A partir des fichiers étiquetés (XML avec TreeTagger2XML et .cnr avec Cordial) on peut extraire des patrons syntaxiques. Ces patrons vont permettre d'établir des terminologies pour chaque rubrique et de les contraster entre elles. Une terminologie correspond à " l'ensemble des termes, rigoureusement définis, qui sont spécifiques d'une science, d'une technique, d'un domaine particulier de l'activité humaine", d'après Wikipedia. Pour notre projet, nous allons donc tenter de voir, à travers l'étude de patrons syntaxiques, quels sont les termes caractéristiques de chaque rubrique.
Le choix des patrons à extraire est primordial pour obtenir des termes pertinents. Les noms, les adjectifs et les verbes seront les termes clés que nous allons observer. Les patrons à extraire seront donc dans un premier temps : NOM-ADJ et ADJ-NOM ; NOM-PREP-NOM (avec peut-être des variantes si on veut inclure les noms propres). Pour les patrons avec des verbes, on part du principe que dans notre corpus issu de la presse écrite, les sujets nominaux ne seront pas rares (ce qui est le cas à l'oral), on tentera donc de regarder les patrons : NOM-VERBE-NOM et NOM-VERBE-PREP-NOM. A chaque fois, si nécessaire, on incluera des déterminants. Une fois encore, plusieurs méthodes existent pour réaliser la tâche qu'on souhaite effectuer. On utilisera un script Perl avec des expressions régulières, des feuilles xsl et des requêtes XQuery. Bien entendu, les deux dernières méthodes ne valent que pour les fichiers XML.
Perl et expressions régulières
Cette première méthode sert à analyser les fichiers Cordial. Le script prend en argument le nom du fichier Cordial à traiter et le nom du fichier de patron à extraire. On a élaboré un fichier par patron. Le problème au cœur de ce script était de pouvoir rechercher des patrons dans un document vertical (un item sur une ligne), à l'aide d'expressions régulières qui fonctionnent horizontalement (soit ligne à ligne). Il fallait donc 'rétablir l'horizontalité du texte' (pour reprendre les mots de J.-M.D.). Cela a été possible grâce à une autre RegEx : pour chaque ligne, on a mémorisé la forme et la POS qu'on a ensuite concaténées, entre elles avec un "_" et avec les autres éléments de la phrase par un " ". A chaque fois qu'on rencontre une ligne avec un 'PCTFORTE', cela signifie qu'on est arrivé à la fin d'une phrase et qu'on s'arrête.
- Conditions pour récupérer la forme et la POS :if (($ligne=~/^([^\t]+)\t[^\t]+\t([^\t]+)$/) and ($ligne!~/PCTFORTE/))
- Concaténation :$chaine=$chaine.$POS."_".$forme." ";
Quand on rencontre une ligne qui correspond à la fin d'une phrase (ou qui ne correspond plus à la forme 'token lemme POS'), on ouvre le fichier contenant le patron. Chaque ligne correspond à un patron à retrouver. On transforme le patron en expression régulière et on stocke le tout dans une variable $motif. Ensuite, on recherche ce motif dans notre phrase recomposée : s'il y a une correspondance, on la récupère grâce à la variable par défaut $& qu'on affecte à la variable $correspondance, puis on enlève l'étiquette de POS pour ne garder que la forme. Le script renvoie cette correspondance nettoyée.
- Transformation du patron en RegEx :$motif=~s/([^ ]+)/$1_\[\^ \]\+/g;
- Nettoyage de la correspondance trouvée$correspondance=~s/[A-Z]+\d?[A-Z]?_//g;
Le script d'extraction de patrons est disponible ci-dessous.
