
Étiquetage morpho-syntaxique du corpus
Cette deuxième étape consiste à réaliser un étiquetage morpho-syntaxique des fichiers obtenus précédemment :
Cordial est un logiciel qui ne fonctionne pas en ligne de commande, il faut passer par une interface graphique, ce qui fait impossible d´automatiser ou introduire cette étape dans notre script.
On va étiqueter chaque fichier correspondant à chaque rubrique pour obtenir des fichiers « tabulaires » (aspect important pour les prochains traitements...) qui contiendront le terme traité, le lemme et la catégorie grammaticale. Il faut remarquer que Cordial ne traite que des fichiers encodés en ISO-8859-1. Conséquemment, on a dû transformer les fichiers créés (on rappelle que ces fichiers étaient encodés en UTF-8) en ISO-LATIN-1 avec la commande unix « iconv ». Après avoir étiqueté les fichiers, on les a transformé en UTF-8.
Voici un exemple du résultat de l´étiquetage avec Cordial (rubrique Europe, 3214) :
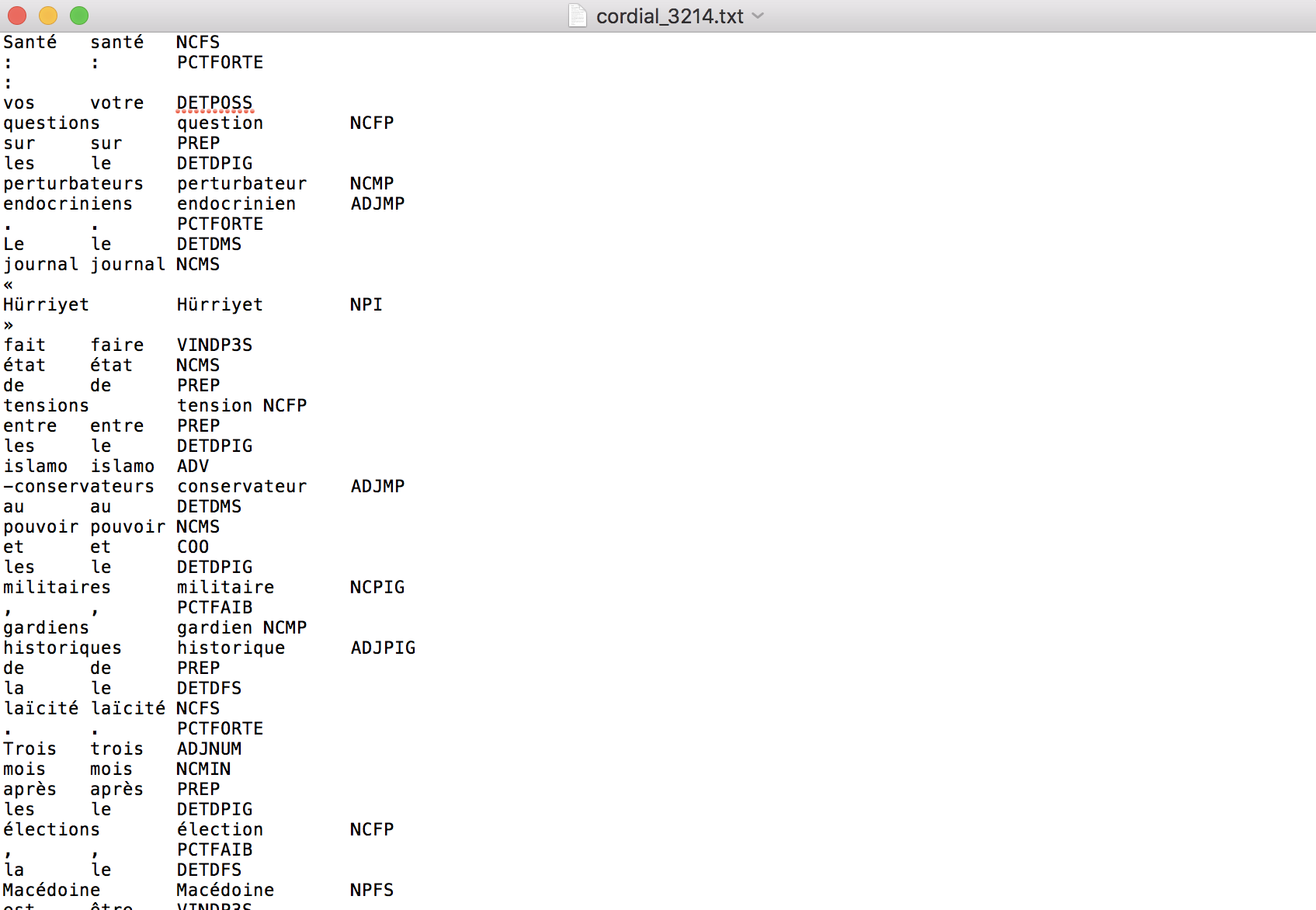
Dans ce cas là, on va intégrer dans notre programme construit dans la BàO 1 un sous-programme qui applique un traitement d´étiquetage sur chacun des fichiers rencontrés lors du parcours de l´arborescence. En plus, en sortie, ce programme devra construire un fichier structuré, c´est-a-dire, en format XML, qui lui contiendra le résultat de ce traitement.
Quels sont les données a traiter? On va étiqueter les contenus textuels qui se trouvent à l´intérieur des balises « title » et « description » des fichiers XML produits dans la première étape.
