Analyse du corpus coréen

En ce qui concerne le corpus coréen, pour le premier essai, j'ai essayé d'utilisé un "gros_fichier.txt" qui regroupe tous les dump textes du corpus coréen et qui les balise.
Cependant, j'ai rencontré un problème concernant notre motif "protection environnementale" en coréen. Parfois le mot peut s'écrire en deux mot contenant un espace (환경 보호) ou bien en un seul mot ne contenant pas d'espace (환경보호). Quand j'ai cherché "환경보호" (sans espace), cette recherche ne résulte pas ce que l'on attendait avoir, voire le résultat ne semble pas cohérent. D'après le tableau obtenu lors de l'exécution du programme bash, il y a seulement deux fichiers dans lesquels le motif ne se trouve pas tandis que ce gros_fichier.txt ne correspond pas à ce résultat.
De plus, comme le coréen est une langue à cas, notre motif était souvent suffixé. Voici quelques exemples :
Ce fait nous aide à comprendre pourquoi le résultat précédent ne correspondait pas à la réalité. C'est parce qu'il ne comprend pas de motif qui est suffixé. C'est un de mes arguments pour l'utilisation des fichiers segmentés.
En outre, j'ai trouvé des séquences de mots (en l'occurrence, des phrases) qui sont considérées comme un seul mot car elles ne contiennent aucun espace.

J'ai alors utilisé la fonction "carte" marquée dans l'image au-dessus pour voir dans quel fichier ce "mot" existe et comment. Comme je trouve que la non-existance d'espace est impossible, surtout dans un article de presse, je suis allée directement sur le site. Je suppose que lors de l'aspiration de la page, une légende dans une photo est aspirée sans espace car seulement cette partie ne contient pas d'espace dans le dump texte..

Avec ces différentes raisons, j'ai pris alors les dump textes avec quoi j'ai procédé à la segmentation grâce à l'analyseur morpho-syntaxique du coréen. Puis, j'ai remplacé "환경 보호" par "환경_보호" pour faire la recherche dans iTrameur parce qu'après la segmentation, j'aurais dû avoir une seule forme de mot (환경 보호 et non 환경보호). (à voir dans le blog...)
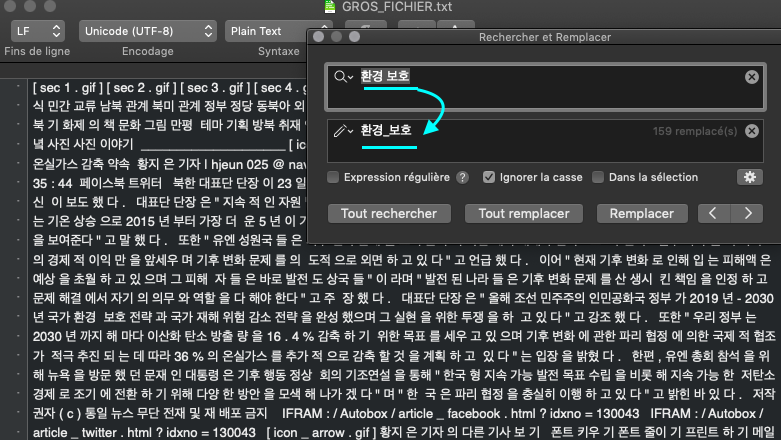
Avant de télécharger le gros_fichier, j'ai supprimé un tiret bas dans la case de délimiteur pour permettre plus tard d'obtenir la forme "환경_보호".
Ventilation
La ventilation est la répartition du mot en parties. Nous en trouvons la fréquence absolue, la fréquence relative et la spécificité. La fréquence absolue compte le nombre de fois que le pôle apparaît dans chaque partie alors que la fréquence relative rapporte le nombre de fois que le pôle apparaît au total des mots dans la partie (donc en tenant compte de la taille de la partie). La spécificité compare une partie avec d'autres parties ; si une partie est en sur-représentation, le motif est particulièrement présent par rapport aux autres parties. Pour ce phénomène, nous nous attendons à avoir le nombre de fois que le motif apparaît équivalent pour chaque partie.
