Français
Commençons par noter que nous avons limité géographiquement la recherche d'URL à la France, les résultats suivant ne concernent donc pas, à priori, les articles provenant d'autres pays francophones.
Observons tout d'abord les résultats d'iTrameur.
Pour le français, on constate sans surprise beaucoup de petits mots vides tels que "la" ou "de" ainsi que des résultats un peu plus étranges tels que "n1" ou "autoindexee". En y regardant de plus près grâce aux options de ventilation d’iTrameur, il semble que ces "n1, n2, n3 autoindexee" proviennent tous de la même page, une page du CHU de Rouen recensant un très grand nombre d’articles médicaux contenant le mot "sexualité", un peu comme un corpus dans notre corpus ! Et tous ces articles sont séparés par des balises de type "n1 autoindexee" dans le dump. Nous ne tenons donc pas compte de ces mots, et nous focalisons sur les mots porteurs de sens pour notre analyse.
En français, le thème de la sexualité semble être abordé essentiellement dans des sujets de vie sexuelle, d’épanouissement sexuel, de vie de couple ("épanouie", épanouissante", "sentiments", "couple", "expérience", "conjugal") mais aussi dans des sujets médicaux ("médecine" "grossesse" "tumeur" "cancer" "généralistes" "contraception") et d’éducation sexuelle ("éducation" , "adolescents", "apprend"). D’autres mots très représentés dans les cooccurrences sont "genre", qui laisse donc à penser que sexualité est également souvent trouvé dans des questions d’identité sexuelle, ou orientation sexuelle, et "handicapée". Il y avait effectivement beaucoup d’articles concernant la sexualité des personnes handicapées parmi les URLs analysées.
L’analyse des nuages de mots, basée sur la concaténation des fichiers contextes, montre des résultats similaires aux coocurrences d’iTrameur, c’est bien logique. On notera que "femme" est beaucoup plus représenté que "homme". La sexualité serait donc plus vu comme un sujet concernant les femmes ?
Comparons maintenant nos données avec celle d’un corpus plus important, via le corpus de l’Université de Leipzig.
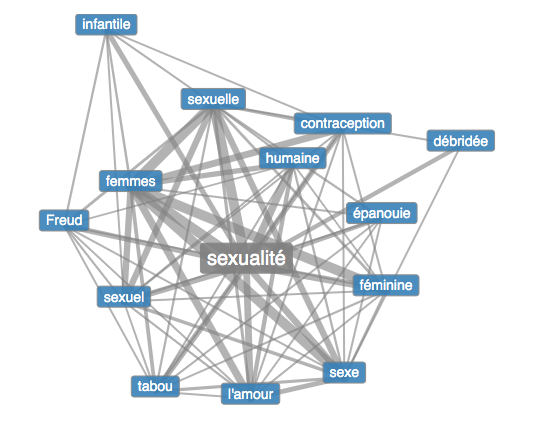
On voit que les résultats sont dans l’ensemble assez similaire, mais ceux du corpus de l’université de Leipzig comporte les mots "Freud", "tabou", qui font plus penser à l’analyse de la sexualité dans un contexte de psychologie et de la psychanalyse, et "infantile", qui fait probablement également référence au postulat de la "sexualité infantile" de Freud. Pour le français, l’analyse est basée sur le corpus "Corpus: French (fra_mixed_2012)" de l’université de Leipzig. On peut donc supposer que ce corpus contient beaucoup plus de contenu relevant de la psychologie et psychanalyse que notre corpus.
Anglais
Les analyses sur les co-occurrents de sexualité en anglais sur iTrameur ont démontré que, à part quelques mots vides, le mot sexualité en anglais est le plus lié à des termes tels que le genre, l'ethnie, l’histoire, ainsi que les relations et l’identité. Un autre mot fortement lié à sexualité était la citoyenneté, ce qui pour moi était un résultat peu attendu. Heureusement, iTrameur m’a permis de regarder facilement les contextes dans lesquels la citoyenneté se trouve en cooccurence avec la sexualité, et cette fonction a révélé que ces cooccurrences semblent provenir d’une seule revue de livre consacrée à ce sujet. Ceci montre que, même avec un corpus relativement grand, un seul texte peut avoir un impact important sur nos résultats. Une tendance similaire se voit avec les mots ethnie, genre, et pouvoir, qui sont tous les trois surreprésentés parce qu’ils sont inclus dans un titre de texte cité plusieurs fois dans une bibliographie.
