À l'aide de la boîte à outil 2 , nous avons comme objectif d'effectuer du Pos-Tagging automatique à l'aide des outils d’étiquetage ( Pour ce projet, nous allons utiliser TreeTgger et UDpipe) .
Deux annotations seront réalisées :
- Annotation en morphosyntaxe (TreeTagger)
- Annotation en dépendances(UDpipe)
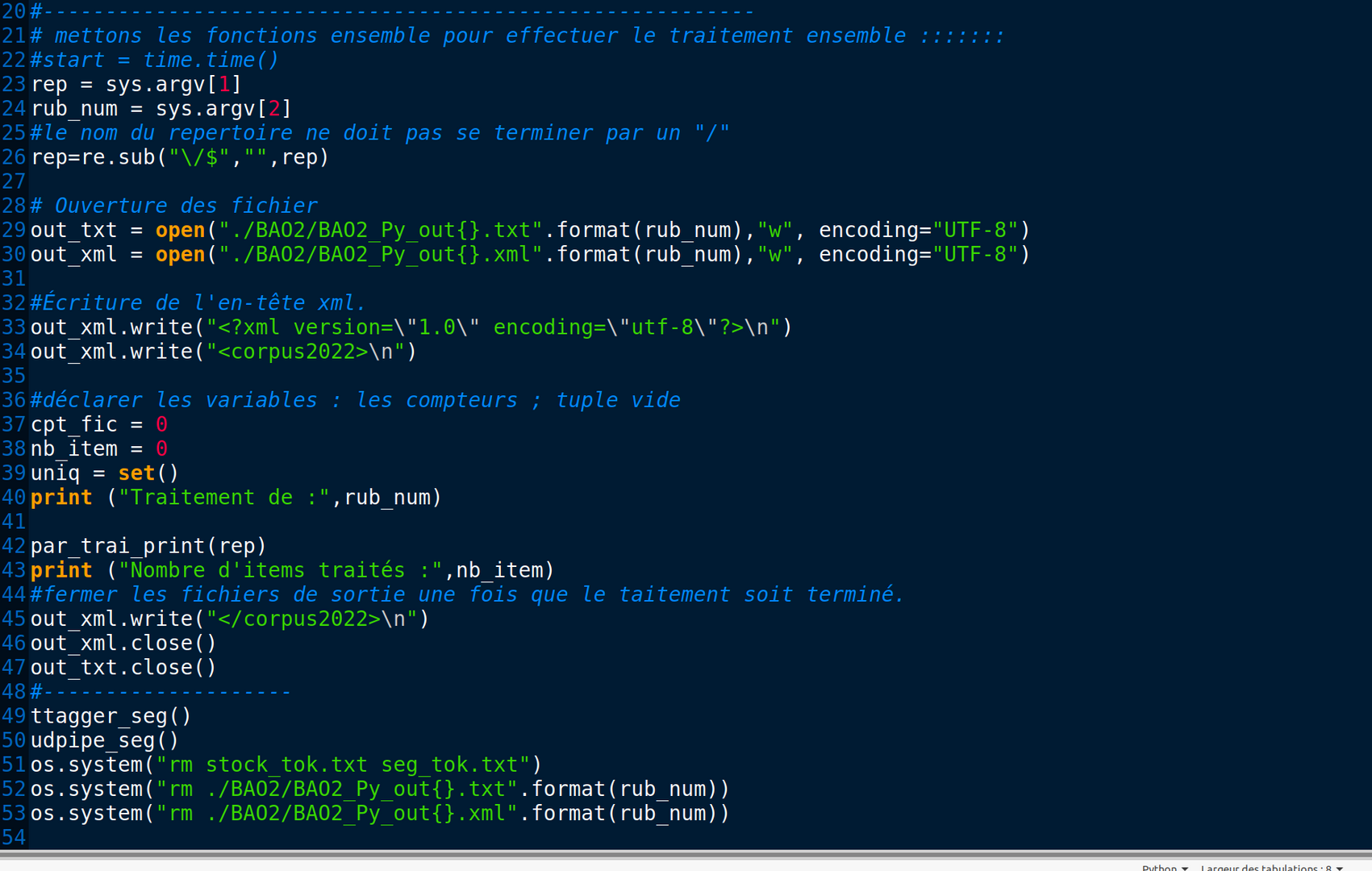
Dans cette boîte à outils, perl occupe une proportion importante, car nous avons à notre disposition deux scripts fournis par Monsieur Fleury pour la transformation des fichiers annotés en XML.
