SCRIPT
Cette partie se consacre à la spécification de notre script.
Le script contribue à collecter, filtrer et prétraiter des ressources langagières de la presse à partier des URLs approvisonnées pour but de disposer d’un corpus multilingue. La diversité de nos ressources exige cependant des traitements spécifiques. Par essai et erreur, nous avons amélioré notre script au fil du projet.
DÉSCRIPTIF
Répertoire de travail
Nous montrons dans cette arborescence notre répertoire de travail.
Le script et ses fichiers paramètres sont dans le dossier PROGRAMMES ;
Les quatre fichiers des URLs de nos quatre langues sont stockés dans le dossier URLS ;
Les pages HTML aspirées sont dans le dossier PAGES-ASPIREES ;
Les textes déchargés (en utf-8 ou en d’autres encodages ) et les fichiers d'index dans le dossier DUMP-TEXT ;
Les contextes du motif (au format texte ou HTML) dans le dossier CONTEXTES ;
Les fichiers de bigramme dans le dossier BIGRAMME ;
Dans le dossier TABLEAUX est le fichier HTML des tableaux qui donnent une vision globale du corpus.
Environnement de travail:
Clickez ici pour le script pour préparer l'environnement de travail
Outils /modules prélinimaires
-
Qui extrait le contexte du motif et génère le résultat au format HTML ;
-
Le code en python qui tokenize le texte chinois ; Pour plus d'information sur le traitement du chinois, veuillez consulter notre blog ;) https://talbonheur.wordpress.com/2018/12/28/traitement-du-corpus-chinois/
Données (entrées et sorties)
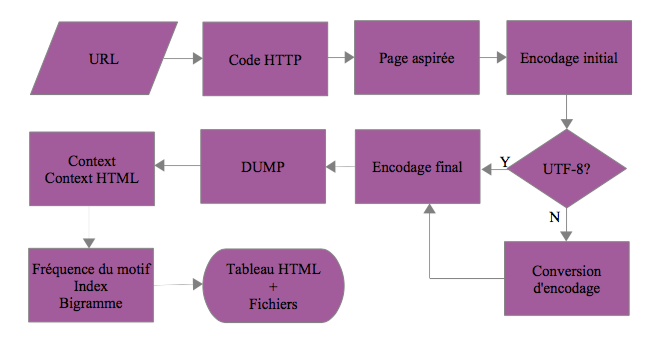
Le diagramme de flot de données (version très simplifiée) ci-dessous montre les données d’entrées et de sorties du script.
SCRIPT
Voici le script
Clickez ici pour le script du projet
Clickez ici pour le script du traitement du corpus chinois
Clickez ici pour le script de la concaténation des fichiers contextes et dumps
Les paramètres
paramètre 1: /URLS
paramètre 2: /TABLEAUX/tableaulang.html
paramètre 3: "bonheur|travail|happiness|work|幸福感|工作|kaligayahan|trabaho"
Le motif pour minigrep
nom fichier: motif-regexp.txt
MOTIF="bonheur|travail"
MOTIF="happiness|work"
MOTIF="幸福感|工作"
MOTIF="kaligayahan|trabaho"