D’autres mots tels que « pouvoir » et « constructions » suggèrent que la théorie du genre a une influence importante sur notre corpus en anglais. Ceci n’est pas particulièrement surprenant, puisque une grande portion des URLS que nous avons récupérés semblent porter sur l’identité sexuelle, mais nous avonss été surpris de ne pas voir plus d’occurrences portant sur la reproduction et le bien-être sexuel. Dans les réglages, on a cherché des co-occurrences à dix mots de sexualité, mais cette tendance reste plus ou moins constante quels que soient les réglages. Néanmoins, un regard rapide à notre nuage de mots montre que santé est un des mots les plus communs dans notre corpus. Ceci suggère que le bien-être sexuel est un concept important dans notre corpus, même si le mot santé se trouve plus rarement à côté du mot sexualité.
Enfin, on a comparé ces résultats à ceux d’un programme similaire proposé par l’Université de Leipzig, qui génère des graphiques des co-occurrences d’un mot donné dans de vastes corpus proposés en plus de 200 langues.
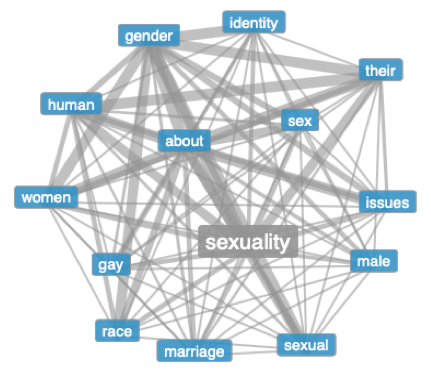
Leurs résultats pour le mot sexualité semblent beaucoup plus généraux, soulignant des mots comme « femmes », « humain » ou bien « enjeux ». Je soupçonne que ceci est le résultat d’un corpus beaucoup plus grand que le nôtre, qui est moins susceptible d’être influencé par une petite minorité d’articles qui contiennent un mot spécifique de nombreuses fois, comme c’était le cas pour citoyenneté.
Il convient également de noter que lors de la récupération des liens, nous avons limité nos résultats à des pages écrites au Royaume-Uni, donc il est possible que focus géographique plus limité explique partiellement cette différence.
Arabe
Les résultats de l'analyse du mot sexualité en arabe sont encore plus surprenants qu’en anglais. Bien que certains mots associés, tels que famille, santé, la femme et même le développement, n’ont rien d’étonnant, le mot ayant le plus haut niveau de co-occurence est un mot qui désigne « formation », ce qui n’est pas forcement le premier concept auquel la plupart d’entre nous associe la sexualité. On s'est dit que cela doit faire référence à l’éducation sexuelle, mais on a décidé de regarder le mot en contexte pour en être certains.
Finalement, toutes les phrases contenant ce mot parlaient d’un forum sur la sexualité qui a eu lieue dans la ville de Naplouse, en Palestine. Cela explique également pourquoi Naplouse et le mot forum occupent une position aussi élevée parmi les co-occurrents. Nous étions également curieux de voir pourquoi le nom du philosophe français Michel Foucault pouvait apparaître si souvent dans le corpus. On a découvert une série de phrases académique examinant ses théories sur la sexualité. En examinant le corpus, on trouve quelques articles mentionnant Foucault, même si le nombre ne semble pas du tout proportionnel à la position de ce nom dans notre liste de co-occurrents. Ceci démontre encore comment nos résultats peuvent être influencés par une minorité de textes s’ils mentionnent un certain mot très souvent. D’autres mots qui s’affichent plus bas, comme étude, justice, et rôle, semblent plus cohérents à ce qu’on imaginait trouver, mais la dernière tendance qui saute aux yeux est la série de références à la Tunisie. Encore une fois, tous ces co-occurrences sont le résultat d’un même sujet : des études sur la sexualité des Tunisiens.