Pour avoir des résultats plus agréables visuellement, ils sont modifiés pour que les fichiers contiennent que des informations qui nous sont utiles et que la représentation soit en harmonie.
Ligne de commande pour lancer le programme:
perl Bao2.pl ./2021 3210(3234/3246)
(On se situe dans le répertoire BAO)
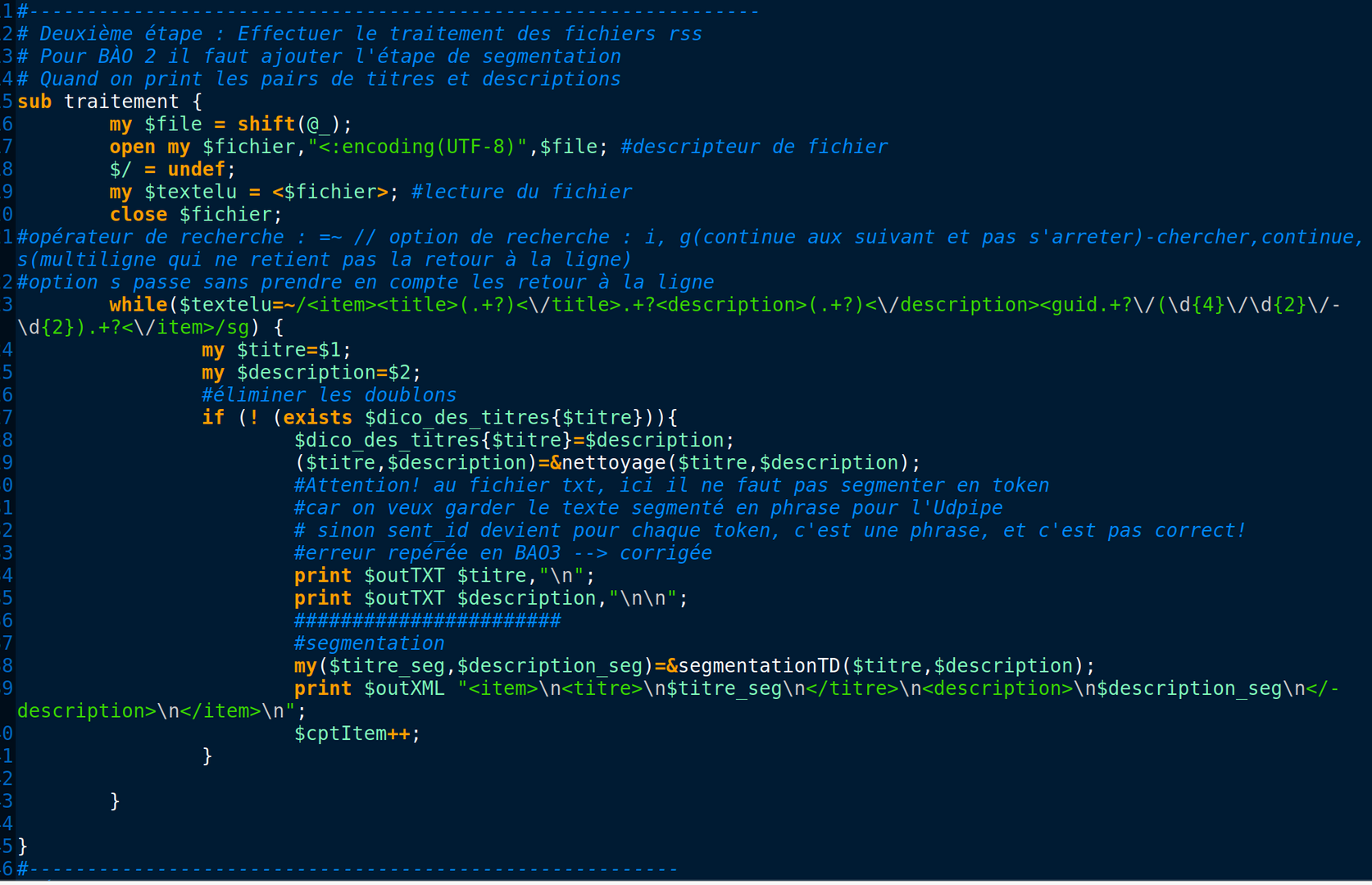
Par rapport au programme de la BÀO1, 3 nouvelles fonctions sont intégrées pour effectuer le traitement d'annotation :
- Segmentation avec TreeTagger.
- Étiquetage avec TreeTagger.
- Étiquetage avec UDpipe.
Non seulement dans le programme principal il faut ajouter l'exécution des nouvelles fonctorialités, il faut aussi faire attention à ce qu'on doit modifier ou pas dans la fonction de traitement.
