BAO3 "extraction de patrons & relations" :
Dans cette BÀO, nous allons rechercher et extraire de patrons Morphosyntaxiques sur les données étiquetées (les séquences NOM PREP NOM, NOM ADJ etc.) ou de relations de dépendances.
Pour cette BÀO, deux nouvelles propositions seront présentées, feuille de style XSLT pour générer notre fichier RSS, et les requêtes Xquery que nous allons lancer sur BaseX.
Cette partie et donc séparée en deux sous parties et un avant premier :
AVANT DE COMMENCER...

Question:
Les étiquettes TreeTagger et celles d'UDpipe porte de noms différents. Pour éviter de éventuelles confusion et simplifier notre traitement d'extraction, il est avantageux de unifier les deux sorties(TreeTagger et UDpipe)
La logique derrière est simple :
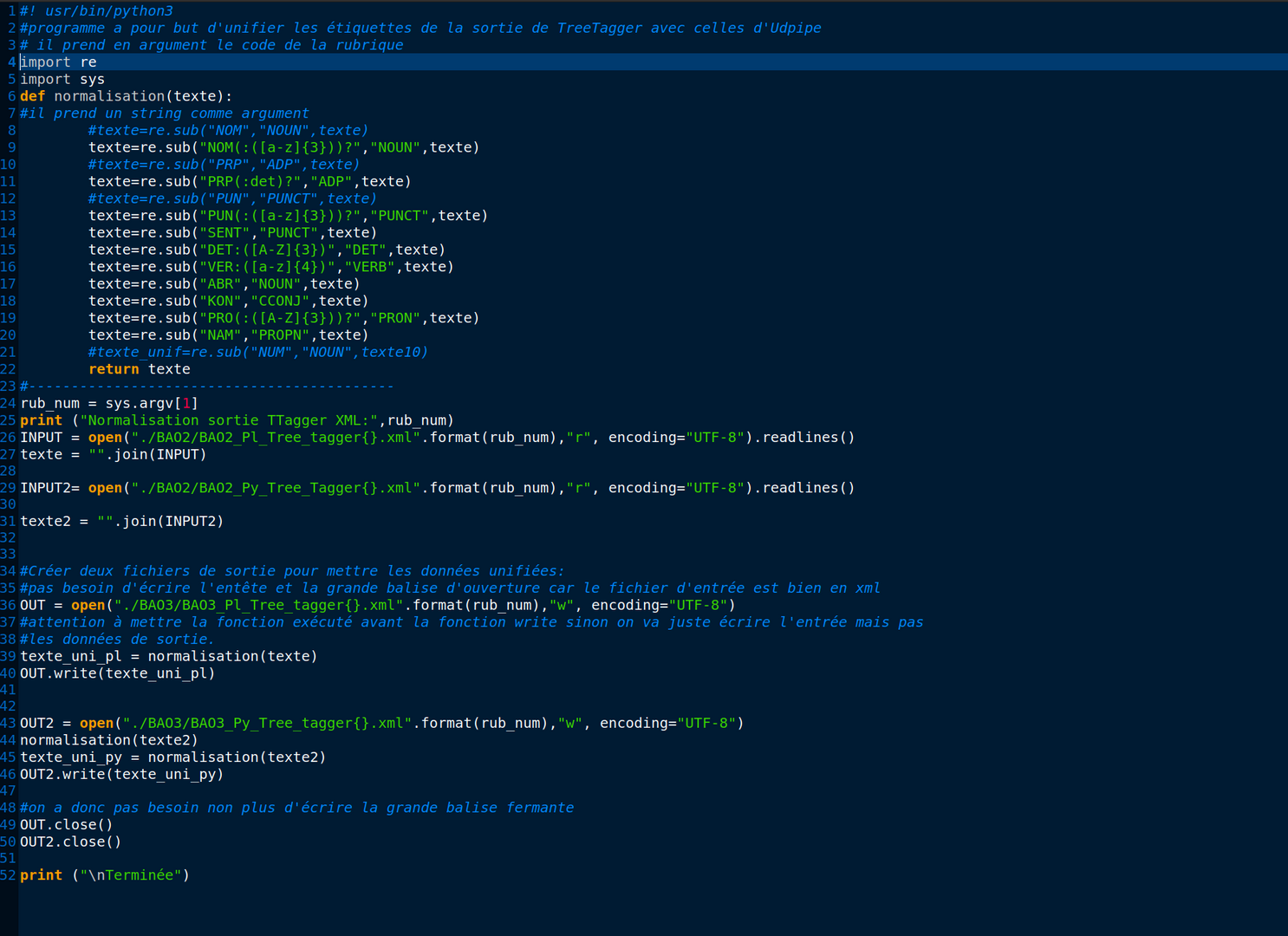
nous avons besoin de remplacer les
étiquettes de TreeTagger par celles d'UDpipe. (NOM --> NOUN)Nous avons décidé de faire cette étape à l'aide d'un script python:
Il ne prend qu'un argument : le numéro de la rubrique.