Premier patron
Le premier patron vise à extraire les structures 'NOM-PREP-NOM', peut importe le genre, le nombre du nom ou s'il s'agit d'un nom propre ou d'un nom commun. Toutes les étiquettes de Codial pour les noms (cf. le tagset disponible dans la Boîte à Outils 2) commencent par un N majuscule. D'autres lettres suivent, toujours au moins deux et au maximum cinq. De plus, je veux récupérer les noms propres et les noms communs, la seule lettre que je spécifie est donc N mais parmi les étiquettes des verbes, quand il s'agit de l'indicatif, il y aussi la lettre N : la RegEx récupère donc parfois des verbes ! Heureusement, dans ces cas-là, l'étiquette comporte également des nombres (pas que des lettres), je spécifie donc que je ne veux que des lettres après mon N, grâce à [A-Z]. Notre patron sera donc : N[A-Z][A-Z][A-Z]?[A-Z]?[A-Z]? PREP N[A-Z][A-Z][A-Z]?[A-Z]?[A-Z]?. Le résultat de l'extraction par le script s'affiche sur le terminal (pas de fichier de sortie créé). Au moment du lancement, on en profite donc pour enchaîner l'exécution du script avec des commandes Bash qui permettent de supprimer les doublons, de compter les résultats et de les trier par ordre de fréquence croissante. On redirige ensuite le tout dans un fichier de résultat. Le script se lance donc comme suit :
ATTENTION ! Avant de lancer le script, il faut s'assurer que les fichiers .cnr ont été reconverti en UTF-8 et en format Unix, autrement l'extraction ne fonctionnera pas. (Cordial retourne des fichiers Windows ANSI)
Le fichier de patron et les résultats pour chaque rubrique sont disponibles ci-dessous.
En observant les résultats obtenus pour ce patron sur les trois rubriques différentes, on remarque que les rubriques "A la une" (3208) et "International" (3210) ont des terminologie proches, comparées à celle de la rubrique "Culture" (3246), comme on pouvait facilement le supposer. L'image ci-dessous montre les vingt plus fréquentes structures N-PREP-N.
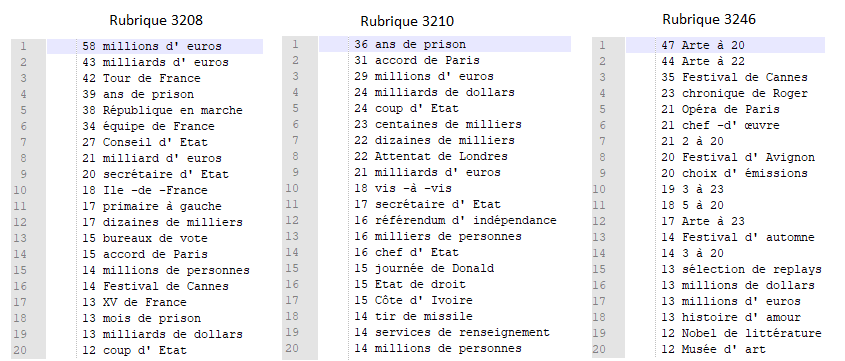
Il est tout de même amusant de constater que les deux seuls points communs entre ces trois extraits de terminologie sont "millions de dollars" et "millions d'euros". L'argent semble donc être une préoccupation centrale, que ce soit à la une, à l'international ou dans la culture... Notons aussi que les résultats pour la culture sont moins parlants à cause de la présence d'expressions comme "3 à 23", "5 à 20" etc. Je ne sais pas trop à quoi cela renvoie mais je doute que ça soit réellement pertinent. Cordial est peut-être à blâmer ici puisqu'il a considéré ces nombres comme des noms...
Deuxième patron
Le deuxième patron sert à extraire les structures NOM-ADJ, encore une fois, sans distinction de genre, de nombre etc. Pour les étiquettes d'adjectifs, on peut avoir de une à trois lettres après 'ADJ'. Le patron est donc : N[A-Z][A-Z][A-Z]?[A-Z]?[A-Z]? ADJ..?.?. Comme je veux également inclure les patrons ADJ-NOM (je veux avoir toutes les associations de nom et d'adjectif, peu importe l'ordre), j'ajoute une deuxième ligne sur le fichier de patron : ADJ..?.? N[A-Z][A-Z][A-Z]?[A-Z]?[A-Z]?. A noter également que les 'adjectifs numériques ordinaux' et 'cardinaux' seront inclus dans les résultats.
Le fichier de patron et les résultats pour chaque rubrique sont disponibles ci-dessous.
Une fois encore, on compare les vingts structures les plus fréquentes pour les résultats N-ADJ/ADJ-N des trois rubriques. Comme le montre l'image ci-dessous, les résultats confirment encore la proximité des rubriques "A la une" et "International" (sur ces vingts expressions, plus de la moitié sont en commun entre les deux rubriques).
