Extraction du corpus
L´objectif de cette première Boîte à Outils 1 consiste à extraire les informations textuelles comprises dans l´arborescence qui contient les fichiers RSS du journal Le Monde de l´année 2017. Comme résultat, il produira en sortie deux fichiers: l´un en format TXT et l´autre en format XML.
Un script Perl, présenté ci-dessous, réalisera l´extraction automatiquement.
Le contenu de notre travail est composé des fichiers fils RSS du journal Le Monde récupérés pendant l´année 2017. Les fils RSS sont des flux de contenus d´Internet, dans ce cas, du journal déjà mentionné, qui incluent souvent le titre de l´information, une courte description et un lien vers une page qui décrit cette information de façon plus détaillée. Le format « RSS » ( « Really Simple Indication ») permet de décrire d´une façon synthétique le contenu du site web dans des fichiers au format XML. Pour ce projet là, on a récupéré les fils RSS de ce journal de toutes les rubriques, mais on travaillera plus en détail dans quelques unes, celles qui pourront être plus intéressantes pour notre but, notamment pour l´analyse linguistique. En ce qui concerne la structure des fils RSS, on peut remarquer dans chaque fichier XML les balises « channel » (pour décrire le fil d´information de façon générale), et ensuite les balises « items », qui contient en même temps les balises dont nous nous en servirons : « title » et « description ». Nous avons choisi les rubriques À la Une (3208), International (3210), Europe (3214) et France (3224).
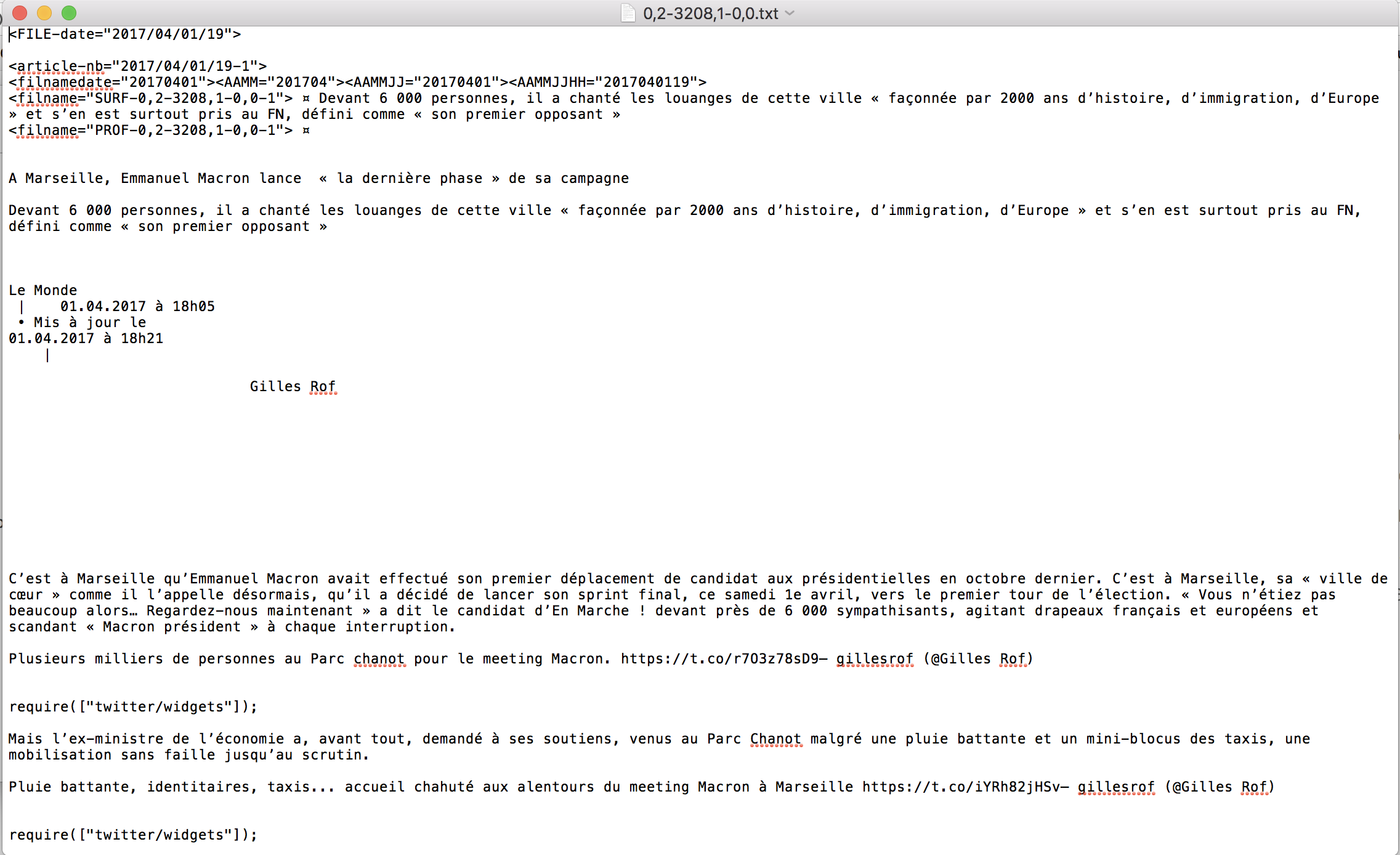
Voici un exemple d´un fil RSS de notre corpus :
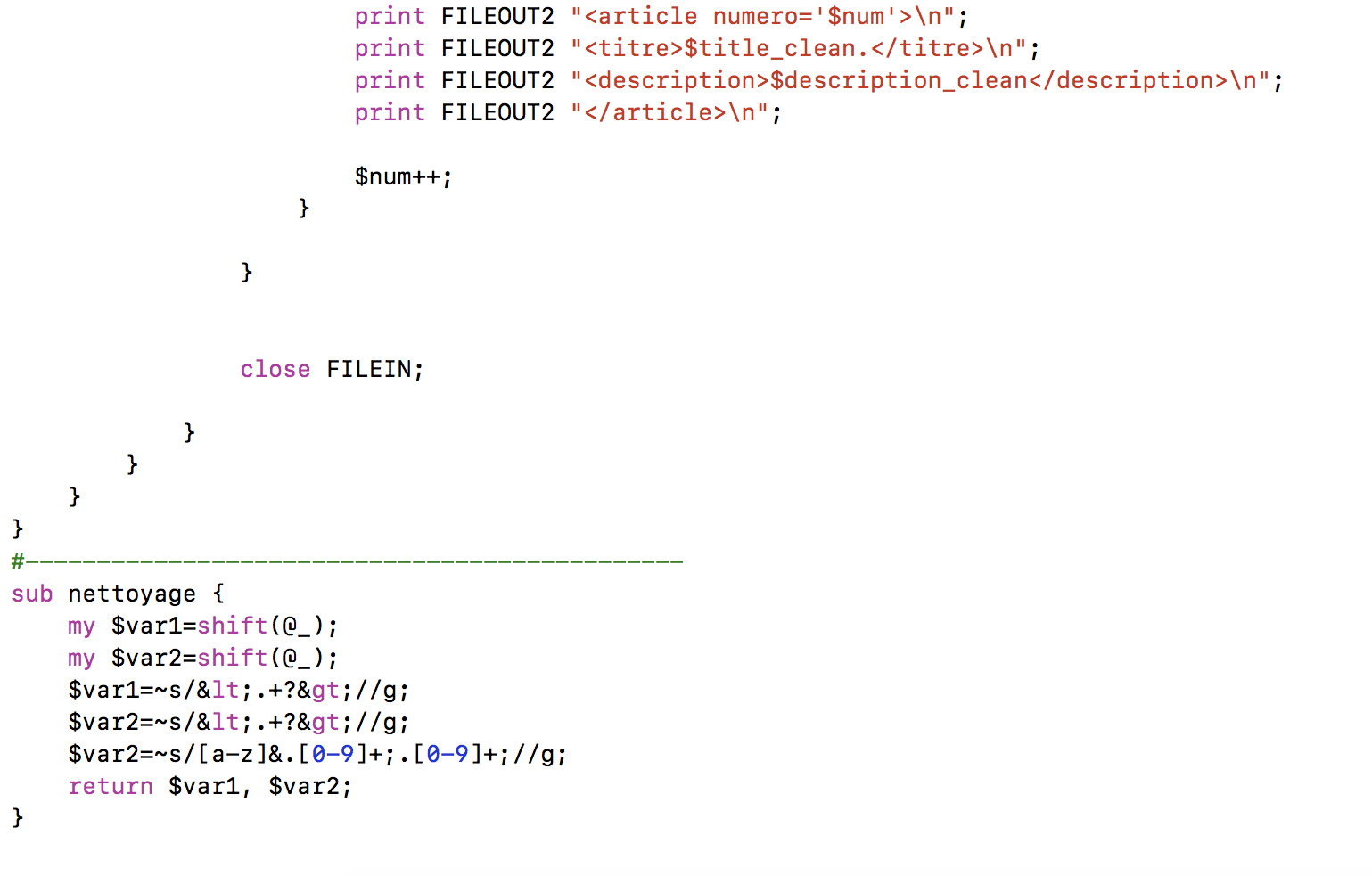
Ce programme parcourt une arborescence de fichiers XML et applique un traitement sur chacun des fichiers rencontrés au moment du parcours. En sortie, le programme extraira le contenu textuel des fils RSS dans deux fichiers, l´un au format TXT et l´autre au format XML.
En premier lieu, on initialise deux variables qui seront les entrées de notre programme : $rep, le dossier contenant tous les fichiers RSS et $rubrique, chiffre correspondante à la rubrique à traiter. La variable hash %redondant gardera à chaque fois le contenu du titre pour éviter la répétition des informations.
En sortie, on va créer deux fichiers pour chaque rubrique, encodés en UTF-8 et nommés selon son format, soit « sortie_$rubrique.txt », soit « sortie_$rubrique.xml ». Ce deuxième fichier, on le modifiera progressivement pour en ajouter des différentes balises qui marqueront spécifiquement le début et la fin de chaque article.
Ensuite, on passe au sous-programme Perl nommé « parcoursarborescencefichiers », qui permet de parcourir tous les fichiers XML de l´arborescence des fils RSS. Ce sous-programme reçoit comme entrée le répertoire où se trouvent tous nos fichiers RSS. À chaque fois qu´il trouve un sous-répertoire, il l´ouvre et vérifie s´il s´agit d´un répertoire ou d´un document XML. Il répète ce procédure jusqu´à ce qu´il a fini toute l´arborescence. C´est à l´intérieur de ce sous-programme où on va ajouter le traitement de chaque fils RSS. Quand il trouve un fichier dont l´extension est « .xml » et le nom corresponde à la chiffre qu´on a donné en entrée comme rubrique, il passe aux traitements suivants :
Le script final de la Boîte à Outils 1 se trouve ici.


