui a un "type" de valeur "ADJ". Et, pour être sûr que le noeud frère qui suit est un noeud frère "immédiat", j'impose une condition sine qua non tel que je veux aussi que cet élément frère soit de type ADJ et que son noeud frère précédant soit de type NOM.
Comme pour l'extraction sur sorties brutes, le script de cette méthode prend en entrée deux fichiers (arguments), l'un étant une sortie XML de la BàO2, et l'autre étant le fichier de patrons. Le programme se déroule en deux étapes principales, premièrement, la construction du chemin XPath pour le motif cherché, et deuxièmement, l'extraction des noeuds avec l'objet XML::XPath. Le script débute ainsi : 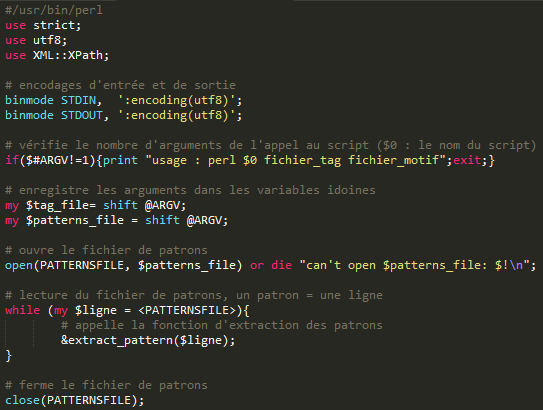
Comme pour la méthode précédente, il permet d'appliquer l'extraction sur chaque ligne, soit chaque patron, de la liste de patrons présents dans le fichier de patrons.
La construction du chemin XPath pour le motif cherché : 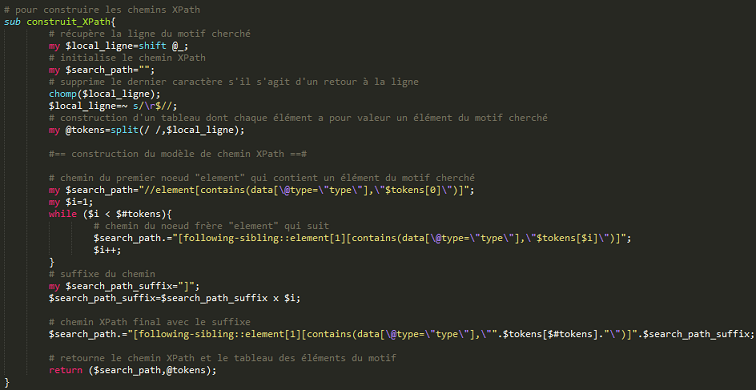
On construit un modèle de chemin XPath.
L'extraction des noeuds avec l'objet XML::XPath : 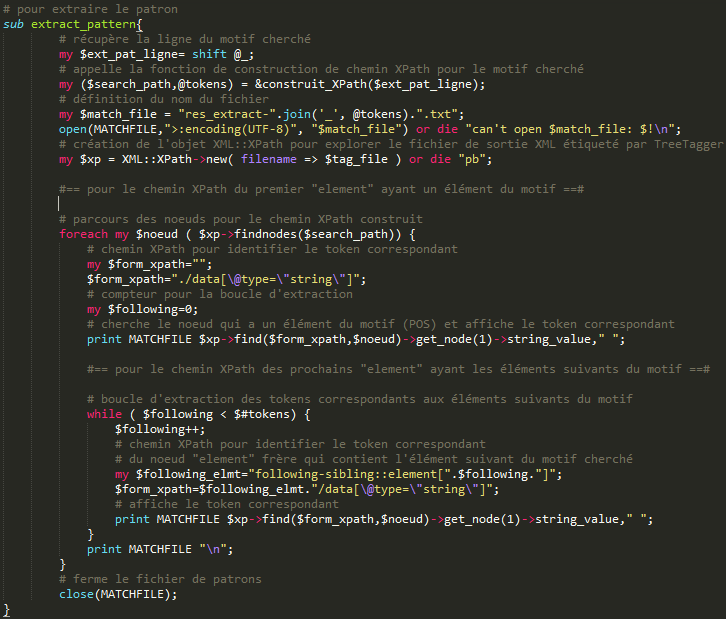
On applique le modèle de chemin pour chaque élément du motif cherché jusqu'à ce qu'on puisse extraire toutes les formes / tokens correspondants de l'ensemble des éléments du motif cherché.
Les extractions de patrons de la BàO3 sont semblables aux extractions de contenus textuels de la BàO1. Si la méthode d'extraction sur sorties brutes correspond à une méthode pure Perl, la méthode d'extraction sur sorties XML via XML::XPath correspond à la méthode XML::RSS. Le principe est donc le même : extraction en pure Perl ou extraction avec le parcours d'une structure arborescente.
# EXTRACTION SUR LES SORTIES XML AVEC XPATH DANS XSLT # L'extraction avec XPath dans une feuille de styles consiste à intégrer les chemins du motif cherché directement dans la feuille de styles. Pour cela, on utilise l'instruction "apply-templates" et l'attribut "select" contenant une requête XPath pour sélectionner les noeuds pour lesquels on va chercher des règles de transformation à activer. NOM ADJ : NOM PRP NOM : Elles partent de la racine <PARCOURS> pour appliquer les transformations au contenu des éléments correspondant au motif cherché. Cependant, on ne veut appliquer les transformations qu'à une partie de ce contenu, les tokens (element/data[3]). Au niveau des "template match", qui vérifient les requêtes XPath des instructions "apply-templates", il faut donc indiquer les valeurs de chaque requête, autrement dit, le chemin de chaque valeur (token du motif) : - pour le token correspondant au premier élément du motif : <xsl:value-of select="./data[3]"/> - pour le token correspondant au deuxième élément du motif : <xsl:value-of select="following-sibling::element[1]/data[3]"/> - pour le token correspondant au troisième élément du motif : <xsl:value-of select="following-sibling::element[2]/data[3]"/>, et ainsi de suite... Des exemples de feuilles de styles possibles pour NOM ADJ et NOM PRP NOM.
# RESULTATS DES EXTRACTIONS DE PATRONS # On obtient un fichier par motif cherché. Ci-dessous un exemple de résultat pour le motif NOM ADJ (format TXT) : 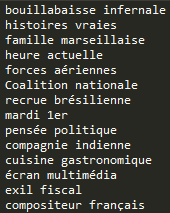
Pour l'extraction via XPath dans XSLT, on obtient aussi un résultat tabulaire mais avec l'application de styles en plus. Par exemple : 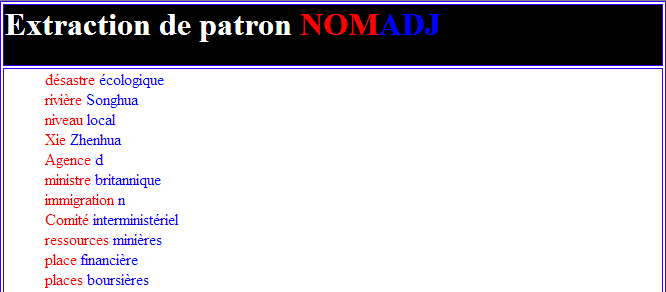
|
|
|