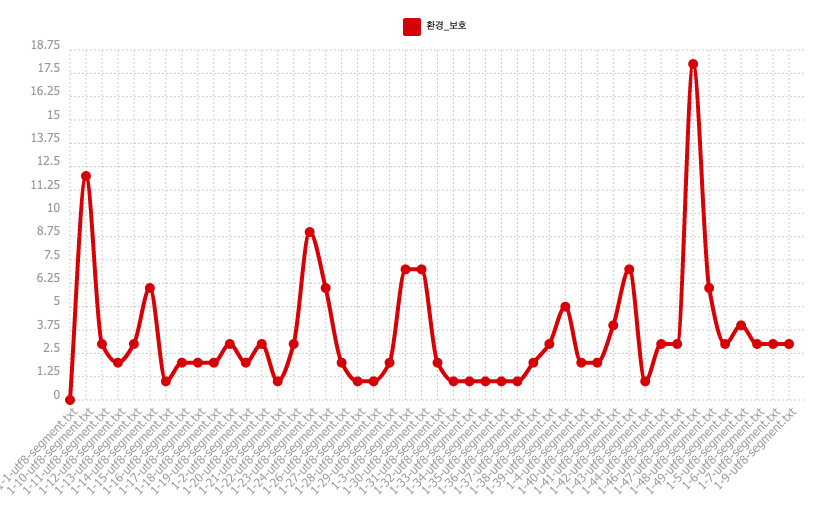
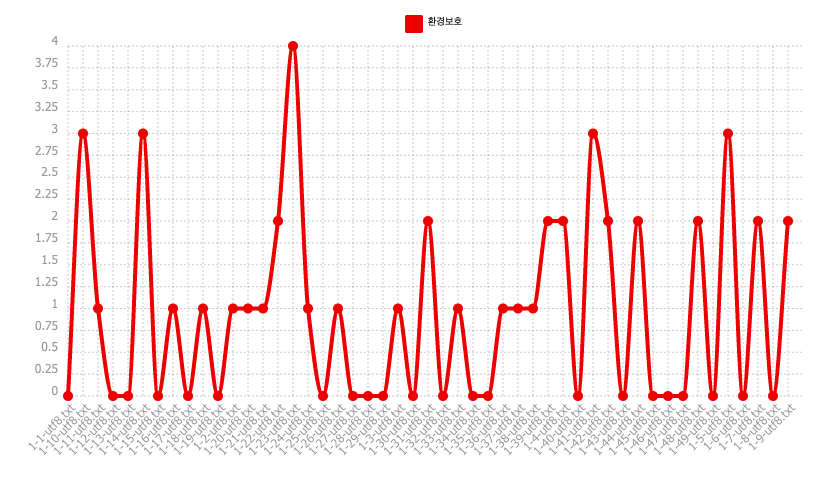
Tout d'abord, on voit que la partie 1-47.txt contient le nombre de fois que notre pôle "환경_보호" apparaît le plus élevé et que la partie 1-1.txt ne contient aucune occurrence du motif. Ces résultats me semblent cohérents car ils correspondent à la fréquence d'occurrence du pôle obtenue lors de l'exécution du programme bash.