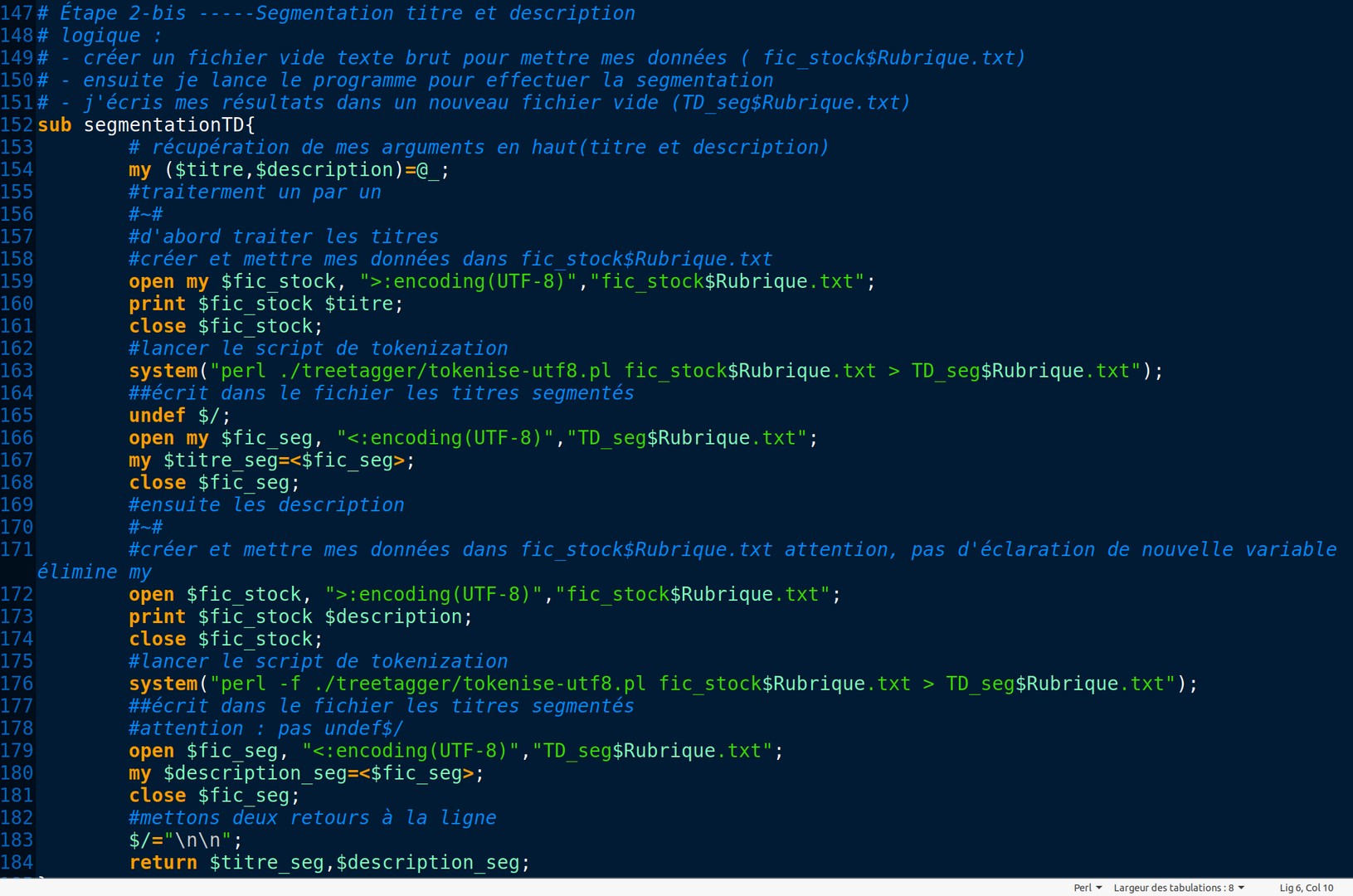
Quand on effectue a segmentation, il faut faire attention à ne pas modifier le fichier de sortie d'extraction des titres et description en Txt mais uniquement celui en XML.
