
 |
 |
 |
 |
|
|
||||
|
|
*** BOITE A OUTILS, SERIE 2 *** Objectif : produire un étiquetage des données textuelles extraites dans l'arborescence des fils RSS Pour cela, il faut suivre deux parcours et deux outils sont proposés : un étiquetage via Cordial et un autre via TreeTagger. L'étiquetage via Cordial concerne la concaténation complète des textes extraits au cours du parcours de l'arborescence dans la BàO1. Il produit en sortie un fichier .cnr avec trois colonnes (forme, lemme, catégorie). L'étiquetage via TreeTagger nécessite la modification du script de la BàO1 au niveau du parcours de l'arborescence afin d'étiqueter les contenus textuels juste après leur extraction. La sortie est au format XML. Les fichiers de sortie (par rubrique) de la BaO1 à étiqueter pour la BàO2 peuvent être consultables à cette adresse : TXT_XML_rub. On peut aussi y retrouver les résultats de l'étiquetage via TreeTagger. # ETIQUETAGE AVEC CORDIAL # L'usage de Cordial nécessite une phase de pré-traitement, en effet, le logiciel impose une limite de format et de taille pour le fichier d'entrée, d'où notre choix de prendre parmi les résultats de la BàO1 uniquement les sorties TXT des rubriques. Cordial exige aussi en entrée un encodage en ISO-8859-1. Les fichiers à traiter étant en UTF-8, on se charge de les convertir en ISO-8859-1 avec des commandes Unix : 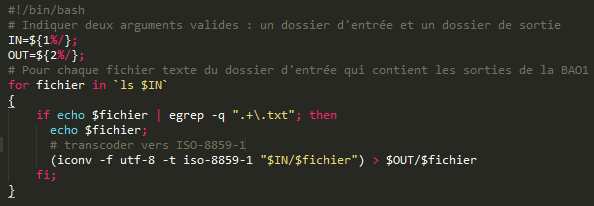
Pour étiqueter avec Cordial : ouvrir le fichier TXT à étiqueter, puis Syntaxe -> étiquetage de texte. Ensuite, il faut appliquer les paramètres de l'étiquetage avant de lancer le programme : 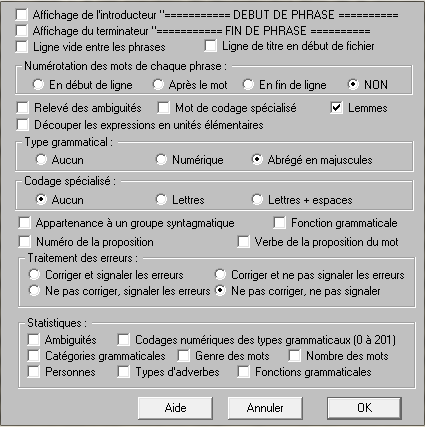 Tout processus d'étiquetage comprend une étape de segmentation de texte en tokens et une étape d'étiquetage de ces tokens. Apparemment, la segmentation est automatiquement effectuée par le logiciel Cordial avant l'étiquetage à proprement dit.
Le résultat est un fichier .cnr présentant sous forme de tableau le token suivi de son lemme et de sa catégorie syntaxique : 
Les principes de fonctionnement et les ressources liées au logiciel Cordial sont consultables à cette adresse.
# ETIQUETAGE AVEC TREETAGGER # Comme dit précédemment, l'étiquetage avec TreeTagger nécessite une modification du script de la BàO1 au niveau du parcours de l'arborescence, TreeTagger a en effet la possibilité d'être utilisé dans une interface en ligne de commande. Les principales modifications peuvent être visibles en rouge. 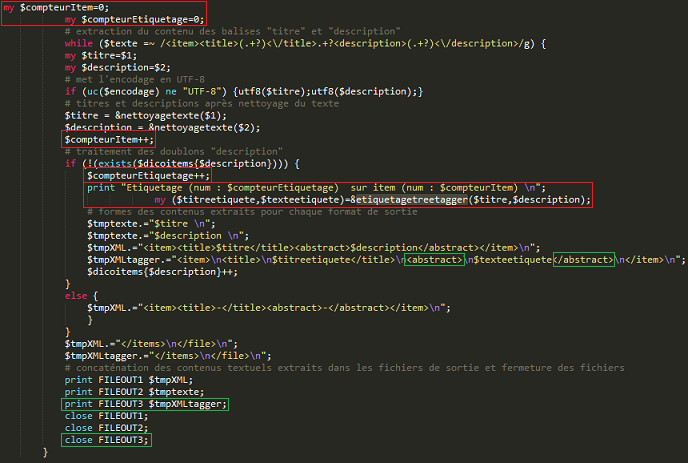
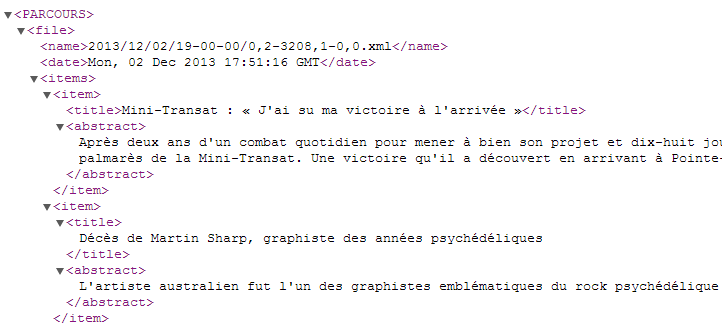
On peut voir que l'étiquetage est réalisé sur les contenus de type "titre" et "description", les compteurs permettent de traiter les items un par un sachant que chaque item est composé d'un titre et d'une description.
