Quand on a réussi à extraire les contenus textuels des balises <title> et <description> de tous les fichiers xml correspondant aux rubriques que nous avons choisies d'étudier, il faut étiqueter ces extractions. C'est grâce à l'étiquetage morpho-syntaxique qu'on pourra ensuite extraire des patrons morpho-syntaxiques. De même que pour l'extraction, plusieurs méthodes sont possibles. Elles ont impliqué TreeTagger puis TreeTagger2XML et Cordial.
TreeTagger et TreeTagger2XML
L'utilisation de TreeTagger et de TreeTagger2XML a été incorporée dans les scripts d'extraction (cf. boîte à outils 1). Une procédure d'étiquetage a été rajoutée. Les scripts donnent maintenant en sortie un fichier texte (le même que précédemment) et un fichier XML avec les textes étiquetés. L'étiquetage intervient après le nettoyage et fait intervenir de nombreux fichiers intermédiaires (qui sont tous supprimés avant la fin de l'exécution). Pour expliquer la démarche, je vais prendre l'exemple de l'extraction des titres. Grâce aux expressions régulières ou à XML::RSS, on a réussi à extraire un titre. On le fait passer dans la procédure de nettoyage et on l'écrit dans le fichier de résultat texte. Puis on applique la procédure d'étiquetage sur ce titre nettoyé. D'abord, un fichier appelé "titre.txt" sera créé et le titre sera écrit dedans. Ensuite, grâce à la fonctionnalité 'system()', on tokenise ce fichier, on applique TreeTagger et on stocke le résultat dans le fichier "etiquetage_titre.txt". Enfin, toujours grâce à 'system()', on applique TreeTagger2XML sur ce dernier fichier : le résultat apparait sous la forme "etiquetage_titre.txt.xml". La dernière étape consiste à lire ce fichier et à stocker son contenu dans une variable. C'est cette variable qui est retournée par la procédure et qui peut être écrite dans notre fichier de résultat XML. Les descriptions subissent exactement le même processus.
- Application de TreeTagger au sein des scripts (cliquez sur les liens pour accéder aux fichiers de TreeTagger) :system("perl tokenise-utf8.pl titre.txt | ./tree-tagger.exe -token -lemma -no-unknown french-utf8.par > etiquetage_titre.txt");
- Application de TreeTagger2XML au sein des scripts (cliquez sur le lien pour accéder au fichier de TreeTagger2XML) :system("perl treetagger2xml-utf8.pl etiquetage_titre.txt utf8");
Les nouveaux scripts ainsi que les sorties contenant l'étiquetage (fichiers xml) sont disponibles ci-dessous. A noter cependant qu'un dernier traitement a été nécessaire pour les fichiers XML : les entités & avaient été remplacées par un & simple mais dans nos fichers XML d'étiquetage, cela prose problème (message d'erreur à cause d'une entité non reconnue). Via Notepad++, j'ai donc recherché et remplacé tous les & en & à nouveau. On peut penser qu'il aurait suffit de ne rien changer dès le départ, mais si on avait laissé les entités telles quelles, TreeTagger aurait interprété le ; de l'entité comme une ponctuation, cette dernière aurait donc été séparée et l'analyse faussée (j'ai fait des tests). Je pense donc qu'il vaut mieux re-changer tout après pour avoir une meilleure analyse.
N.B.1: Les fichiers XML sont volumineux (d'environ 36 à 22Mo), les navigateurs peuvent donc avoir du mal à les afficher. Si vous souhaitez les visionner sans problème, je vous conseille de les télécharger.
N.B.2: Comme cela a été précisé sur la page de la Boîte à outils 1, le script avec XML::RSS est plus lent que celui avec les expressions régulières. L'étiquetage étant lui-même très long et les résultats des deux scripts étant fortement similaires, j'ai décidé de gagner du temps en faisant tourner uniquement le script RegEx contenant la procédure d'étiquetage.