exemple de commande :
python3 uniformation.py 3210
BÀO 3 - <1> Extraction des patrons
Solutions :
- Perl
- Python
- Xslt(feuille de style)
- Xquery(BaseX)

Ligne de commande pour lancer le programme:
(On se situe dans le répertoire BAO)
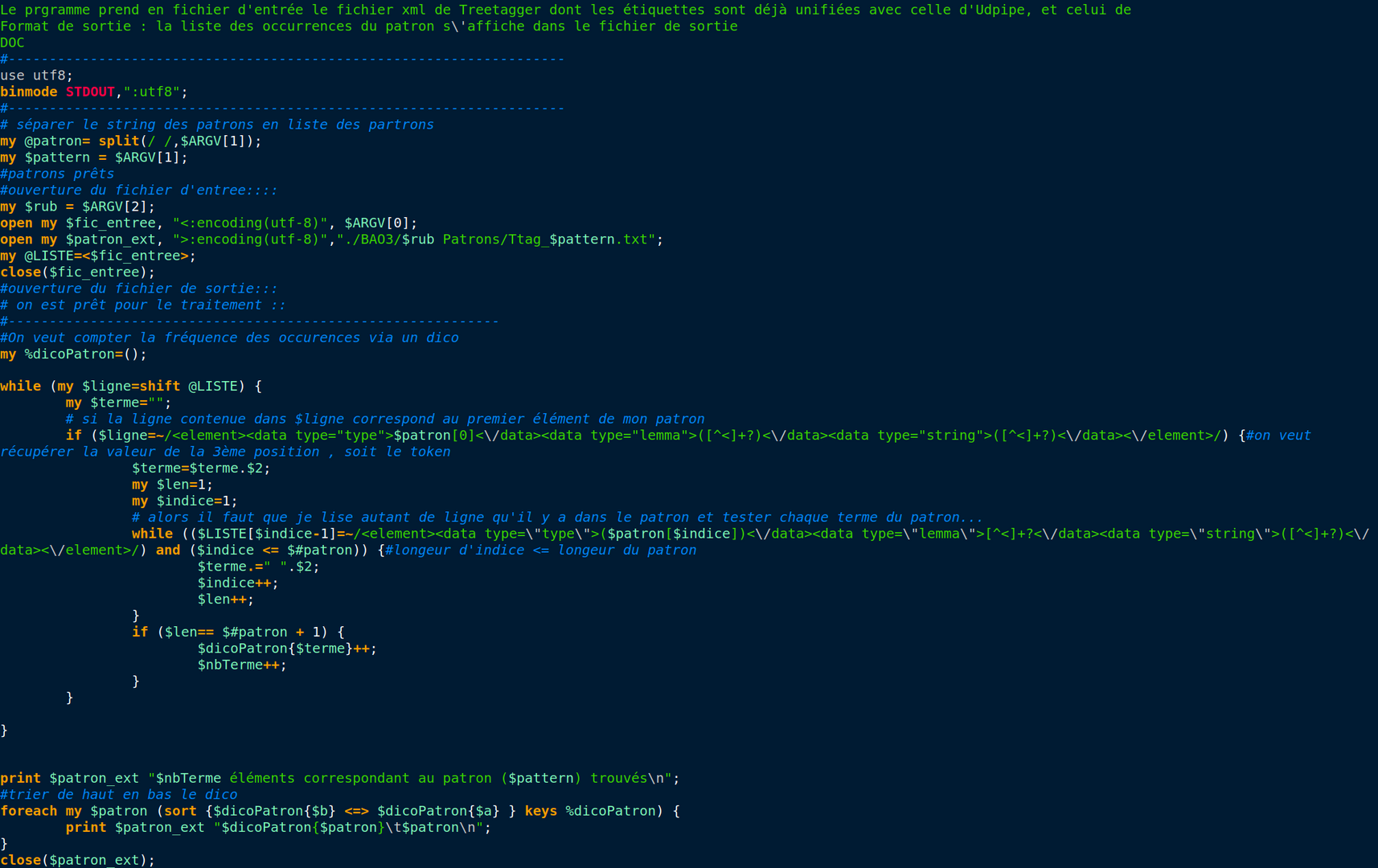
perl Bao3_patron_ttg.pl ./BAO3/BAO3_Pl_Tree_tagger3210.xml "NOUN ADP NOUN ADP" 3210
Le script prend comme arguments :
- le nom du fichier d'entrée
- le patrons
- le numéro de la rubrique
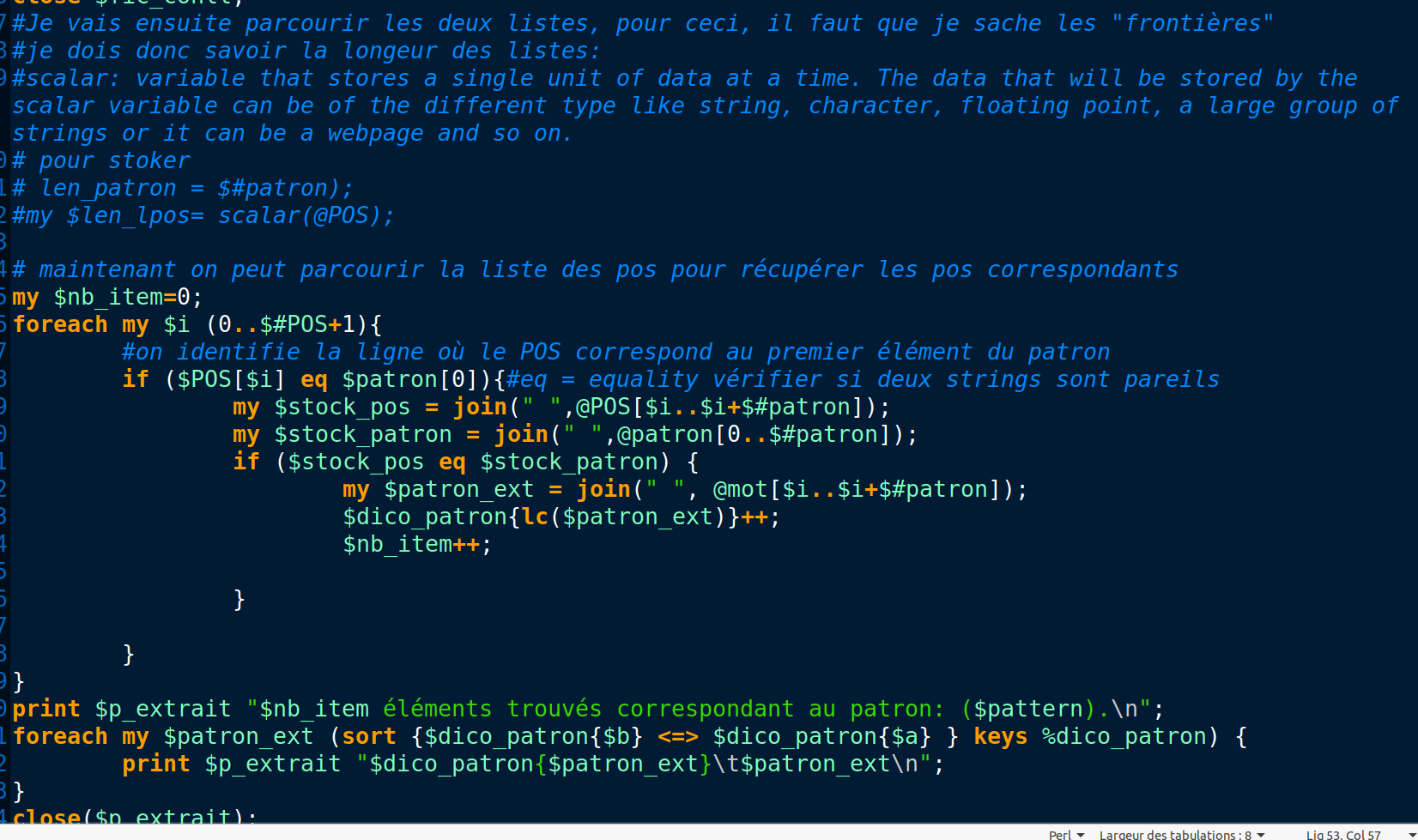
