
Extraction de patrons morpho-syntaxiques
À partir des sorties étiquetées morpho-syntaxiquement à la Boîte à Outils 2, dans cette étape du projet nous allons créer des listes de patrons morphosyntaxiques en différents formats.
On va proposer différentes méthodes pour chacune des sorties de la Boîte à Outils 2 :
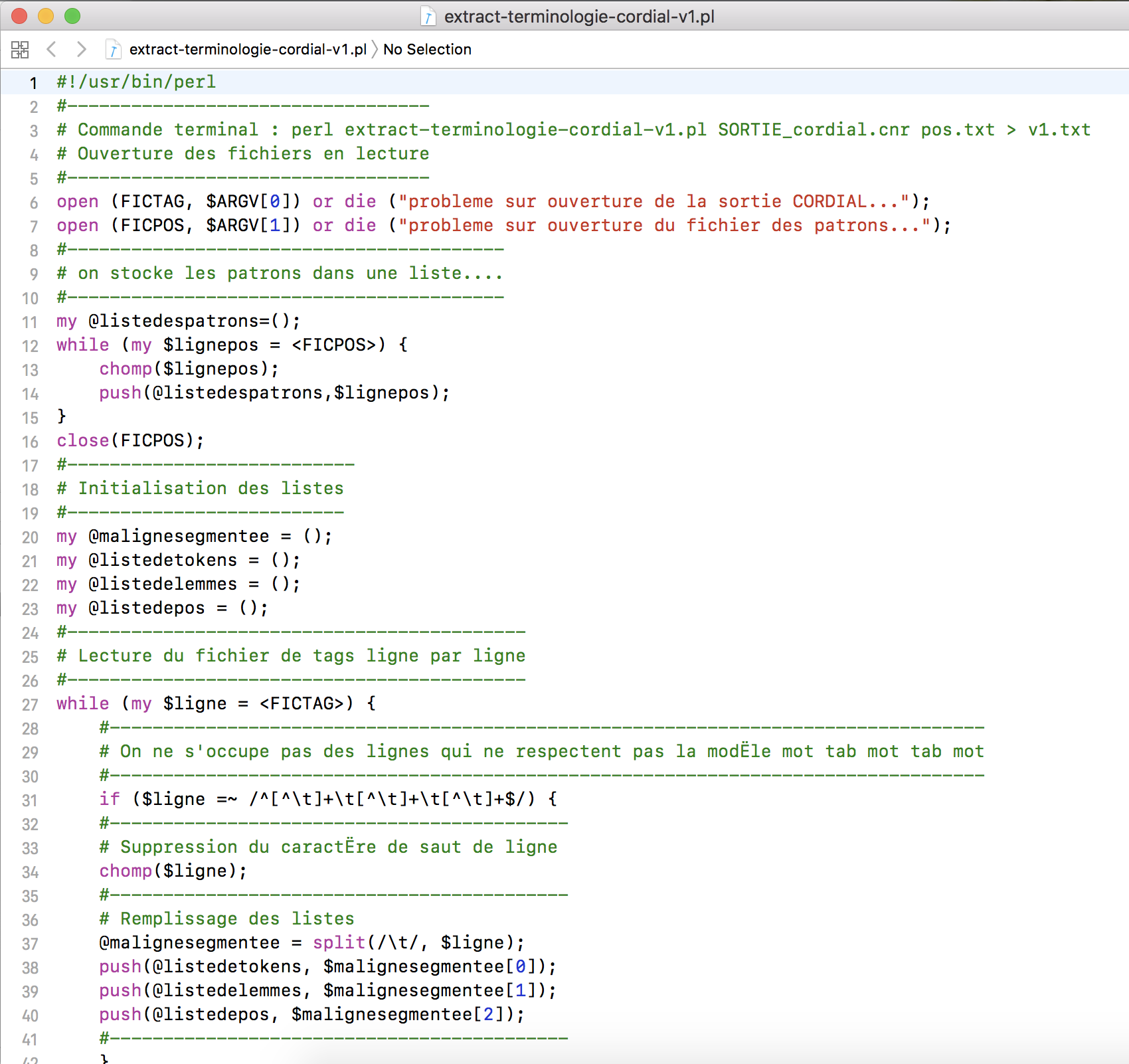
Le premier traitement à faire dans ce script est de mettre en horizontal le fichier Cordial, c´est-à-dire, dans une seule ligne. Il faut se rappeler que notre fichier Cordial est une suite de tokens correspondants à la chaîne traitée, son lemme et sa POS, tous séparés par des tabulations. Le script lit la première ligne, il va chercher les trois tokens séparés par des tabulations et va garder la chaîne et la