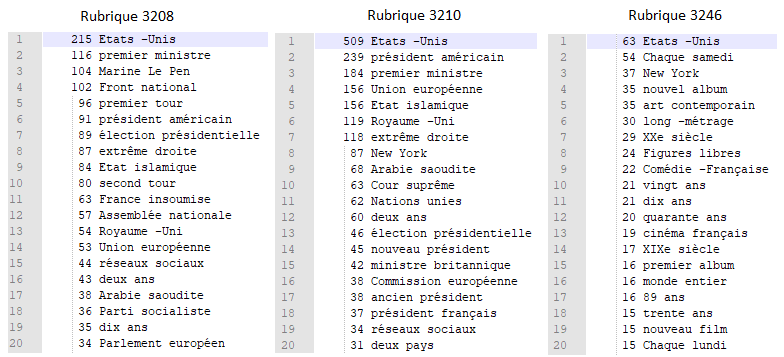
Que ce soit à la une ou à l'international, on parle beaucoup "d'extrême droite", "d'élection présidentielle" et des "Etats-Unis". Cette fois-ci, ce qui semble unir la culture et les deux autres rubriques ce sont les "Etats-Unis", qui arrive en tête à chaque fois. Petit bémol, les "Etats-Unis" restent un nom propre, on aurait peut-être aimé qu'il ne soit pas reconnu en séquence NOM-ADJ, mais c'est tout de même intéressant de voir la place très importante qu'ils occupent dans un journal comme Le Monde. Pour revenir sur la rubrique "A la Une", grâce à cette terminologie, on voit bien la couverture médiatique très importante dont ont bénéficié les élections présidentielles durant l'année 2017.
Toisième et dernier patron
Pour ce dernier patron, j'ai choisi d'extraire les séquences du type N-VERBE-DET-N. Les déterminants peuvent avoir de trois à cinq lettres pour les spécifier après le 'DET'. Les étiquettes pour les verbes sont très nombreuses. J'ai décidé de me concentrer sur les verbes conjugués aux temps simples. Le patron est donc : N[A-Z]{2}[A-Z]?[A-Z]?[A-Z]? V[^P][A-Z]{2}... DET....? N[A-Z]{2}[A-Z]?[A-Z]?[A-Z]?.
Le fichier de patron et les résultats pour chaque rubrique sont disponibles ci-dessous.
L'extrait des résultats des vingts expressions les plus fréquentes montrent que ce patron n'est pas aussi pertinent que les autres pour déterminer la terminologie des rubriques, puisque la fréquence maximale est de 3 à 8 occurrences. On constate aussi que Cordial a confondu le point cardinal "Est" et le verbe être conjugué "est". Point intéressant cependant, si on écarte l'erreur d'annotation de Cordial, il n'y a cette fois-ci aucune structure en commun entre les différentes rubriques.
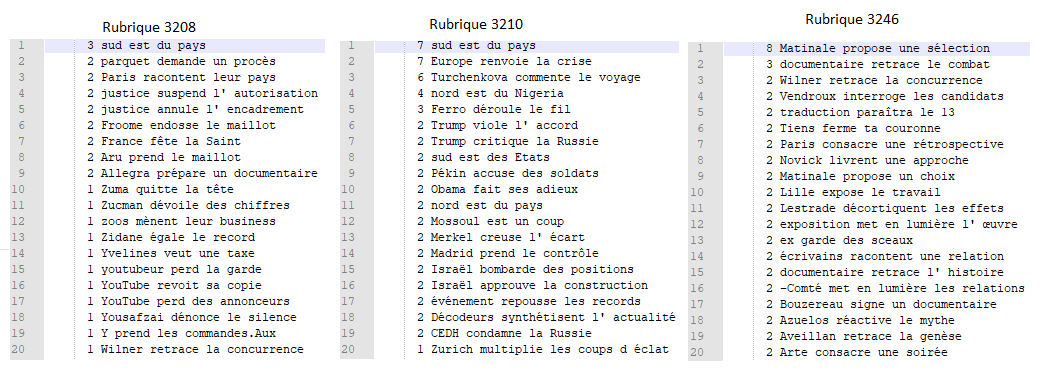
Si on regarde bien, on peut aussi remarquer que dans la rubrique "International", les noms à gauche reflètent bien le caractère "international" : "Europe", "Trump", "Pékin", "Obama", "Mossoul" etc. Ce qui n'apparait pas dans les autres rubriques.
Feuilles xsl
Pour extraire des patrons des résultats de TreeTagger et TreeTagger2XML, on peut utiliser des feuilles xsl. En choisissant la méthode de sortie texte et en utilisant la commande 'xsltproc' sur Cygwin, on obtient des fichiers de résultats similaires à ceux vus précédemment (on a aussi enchaîné le lancement avec les commandes Bash pour trier et compter les résultats). La transformation xsl se lance donc comme suit :
Les patrons choisis sont les mêmes que précédemmment. Il y a une feuille xsl par patron.