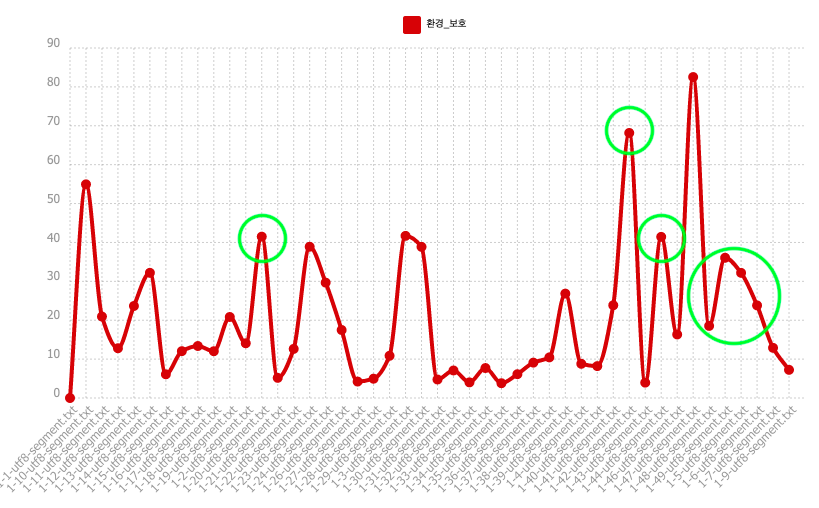
En tenant compte de la taille du texte lors du comptage du motif, on observe des pics remarquablement augmentés. En effet, la fréquence d'occurrences du pôle est peut-être faible dans ces parties, mais elle n'est pas aussi faible par rapport aux autres mots. Ce qui est étonant, c'est que le pic de la partie 1-47.txt est toujours le plus élevé dans la fréquence relative. C'est-à-dire qu'elle contient le pôle plusieurs fois dans son texte mais aussi de divers mots (le texte devrait donc être long).
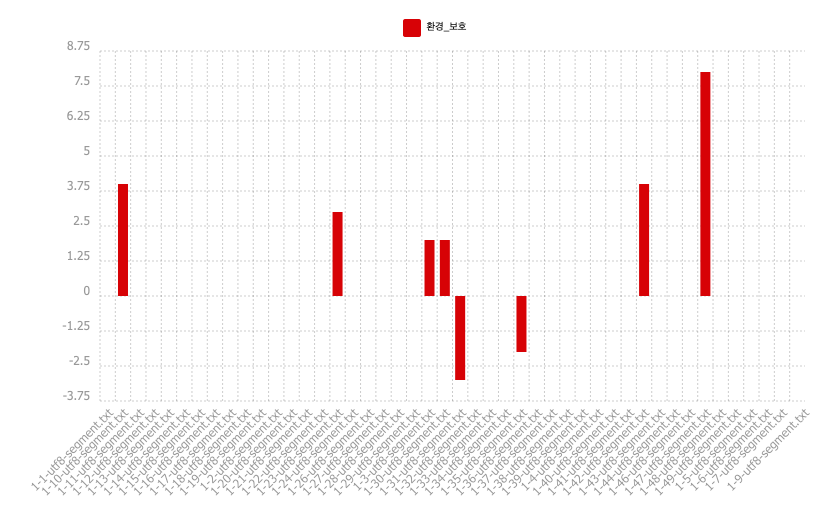
Enfin, en ce qui concerne la spécificité, on peut considérer que celle-ci resemble à la fréquence absolue. Dans la fréquence absolue, nous pouvons repérer les 6 pics les plus élevés qui correspondraient aux barres positifs dans la spécificité. Cela montre la sur-représentation du motif "환경_보호" dans la partie de ces derniers comparé aux autres parties. Cependant, nous avons une barre négative pour la partie 1-31.txt qui indique que le pôle est particulièrement absent par rapport aux autres, donc la sous-représentation.
BT et VN
Comme nous ne travaillons pas sur l'évolution du terme dans le temps, nous n'étudierons pas dessus.
Co-occurrence
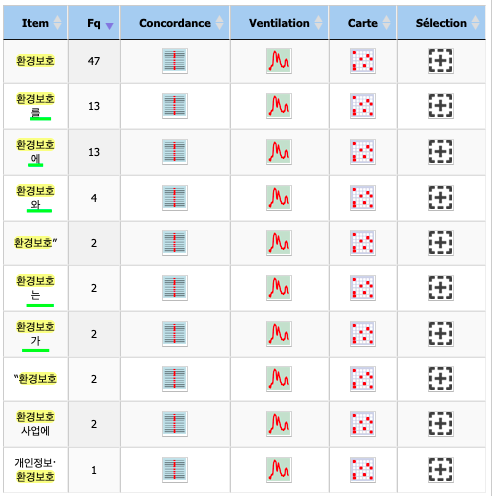
Comme nous nous intéressons au champs lexical du terme "protection environnementale", nous allons étudier la co-occurrence de ce mot. Pour faciliter la vue, j'ai souligné les mots pleins (lexèmes).