POS dans la variable $chaîne dans ce format : POS_FORME. Une fois qu´il a mis tout le fichier en ce format-là, il va aller chercher la première ligne du fichier patrons pour récupérer le premier patron morphosyntaxique et va comparer cette ligne là avec la variable $chaîne pour trouver les possibles correspondances. S´il en trouve une, ça veut dire qu´il a trouvé une séquence de chaînes qui correspondent au patron, alors il va la garder dans la variable $correspondance. Il va procéder de cette façon-là en parcourant toute la variable $chaîne pour chaque patron écrit dans le fichier. Une fois qu´il a fini avec le patron, on transforme à nouveau les symboles « % » par des espaces.
Trouvez ici le script final pour l´extraction de patrons avec Perl.


Finalement, le script produit un fichier texte brut qui contient des lignes chacune correspondante à un patron morphosyntaxique du fichier patron. En plus, on compte les occurrences des patrons trouvés.
Ici en bas, un example du résultat obtenu avec la rubrique France :

On a modifié des feuilles de style pour chercher les différents patrons et obtenir comme résultat différents fichiers, chacun pour un patron donné. Une première feuille de style qui produit un fichier TXT avec les correspondances, et une deuxième feuille de style qui produit l´affichage HTML des correspondances trouvées.
On a utilisé le logiciel BaseX pour réaliser des requêtes avec XQuery. On a cherché trois patrons morphosyntaxiques :
Trouvez en bas une capture du logiciel avec la requête :