Premier patron
Le premier patron extrait les structures 'NOM-PREP-NOM'. L'étiquetage de TreeTagger est moins complexe que celui de Cordial (cf. le tagset de TreeTagger disponible via la Boîte à outils 2), il y a donc moins de cas de figure à prendre en compte. Il faut seulement faire attention à l'alternance entre 'NAM' pour les noms propres et 'NOM' pour les noms communs si on veut avoir des résultats semblables à ceux de Cordial.
La feuille XSL et les résultats pour chaque rubrique sont disponibles ci-dessous.
Comme l'étiquetage est différent, les résultats obtenus ne sont pas identiques, bien entendu, à ceux dérivés des fichiers Cordial. On se souvient que TreeTagger ne segmentait pas bien les "d' " et qu'il avait tendance à repérer les nombres comme des cardinaux, ce qui expliquerait la disparition de "millions d'euros", "millions de dollars", "dizaines de milliers" etc. Le fait que ces expressions n'apparaissent plus laisse plus de place pour les autres. "Tour de France" arrive donc en tête dans la rubrique "A la Une" (avec le même nombre d'occurrence que ce qui avait été trouvé dans les fichiers Cordial). En revanche, un point positif de TreeTagger : il reconnait "Etats-Unis" comme un nom propre ! C'est donc "président des Etats-Unis" qui passe en tête pour la rubrique "International" (cette expression était absente dans les premiers résultats). Par contre, je ne m'explique pas la disparition de "ans de prison" (qui avait tout de même 36 occurrences dans le fichier Cordial). Les résultats pour la rubrique "Culture" sont très différents à cause de la disparition des nombres. C'est le "Festival de Cannes" qui est cette fois le plus représenté.

La proximité entre les rubriques se voit de manière différente. "Culture" et "A la Une" ont plusieurs termes en commun : "Festival de Cannes", "Ville de Paris" et "Matinale du Monde". Le festival de Cannes est sûrement l'évènement culturel qui bénéficie d'une couverture médiatique plus large. Pour "Ville de Paris", il est possible que le terme ne soit pas associé aux mêmes éléments dans les deux rubriques. "Matinale du Monde" est également présent dans "International", je suppose qu'il s'agit d'une sorte de pub au sein du journal pour une de leur rubrique... On peut aussi constater une apparition plus prononcée du sport dans "A la Une", la rubrique est maintenant moins proche de "International".
Deuxième patron
Le deuxième patron extrait les structures NOM-ADJ. Comme précédemment, pour les noms on a seulement la différence entre 'NAM' et 'NOM' à prendre en compte. Sur une même feuille XSL, on a pu réunir les séquences 'NOM-ADJ' et 'ADJ-NOM', comme pour le script d'extraction sur les fichiers Cordial.
La feuille XSL et les résultats pour chaque rubrique sont disponibles ci-dessous.
Les résultats sont une fois encore chamboulés par la différence d'étiquetage : il n'y a quasiment plus d'adjectifs numériques et les Etats-Unis ont disparu des listes (alors qu'ils étaient en tête partout précédemment). Les rubriques "A la une" et "International" sont moins proches : elles ont moins de la moitié des termes en commun. Par contre un défaut de TreeTagger apparait ici en force : son incapacité à segmenter les mots avec des apostrophes fait surgir une même expression plusieurs fois ("Etat Islamique" vs "l'Etat Islamique", par exemple) et fausse le comptage d'occurrences.

Un point commun apparait entre "A la Une" et "Culture" : le "jeu vidéo". Les "réseaux sociaux" font, quant à eux, le lien entre les trois rubriques. Globalement, les résultats de pour la rubrique culture sont quand même plus pertinents (disparition des expressions avec des adjectifs numériques, notamment).
Toisième et dernier patron
Le dernier patron extrait les séquences du type N-VERBE-DET-N. Cette fois, il n'y avait pas vraiment la possibilité d'extraire seulement les verbes conjugués aux temps simples. Cependant, étant donné l'enchainement très spécifique de POS que je chercher à récupérer, il y a peu de chance qu'autre chose soit renvoyé (en effet, un verbe composé aura deux verbes à la suite l'un de l'autre et un verbe non conjugué a peu de chance d'être entre un nom et un déterminant)..
