PERL
Nous commençons le traitement par le biais du script Perl extract-terminologie-bisbis.pl qui demande deux arguments dans la ligne de commande :
---> un texte étiqueté et lemmatisé par Talismane
---> un fichier de patrons syntaxiques "Termino" avec un patron par ligne (ex: DET NC ADJ)
Le rendu final est un fichier qui contient pour chaque patron sa liste de termes triés par fréquence
L'aperçu du script


Script
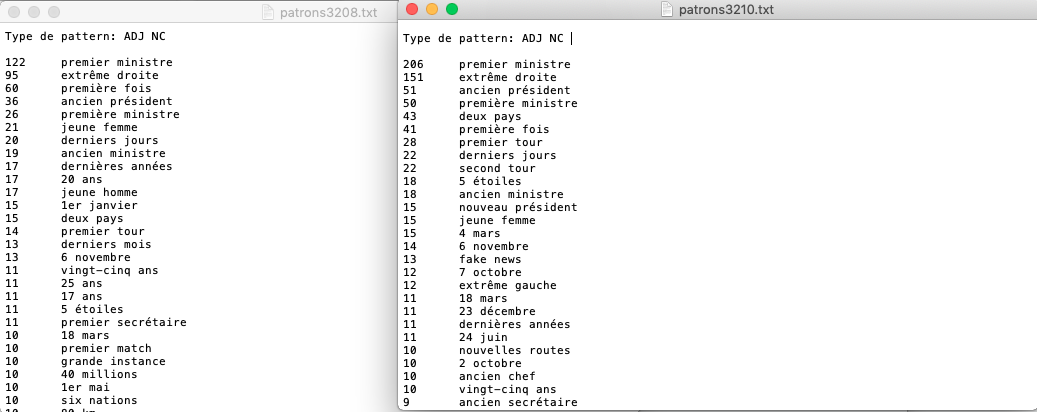
Output ADJ NC
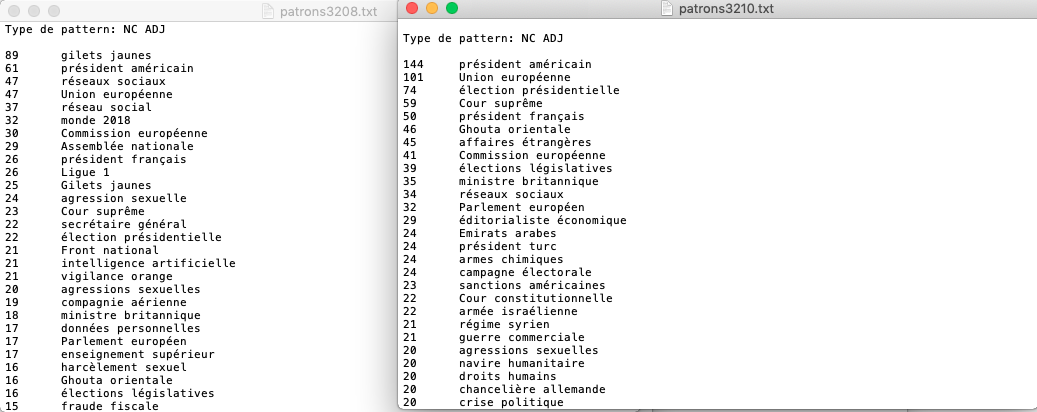
Output NC ADJ
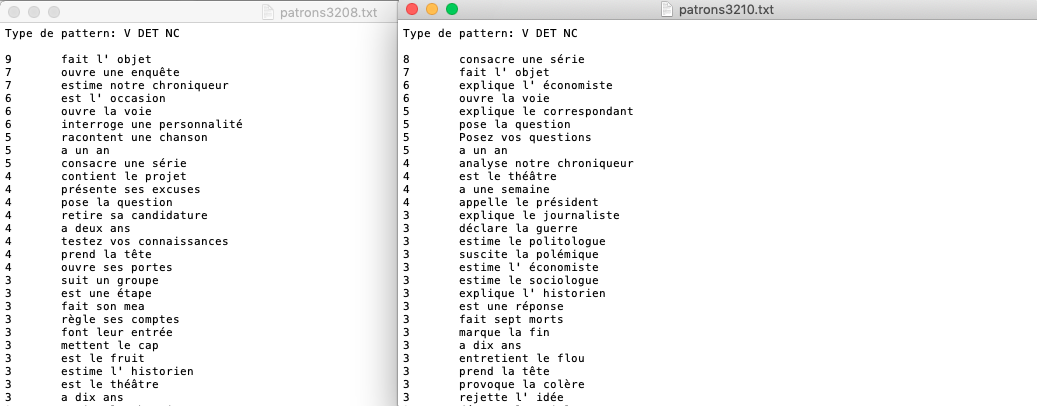
Output V DET NC
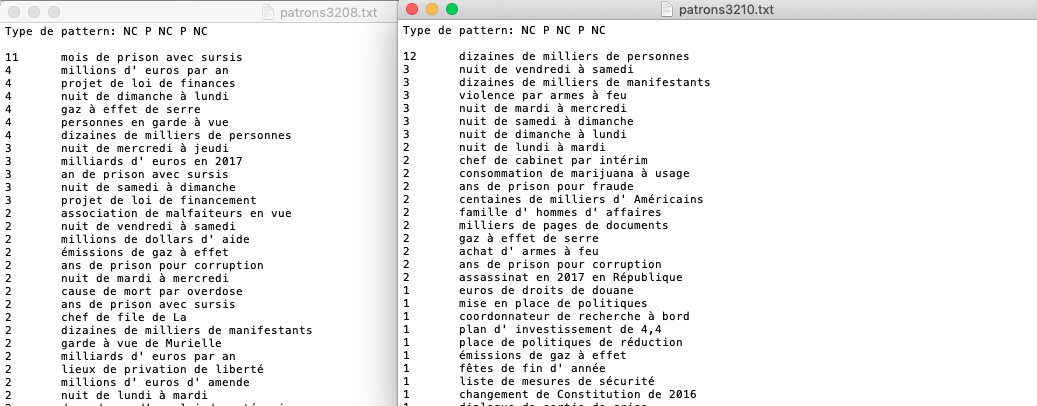
Output NC P NC P NC
A la Une
International
XSLT
Dans cette partie du travail, nous avons utilisé les feuilles de style afin de manipuler le contenu des fichiers et de le modifier.
Le but est d'extraire différents patrons morpho-syntaxique du coprus annoté par treetagger en format xml. Pour extraire les données nous avons procédé comme suivant:
---> En tant que données d'entrée, nous avons utilisé l'output annoté avec treetagger
---> Nous avons donc écrit un fichier xsl dans lequel nous avons défini le contenu des requêtes
---> Aussi nous avons installé sur nos machines le processeur Saxon.jar pour XSLT et XQUERY afin de pouvoir appliquer les feuilles de style sur les fichiers d'entrée xml, à partir de la ligne de commande.
---> A la fin, nous avons utilisé la commande suivante pour générer le tri:
java -jar ./SaxonHE9-9-1-1J1/saxon9he.jar ./sortie-3210-xmlrss.xml ./VERB_DET_NOM.xsl -o:./outputVERB_DET_NOM3210.fo.