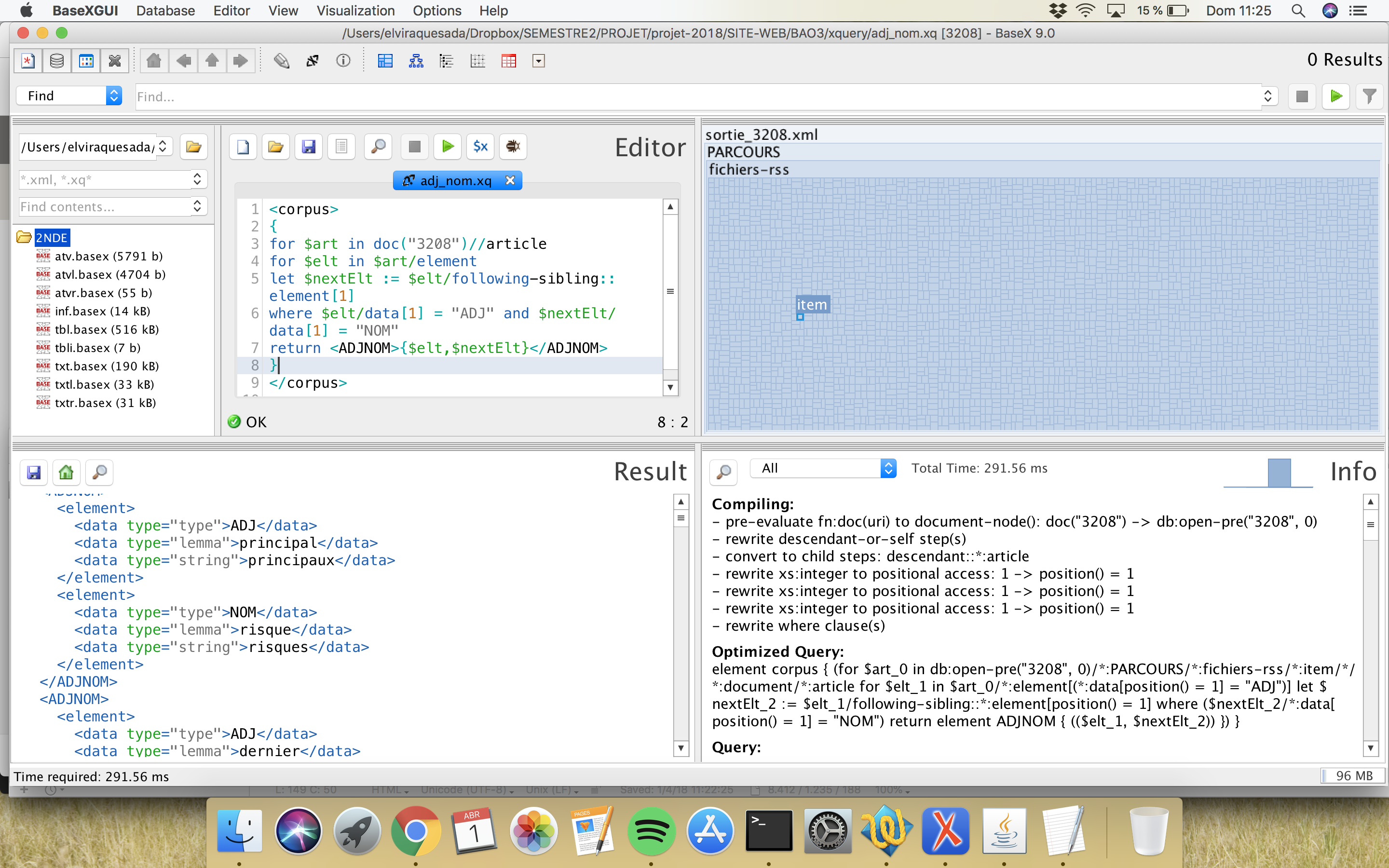
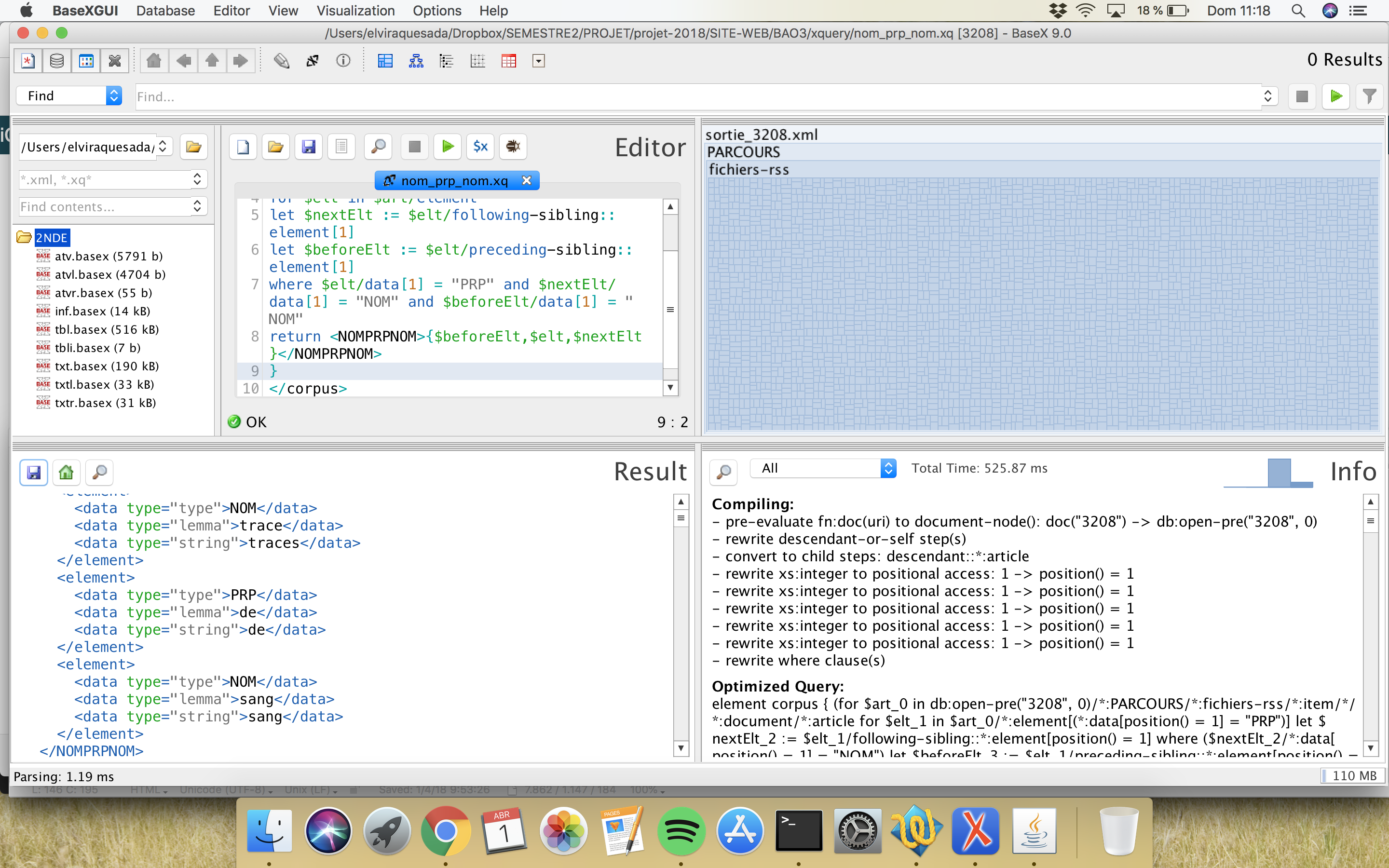
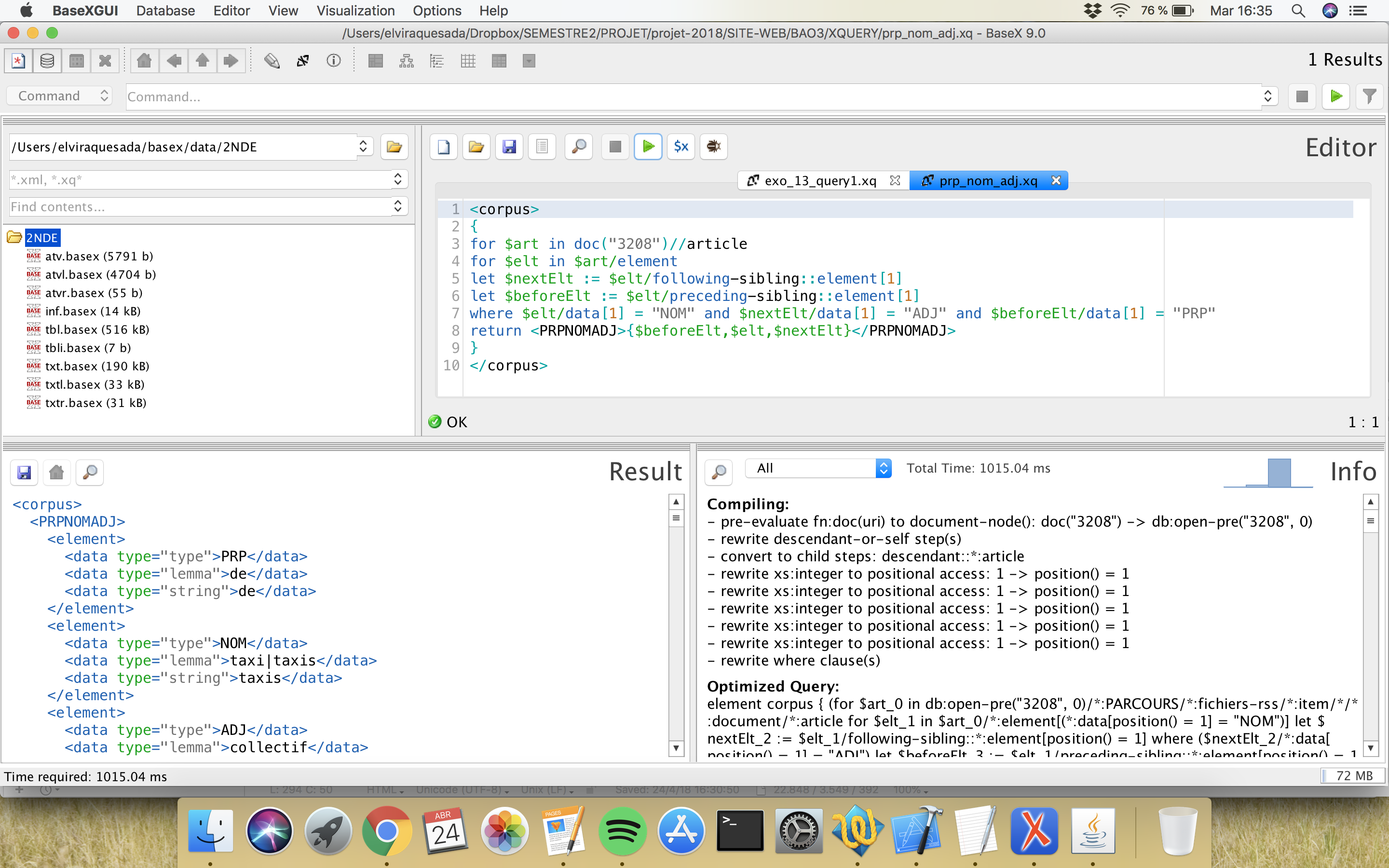
Dans ce cas-là, on a construit un nouvel script Perl pour l´extraction de patrons morpho-syntaxiques. Cette fois-ci, on va déterminer le patron à l´intérieur du script Perl; conséquemment, on adaptera à chaque fois le script pour chercher un patron spécifique. Le script est modifié pour chercher chaque patron pour chaque type de sortie, soit Cordial soit TreeTagger.
Le script prend comme seul argument le fichier sortie étiqueté, il le lit d´un seul coup et le garde dans le tableau @lignes. Ensuite, le script entre dans un boucle « while » qui va lire cette variable ligne par ligne, et on va parcourir le tableau un cherchant dans la premier ligne la première catégorie cherchée du patron, si cette ligne-là contient la catégorie qu´on veut, on va l´extraire du tableau et on va ensuite passer à la ligne suivante pour vérifier qu´on trouve la suivante catégorie. La variable clé c´est « $longueur », si elle corresponde à la longueur de la séquence du patron, par example, si on cherche « NOM ADJ », la longueur visée est 2, alors on va imprimer la séquence. Voici les différents scripts selon le patron visé pour l´extraction :
Pour la sortie Cordial :
Pour la sortie Treetagger :
Ce script donne comme résultat un fichier texte brut avec les séquences des mots correspondants aux patrons cherchés.
Voici un exemple du fichier texte obtenu avec la sortie Treetagger de la rubrique À la Une pour le patron NOM ADJ.