La feuille XSL et les résultats pour chaque rubrique sont disponibles ci-dessous.
Les résultats sont toujours aussi peu pertinents. On peut tout de même noter la disparition de "sud est..." et "nord est...". Par contre, des participes présents font leur apparition.

Les résultats diffèrent peut-être un peu moins que pour les autres patrons, sûrement à cause du peu d'occurrences du patrons N-V-DET-N...
Requêtes XQuery
Une autre façon de fouiller les données des fichiers XML est de faire des requêtes XQuery, en passant par le logiciel BaseX. Cette méthode a beaucoup été utilisée pour le cours L8DNI1-Document Structuré et ne sera donc pas détaillée ici. A chaque fois, les résultats ont été enregistrés puis triés et comptés grâce aux commandes Bash. De plus, il a fallu créer une nouvelle base de données pour chaque fichier et donc bien entendu changer le nom du document que l'on parcourt (seules les requêtes pour "3208" ont été affichées ici, puisque pour les autres la seule différence est le nom du document).
Premier patron
Pour l'extraction, on fait une fois encore attention a prendre en compte l'alternance nom propre/nom commun. Cela est possible grâce au 'or' qui permet de rendre compte de l'alternative dans le filtrage des résultats à renvoyer.
- Requête pour extraire le patron N-P-N :for $article in doc("sortie_2017-3208")//article for $element in $article/element let $nextElement := $element/following-sibling::element[1] let $nextElement2 := $element/following-sibling::element[2] where ($element/data[1] = "NOM" and $nextElement/data[1] = "PRP" and $nextElement2/data[1] = "NOM") or ($element/data[1] = "NOM" and $nextElement/data[1] = "PRP" and $nextElement2/data[1] = "NAM") or ($element/data[1] = "NAM" and $nextElement/data[1] = "PRP" and $nextElement2/data[1] = "NAM") or ($element/data[1] = "NAM" and $nextElement/data[1] = "PRP" and $nextElement2/data[1] = "NOM") return (concat($element/data[3]/text()," ",$nextElement/data[3]/text()," ",$nextElement2/data[3]/text()))
Les résultats triés et comptés de l'extraction sont disponibles ci-dessous.
Etonnamment, les résultats ne sont pas identiques à ceux obtenus avec les feuilles XSL. C'est un mélange des deux résultats précédemment détaillés (on observe le retour de "ans de prison" et de "miliards de dollars", par exemple) avec l'apparition de nouveaux éléments comme "chef de l'Etat". Il est très étrange que cette expression ne soit pas apparue avant puisqu'apparemment, il y en a 72 occurrences dans la rubrique "A la une" et 60 dans "International", ce qui en fait d'ailleurs à chaque fois le terme le plus fréquent.

Malgré ce changement de résultats, les rubriques 3208 et 3210 restent plus proches entre elles qu'avec la rubrique 3246, qui se retrouve cette fois sans élément commun avec les autres rubriques.
Deuxième Patron
Pour extraire les séquences NOM-ADJ et ADJ-NOM, il est également nécessaire d'utiliser le 'or'.
- Requête pour extraire le patron NOM-ADJ :for $article in doc("sortie_2017-3208")//article for $element in $article/element let $nextElement := $element/following-sibling::element[1] where ($element/data[1] = "NOM" and $nextElement/data[1] = "ADJ") or ($element/data[1] = "NAM" and $nextElement/data[1] = "ADJ") or ($element/data[1] = "ADJ" and $nextElement/data[1] = "NOM") or ($element/data[1] = "ADJ" and $nextElement/data[1] = "NAM") return (concat($element/data[3]/text()," ",$nextElement/data[3]/text()))
Les résultats triés et comptés de l'extraction sont disponibles ci-dessous.
Cette fois on a bien ce à quoi on aurait pu s'attendre : des résultats identiques pour l'extraction du patron syntaxique N-ADJ/ADJ-N avec une feuille XSL et avec la requête XQuery.

La différence peut-être due à plusieurs facteurs. Soit ma feuille XSL et ma requête ne sont pas aussi similaire que je le pensais (j'ai pourtant du mal à voir où se trouve la différence) ; soit les méthodes d'extraction étant différentes, certains résultats passent entre les mailles du filet ; soit il y a eu un problème au moment du trie et du comptage (je doute cependant que ce soit...).