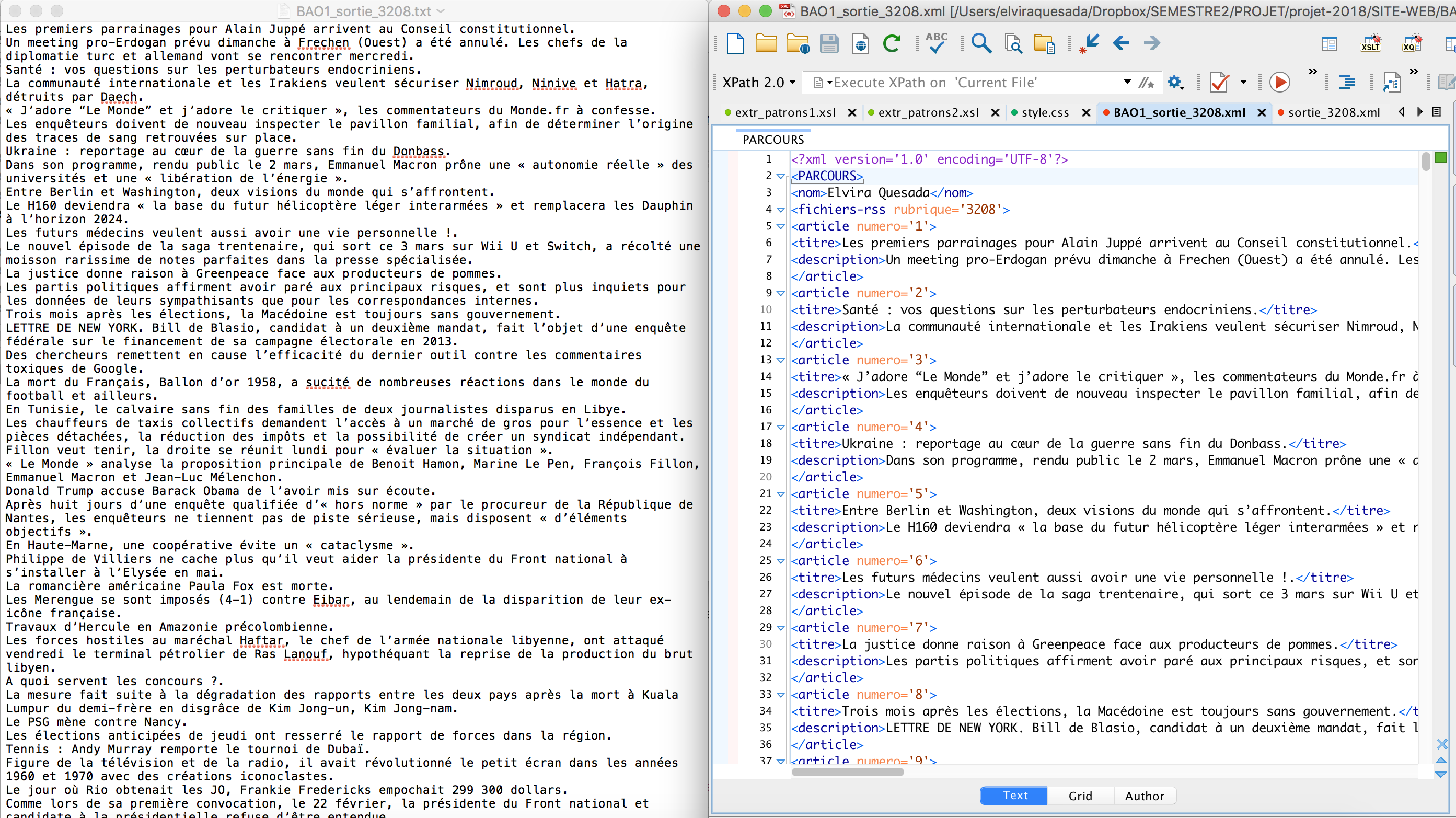
Le fichier texte produit ne montre qu´une simple liste de titres et descriptions des articles. Le fichier XML est une liste structurée des fichiers, pour chaque article on trouve les items contenus dans les fichiers, et chaque item contient son titre et sa description. Voici un exemple des fichiers obtenus pour la rubrique « À la Une » : le fichier TXT et le fichier XML.
Ici une capture des deux sorties TXT et XML pour cette rubrique.
Trouvez en bas les sorties obtenues pour le reste des rubriques :
Rubrique 3210 : sortie XML et sortie TXT
Rubrique 3214 : sortie XML et sortie TXT
Rubrique 3224 : sortie XML et sortie TXT