Bien sûr, le script original de la BàO1 subit aussi de petites modifications au niveau des sorties. Premièrement, il y a la création d'une troisième sortie FILEOUT3 pour les contenus extraits étiquetés, et deuxièmement, on change un peu les balises des sorties XML. De sorte que, <ROOT> soit remplacée par <PARCOURS> et <description> par <abstract>. Une partie de ces modifications mineures peut être visible en vert dans la capture d'écran précédente. 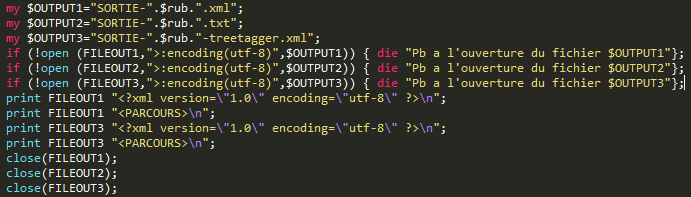
Voici la fonction associée à l'étiquetage : 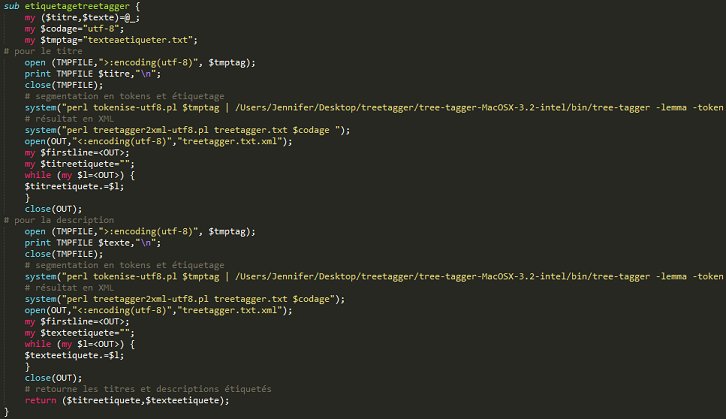
Regardons de plus près.
Le processus d'étiquetage comprend une étape de segmentation des contenus textuels en tokens avec le script Perl tokenise-utf8.pl (distribué avec TreeTagger et appelé par l'interface) et une étape d'étiquetage des tokens avec le logiciel TreeTagger. Avant d'étiqueter avec TreeTagger, il faut indiquer dans Perl le fichier d'entrée texteaetiqueter.txt stocké dans la variable $tmptag et le chemin où se trouve le logiciel pour pouvoir l'utiliser. Pour l'étiquetage morpho-syntaxique, on a choisi d'afficher avec la catégorie syntaxique, le lemme "-lemma" et le mot étiqueté "-token". En plus de ces options d'étiquetage, il faut aussi veiller à ne pas oublier de préciser le chemin du fichier de paramètre de la langue fourni par la bibliothèque de TreeTagger, french-utf8.par (français UTF-8) : 
Le résultat de l'étiquetage avec TreeTagger est semblable au résultat de l'étiquetage avec Cordial, on a un tableau avec une colonne token, une colonne lemme et une colonne catégorie syntaxique mais dans un fichier de sortie TXT : > treetagger.txt.
La sortie doit être sous format XML, on utilise donc le script treetagger2xml-utf8.pl pour convertir le format : 
Les résultats XML de l'étiquetage TreeTagger ont un avantage en terme de structuration et de lisibilité mais le traitement via Perl / TreeTagger est beaucoup plus long que celui via Cordial. Voici un exemple de résultat : 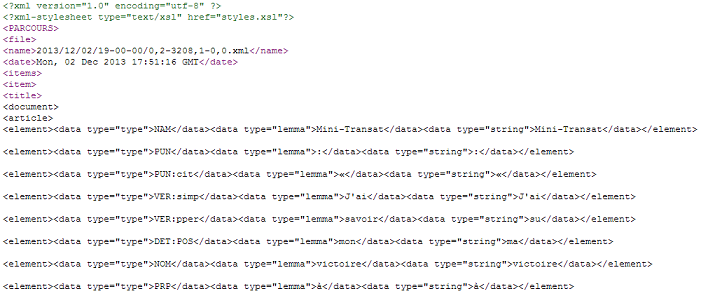
Et voici un aperçu de ce que cela peut donner une fois que le document XML est transformé avec une feuille de style : 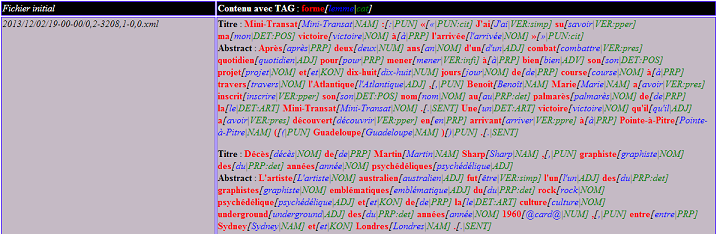
Les principes de fonctionnement et les ressources liées au logiciel TreeTagger sont consultables à cette adresse.
|
|
|