Nous avons également essayé de générer un graphique de co-occurrence sur le service proposé par l’Université de Leipzig, mais aucun graphique n’a été proposé, apparemment en raison d'un manque de données. Ceci montre que la traduction de sexualité que nous avons choisie pour l’arabe pourrait simplement être utilisé moins souvent et dans moins de contextes que dans d’autres langues, ou bien que ce sujet est traité moins souvent dans les médias arabes. Cette hypothèse est confirmé par nos recherches sur Google, qui proposait pas plus de 150 résultats pour notre requête. Il est possible qu’une traduction moins exacte mais plus commune aurait généré des résultats moins influencés par des sujets extrêmement précis, tels que le travail de Michel Foucault ou le forum à Naplouse.
Même le nuage des mots présente des problèmes similaires pour l'arabe, avec le nom Foucault étant fortement surreprésenté à côté de résultats plus prévisibles comme femmes, hommes, et social.
Russe
Dans le corpus on trouve beaucoup d’articles issus de revues féminines comme Cosmopolitan, Marie Claire et de sites de conseils pour les femmes. On y trouve de longues rédactions sur les femmes et la sexualité, donc dans le corpus russe il n'est pas étonnant qu'il soit plutôt question de la sexualité féminine.
En lisant les contextes des mots les plus fréquents, on peut constater qu’on y parle beaucoup de comment définir la sexualité, comment l’acquérir et la manifester (femme, développement,capacité, comportement, travail). On voit que la sexualité est vue comme quelque chose d’essentiel pour une femme, pour sa vie amoureuse et son bien-être personnel (vie, moment, psychologie, énergie, santé, sentiment, orgasme, personnalité). On insiste aussi sur le fait que la sexualité n’est pas liée à la beauté, le désir, le charme, l’excitation, le sexe, corps. La sexualité est vue comme un état d’esprit d’une femme qui permet d’entre en harmonie avec elle-même. Il semble que le sexualité est très présente dans la psychologie et la santé.
Contrairement à notre hypothèse de départ : il semble que la question de l’orientation sexuelle ne soit pas au cœur du débat dans les résultats en russe.

A la fin, on a comparé notre corpus avec le corpus sur la sexualité de l’Université de Leipzig, pour voir si on trouve les mêmes termes.
En effet, le corpus de l’Université de Leipzig parle plutôt de la sexualité de la femme. On mentionne aussi quelques femme célèbres comme Angelina Jolie et Lindsay Lohan.
Japonais
L’analyse du mot « sexualité » était compliquée, car il n’existe pas de mot vraiment équivalent en japonais. Il existe cependant un mot d’emprunt à l’anglais. L’analyse s’est donc faite sur deux axes :
- analyse du mot d’emprunt (deux orthographes : セクシュアリティ(ー) et セクシャリティ(ー))
-analyse d’un groupe de mots « plus japonais » qui recouvrent les mêmes concepts que « sexualité » en français : 性生活(vie sexuelle) 性欲 (désir sexuel) 性的指向 (orientation sexuelle)…
L’idée était de voir si les résultats seraient similaires ou différents. L’hypothèse était que le mot d’emprunt serait plus souvent trouvé dans des contextes lgbt, ou accompagné de concepts provenant d’occident, tels que ceux liés à la théorie du genre par exemple.
LE MOT D'EMPRUNT:
A partir de l’analyse sur iTrameur, ce qui saute aux yeux en premier est que le motif analysé (le mot d’emprunt à l’anglais pour « sexuality ») compte beaucoup de mots écrits en katakana parmi ses co-occurrents. L’alphabet katakana est celui utilisé pour les mots d’emprunt. Le mot d’emprunt pour « sexuality » est donc souvent accompagné d’autres mots d’emprunt, tels que : カミングアウト (coming out), デミセクシャル (demisexuel), ジェンダー (genre), パンセクシュアル (pansexuel), メンズ - hommes (surtout dans un contexte de mode). Ces mots sont, comme on s’y attendait, liés au milieu LGBT, a l’orientation sexuelle et à l’identité sexuelle. On ne s’avance pas trop en supposant que tous ces concepts sont arrivés d’Occident, puisqu’ils sont exprimés directement avec des mots d’emprunt à l’anglais. Notons également le verbe 迷う(hésiter) qui se rapporte probablement aussi à la sexualité dans le sens d’identité sexuelle ou orientation sexuelle.
Parmi les résultats on trouve également des mots (pas empruntés) concernant les relations et le rapport à l’autre : 自分(soi-même), 他人 (autrui), 関係(relation, rapport), des termes concernant la médecine : 診断 (diagnostic), et l’éducation : 教育(éducation).
