L'enjeu de cette étape est de réussir à extraire, sur l'intégralité de l'arborescence, les contenus textuels pertinents pour notre projet et de les concaténer en un seul fichier, dont on se servira pour les étapes suivantes. On veut obtenir un fichier par rubrique. Notre corpus étant une arborescence, il va falloir le parcourir pour aller chercher uniquement les fichiers xml qui nous intéressent, soit les fichiers correspondant au flux RSS d'une rubrique du journal.
Tous les fichiers xml ont la même structure ce qui nous permet d'élaborer un seul script pour aller récupérer automatiquement les contenus pertinents. Dans chaque fichier, on veut extraire les contenus de deux balises : les balises titres (<title>) et descriptions (<description>). Ces deux types de balises sont des couples correspondant à la mise à jour d'un article et sont situées au sein de balises <item>. Plusieurs méthodes différentes permettant de récupérer ces informations ont été vues en cours et seront détaillées ci-après. Pour les deux premières solutions, l'élaboration du script d'extraction a été prévue pour fonctionner sur un seul document. Le parcours récursif de l'arborescence a ensuite été intégré dans les programmes. Ce parcours s'effectue grâce à la fonction fournie en cours (qui intègre déjà l'extraction par expression régulière).
Extraction grâce à des expressions régulières
Ecrit en Perl, ce script a pour objectif de mimer le comportement d'un Egrep Unix. Comme on connaît la structure de nos fichiers XML, on peut élaborer une expression régulière qui va 'matcher' les motifs qui nous intéressent et garder en mémoire les portions qu'on souhaite réutiliser grâce aux parenthèses. Mais quelques traitements ont été effectués au préalable pour pourvoir utiliser l'expression régulière qui suit. Tout d'abord, j'ai enlevé de $ensemble tous les espaces, retours à la ligne etc. (grâce à '\s') qui se trouvaient entre deux balises pour qu'elles soient collées. Ensuite, j'ai transformé les balises <description/> en '<description> </description>. En effet, lors de versions précédentes du programmes, certains titres manquaient à l'appel dans les fichiers résultats. Après avoir observé les fils RSS, j'ai remarqué que les titres absents étaient tous suivis d'une balise <description/>. Afin de conserver une seule expression régulière pour extraire l'intégralité des titres, j'ai préféré modifier le fichier en amont et donc remplacer les balises qui me gênaient.
- Expression régulière pour 'matcher' les contenus textuels des balises titres et descriptions : <item><link>.+?<\/link><title>([^<]+?)<\/title><description>([^<]+?)<\/description>
Le principe de ce script est donc assez simple. L'utilisateur lance le programme en mettant en argument le nom du répertoire à parcourir et l'identifiant de la rubrique qu'on souhaite étudier. Le script récupère ces données et les utilise pour parcourir l'arborescence fournie à la recherhce de fichier xml contenant l'identifiant de rubrique dans leur nom. Quand il tombe sur un de ces fichiers, il le lit et stocke chacune de ses ligne dans une variable appelée $ensemble (en enlevant les retours à la ligne). C'est dans cette variable qu'on recherche l'expression régulière indiquée précédemment. On n'oublie pas d'utiliser l'option 'g' de la fonctionnalité de recherche Perl, qui indique qu'on veut faire une recherche globale (i.e. on ne souhaite pas s'arrêter à la première occurrence rencontrée). Tant que le programme rencontre des portions correspondant à ce qui est cherché, les motifs sont affectés aux variables $titre et $description. On vérifie que le titre n'a pas déjà été trouvé auparavant grâce à une table de hashage dans laquelle on a rangé tous les titres rencontrés. Si le titre est nouveau, on applique une procédure de nettoyage (pour remplacer les entités xml par les 'vrais' caractères, principalement) sur $titre et $description. Ce sont les contenus nettoyés qu'on écrit ensuite dans les documents de sortie.
Le résultat d'exécution du programme est composé de deux fichiers : un fichier texte, où chaque titre est précédé d'un signe § ; un fichier XML où les couples titre/description sont contenus au sein de balises <item> (avec des balises <titre> et <description>). Le progamme se lance comme suit :
Le programme et les résultats obtenus pour chaque rubrique sont disponibles ci-dessous.
