Boite à Outils 4 : Du texte au graphes
Une fois les patrons morpho-syntaxiques extraits, nous passons à la dernière partie de ce projet. Il nous faut choisir des motifs, produire les graphes de cooccurrence à l'aide de l'outil patron2graph.exe et comparer les résultats obtenus selon les rubriques.
Ce programme est disponible sur I-Campus. Il va permettre d'afficher des graphes qui montrent les relations entre le mot choisi (motif) et les mots de son contexte.
- Le fichier executable requière trois arguments:
- l'encodage utilisé
- le fichier contenant nos entrées, c'est à dire le résultat du filtrage morpho-syntaxique des fichiers en texte brut.
- un fichier contenant notre motif lexical sur la base duquel nous filtrons les entrées (facultatif)
On a décidé de s'intéresser aux mots qui commencent par [F|f]ran[c|ç] et [e|E]uro , ainsi que la préposition "sous" dans les 3 rubriques choisies: International, Europe et société.
Vu la quantité de données à traiter, et afin d'afficher des résultats plus clairs, on a décidé - pour chaque mot choisi - de n'afficher qu'un seul graphe par rubrique (soit sur la sortie Treetagger, soit sur la sortie Cordial) en prenant soin de choisir le graphe qui affichait les meilleurs résultats.
Bien que les sorties treetagger et Cordial soient nettement différentes à l'étiquetage (cf BAO 3), les graphes autour d'un mot choisi sont sensiblement les mêmes.
Les mots qui commençent par: [e|E]uro\w+
Pour la rubrique : "International"

Pour la rubrique : "Europe"
On aperçoit aussi le mot " Européens" qui apparaît dans "International" et "Europe"

Pour la rubrique : "Société"
![]()
Analyse:
On remarque que le vocabulaire autour du mot "Euros" dans les 3 rubriques est plus ou moins semblable. Il est un peu plus riche au niveau de la rubrique "société".
On peut voir aussi qu'il est en relation avec plusieurs mots comme: million(s), milliard(s),milier(s), amende...
Les mots qui commençent par: [F|f]ran[c|ç]
Pour la rubrique : "International"

On retrouve "président de France" içi, car dans la rubrique "International", on a tendance à utiliser ce terme pour bien préciser de quel président on parle . Tandis que dans la rubrique "société", le fait de dire "président" refère directement au président français.
On retrouve aussi le mot "francophonie", qui est aussi un terme plus globale et ne concerne pas uniquement la France.
Pour la rubrique : "Europe"
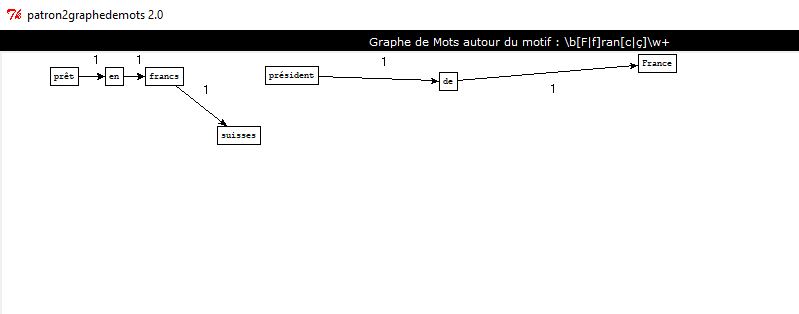
Même hypothèse pour le mot "président de France". On retrouve aussi le mot "francs" qui est suivi de "suisses": ça nous paraît plutôt évident pour cette rubrique
Pour la rubrique : "Société"

Le vocabulaire içi est plus fourni que dans les rubriques "International" et "Europe". En effet,on trouve les mots communs "francs" et "France/ français" dans les 3 rubriques. Cependant,on apperçoit aussi le mot "Franciliens" qui est effectivement, un mot spécifique à la société française.
On suppose que le fait qu'on retrouve l'expression "millions de françaises" est due au fait que dans cette rubrique, on peut parler de statistique sur la société.
Il est aussi intéressant de voir que le programme trouve aussi le mot: "franchise" , auquel on y'avait pas pensé lorsqu'on a choisi le motif.
La préposition "Sous":
Pour la rubrique : "International"
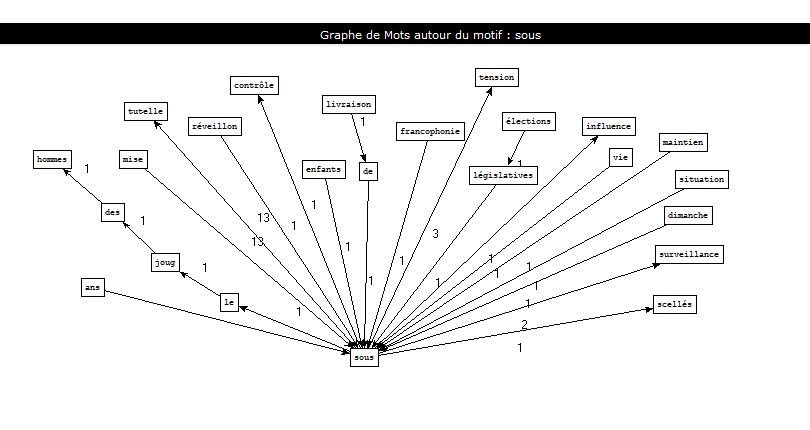
Pour la rubrique : "Europe"

Pour la rubrique : "Société"
![]()
Analyse:
Pour le cas de la préposition,on remarque que tous les mots repèrés montrent bien la polysémie de "sous".
- Elle peut être une subordination comme : sous tension..., sous peine... , sous l'emprise de ...
- Elle peut refèrer à un lieu ( ce qui est placé plus bas).
- Elle peut signifier , le fait de consommer certaines choses comme dans l'exemple: sous stupéfiants
Dans la rubrique "International", on retrouve des mots spécifique au jargon politique: élections législatives, maintien sous.. , sous contrôle ...
Dans la rubrique "Europe", on retrouve les mêmes mots avec une legère différence. Par exemple: Européens sous ... alors que dans la première rubrique, il y'avait : Francophonie sous ...
Dans la rubrique "Société", parcontre, on trouve les mots comme: personnes, établissement...
Conclusion:
Durant tous le deuxième semestre, nous avons appris à programmer en Perl afin d'extraire du contenu textuel depuis un document XML. Nous avons également appris à utiliser des programmes comme Cordial et Treetagger pour l'étiquetage morpho-syntaxique.
A l'aide des expressions régulières, nous avons filtré des motifs. Puis, nous avons transformé les documents XML grâce des feuilles de styles XSLT
Et pour finir, nous avons développé nos compétences en HTML et CSS pour construire ce site .