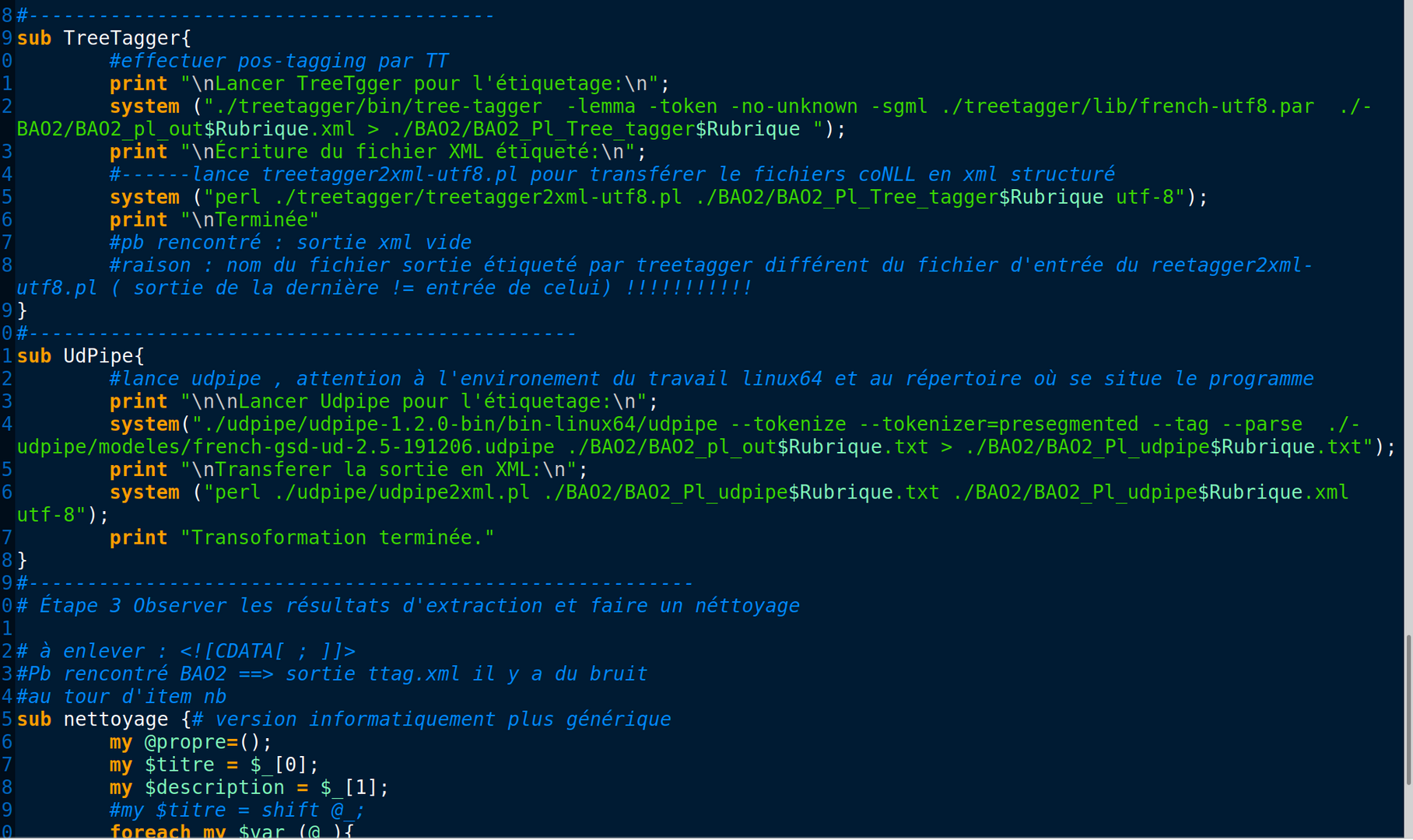
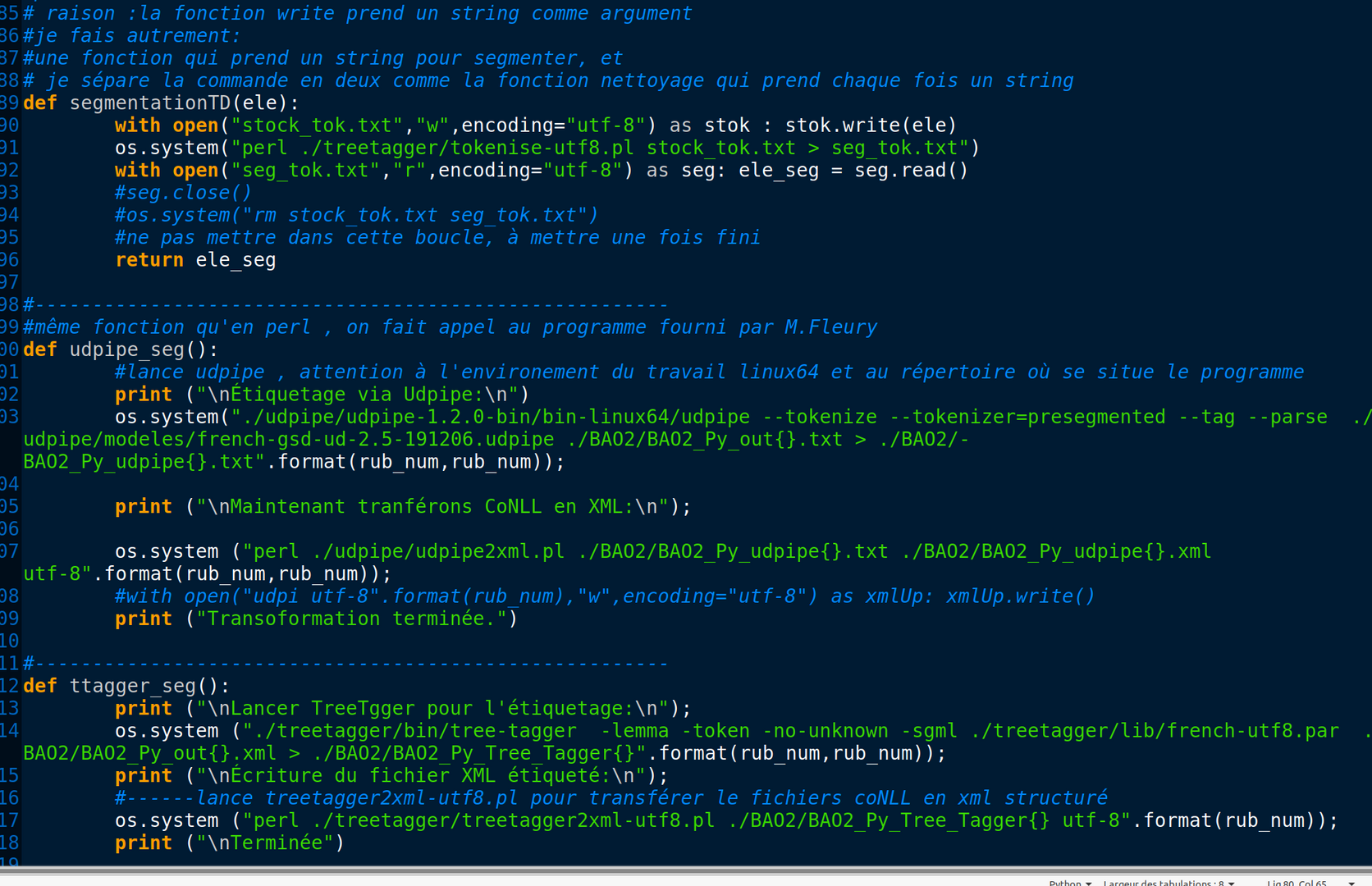
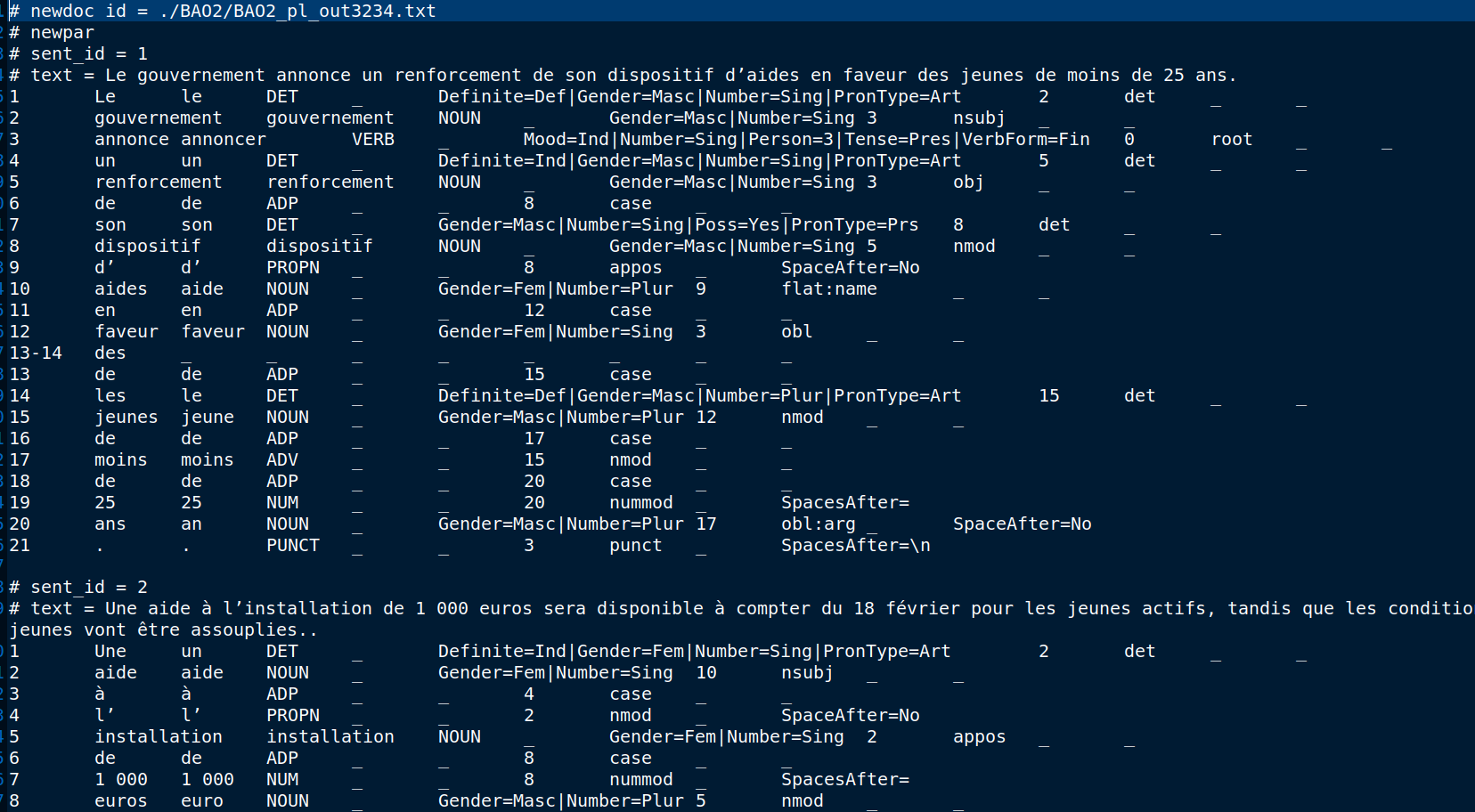
UDpipe prend des phrases en entier et annoter la relation de