On récupère le script construit lors de la prémière étape de la Boîte à Outils 1. C´est juste après le nettoyage des variables « title » et « description » où on appliquera le sous-programme « étiquetage ». Ce sous-programme prend comme arguments les deux variables, « title » et « description » et il est divisé en deux parties, chacune traitant chaque variable. Comme TreeTagger et les programmes tokenise et treetagger2xml peuvent se lancer en ligne de commande, c´était plus rapide de les intégrer dans le script d´extraction. Comme notre script principal est écrit en Perl, il ne fallait qu´utiliser « system » pour automatiser le traitement. En premier lieu, on utilise « tokenise-utf8.pl », un script perl pour segmenter le contenu textuel en tokens et ensuite on fera appel au programme TreeTagger pour l´étiqueter. En dernier lieu, on transforme le fichier obtenu (les données segmentés et étiquetés des variables « title » et « description ») en format XML avec le programme « treetagger2xml-utf8.pl », qui transforme la sortie du TreeTagger au format XML. On applique ce même procédé aux deux variables.

Après tous les traitements mentionnés, la sortie obtenue ressemble à ceci :

Le résultat obtenu après l´étiquetage de Cordial ressemble à ceci:
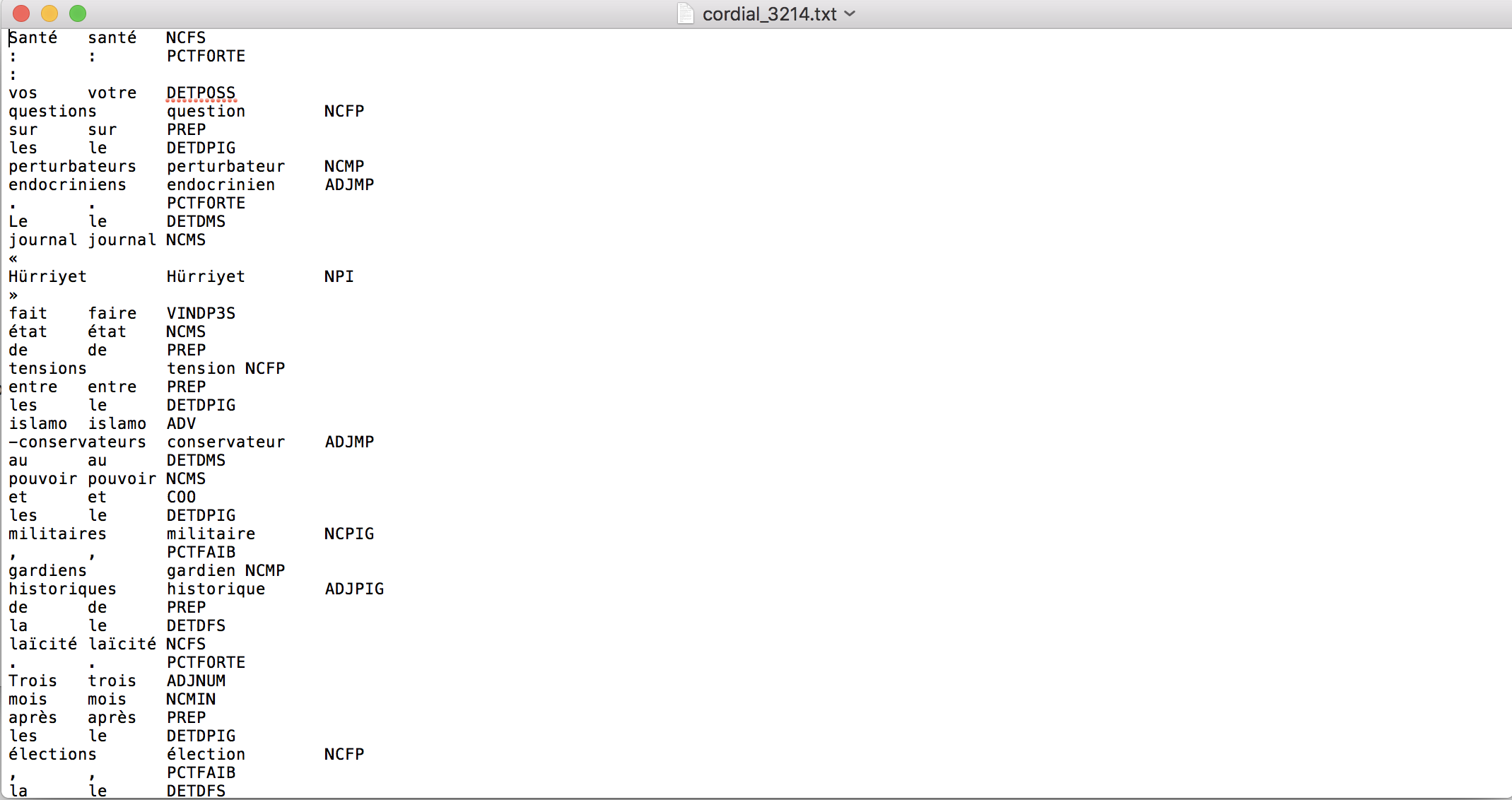
Le script final correspondant à la Boîte à Outils 2 se trouve ici.
En bas, vous pouvez accédez aux fichiers sorties obtenus après la Boîte à Outils 2 :
Rubrique 3208: sortie TreeTagger et sortie Cordial
Rubrique 3210: sortie TreeTagger et sortie Cordial
Rubrique 3214: sortie TreeTagger et sortie Cordial
Rubrique 3224: sortie TreeTagger et sortie Cordial
Une fois qu´on a étiqueté toutes les rubriques avec ces deux étiqueteurs, on va examiner d´un peu près les résultats pour observer s´il y a des différences dans les étiquetages produits.