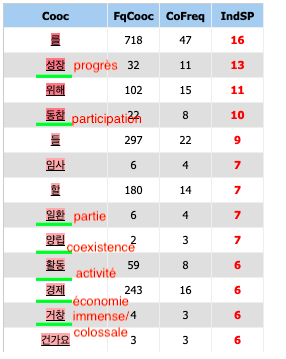
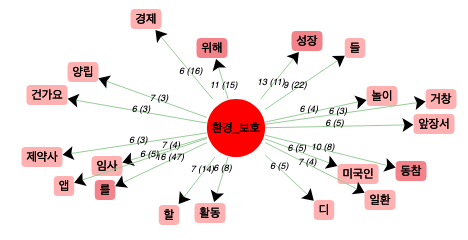
Le mot "progrès" est le plus fréquemment utilisé avec le pôle "protection environnementale". Quand on regarde les contextes, nous observons que ce mot est utilisé avec l'économie, ce qui est équivalent au mot "la croissance économique" en français. Trouvant qu'il est curieux d'avoir toujours ce dernier dans les contextes, j'ai raffiné la recherche pour avoir des informations sur la partie contenant ces contextes.
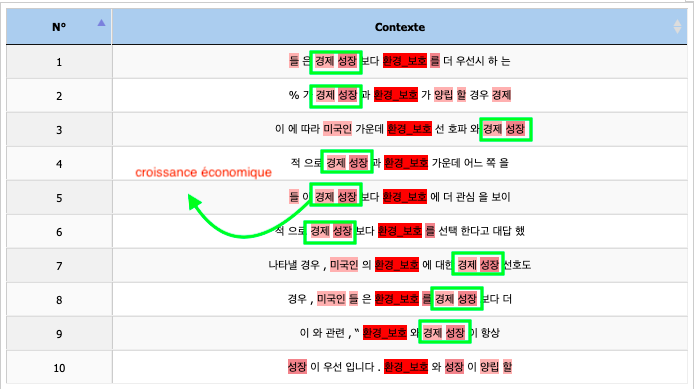
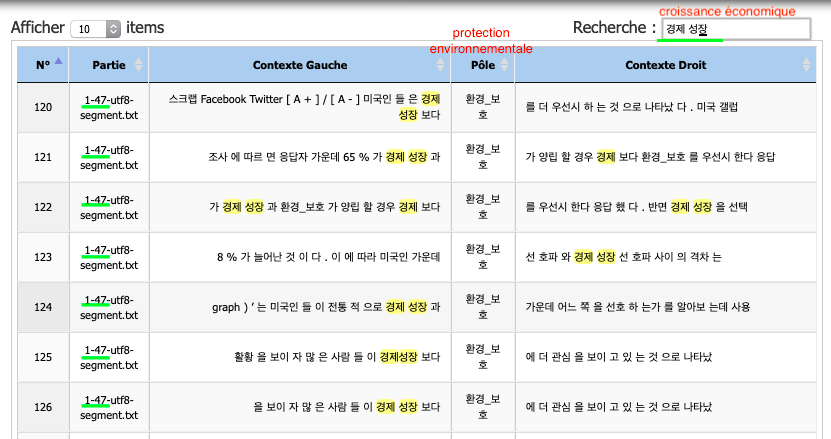
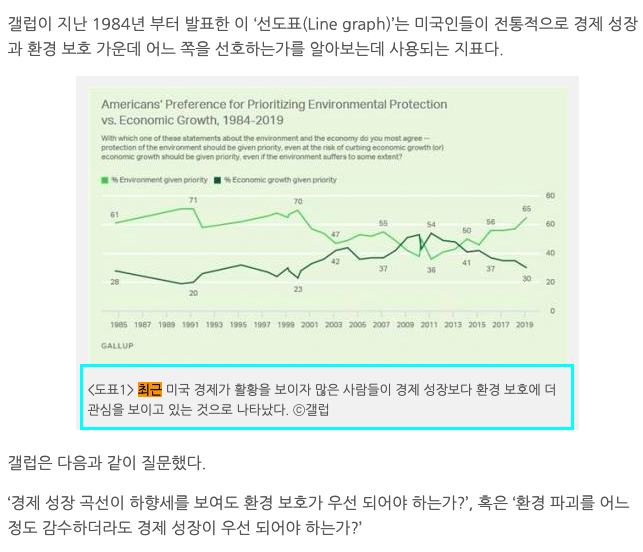
Toutes ces contextes sont tirées d'un seul texte parlant d'un sondage fait aux États-Unis. Les américains auraient dû répondre à un sondage sur le choix entre la croissance économique et la protection environnementale.