On trouve également un résultat un peu inattendu « Freddy Mercury » (フレディ・マーキュリー). Probablement car le film Bohemian Rhapsody a très bien fonctionné au Japon, ce qui a du faire couler de l’encre au sujet de la sexualité de Freddy Mercury.
L’analyse des nuages de mots montre à peu près les mêmes résultats, avec quelques autres termes très représentés :
- lgbt, マイノリティ(minorité), アセクシュアル (asexuel), qui va de pair avec les résultats présentés précédemment
- 社会(société) qui laisse à penser que la sexualité est souvent mise en relation avec les exigences, moeurs ou pression de la société.
Comparons avec les résultats de l’Université de Leipzig.
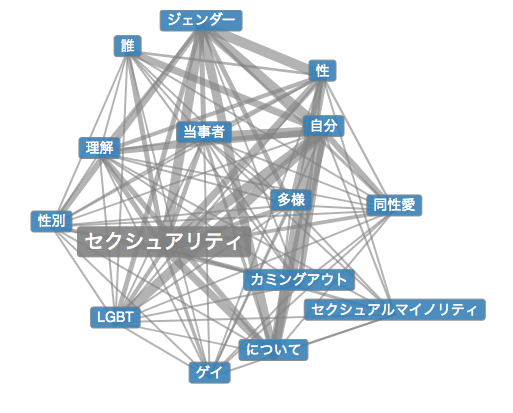
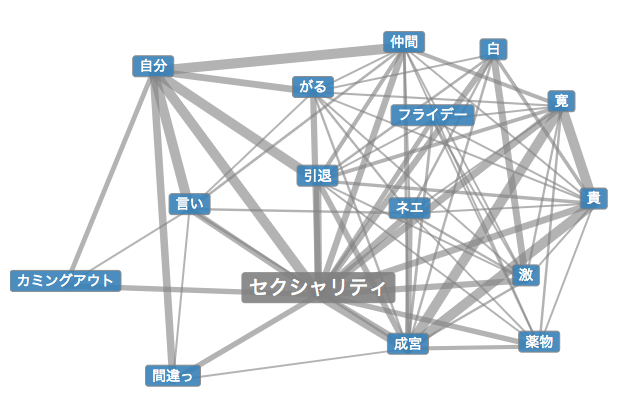
Les résultats sont globalement similaires, notamment au niveau des termes en rapport avec le milieu LGBT, les questions d’orientation sexuelle et d’identité sexuelle. On remarque cependant un termes qui n’était pas dans l’analyse de notre corpus : 薬物 (drogue, médicament). Difficile de savoir pourquoi ce mot se retrouve lié à « sexualité », peut être pour des remèdes aux troubles de la sexualité ? Il faudrait étudier le corpus utilisé par l’Université de Leipzig pour le savoir…
GROUPE DE MOTS "JAPONAIS":
L’analyse des occurrences de mots via iTrameur révèle :
- encore une fois de nombreux termes liés à l’orientation sexuelle et le milieu lgbt: 同性愛 (homosexualité), 異性愛 (hétérosexualité), クエスチョニング (questioning), lgbt
- termes liés à l’identité sexuelle : 性別 (genre, sexe), ジェンダー・アイデンティティ(gender identity)
Jusque là les résultats sont similaires à ceux pour le mot d’emprunt. Cependant, pour le groupe de mots japonais, on observe également une plus grande représentation de mots relevant de :
- la vie de couple et les rapports sexuels : 配偶(conjoint), 親密(intimité)性愛(rapports sexuels),性行為(comportements sexuels)
- l’éducation : 教育(éducation), 性教育(éducation sexuelle), 同級生(camarade de classe)
- les sentiments : 恋愛 (amour), 感じる(ressentir), 共感 (empathie), 心配 (inquiétude)
- domaine médical : 闘病 (maladie)
D’autres termes intéressants avec une haute fréquence sont :
- 復活 (resurrection), probablement utilisé dans le sens de renaissance du désir sexuel, de la vie sexuelle. Cela laisse à penser qu’il existe une préoccupation pour faire renaître la sexualité.
- 面倒くさい (embêtant, chiant), 問題(problème) la sexualité serait donc souvent associée à des choses pénibles.