Attention ici quand on écrit l'expression régulière pour représenter la ligne d'élément, il faut savoir que seuls les segments entre les parenthèses seront compter en bas comme variable. Évitons de mettre des parenthèses partout et mettons juste sur les variables dont on a besoin.
Ligne de commande pour lancer le programme:
perl Bao3_patron_Up.pl ./BAO2/BAO2_Pl_udpipe3210.txt "NOUN ADP NOUN ADP" 3210
(On se situe dans le répertoire BAO)
le longueur d'un tableau égale à son index du dernier élément du tableau +1.
Le dictionnaire ici est créer pour compter la fréquence des groupes de tokens qui ont des POS correspondant à notre patron.
Précision :
Nous devons extraire 4 patrons proposés dans le programme et 2 de notre choix. Les patrons de notre chiox ne peuvent pas avoir moins de 3 segments.
Les patrons à extraire sont les suivant:
- NOM PREP NOM PREP
-NOM ADJ
-ADJ NOM
- VERB DET NOM
-NOM PREP VERB
-VERB PREP VERB
Ligne de commande pour lancer le programme:
python3 BAO3_Patron_Buffer.py 3210 ./BAO3/BAO3_Py_Tree_tagger3210.xml NOUN ADP NOUN ADP
(On se situe dans le répertoire BA0)
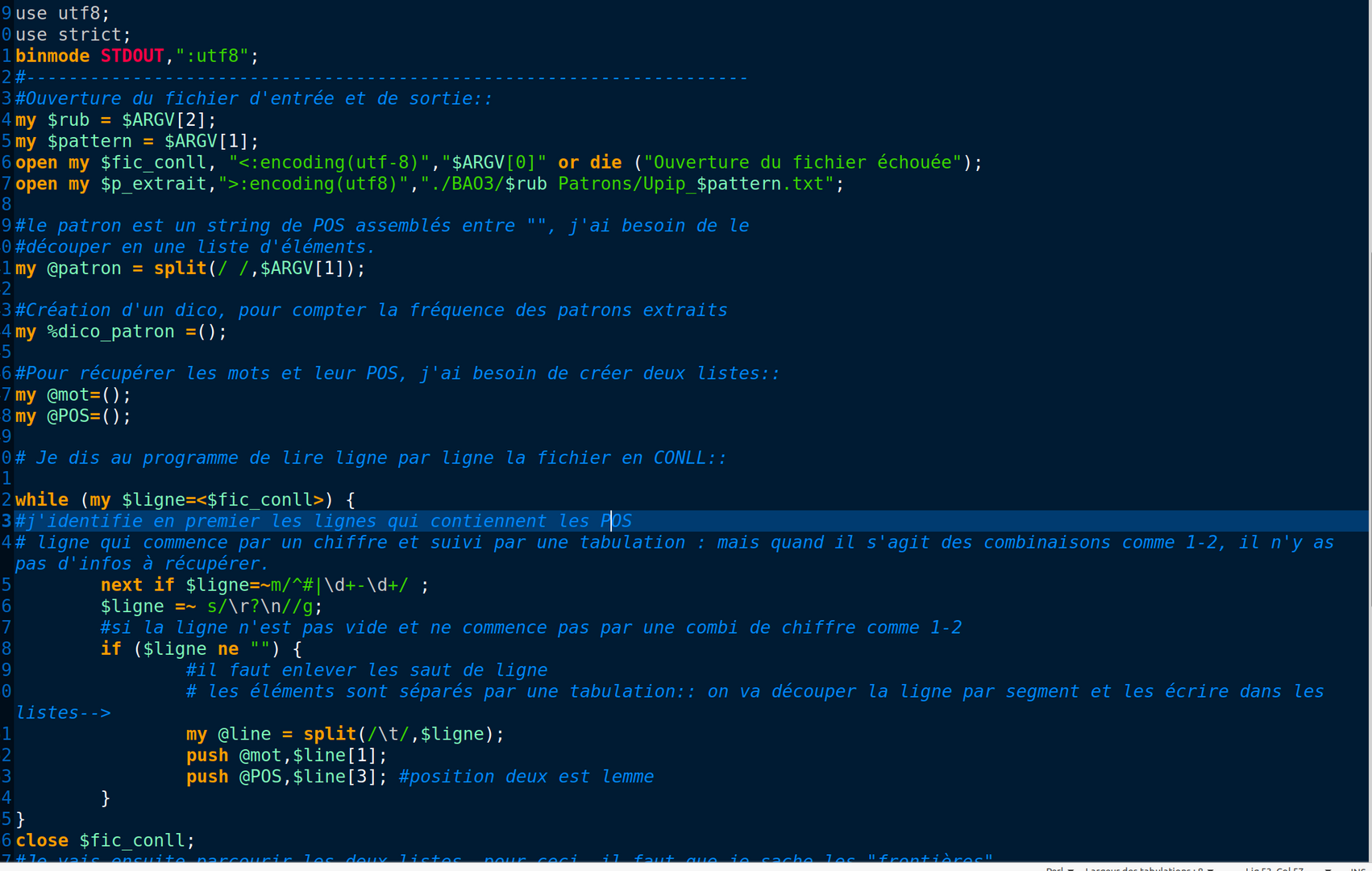
Deux choses importantes à faire attention dans ce scipt:
- quand on utilise les expression régulières pour identifier les lignes contenants des patrons, il faut éviter les lignes "vide". Souvent quand un token est en effet deux mots rassemblés ils sont précis au dessous, donc il faut les éviter.
- en terme de la commande pour lancer le script il faut faire attentions de bien mettre de " " pour englober le patron en entier dans l'argument.