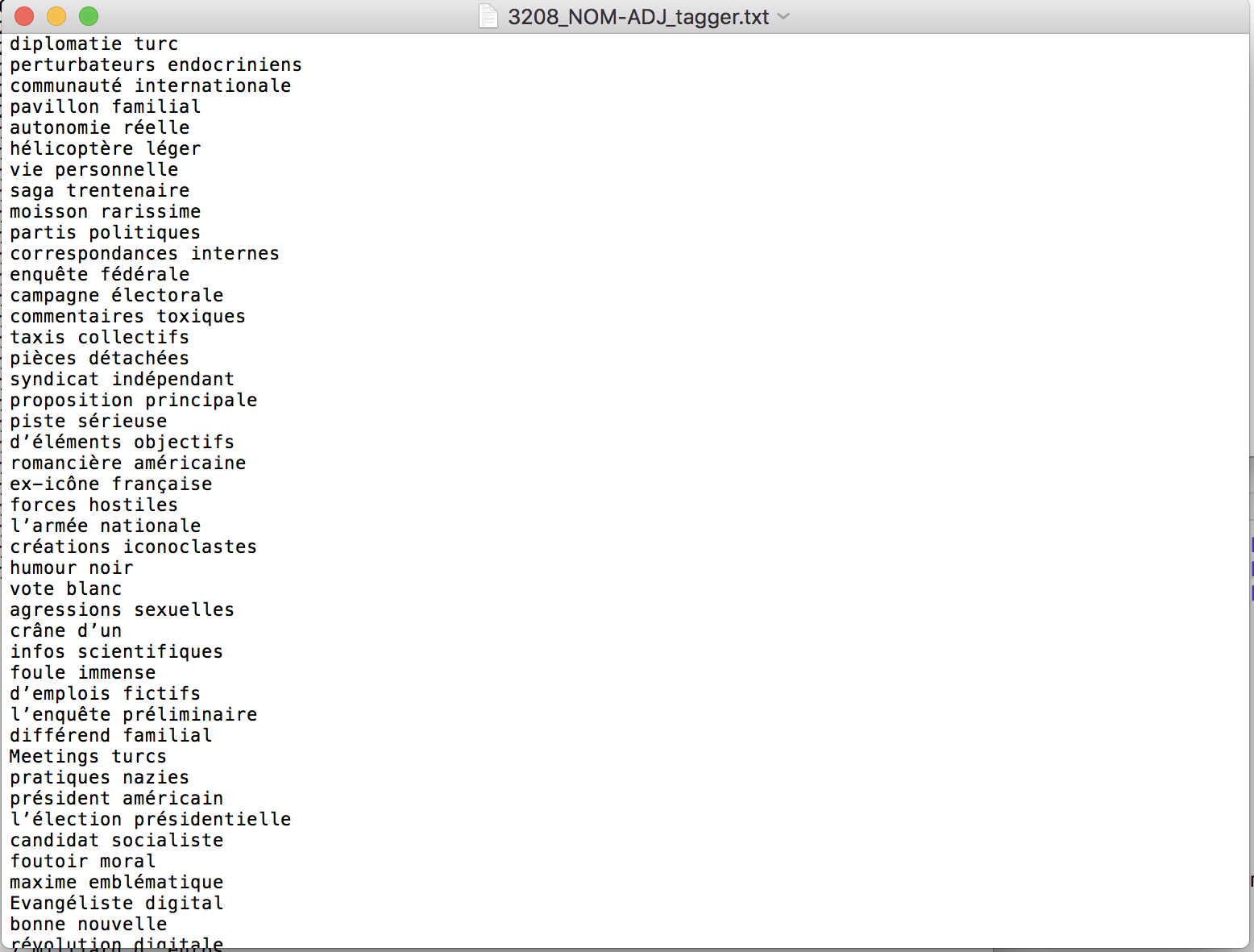
Les fichiers obtenus sont les suivants :
Rubrique À la Une (3208) :
Rubrique International (3210) :
Rubrique Europe (3214) :
Rubrique France (3224) :
Pour cette troisième solution on va expliquer deux sortes de scripts. Un premier script, qui prend comme arguments le fichier sortie et le fichier avec les patrons. En premier lieu, le script met tout le contenu du fichier patrons dans le tableau @listedespatrons, et définie chaque patron comme $lignepos. Ensuite, il va parcourir ligne à ligne le fichier de la sortie étiquetée pour la segmenter en tokens, lemmes et POS, et met chacun dans son tableau correspondant : @listedetokens, @listedelemmes et @listedepos. Après on va copier chaque tableau dans un tableau correspondant temporel pour parcourir les POS et supprimer le premier élément à chaque fois et on segmente la liste des termes pour avoir les patrons. Si l´élément courant POS correspond au premier élément du patron, on vérifie la suite. À chaque fois qu´on trouve une correspondance on incremente la variable $verif, comme ça on peut comparer à la fin si le nombre d´éléments du patron (séparés par le symbol « # ») trouvés est égal à $verif, alors ça veut dire qu´on a tout reconnu et on peut imprimer cette séquence.