Extraction grâce à XML::RSS
Cette seconde méthode utilise une fonctionnalité de Perl particulière : la bibliothèque XML::RSS. C'est ce module qui permet d'extraire les contenus des balises <title> et <description>. Tout ce qui est autour reste identique au programme précédent : il faut toujours fournir en argument le nom du répertoire et l'identifiant de la rubrique ; le parcours de l'arborescence s'effectue de la même manière ; quand les titres et les descriptions ont été sortis par XML::RSS, on les nettoie ; en sortie, on a deux fichiers, un texte et un xml.
En revanche, pour pouvoir utiliser XML::RSS, il faut qu'il soit disponible sur notre Perl ! Je travaille sur Cygwin et l'installation du module sur le Perl du Cygwin est laborieuse... Pour contourner le problème, j'ai installé le module sur le Perl de mon ordinateur (via l'invite de commande Windows) puis sur Cygwin je spécifie bien que je veux utiliser la version du Perl de mon ordinateur. Le programme se lance donc comme suit :
Le programme et les résultats obtenus pour chaque rubrique sont disponibles ci-dessous.
Extraction grâce à XQuery, via BaseX
Une autre solution pour extaire les titres et les descriptions a été vue en cours : il s'agit d'une requête XQuery, lancée sur le logiciel BaseX. Cette technique a surtout été abordée dans le cours L8DNI1-Document structuré, je ne la détaillerai donc pas beaucoup ici. Afin de pouvoir fouiller notre arborescence sur BaseX, il faut créer une base de données. On peut spécifier un motif que le logiciel utilisera pour sélectionner les fichiers xml qu'il rencontre. Une première base de données pourrait donc être créée avec l'identifiant de rubrique "3208", par exemple. Ensuite, on peut effectuer notre requête pour extraire les titres et les descriptions.
- Requête XQuery pour extraire les contenus textuels des balises titres et descriptions : for $document in collection("ex12-2017") for $item in $document//item let $titre:=<titre>{$item/title/text()}</titre> let $description:=<description>{$item/description/text()}</description> return <item>{$titre,$description}</item>
Voici une capture d'écran du résultat obtenu sur BaseX
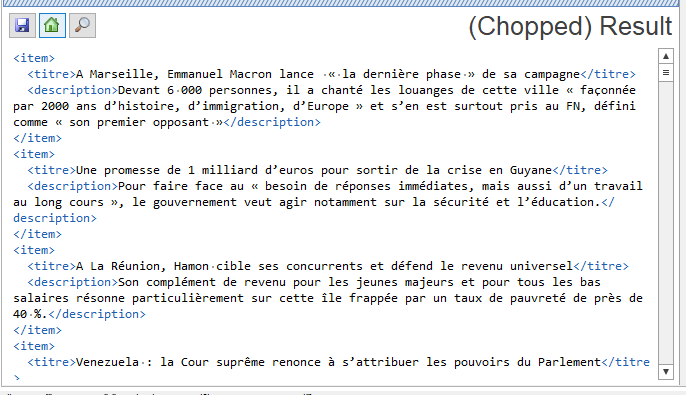
N.B. : je n'ai pas téléchargé les résultats, mais cela aurait été possible en appuyant sur l'icône 'save'.
Comparaison des scripts : avec RegEx ou avec XML::RSS ?
Les contenus des résultats obtenus grâce aux deux programmes sont sensiblement les mêmes. Cependant, on notera que les retours à la ligne ne sont pas encodés de la même manière : en Unix pour le scirpt avec les expressions régulières et en Windows pour l'autre. En comparant les fichiers textes avec le module 'Compare' de Notepad++, j'ai observé une seule différence, d'ailleurs minime. Elle est due à la modification que j'ai effectuée pour me débarrasser des balises <description/>. J'avais ajouté un espace entre les deux balises de remplacement qui se retrouve dans les résultats, seul sur une ligne qui aurait dû contenir une description dans le fichier résultat du script avec RegEx. XML::RSS, quant à lui, n'a tout simplement rien renvoyé dans le cas des balises description auto-fermantes : la ligne de description est donc tout simplement vide.
Voici des captures d'écran qui montrent la visualisation d'un exemple de différence entre fichiers textes avec Notepad++. Le test a été effectué avec les résultats pour la rubrique 3208.


Selon moi, le point qui oppose le plus les deux méthodes d'extraction est la vitesse d'exécution. Le script avec les expressions régulières a fourni des résultats très rapidement, mais XML::RSS était beaucoup plus lent. Cette lenteur, si elle est tolérable pour une simple extraction de données, est plus gênante lorsqu'on commence à étiqueter les contenus : l'étiquetage étant déjà long, attendre encore plus à cause de XML::RSS peu être irritant...