En effet, cette commande a besoin de quatre arguments:
1- le chemin vers saxon sur notre machine = 'java -jar ./SaxonHE9-9-1-1J1/saxon9he.jar'
2- le fichier xml (annoté par Treetagger) = ./sortie-3210-xmlrss.xml
3- la feuille de style xsl = ./VERB_DET_NOM.xsl
4- un fichier dans lequel nous allons stocker les données renvoyées = ./outputVERB_DET_NOM3210.fo
Requêtes XSLT :
ADJ NC
NC ADJ
V DET NC
NC P NC P NC
Output ADJ NC
A la Une
International
Output NC ADJ
A la Une
International
Output V DET NC
A la Une
International
Output NC P NC P NC
A la Une
International
PROBLEMES TREETAGGER
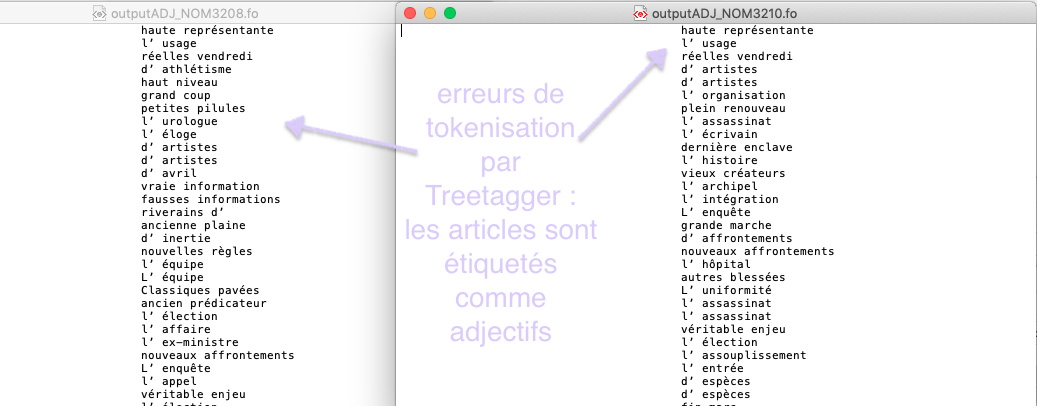
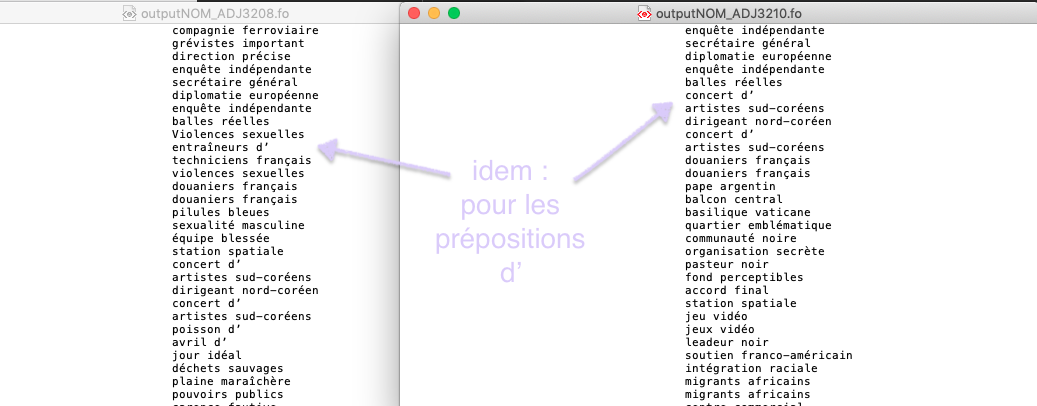
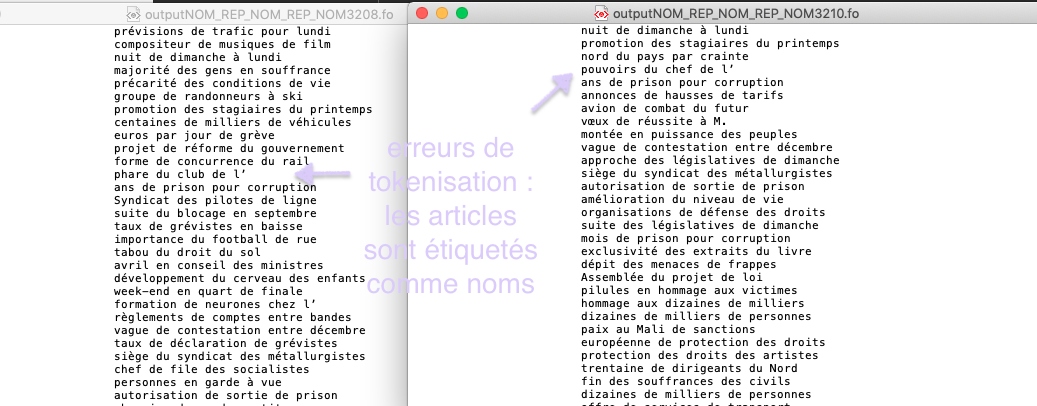
Comme nous l'avons déjà évoqué dans la bào2, Treetagger est un outil très utilisé dans le monde du traitement automatique des langues mais cet outil a ses limites. Bien que nous avons corrigé le script afin de bien segmenter le texte en token, Treetagger a tout de même commis des fautes lors de la phase d'étiquetage.