Cordial
En utilisant les fichiers textes produits par les programmes, on peut faire un nouvel étiquetage via le logiciel Cordial. Avant de lancer l'étiquetage, il faut convertir les fichiers en ISO-8859-1 car Cordial ne prend pas en charge l'UTF-8. Etant donné qu'il n'y a que trois fichiers à traiter, j'ai les ai convertis à la main grâce à Notepad++.
On peut ensuite ouvrir les fichiers dans Cordial. Pour les étiqueter, il faut cliquer sur "Etiquetage de texte" dans l'onglet "Syntaxe". Une fenêtre de paramètres apparait. Les seules cases qui doivent être cochées sont "Numérotation des mots de chaque phrase --> NON", "Lemmes", "Type grammatical --> Abrégé en majuscules", "Codage spécialisé --> Aucun" et "Traitement des erreurs --> Ne pas corriger, ne pas signaler".

En quelques secondes, on obtient un fichier .cnr comportant trois colonnes avec, de gauche à droite, la forme, le lemme et la catégorie grammaticale. J'avais remplacé les guillemets français (« et ») par des guillemets anglais (") lors de l'extraction : apparemment, Cordial n'a pas reconnu ces derniers car aucune POS ne leur est assignée. Le reste semble avoir bien fonctionné. Les fichiers convertis en ISO-8859-1 et les résultats de Cordial sont disponibles ci-dessous.
N.B.: Comme cela a été dit dans la page Boîte à outils 1, les résultats d'extraction des scripts XML::RSS et RegEx étaient sensiblement les mêmes, j'ai donc effectué l'étiquetage avec Cordial uniquement sur les résultat du script RegEx.
Etiquetage : TreeTaggers ou Cordial ?
Les étiquetages réalisés par l'enchainement des deux TreeTaggers et par Cordial sont assez différents et présentent tous des avantages. Grâce à TreeTagger2XML, on obtient un résultat qu'on peut directement intégrer dans une feuille XML, ce qui permettra ensuite d'utiliser tout un tas d'outils spécifiques aux documents XML (cf. Boîte à outils 3). Mais le gros désavantage de cette méthode est qu'elle est très coûteuse en temps (il faut facilement compter plusieurs heures pour finaliser l'extraction et l'étiquetage de toutes les rubriques, même si le temps exact varie selon les machines) ! Si Cordial ne permet pas d'obtenir un fichier XML, il renvoie son résultat très rapidement. De plus, ses sorties peuvent être fouillées d'autres manières (cf. Boîte à outils 3).
Les étiquetages sont difficilement comparables dans la mesure où les jeux d'étiquettes (et donc la finesse d'analyse) utilisés ne sont pas les mêmes. Le 'tagset' du français de TreeTagger est constitué d'environ 33 étiquettes contre environ 126 pour Cordial (cf. le tagset de Cordial d'après le manuel Codial). A titre d'exemple, dans ces jeux d'étiquettes, on trouve une dizaine d'étiquettes pour les verbes chez TreeTagger (les sous-catégories sont les temps ou les modes de conjugaison comme indicatif, participe passé etc.) et environ une cinquantaine chez Cordial (qui fait des distinctions de genre et de personne). Ces différences d'étiquettes seront à prendre en compte au moment de la fouille des données. On peut malgré tout comparer brièvement les résultats obtenus pour les deux premières phrases de la rubrique 3208, à titre d'exemple.
Outre une différence d'étiquettes (distinction en genre et en nombre opérée par Cordial, point final de phrase annoté en 'PCTFORTE' chez Cordial et en 'SENT' chez TreeTagger), sur la première phrase on peut remarquer de nombreuses divergences au niveau de l'annotation. Elles sont soulignées en rouge dans l'image qui suit.

La comparaison est ici en faveur de TreeTagger : il a su reconnaître le 'A' initial comme une préposition, malgré l'absence d'accent. Il a également bien annoté 'Macron' en nom propre (Cordial le classe en 'nom commun masculin invariant en nombre') et les guillemets français (qui n'ont pas du tout été reconnus par Cordial, ce qui est étonnant puisque lors de précédents tests, ces derniers avaient été correctement annotés...). Le deuxième exemple (début de la seconde phrase du document) montre des résultats plus mitigés.