En outre, le reste du résultat "participation", "partie", "activité", "immense/colossale" est employé afin de montrer la participation d'une partie des activités dans le but de protéger l'environnement. Particulièrement, le mot "immense/colossale" est utilisé, je suppose, pour se demander si la protection environnementale est difficile, et aborder des exemples d'activités danoises.
Analyse du corpus anglais
Pour le corpus anglais, j'ai remplacé "environmental protection" par "environmental_protection" pour lui faire une seule unité lexicale et pouvoir l'analyser dans iTrameur.
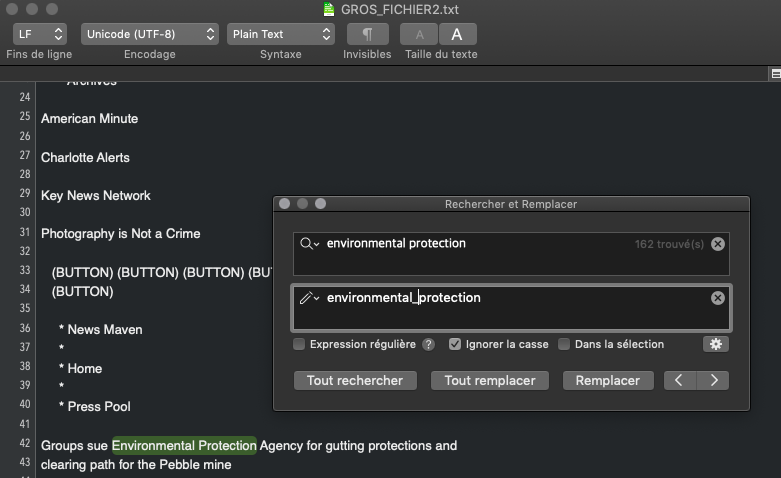
Ventilation
La fréquence d'occurrences du motif me semble cohérent car elle correspond au resultat obtenu grâce au script bash. C'est la partie 1-60.txt qui a le nombre de fois que le pôle apparaît le plus élevé parmis les 60 parties dans le corpus anglais. En outre, nous avons trois parties 1-12.txt, 1-41.txt, et 1-5.txt qui comptent 0 fois d'apparition du motif au sein de leur texte.
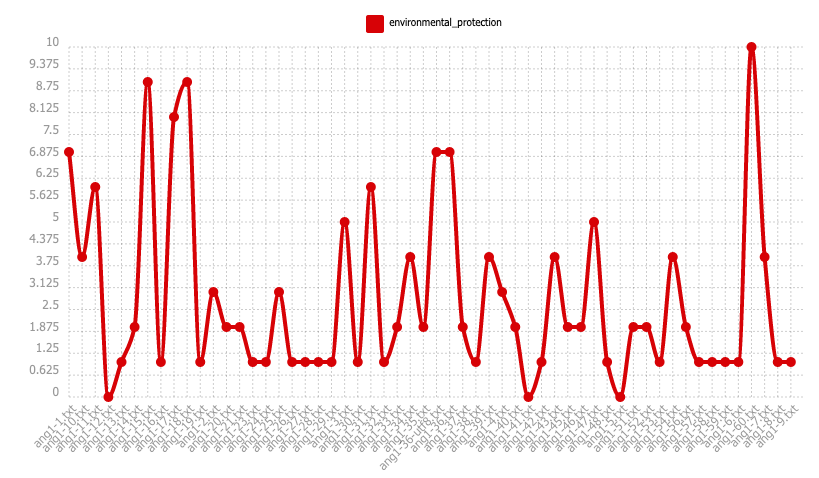
En ce qui concerne la fréquence relative, nous observons non seulment la hausse de fréquence, mais aussi l'abaissement. L'augmentation des fréquences est marquée en bleu, ce sont la partie 1-31.txt, 1-46.txt et 1-47.txt qui y sont concernés. C'est parce que leur taille de texte ne serait pas quantitative, la fréquence relative a été augmentée. Quant à la diminution de fréquence marquée en vert, on voit que ce sont des pics les plus élevés sont abaissés car l'on rapporte le nombre de fois que le motif apparaît au total des mots existant dans le texte. L'on peut supposer que les textes concernés seraient plutôt courts.
