|
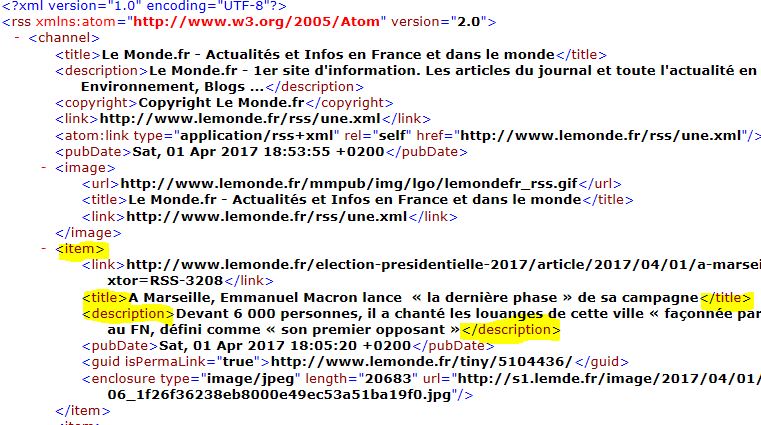
Dans cette première boite à outils, nous avons appris à extraire du texte d'un flux RSS. Nous avons sélectionné et récupéré tous les titres des articles parus dans LeMonde en 2017, avec leur description. Le contenu textuel qui nous intéresse se trouve à l'intérieur des balises <item>. On cherche à y extraire le titre et la description de chaque article, donc ce qui se trouve entre les balises <title> et <description> .
 |
Pour cela, nous avons élaboré deux programmes différents en Perl (dont les codes sont disponibles, commentés et en couleur, dans leurs articles respectifs) :
- avec les Expressions Régulières
On demande à notre expression régulière de trouver tout ce qui se trouve entre les balises <description> et </description> et que la balise fermante sur trouve sur une autre ligne, il y a de grands risques que notre programme ne trouve pas le motif recherché.
Les RegEx sont un sujet où nous sommes désormais autonomes, et l'exécution du programme est plus rapide qu'avec XML::RSS.
- en reprenant XML::RSS.
Parcourir l'arborescence:
Il faut maintenant extraire le contenu textuel des fichiers RSS de toute l'arborescence automatiquement.

Choix des rubriques:
Nous avons choisis de nous concentrer sur 3 rubriques: "International", "Europe" et "société" car nous avons pensé que ce "zoom" géographique, du globale au spécifique, se révelerait interessant lors de l'étude des motifs (BAO4).
Nous nous attendons donc à avoir des résultats différentes pour chaque rubrique.
Voici les fichiers obtenus:
A ce moment du projet, le texte extrait est écrit sur 2 fichiers de sortie : une sortie texte (encodage UTF-8), et une sortie XML.
>>> Passer à la BAO2