dépendance. Si nous mettons un fichier d'entrée où chaque token occupe une ligne, l'UDpipe va prendre ces phrases contenant qu'un mot et nous aurons pas la relations de dépendance de chaque phrase pour poursuivre le traitement en BÀO 3.
Ce script est intégré dans le programme de BÀO2.
Il se situe dans le répertoire d'Udpipe.
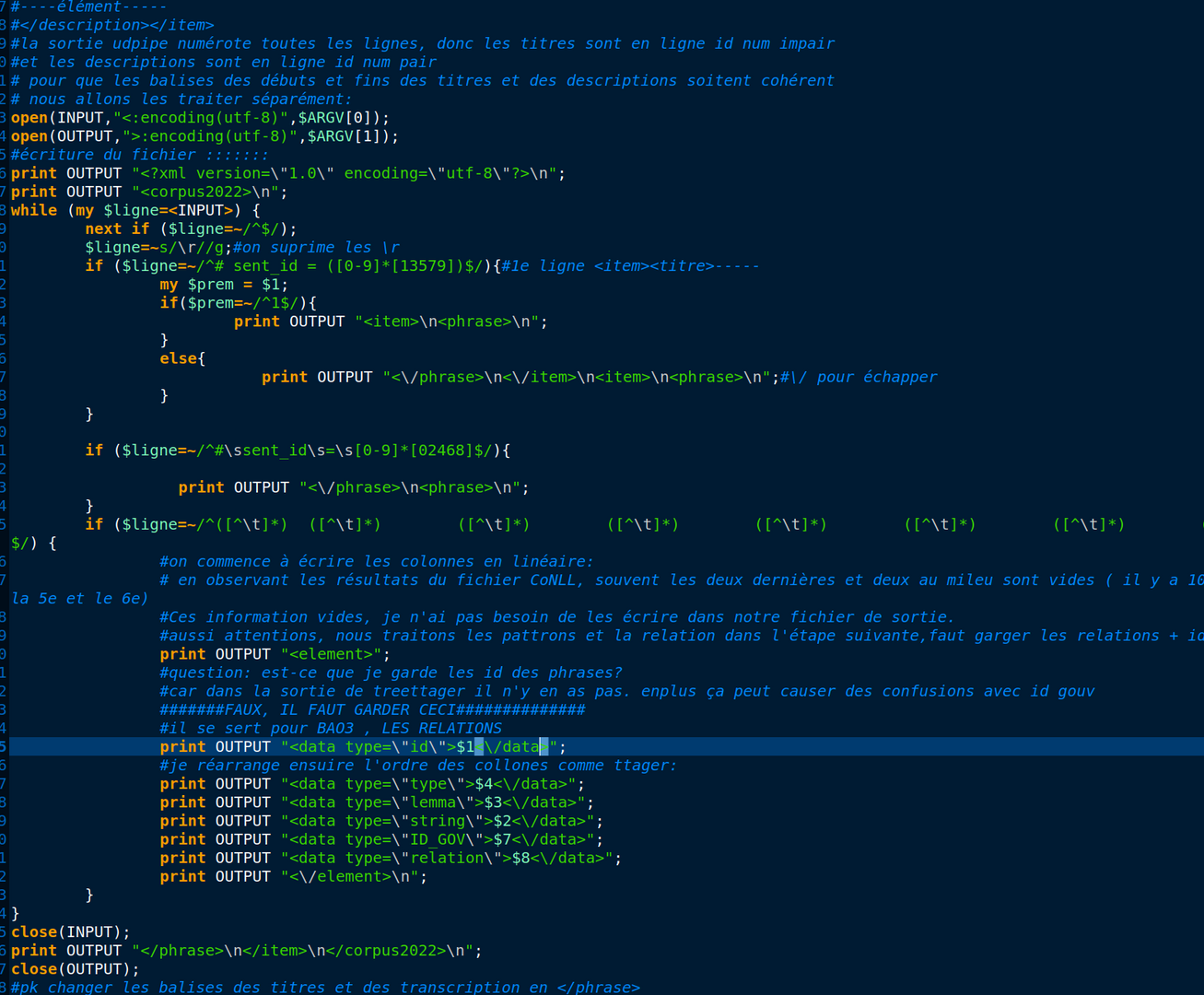
