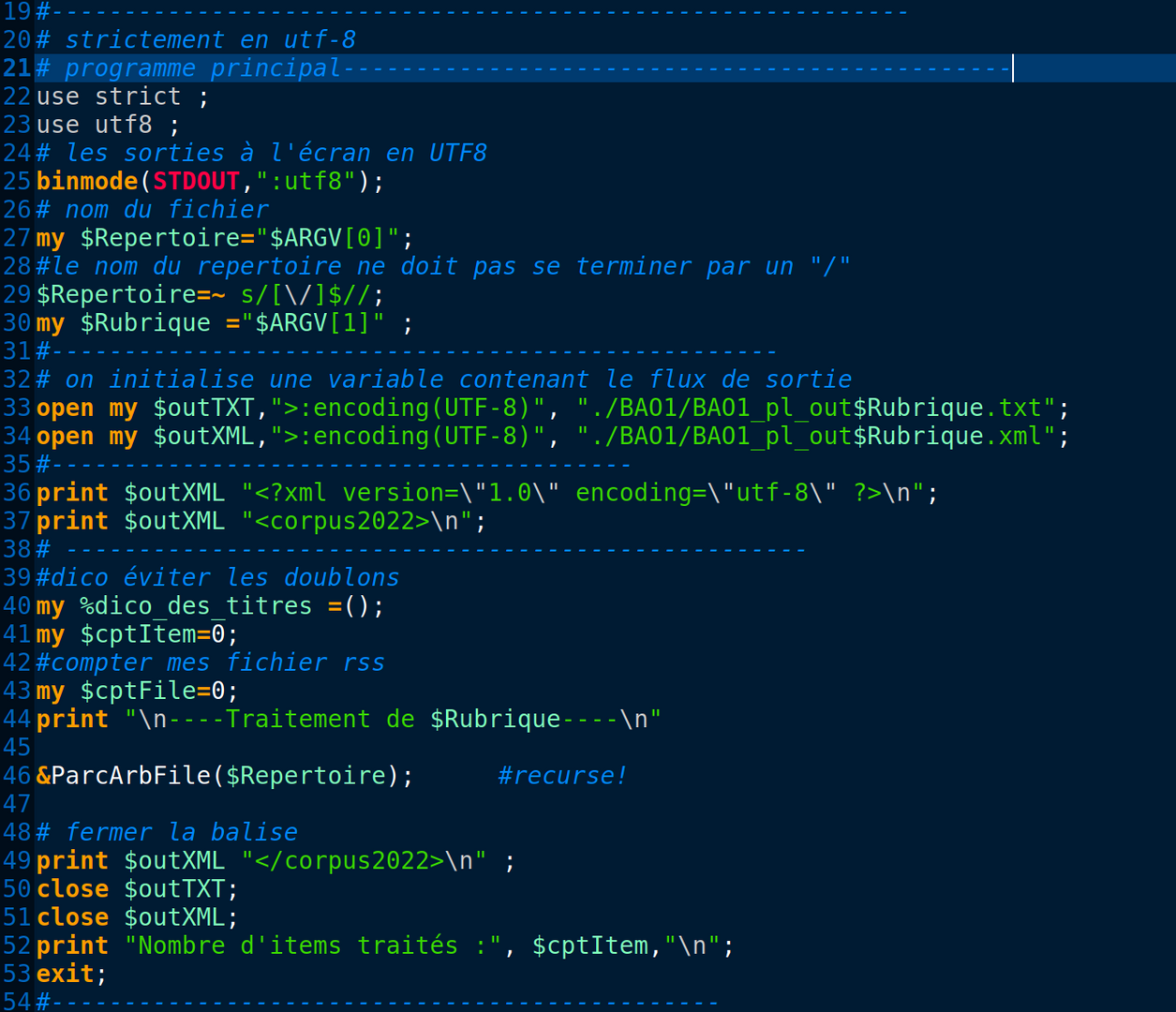
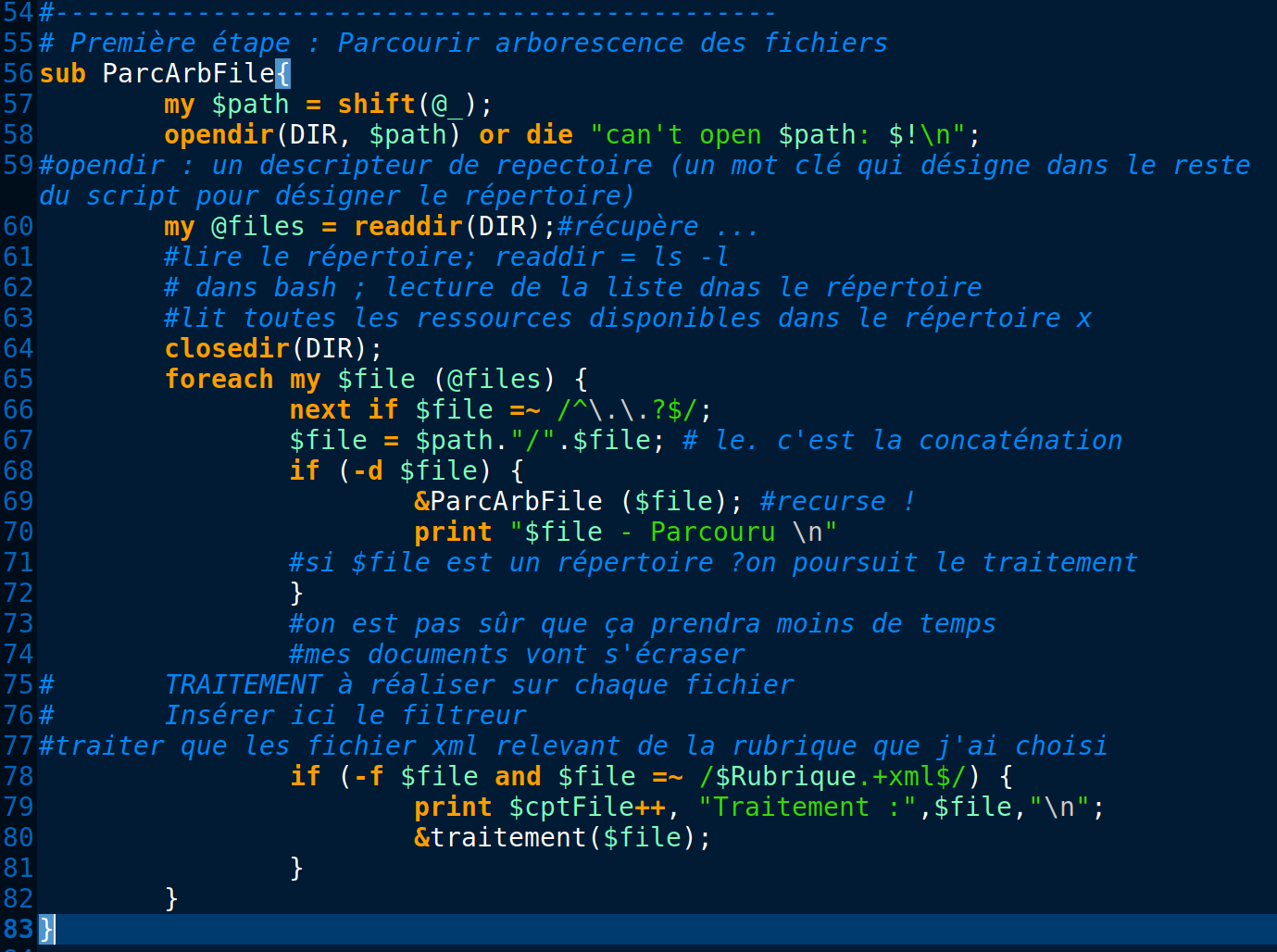
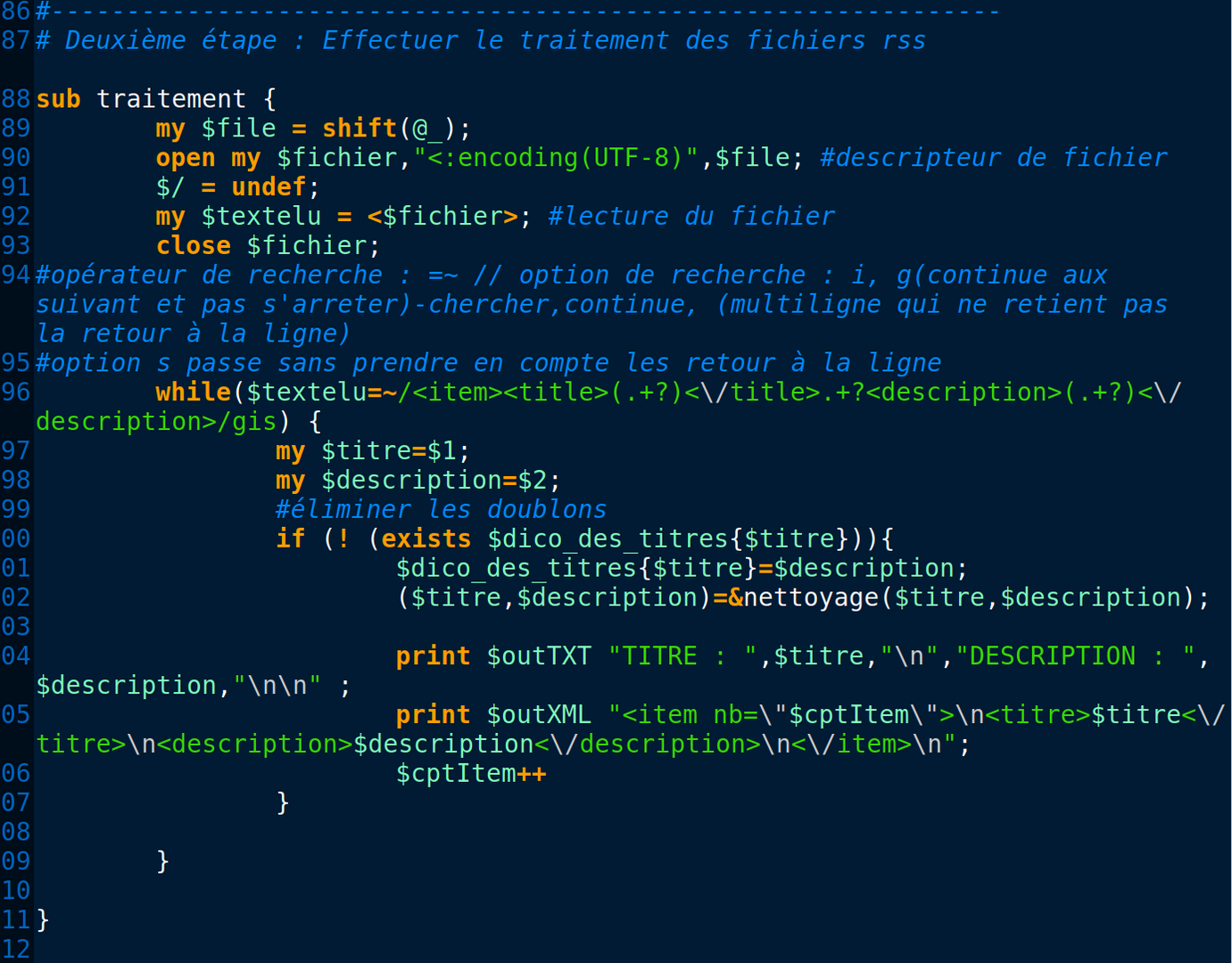
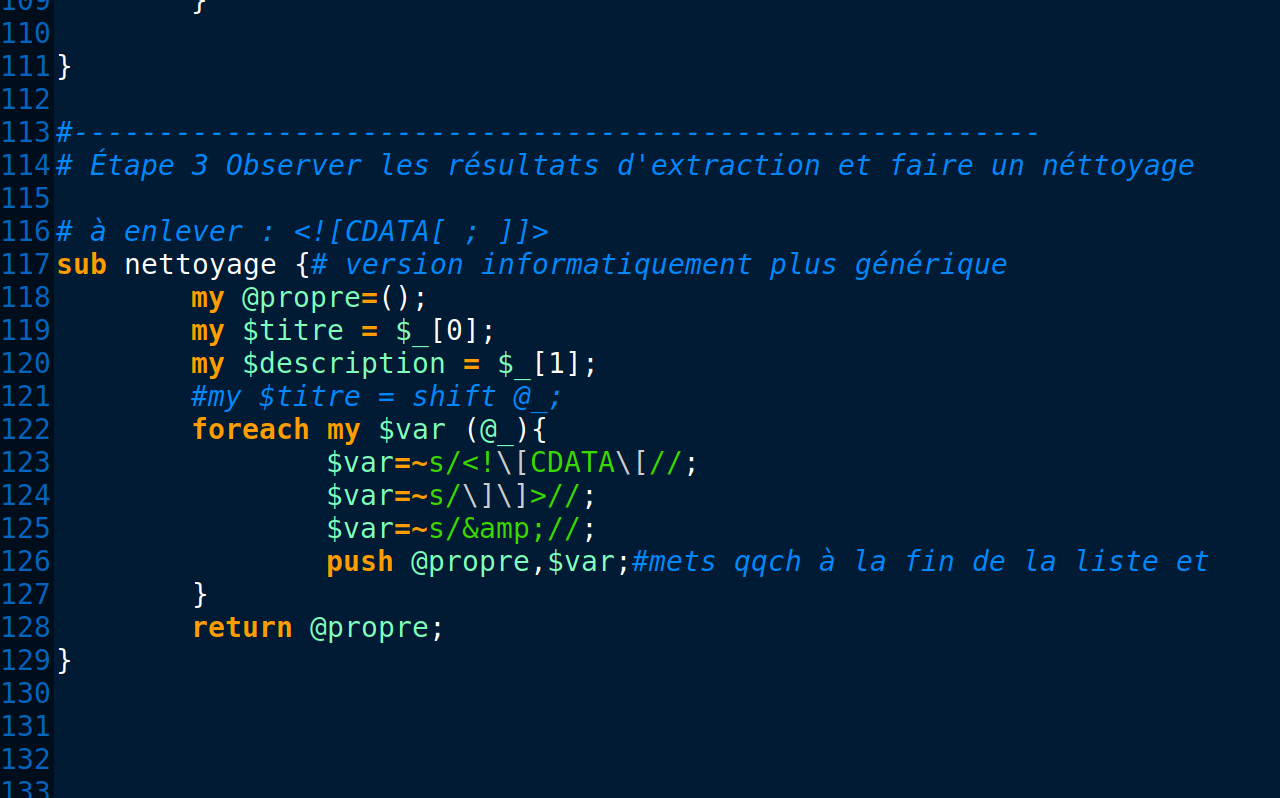
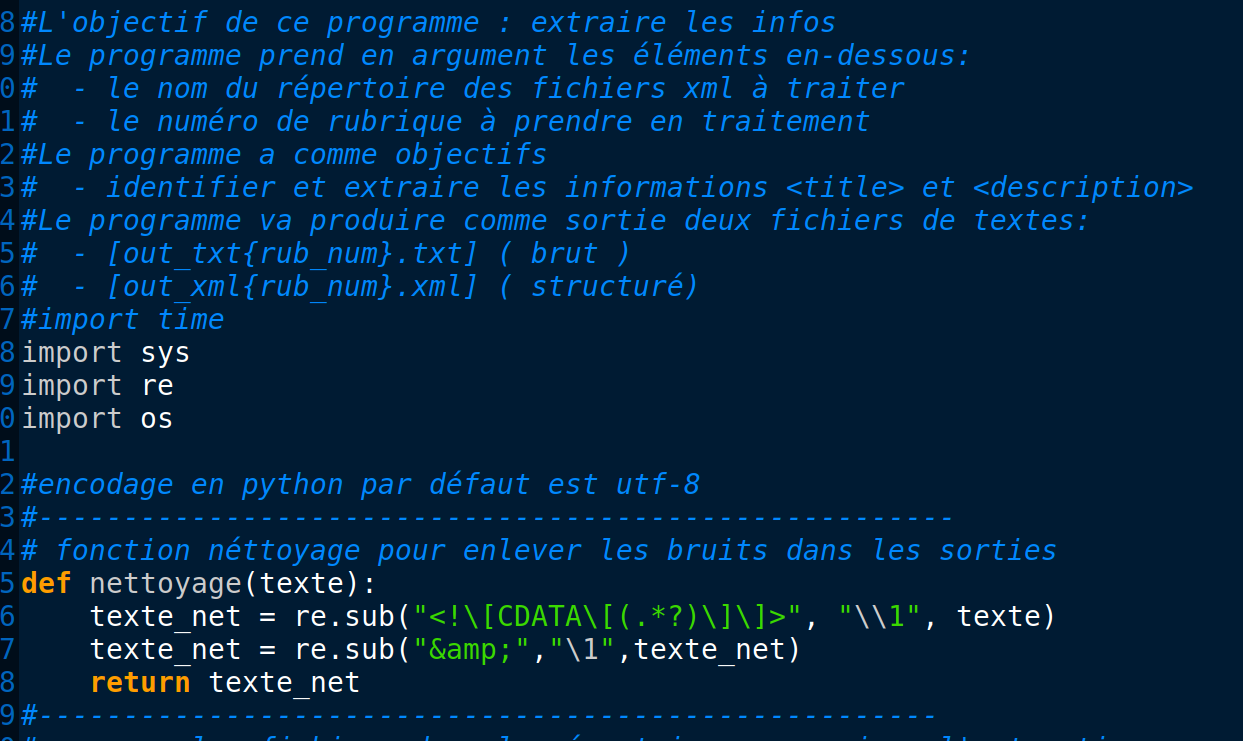
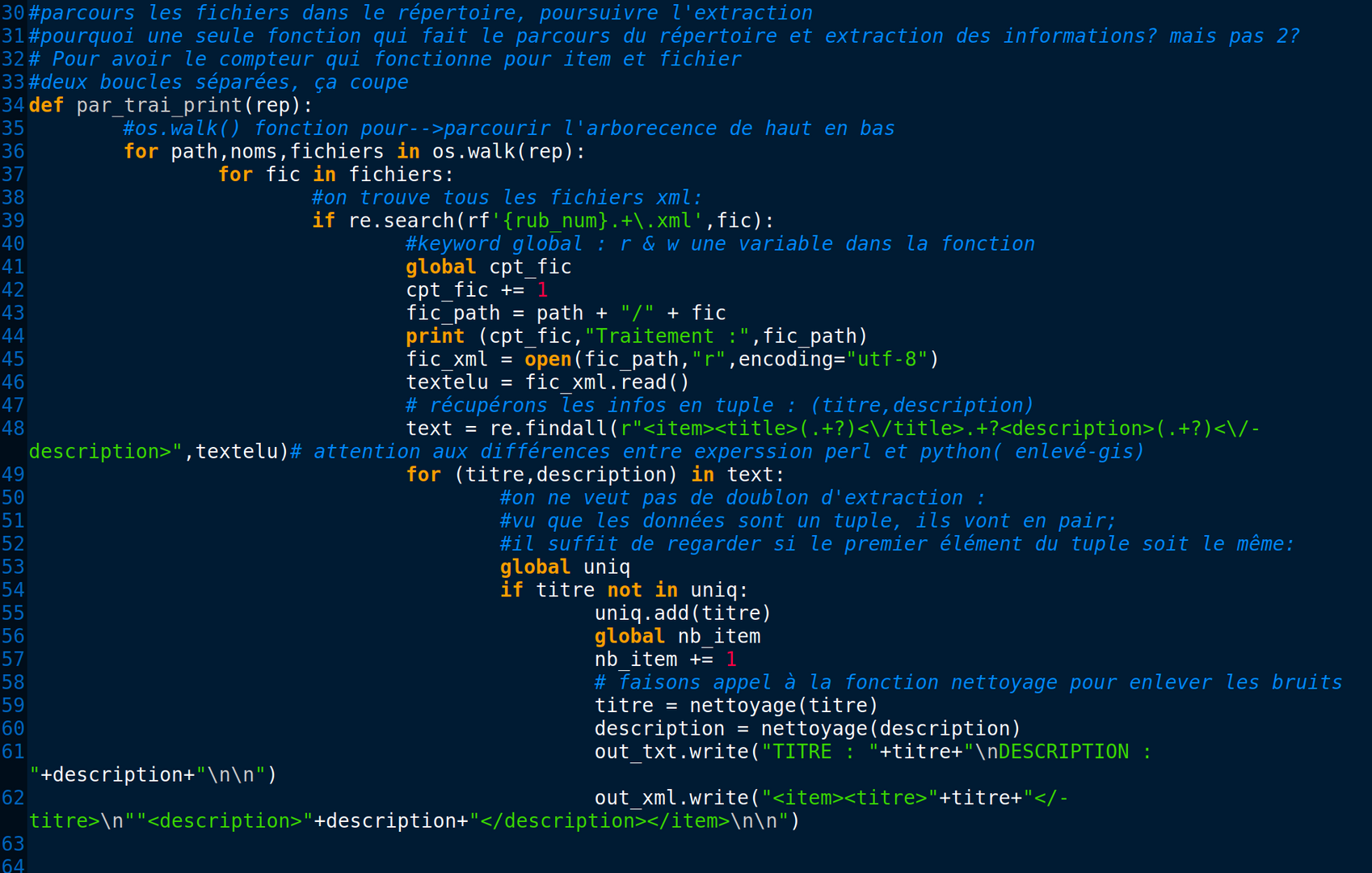
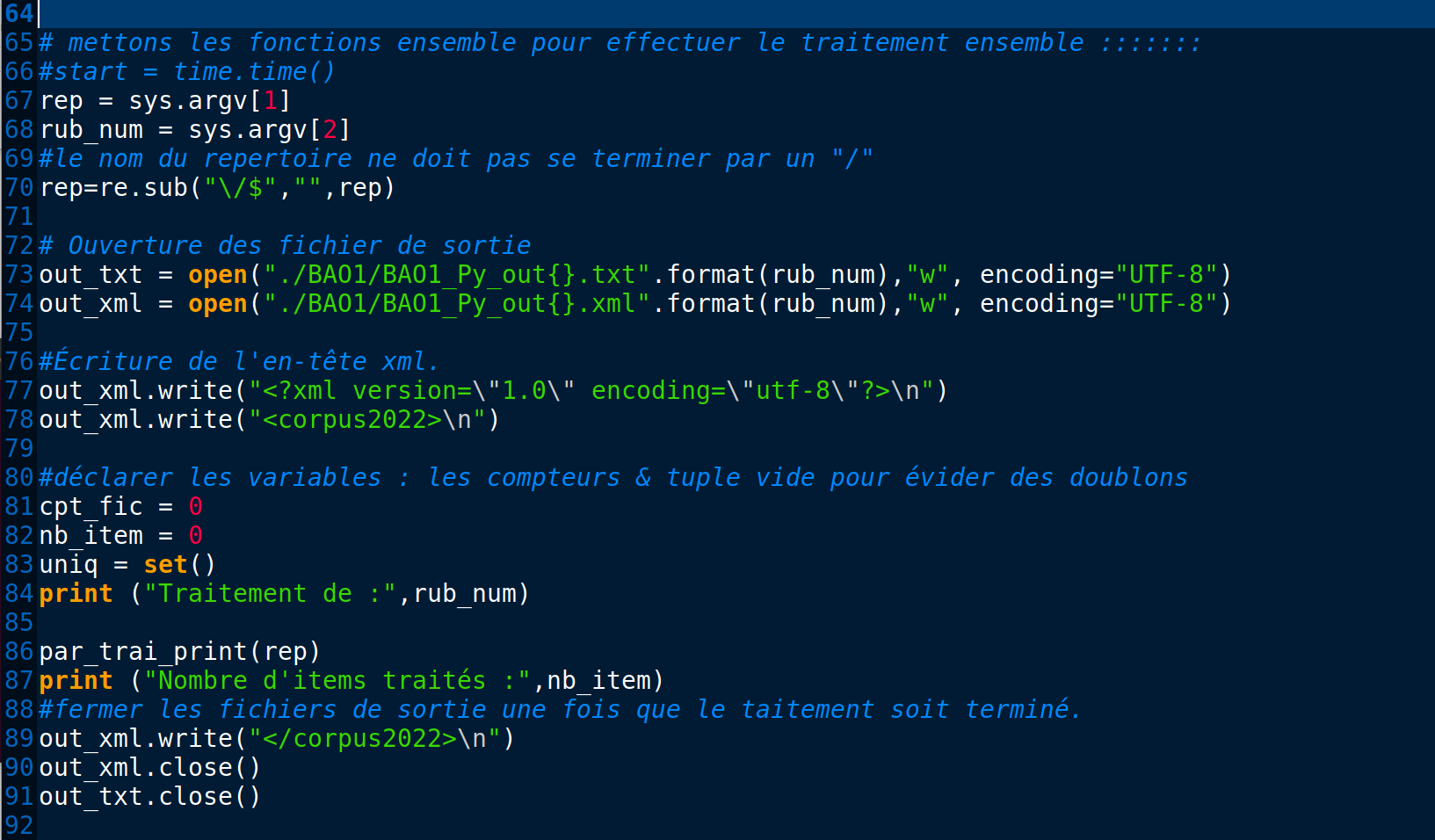