Ici le script pour cette première version

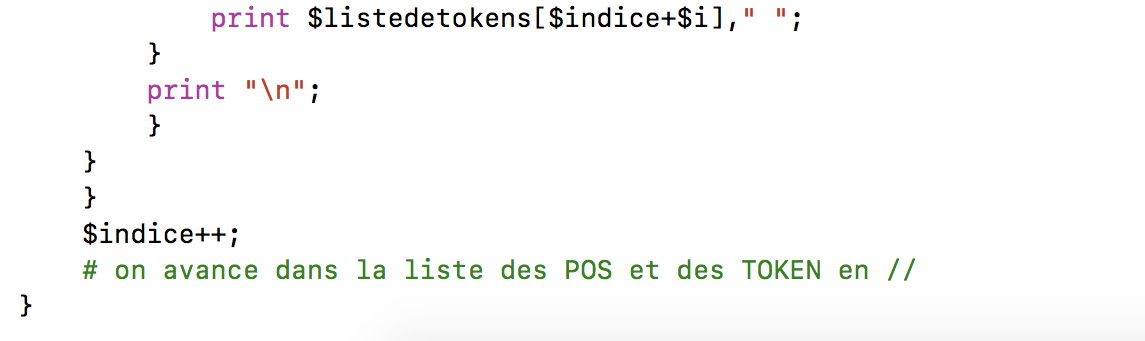
Le deuxième script prend comme premier argument le fichier Cordial étiqueté et comme deuxième argument une chaîne qui correspond au patron morpho-syntaxique cherché. Le fichier sortie étiqueté est gardé dans un tableau : @lignes. Ensuite, on parcourt ligne à ligne et on l´extrait à chaque fois pour vérifier si dans cette ligne-là on trouve la première POS cherchée, qui correspond à la première partie de la chaîne qu´on a tapé : $ARGV[1]. Par example, si on a donné comme entrée NC.+ ADJ.+, alors il va aller chercher "NC.+" dans la partie POS. S´il trouve cette chaîne, alors on garde la partie correspondante au mot dans la variable $sequence. À ce moment-là, on va créer la variable $indice, qui nous permettra de compter le nombre de petits morceaux qui composent notre patron, et aussi la variable $stop. Si l´indice est inférieur au nombre des éléments entrés comme arguments ($#ARGV) et la variable $stop vaut 1, alors on continu à parcourir les arguments de l´entrée parce que ça veut dire qu´il nous restent encore des POS à chercher. On va regarder donc la deuxième ligne, c´est-à-dire, $lignes[$indice-1]. Pourquoi $indice - 1? Parce que la première ligne étudiée était celle correspondante à @lignes[0], mais comme on l´a extrait, la deuxième ligne qu´on va aller regarder ça sera toujours @lignes[0], mais la prochaine fois on regardera la suivante donc @lignes[1] et comme ça à chaque fois...On va concaténer le mot trouvé dont la POS correspond à celle cherchée dans $sequence. Une fois que $longueur, celle qui compte aussi le nombre des éléments du patron est égal à $#ARGV, alors on arrête le programme puisqu´on a parcouru toute le patron.
Ici le script pour cette deuxième version

Le premier script produit un fichier texte brut qui contient les correspondances trouvées dans la sortie par rapport aux patrons cherchés.
Pour chaque rubrique, on obtient un fichier TXT avec les correspondances trouvées :
Le deuxième script produira aussi un fichier en texte brut avec les séquences qui correspondent au patron qu´on a saisi comme entrée.
Rubrique À la Une :
Rubrique International :
Rubrique Europe :
Rubrique France :