Description
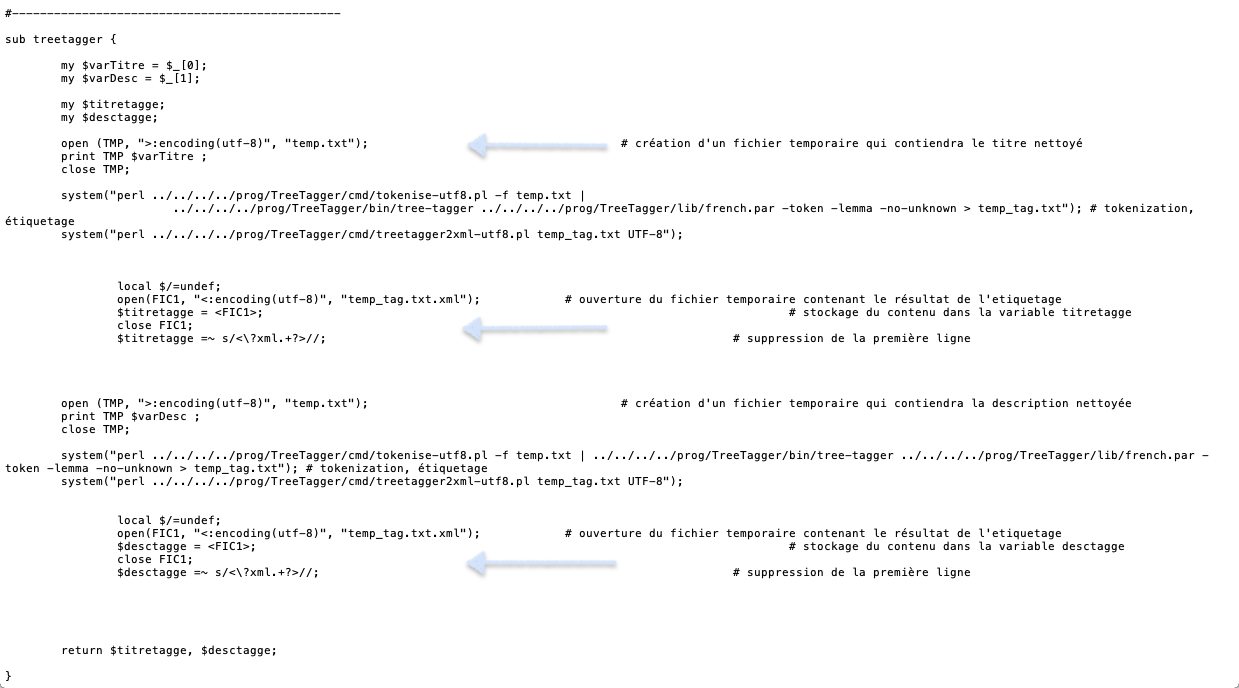
La deuxième boite-à-outil nous permet l'étiquetage des données. Nous avons utilisé donc deux outils: Treetagger et Talismane qui sont deux outils d'annotation des parties de discours, en les intergrant dans le script de la BàO1.
La fonction de Perl 'system' nous a permis d'automatiser le traitement avec ces deux outils et de ne pas les appeler en ligne de commande.
Par ailleurs, nous avons utilisé le script 'tokenise-utf8.pl' pour segmenter le contenu en tokens, étape nécessaire pour passer à l'étiquetage avec Treetagger, et le script « treetagger2xml-utf8.pl » qui nous permet d'avoir un output en format XML, généré suite à la segmentation et l'étiquetage avec Treetagger .
TREETAGGER
Treetagger est un étiquetteur morpho-syntaxique permettant l'annotation des parties du discours. cet outil a été conçu par Helmut Schmid dans le cadre du TC project, au sein du Institut für Maschinelle Sprachverarbeitung de l'Université de Stuttgart.
C'est un étiquetteur probabiliste utilisé pour annoter plusieurs langues comme le français, l'anglais, l'allemand, le russe ... Pour annoter les données, Treetagger recourt à l'arbre de décision qui est un arbre binaire obtenu par entrainement.
