Script
Voici le descriptif du script bash qui a servi à générer les tableaux répertoriant les URLS, les fichiers et les contextes du mot analysé en français et en arabe.
Vous pouvez le télécharger ici !
En résumé...
Au cours du premier semestre, nous avons opté pour l’étude du terme « banlieue » en trois langues : le français, l’arabe et le slovaque pour les raisons explicitées ici.
Notre hypothèse de départ était que le mot « banlieue » présentait un emploi spécifique à l’imaginaire collectif français (de France) qui ne serait pas le même en Algérie ni en Slovaquie.
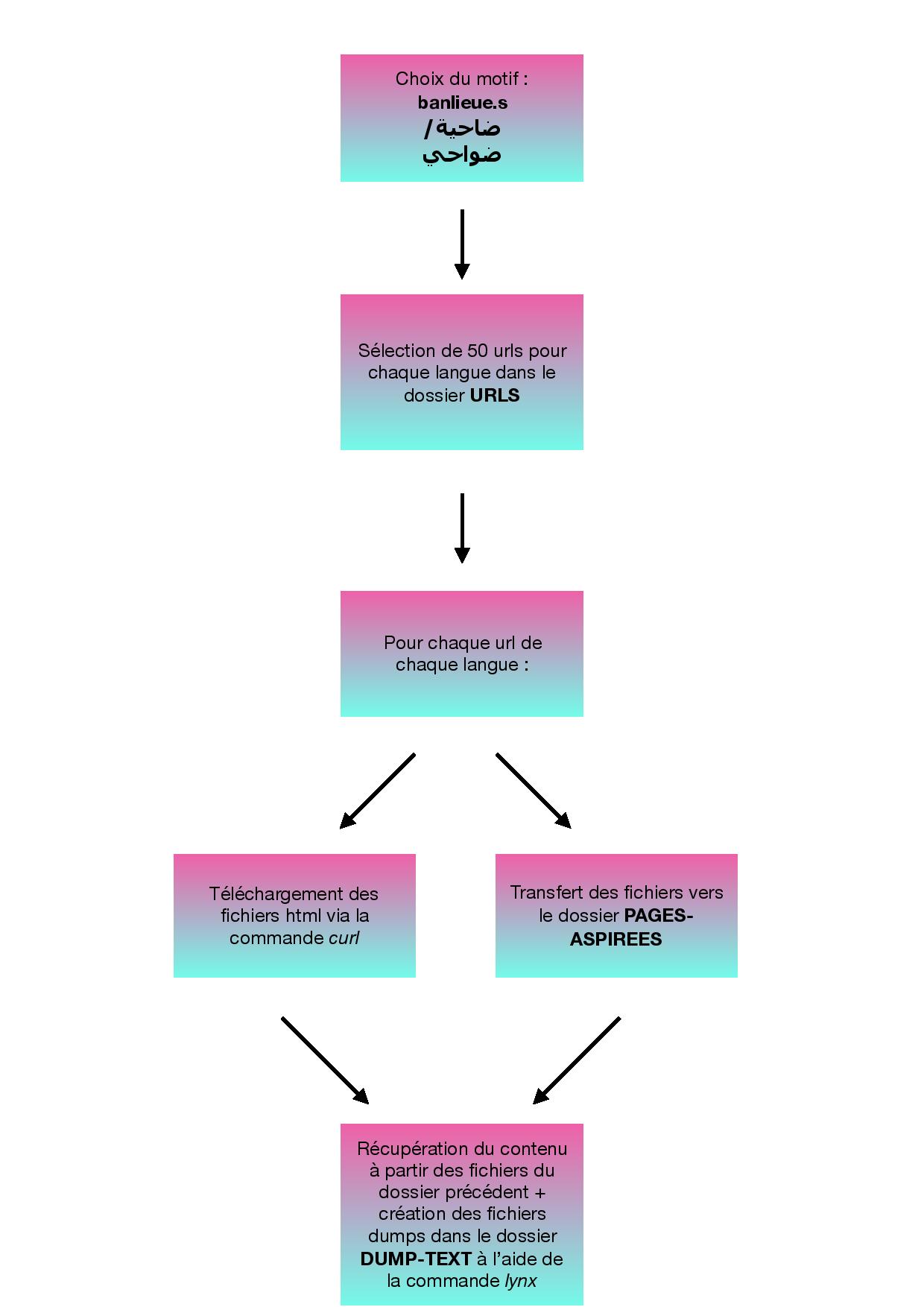
De ce fait nous avons commencé par rassembler 50 urls de presse pour chaque langue avec notre motif. Ensuite, extraire le motif des pages avec ses contextes et enfin, afficher les résultats dans un tableau html.Pour ce faire, nous avons traduit cet algorithme en un programme bash, c’est-à-dire, transformer cette suite logique d’opérations en une succession d’instructions exécutables par l’ordinateur et définissant les opérations à réaliser dans le but d’atteindre un résultat précis.
A cet effet, notre projet se divise en deux parties :
- La première qui comprend l’écriture du programme et qu’on peut schématiser comme suit :

- La seconde partie consiste en l’analyse textométrique à partir des fichiers dumps concaténés. Elle contient la génération de nuages des mots et l’exploration textométrique des cooccurrents. Les résultats obtenus avec iTrameur sont accessibles ici, et l'analyse textométrique ainsi que les nuages de mots de ces résultats sont affichés ici.
Pour parvenir à l’obtention des résultats escomptés, nous avons tenu un blog tout au long du semestre pour y partager, étape par étape, l’écriture du script ainsi que les obstacles rencontrés et les solutions trouvées au cours de la réalisation du projet.
Bonne navigation !