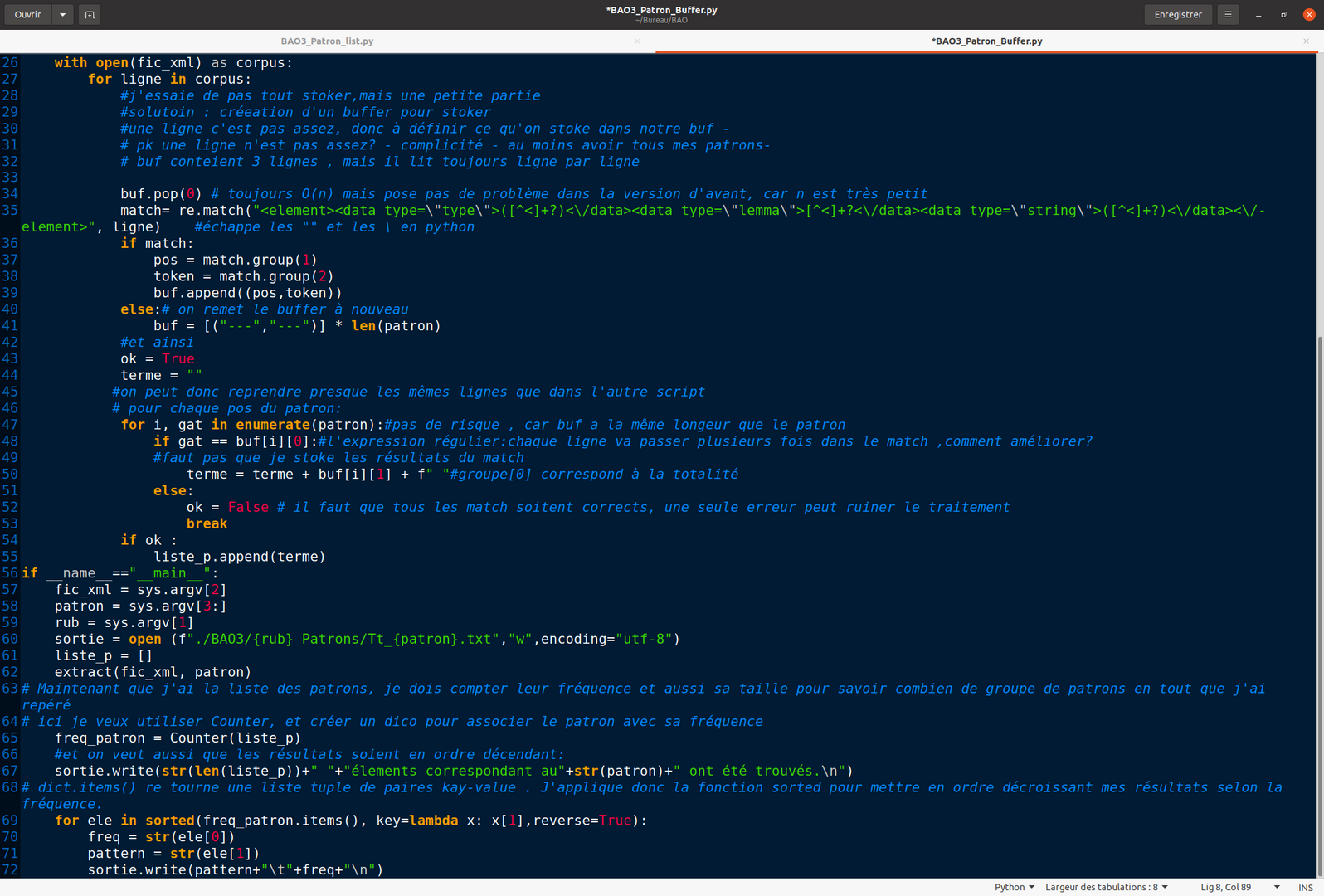
Ligne de commande pour lancer le programme:
python3 BAO3_Patron_Buffer.py 3210 ./BAO3/BAO3_Py_Tree_tagger3210.xml NOUN ADP NOUN ADP
Contrairement à ce qu'on a demander en haute, en lançant ce script nous n'avons pas besoin des mettre des " " au tours du patron en question. En important le module "sys", nous pouvons mettre le patron comme le dernier argument et de désigner qu'à partir de la 3 sème position sont tous compté comme idégale.