- 虐待 (abus)
- 高齢(vieillesse, âge avancé), il est bien connu que le Japon souffre actuellement d’un problème de dépopulation et de vieillissement. La forte représentation de ce mot pourrait signifier deux choses : la sexualité des personnes âgées est une source de préoccupation, ou bien : la sexualité (ou plutôt le manque de comportements sexuels) des Japonais est associée au vieillissement de la population.
Enfin, on repère certains résultats étranges : しいたけ (champignons shiitake) ズッキニー(courgette)… Que dire ? Peut-être qu’une recette de cuisine s’est glissée parmi nos résultats.
Le nuage de mot généré à partir des fichiers contexte présente à peu près les mêmes résulats, notons cependant la forte représentation de 差別(discrimination) et 禁止(interdit), qui montrent que la sexualité est également associée avec ces problèmes.
Nous n'avons ici pas comparé avec le corpus de l'Université de Liepzig, car il était trop compliqué d'effectuer la rechercher sur tout un groupe de mots, les expressions régulières n'étant pas supportées.
Espagnol
D’après les résultats, on peut dire que les mots les plus fréquents sont les articles, les pronoms et les prépositions, ainsi que de nombreux noms. Ce sont les noms qui vont nous intéresser pour faire l’analyse des données. Tout d’abord, iTrameur nous permet de voir les mot les plus fréquents de notre corpus, ainsi que le contexte dans lequel ils apparaissent. D’après cela, on va expliquer les différents sujets de discussion autour de la sexualité.
Les mots comme éducation, jeunesse, adolescente, éduquer nous indiquent que la question de l’éducation sexuelle des jeunes semble particulièrement importante. On trouve ces mots dans les sites gouvernementaux, régionaux ou dans des sites de mairies. Cela veut dire que les régions, et les communes s’intéressent à la sexualité des jeunes générations.
On parle aussi de la santé qui apparaît dans plusieurs contextes comme santé sexuelle et santé mentale. Et des sujets un peu plus délicats, comme l’orientation sexuelle (homosexualité, transsexualité), la sexualité chez les personnes handicapés (handicap, personne handicapée, incapacité) et la religion (bible, chrétien, religion).
L’école de psychologie (en espagnol psicologia, escuela) de José Germain est aussi mentionnée, car on en propose des cours de sexualité.
On trouve également beaucoup de mots concernnt la vie de couple (relation, couple, plaisir, amour).
On voit que le mot sexualité a un côté social et spirituel et il n’est pas forcément lié au plaisir et à l’érotisme.
On a comparé nos corpus avec les corpus issus des travaux de l’Université de Leipzig.

Le corpus de l’université de Leipzig et le nôtre renvoient des résultats communs notamment des sujets comme l’orientation sexuelle, l’éducation et la santé.
Analyse globale et conclusion
Au début de notre projet, nous avons émis l’hypothèse que nous trouverions des contextes très différents pour le mot sexualité en anglais, arabe, espagnol, français, japonais, et russe. Notamment, nous croyions que les résultats concernant les langues européennes couvriraient un large éventail de thèmes comme le bien-être sexuel ou le plaisir, une hypothèse influencée largement par notre perception que les discussions sur la sexualité sont plus ouvertes en Occident. En revanche, nous nous attendions à des résultats reflétant des attitudes plus conservatrices en ce qui concerne des sujets comme l’homosexualité ou les relations hors maritales en Russie ou le monde arabe. Nous pensions également que les résultats pour le japonais largement influencés par des phénomènes sociaux locaux, comme le vieillissement de la population ou les hikikomori, jeunes hommes qui choisissent de s’isoler du monde pour poursuivre une vie de célibat.