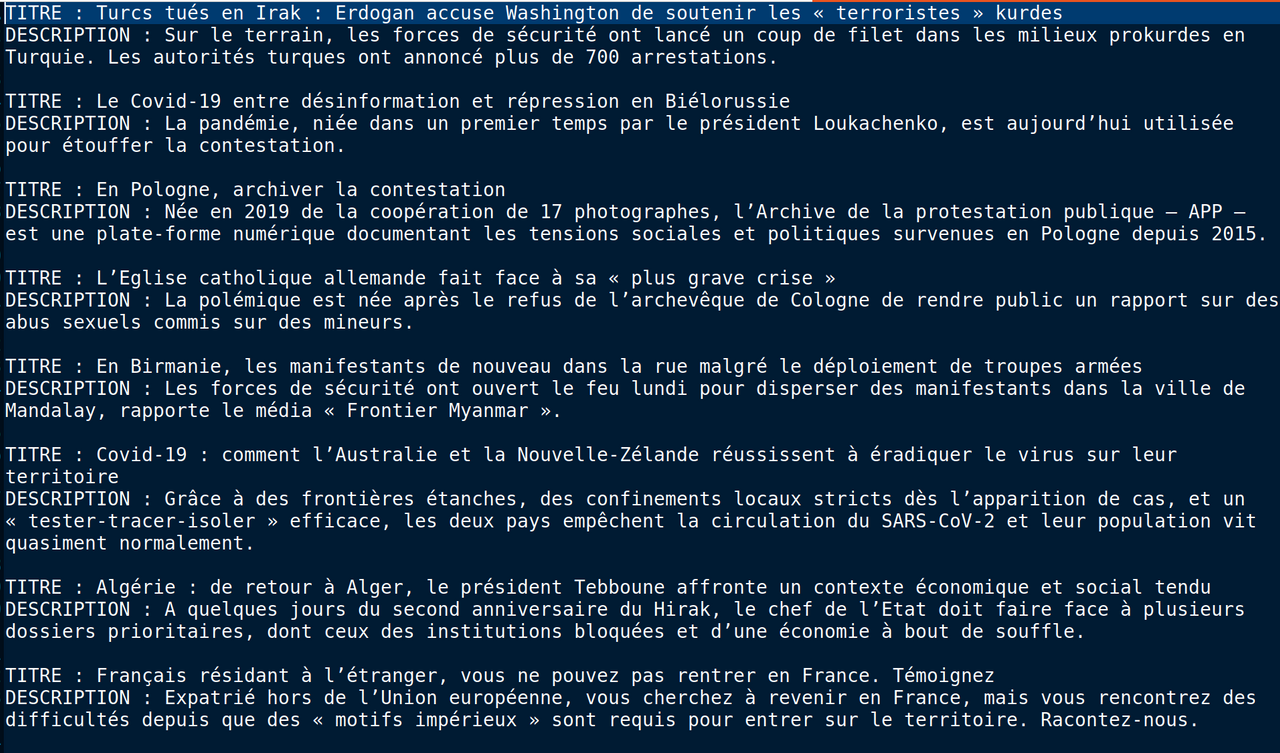
À l'aide de la boîte à outil 1 , nous avons comme objectif de parcourir toute l'arborescence et d'extraire les titres et les description des article issus du journal "Le Monde".