Troisième et dernier patron
Lors de l'extraction du dernier patron, il faut utiliser contains() pour repérer les verbes et les déterminants. Comme leur étiquette est spécifiée, il n'y aura jamais de correspondance exacte avec juste 'VER' ou 'DET'. contains() permet de tester le fait que les chaîne de caractère soient bien là, ce qui permet de récupérer le patron qui nous intéresse malgré tout.
- Requête pour extraire le patron N-V-N :for $article in doc("sortie_2017-3208")//article for $element in $article/element let $nextElement := $element/following-sibling::element[1] let $nextElement2 := $element/following-sibling::element[2] let $nextElement3 := $element/following-sibling::element[3] where ($element/data[1] = "NOM" and $nextElement/data[1][contains(text(),"VER")] and $nextElement2/data[1][contains(text(),"DET")] and $nextElement3/data[1] = "NOM" ) or ($element/data[1] = "NOM" and $nextElement/data[1][contains(text(),"VER")] and $nextElement2/data[1][contains(text(),"DET")] and $nextElement3/data[1] = "NAM" ) or ($element/data[1] = "NAM" and $nextElement/data[1][contains(text(),"VER")] and $nextElement2/data[1][contains(text(),"DET")] and $nextElement3/data[1] = "NOM" ) or ($element/data[1] = "NAM" and $nextElement/data[1][contains(text(),"VER")] and $nextElement2/data[1][contains(text(),"DET")] and $nextElement3/data[1] = "NAM" ) return (concat($element/data[3]/text()," ",$nextElement/data[3]/text()," ",$nextElement2/data[3]/text()," ",$nextElement3/data[3]/text()))
Les résultats triés et comptés de l'extraction sont disponibles ci-dessous.
Les résultats de cette extraction sont quasiment identiques à ceux obtenus avec la feuille XSL. Pour les rubriques "A la Une" et "International", quelques expressions manquent à l'appel, mais globalement tout est similaire.

Cela reste tout de même étrange de ne pas avoir exactement les mêmes résultats.
Extraction de patrons : expressions régulières, feuilles XSL ou XQuery ?
Nous avons donc vu trois méthodes très différentes pour extraires les patrons syntaxiques. Avec les fichiers de résultats Cordial, seule la méthode avec des expressions régulières pouvait fonctionner puisque nous n'avions pas affaire à des fichiers XML. Les résultats de l'extraction étaient à mon avis satisfaisants dans la mesure où ils permettaient de contraster les différentes rubriques. On est ensuite limité par la qualité des données de base : si l'étiquetage est erroné, on ne peut rien y faire... Pour les fichiers XML, plusieurs solutions étaient possibles. Je pensais qu'elles donneraient des résultats identiques mais cela n'a pas été le cas (et je ne suis pas tout à fait sûre de savoir pourquoi). Les résultats obtenus, même s'ils sont différents entre eux, confirment à chaque fois les grandes lignes trouvées avec les résultats de Cordial.
D'après les extractions de patrons syntaxiques, on voit donc bien que les rubriques "A la une" et "International" parlent de sujets assez similaires, laissant la rubrique "Culture" à part. La rubrique 3208 contient des éléments plus diversifiés, allant des élections présidentielles au sport, en passant par les grands évènements culturels. La rubrique 3210 reste quant à elle plutôt cantonnée à l'actualité politique à travers le monde et évoque donc plutôt l'Union Européenne, le président américain ou les dangers du terrorisme (attentats etc.). La rurique 3246 parle sans surprise de culture, qu'elle soit cinématographique ou non.
Enfin, un autre point essentiel à évoquer est la pertinence des patrons. Si des résultats intéressants ont été obtenus avec les patrons NOM-ADJ et NOM-PREP-NOM, ceux du patron NOM-VERBE-DET-NOM manquaient d'intérêt car peu nombreux (ou plutôt trop diversifiés). La morphologie verbale est très complexe en français, ce qui fait qu'un verbe prendra des formes très différentes selon le temps, le mode, la personne et le nombre auxquels il est conjugué. Pour extraire des patrons syntaxiques contenant des verbes, il serait peut-être plus intéressant de passer par les lemmes pour avoir une vue un peu plus regroupée des termes existants.
Pour finir, je voudrais signaler que nombreuses autres solutions existent pour extraire les patrons syntaxiques. Il était notamment possible de faire un script avec des expressions régulières pour extraire les patrons depuis les fichiers XML. Dans ce document zippé se trouvent des solutions alernatives proposées par SF et J.-M.D. : AutresSolutions.zip