Après avoir examiné chaque langue, nous avons déterminé que nos résultats ne correspondent pas exactement à nos attentes. Les mots liés à la santé, par exemple, sont fortement liés à la sexualité en anglais et français comme en arabe, même si nous avions pensé que cet aspect du sujet serait traité plus souvent en Occident. Cependant, en russe, les résultats portent très fortement sur le plaisir féminin, ce qui peut contredire notre hypothèse que le sujet serait traité avec une attitude plus conservatrice en Russie. Par contre, le manque surprenant de données sur l’homosexualité en russe et aussi en arabe peut être interprété comme une sorte de confirmation de notre idée que ce sujet est vu comme plus tabou dans les pays où ces langues sont parlées : d'après nos données, ce n'est pas un sujet dont beaucoup de gens parlent ! Les mentions du vieillissement en japonais confirment aussi plus directement que le contexte social local peut avoir un effet direct et tangible sur les résultats. Nos analyses sur cette langue ont aussi dévoilé une association avec des mots négatifs comme « problèmes » ou « pénible ». En regardant les contextes, nous avons trouvé un sondage dans lequel des Japonais se plaignent des problèmes de libido liés au travail. Est-ce que cela reflète la réputation que les Japonais sont surmenés ?
En comparant nos résultats, nous avons également constaté que le mot sexualité est fortement lié à la Femme dans la plupart des langues. Ceci n’est pas très surprenant d’un point de vu intuitif, mais il est quand-même intéressant d’avoir une preuve quantifiable qui soutient l’impression que la sexualité masculine attire moins d’attention. Une autre tendance générale qui mérite discussion est le fait que les résultats peuvent être facilement influencé par une petite quantité de textes mentionnant un sujet précis. En arabe, des articles sur un forum sur la sexualité ou sur Michel Foucault ont eu un impact disproportionné sur les résultats, comme les articles sur Freddy Mercury en japonais. En anglais, on constate que quelques citations d’un livre dans une bibliographie suffissent pour mettre le mot « citoyenneté » dans nos résultats. Ceci peut-être vu comme une faiblesse de notre méthode de travail. Si jamais nous voulons faire des analyses similaires à l’avenir, il serait peut-être utile de faire un corpus beaucoup plus grand ou bien de créer un système pour donner moins de poids aux mot répétés dans un petit nombre d’articles. Le japonais montre aussi que des synonymes du même mot peut avoir des associations très différentes, donc il faudra sûrement plus prendre en compte les synonymes dans les analyses textuelles à l’avenir.
En dépit de certaines faiblesses de nos données, ceci a été une exercice utile pour voir comment le traitement automatique des langues peut être appliqué à l’analyse des opinions sur internet. Déjà, cela inspire beaucoup de nouvelles idées sur la façon dont nous pourrions identifier les réactions aux nouveaux produits ou aux actualités sur les médias sociaux. À voir pendant le semestre prochain !
Mot de la fin et remerciements
Kristina :
Au cour de ce projet j’ai appris un nouveau langage de programmation, le shell, à incorporer le langage HTML dans un script, à utiliser la commande egrep pour rechercher des motifs, à manipuler des corpus multilingues et quelques logiciels comme iTrameur.
Je tiens à remercier Serge Fleury et Michel Daube, pour avoir assuré le bon déroulement de notre projet et nous avoir aide tout au long du semestre. Je remercie également mes amis Camille et Emmett de m’avoir aidée à créer la liste d’URL et les fichiers concaténés.
Emmett :
J'aimerais remercier mes deux professeurs pour leurs fortes capacités pédagogiques, ainsi que pour l'aide qu'ils ont apportée lorsque j'ai rencontré des problèmes sur mon script, souvent à la dernière minute. Ce projet a été une excellente introduction au TAL qui m'a fait découvrir la façon dont je pourrais appliquer mes études à des sujets d'intérêt comme la politique dans l'avenir.
Camille :
Ce projet m’a permis de m’entraîner davantage à travailler en équipe, ce qui est une bonne chose car j’ai relativement peu d’expérience en travail d’équipe et j’y suis normalement plutôt réticente. Je suis maintenant beaucoup plus à l’aise dans l’écriture de script bash, et j’aime presque ça! (je préfère encore le python, désolée 😁) J’ai également pu manipuler des logiciels d’analyse textométrique, ce que fait une première pour moi.
J’ai appris beaucoup de chose concernant le sujet lui même, à savoir la sexualité. Par exemple, je ne savais pas qu’il existait une catégorie « demisexuel »… Je remercie Serge Fleury et Jean-Michel Daube pour leur présence et leur aide tout au long du projet, et pour les commentaires motivants sur notre blog de travail. Je remercie aussi mes partenaires de projets Emmett et Kristina.
Thème remanié par YUDENKOVA Kristina, STRICKLAND Emmett et REY Camille © 2019
A partir de OS Templates