TALISMANE
Talismane est un étiquetteur syntaxique developpé par ASSAF URIELI au sein du laboratoire CLLE-ERSS. Pour annoter les données Talismane utilise l'analyse en cascade avec 4 étapes: (le découpage en phrase, le découpage en mot, l'étiquetage, et le parsing)
Fonctions ajoutées

Script
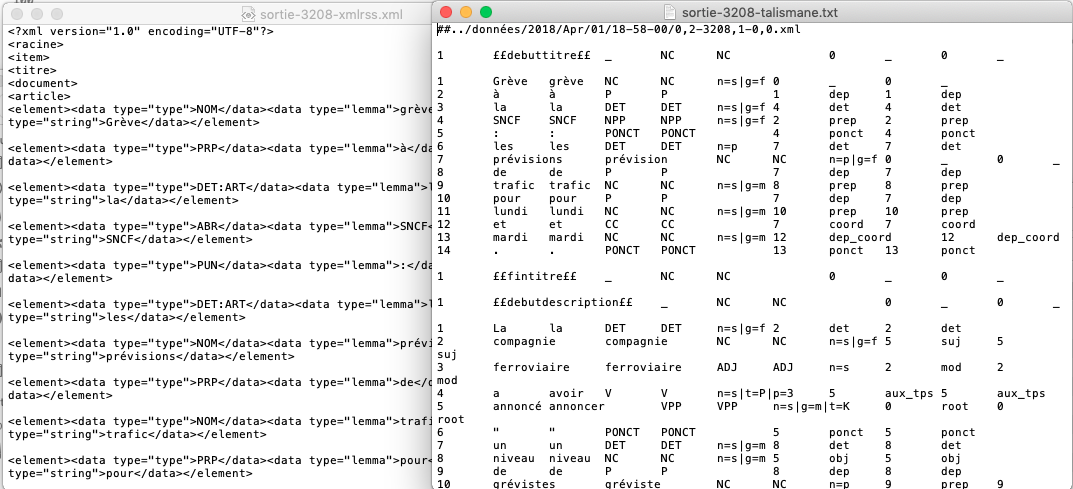
L'aperçu de l'output "A la Une" (Treetagger & Talismane)
XML
TXT
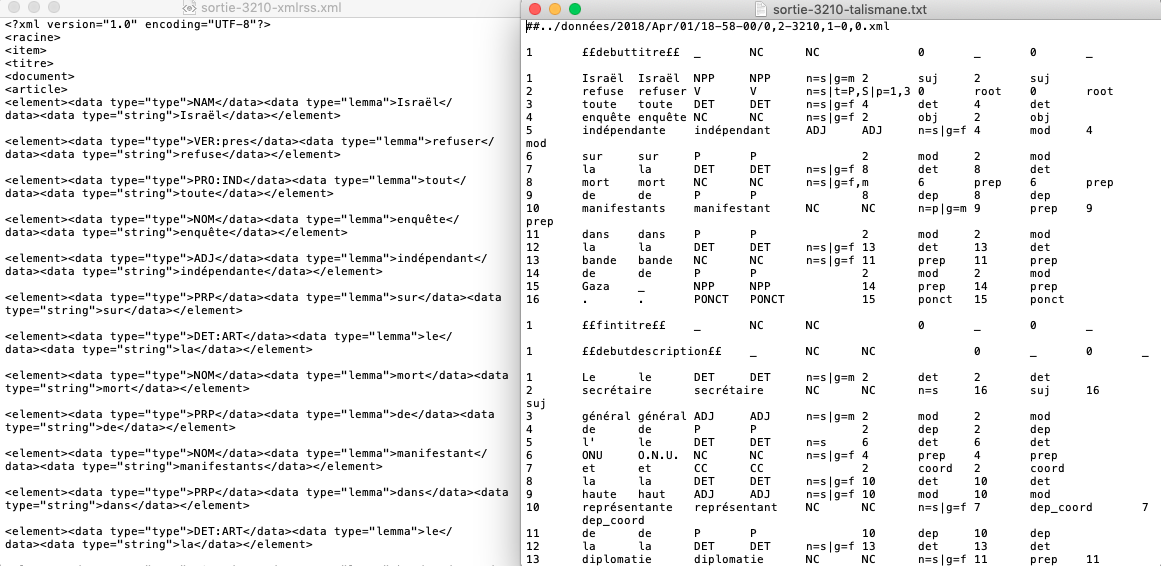
L'aperçu de l'output "International" (Treetagger & Talismane)
XML
TXT
Comparaison des données obtenues par Talismane VS Treetagger
Dans cette partie nous allons commenter brièvement les donées obtenues par les deux étiqueteurs. En effet, comme figure sur les deux captures précédentes, nous avons quasiment le même étiquetage des deux cotês.
Une question peut-être vous vienne à l'esprit quand vous regarder ces résultats ,si vous utiliser ces outils bien évidemment, est la suivante "certes Treetagger est un outil très utilisé mais nous avons toujours eu des erreurs d'étiquetage par ci par là!"
Ce que nous avons pu observer selon nos sorties, c'est que Treetagger fait un mauvais étiquetage plus souvent, et notemment en ce qui concerne les apostrophes, les articles, etc. en dépit des manipulations d'ajout de séparateurs que nous avons fait précédement.
En même temps, une des différences que nous pouvons observer en faveur de Treetagger c'est que le dernier a annoté de façon plus pertinente que Talismane le token 'SNCF': Talismane le considère comme nom propore vu les majuscule mais Treetagger lui attribue l'étiquette de abréviation ce qui est linguistiquement plus précis.