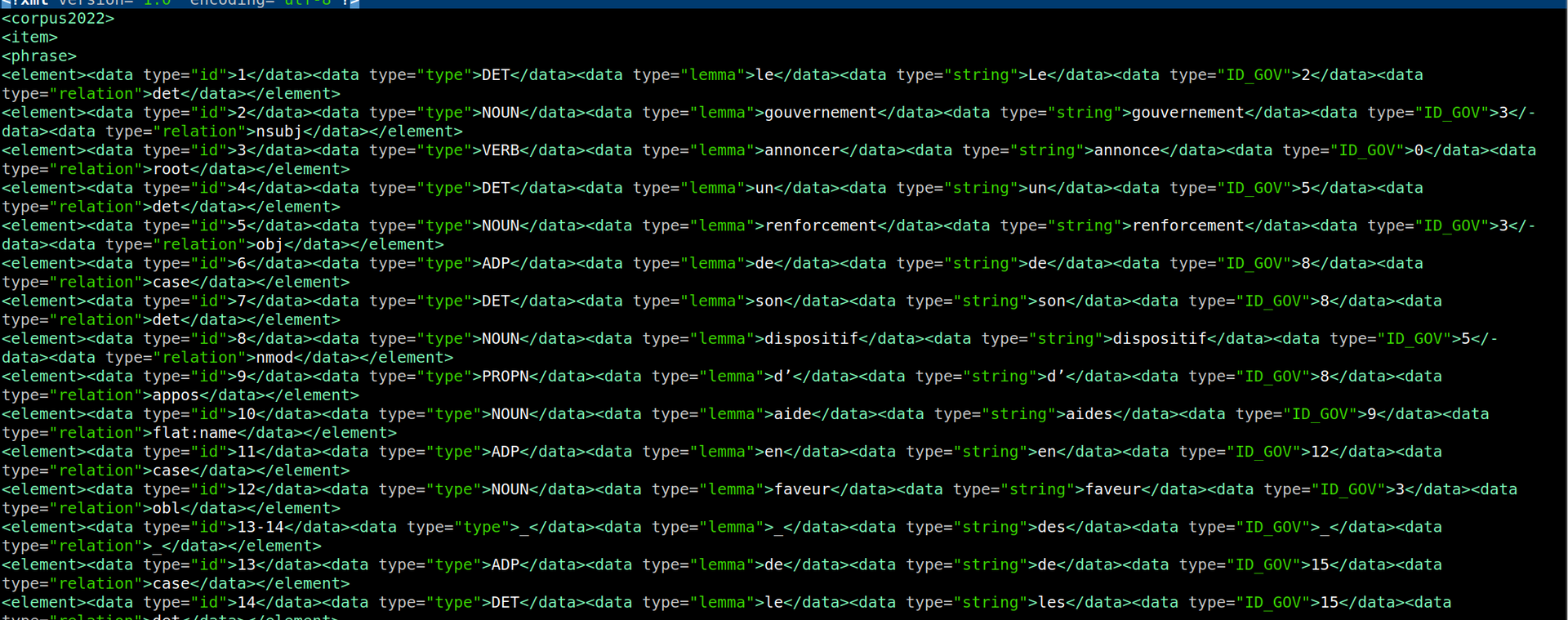
Pour bien faire la transformation, il faut d'abord bien observer les balises dans la sorties xml de TreeTagger et le fichier en Conll d'UDpipe.