Ces articles viennent de 12 rubriques différentes, pour réaliser ce projet, nous devons choisir un nombre de rubrique pour effectuer nos traitement.
Les trois rubriques suivantes consistent notre corpus à traiter : 3210(international ); 3234 (économie); 3246(culture).
Ligne de commande pour lancer le programme:
perl Bao1.pl ./2021 3210(3234/3246)
(On se situe dans le répertoire BAO)
Le programme prend en argument les éléments en-dessous:
- le nom du répertoire des fichiers xml à traiter (./2021)
- le numéro de rubrique à prendre en traitement
Le programme a comme objectifs
- identifier et extraire les informations <title> et <description>
Le programme va produire comme sortie deux fichiers de textes:
- [outTXT$Rubrique.txt]
- [outXML$Rubrique.xml]
Ligne de commande pour lancer le programme:
perl Bao1.pl ./2021 3210
(On se situe dans le répertoire BAO)
En python nous pouvons aussi faire comme en PERL , soit utiliser des expressions régulières pour l'extraction des informations textuelles.
Il suffit d'importer le module "re".
Ce qui est différent que le programme en PERL, c'est qu'au lieu de séparer chaque étape du traitement (d'abord parcourir les fils RSS ensuite extraire les informations) de faire une grande fonction qui fait en même temps le parcours de l'arborescence et l'extraction des informations.
La raison pour laquelle que j'ai préféré de rassembler les deux fonctions et en faire une grande c'est pour m'assurer que le compteur des items et des fichiers matche bien. Car si je les sépare en deux boucles le compteur sera perturbé et ne marcherai pas comme il faut.
created with
Website Builder Software .