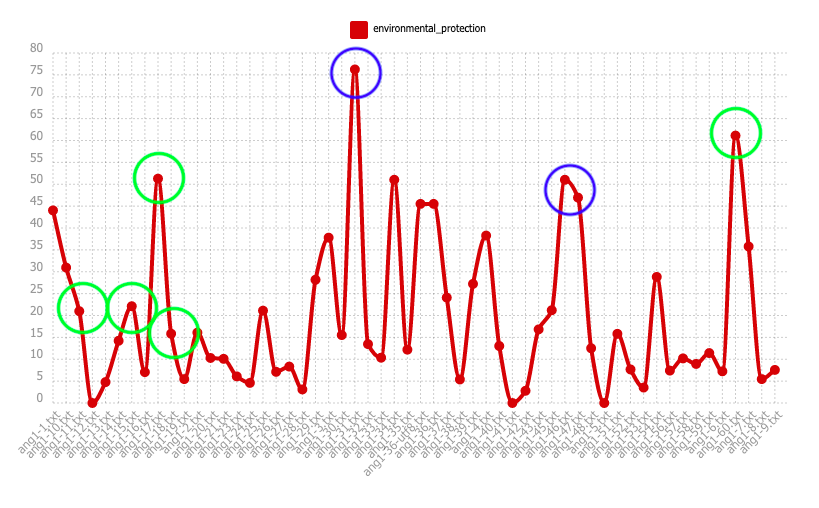
Concernant la spécificité, les parties, qui ont des pics les plus élevés dans la fréquence absolue ou/et la fréquence relative, sont sur-représentées. Dans celles-ci, le pôle est spécialement présent par rapport aux autres parties. Cependant, les parties 1-28.txt, 1-42.txt, et 1-53.txt sont sous-représentés, c'est-à-dire, ce sont les parties dans lesquelles le motif est considérablement moins présent comparé à d'autres parties.
Co-occurrence
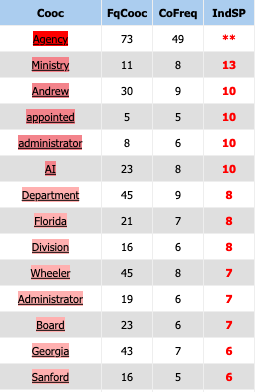
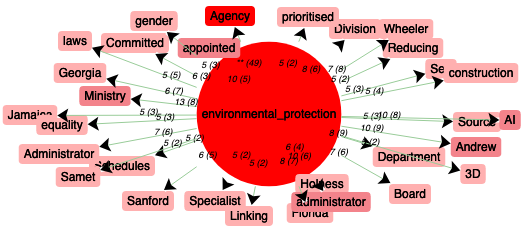
La plupart des co-occurrents du motif "environmental protection" sont des termes liés à la politique ou aux départements/villes des États-Unis. Le motif est presque toujours suivi d'un mot "Agency" car c'est "Environmental Protection Agency" est un nom d'une agence aux État-Unis. Comme elle travaille pour protéger l'environnement, elle serait bien souvent nommée dans des articles de presse dont le sujet est la protection environnementale. De plus, le nom de l'administrateur de cette agence "Andrew Wheeler" est aussi fréquemment employé avec le motif.
Parmi des termes de politique, nous avons un mot "AI". C'est dans la partie 1-10.txt, on parle des techniques de l'IA qui peuvent être très bénéfiques pour protéger l'environnement et aussi pour l'analyse environnementale.