Les lignes impaires sont des débuts des phrases, nous mettons que les balises ouvrantes.
Les lignes paires sont où les balises d'un item se termine et un autre commence, donc on doit écrire une balise fermante et une balise ouvrant.
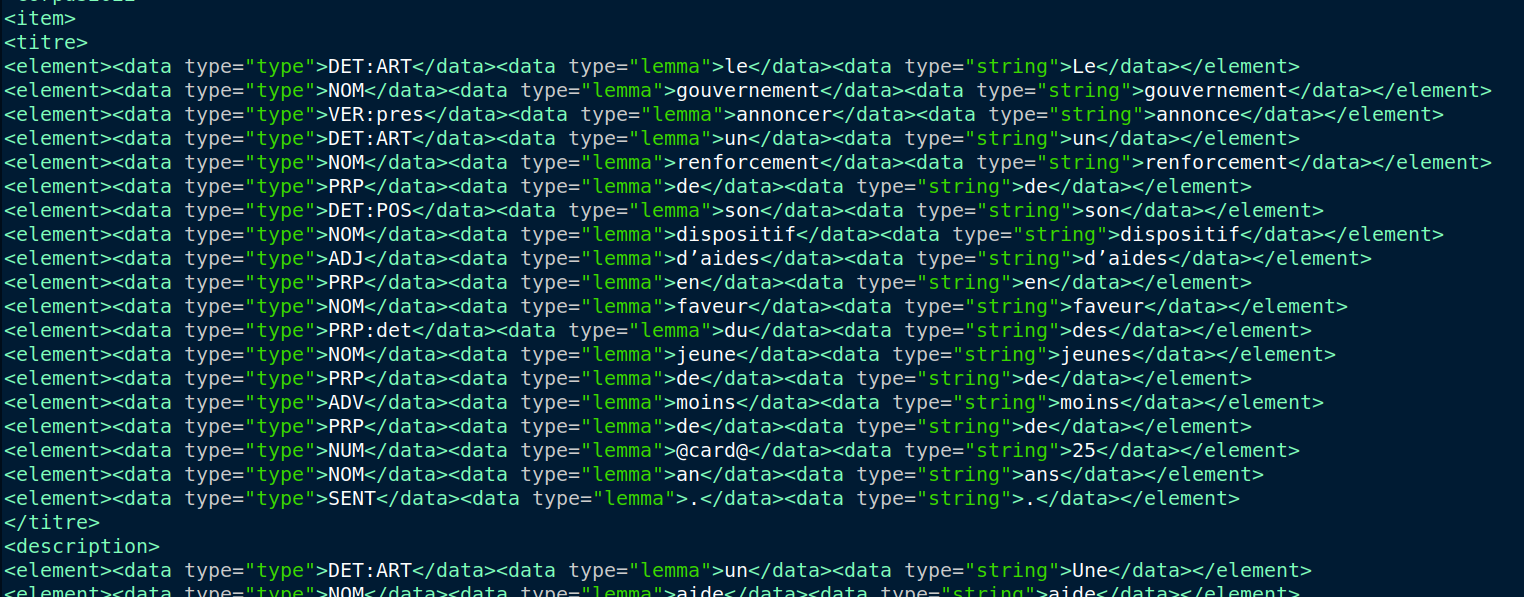
Nous parcourons chaque ligne, les conll ont en tous 10 colonnes et chaque information est séparés par une tabulation. Nous pouvons constater que dans plusieurs colonnes il n'y a pas d'informations, nous pouvons donc ne pas les écrire dans notre sortie, ainsi nous aurons un fichier de sortie en XML bien structuré et propre.
Attention ici dans chaque phrase, vaux mieux garder une forme de balises uniforme comme <data>, ceci va nous faciliter le traitement après pour les relations et la graphe.


created with
WYSIWYG Web Builder .