Ces erreurs d'étiquetage étaient remarquables lors de l'extraction des patrons morpho-syntaxiques. En effet et notamment avec les patrons (nom+adjectif) et (adjectif+nom) nous avons constaté que la quasi totalité des déterminants élidés étaient taggués comme 'ADJ' quand il d'agit des minuscules, ou comme 'ABR' quand il s'agit des majuscules.
Par le biais de cet outil, nous sommes arrivées à extraire les patrons demandés mais après examen des données les résultats sont parfois erronés.
En conclusion, il nous semble évident de dire que la phase de l'étiqutage est primordiale parce qu'elle est en grande partie la reponsable du bon ou mauvais résulat qu'on peut avoir à la fin de notre travail.
BASEX
C'est un système de gestion de base de données xml. Il est spécialisé dans le stockage, la requêtage et la visualisation de larges documents et collections de documents XML. Ce système supporte le langage de requête standard tel que Xpath et Xquery.
Dans cette étape, nous avons utilisé les fichiers étiquetés par Treetagger comme notre base de données, et puis nous avons crée des requêtes xQuery afin d'extraire les patrons qui nous intéressent.
Requêtes xQuery :
ADJ NC
NC ADJ
V DET NC
NC P NC P NC
Output ADJ NC
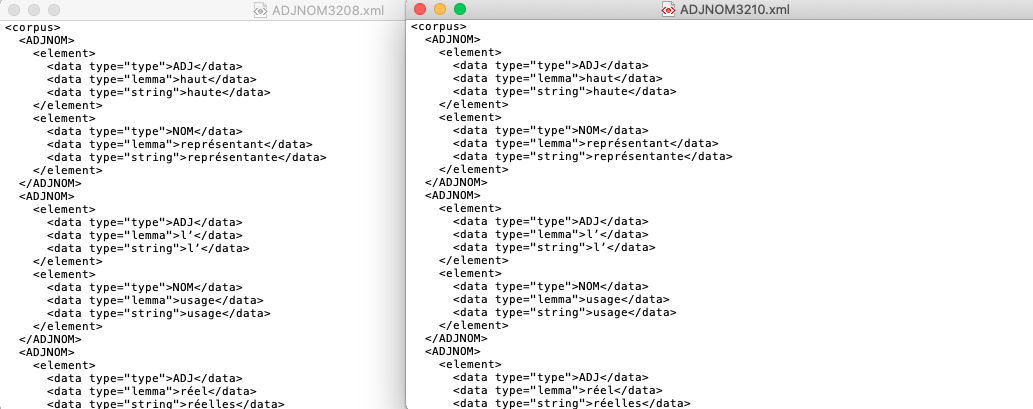
A la Une
International
Output NC ADJ
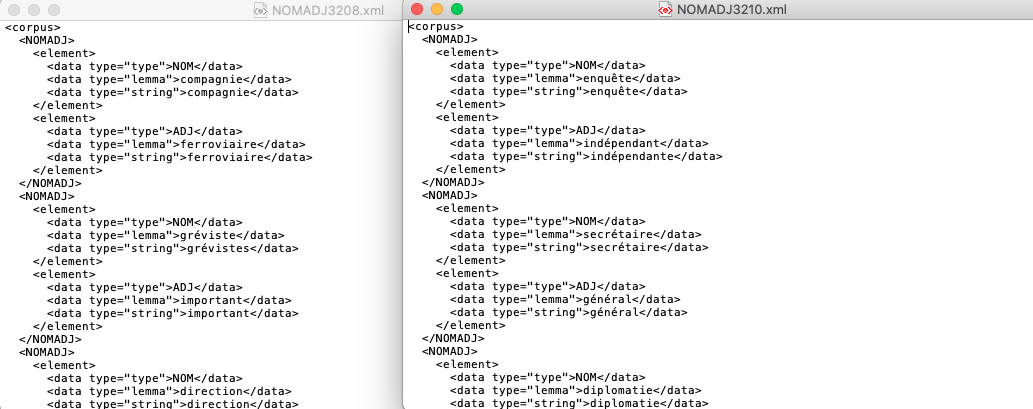
A la Une
International
Output V DET NC
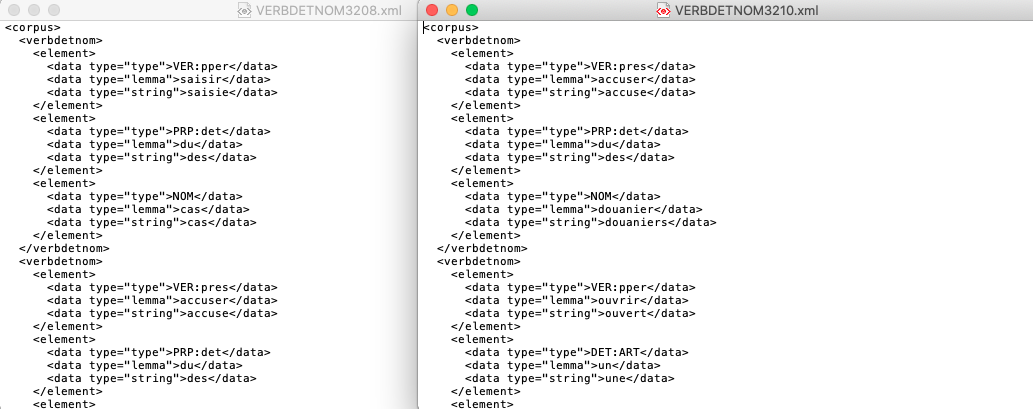
A la Une
International
Output NC P NC P NC
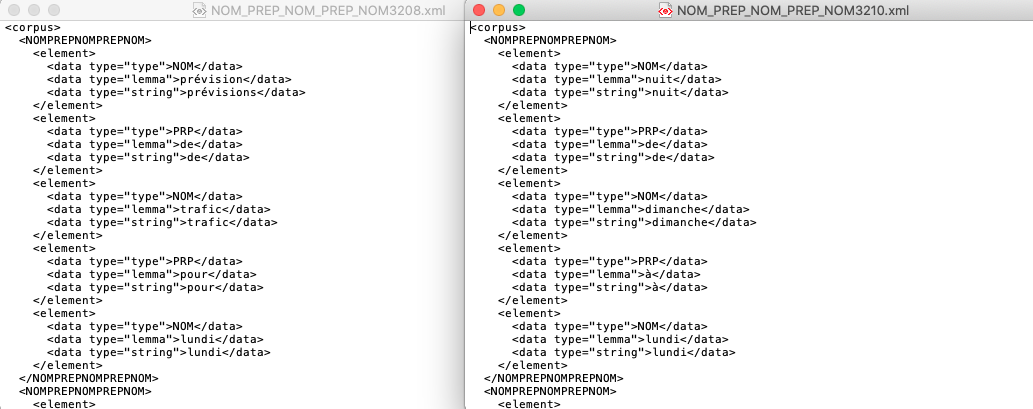
A la Une
International
PERL. DEUXIEME SOLUTION
Cette méthode permet d'extraire simultanément tous ces patrons sur la sortie TALISMANE, préalablement reformatée en XML via un script perl, fourni par nos professeurs lors des cours.