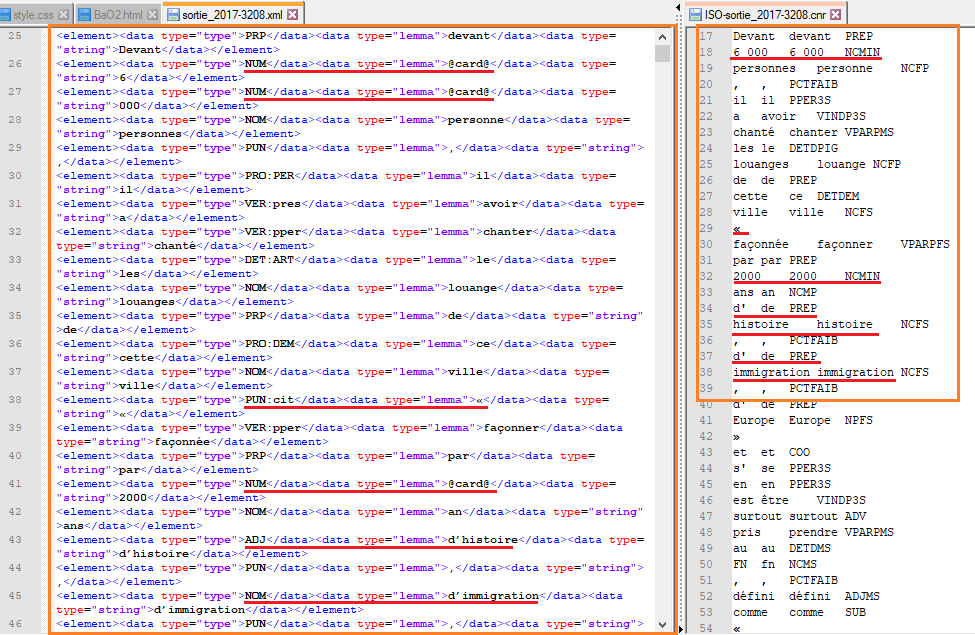
On observe quelques différences d'annotation en faveur de TreeTagger : il a reconnu "6 000" et "2 000" comme étant des nombres cardinaux (Cordial en fait des 'noms communs masculins invariant en nombre' au lieu 'd'ajectifs munériques cardinaux') et il a bien annoté les guillemets français (toujours non reconnus par Cordial). Mais ce qui saute aux yeux ici est surtout une différence de segmentation : TreeTagger a séparé "6 000" en deux à cause de l'espace, en revanche il a laissé collé "d'histoire" et "d'immigration", annotant ces deux derniers exemples comme des adjectifs. Cordial a quant à lui bien segmenté ces éléments, et s'il n'a pas reconnu les nombres, il a correctement annoté "d'" en préposition et "histoire" et "immigration" en 'noms communs féminins singuliers'.
On ne pourrait bien entendu pas juger la qualité des deux étiqueteurs simplement d'après ces deux exemples (pour vraiment les évaluer, il faudrait mesurer le rappel et surtout la précision). Cependant, si le peu qui a pu être observé ici est constant tout au long des documents étiquetés, on saura comment pondérer les résultats obtenus lors de l'extraction de patrons syntaxiques. Si TreeTagger ne segmente pas les 'd' ' (qui peut se trouver souvent dans des structures du type 'NOM-PREP-NOM') et annote le tout en adjectif, cela aura un impact sur les résultats pour deux patrons syntaxiques ('NOM-PREP-NOM' mentionné plus tôt et 'NOM-ADJ'). De son côté, si Cordial ne reconnait pas bien les noms propres, cela pourra nous renvoyer plus de résultats si on veut des patrons uniquement avec des noms communs.