Execution du script
Notre script d'extraction de données Perl fonctionne avec deux arguments :
1) répertoire contenant tous les fichiers RSS
2) le nom de la rubrique à traiter(représentée par une suite de chiffres sur la ligne de commande)
Les données de sorties seront présentées sous deux formats :
*un fichier txt
**un fichier xml
La première étape du script consiste en l'ouverture du répertoire indiqué sur l'entrée standard par l'utilisateur et de vérifier s'il s'agit d'un répertoire ou d'un document xml. Le programe exécuera cette tâche de façon récursive jusqu'à ce qu'il fini toute l'arboresence. Dans notre script cette opération est mise en évidence par le biais d'un sous-programmenommée &parcoursarborescencefichiers.
Puis, une fois que l'interpréteur de commande trouve un fichier xml qui correspond à la rubrique indiquée ultérieurement , il procède à l'extraction des données textuelles. Tout d'abord, on récupère le contenu des balises <titre> et <description> tout en supprimons les doublons si on en trouve.
Ensuite,nous commençons le traitement du texte: cette étapes qui est mie en place par la fonction nettoyage permet de changer les éléments mal interprétés comme : ' ou ê par leurs correspondants.
La dernière étape est celle de stockage des données: en effet, les données recoltées et nettoyées sont conservées dans des fichiers sous l'extension txt et xml ayant comme encodage UTF-8.
L'aperçu du script


Script
Ce script nous permet de récuperer le contenu des fil RSS des rubriques choisies et de nous avons obtenu, comme précédemment précisé, un permier fichier en format text: ce fichier contient simplement une liste des titres et des descriptions des artilces. Un deuxième, en format xml avec une structure hiérarchique 'article' qui contient à son tour le titre et sa description.
Aperçu de la sortie "A la une" /en format txt & xml/
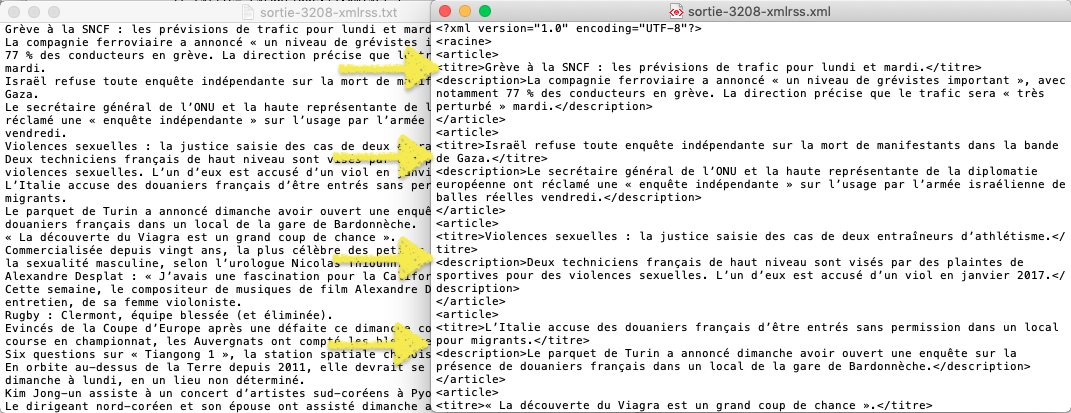
TXT
XML
Aperçu de la sortie "International" /en format txt & xml/
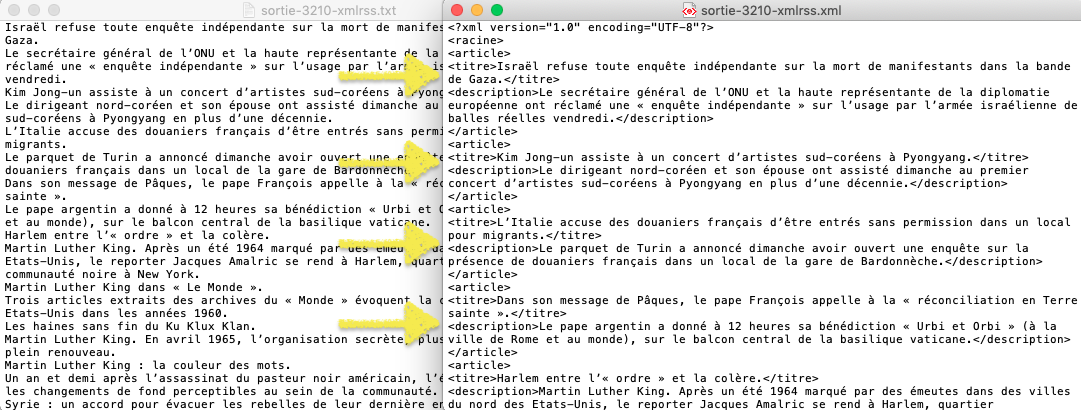
TXT
XML