Script
Requêtes xQuery :
Les solutions aux requêtes en question se diffèrent en terme du tri des patrons et sont données ci-dessous :
TriéNon trié
Output "A la une"
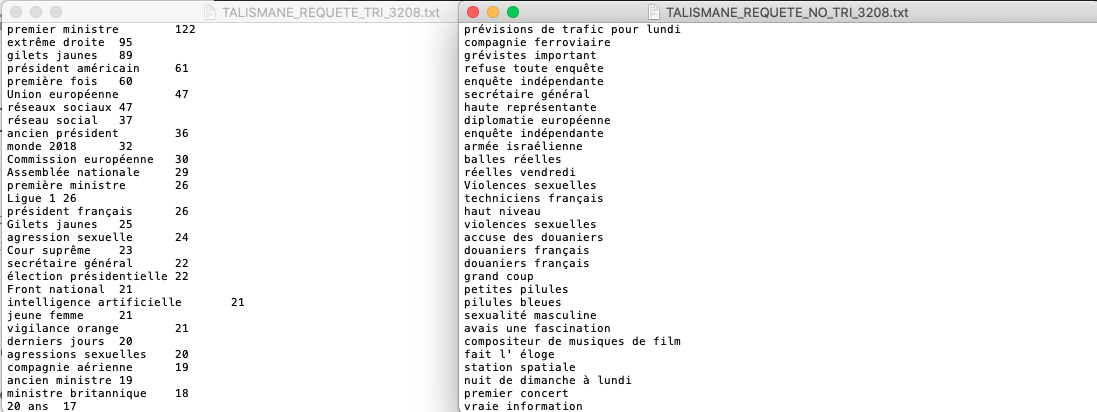
Trié
Non trié
Output "International"
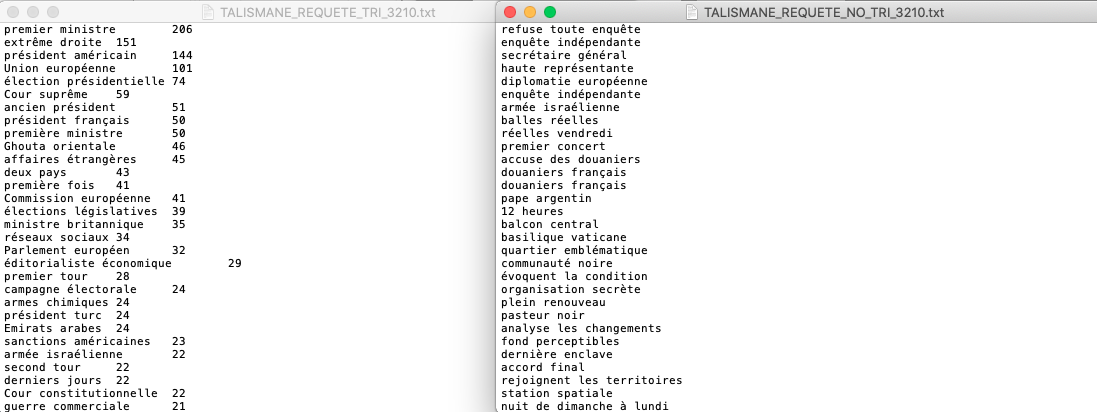
Trié
Non trié
QUELQUES REFLEXIONS
Pour ce projet, nous avons travaillé avec les données dans la langue française. Les résultats obtenus par le biais de l'étiquetage (Treetagger / Talismane) nous ont permis de voir plus clairement quelques différences que nous avons entre les systèmes linguistiques.
En en parlant plus précisement, nous avons été un peu surprises par l'étiquetage des nombres tant que adjectifs. Par exemple, la langue russe possède une partie de discours indépendante pour décrire une quantité numérique qui elle-même se divise en deux parties : de quantité et d'ordre. Toute en ayant des points en commun avec les adjectifs, cette partie de discours ne devra pas être étiquetée tant que ADJ selon la grammaire russe.
Prochainement, nous pensons faire un petit expériment avec plusieurs outils de l'étiquetage : non seulement, avec Treetagger et Talismane, mais en utilisant des modules comme Spacy, Flair, et NLTK en Python. Les résultats pourraient nous servir dans le traitement des données.
En revenant vers le français, nous pouvons dire qu'en ce moment Talismane, Treetagger et Spacy produisent un étiquetage plus pertinent que d'autres mentionnés en haut. NLTK fait plus d'erreurs si le texte contient des mots de slang tandis que Flair fonctionne bien seulement avec les données en anglais et en allemand, les résulats en français ayant un taux d'erreurs beaucoup plus élevé.