XSLT (feuille de style)
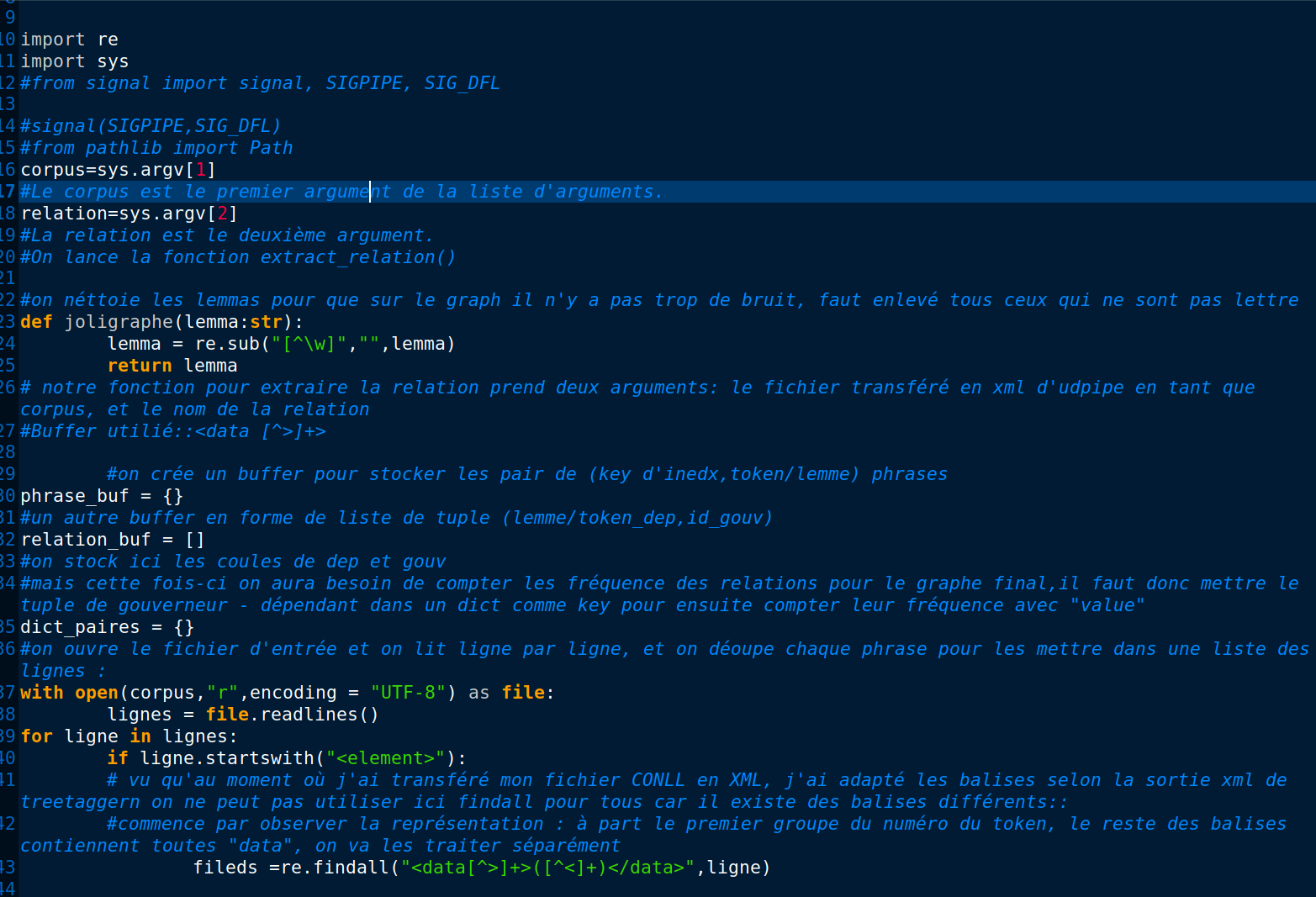
Nous prenons comme fichiers d'entrée la sortie normalisée de Treetagger et Udpipe CONLL en texte brut.
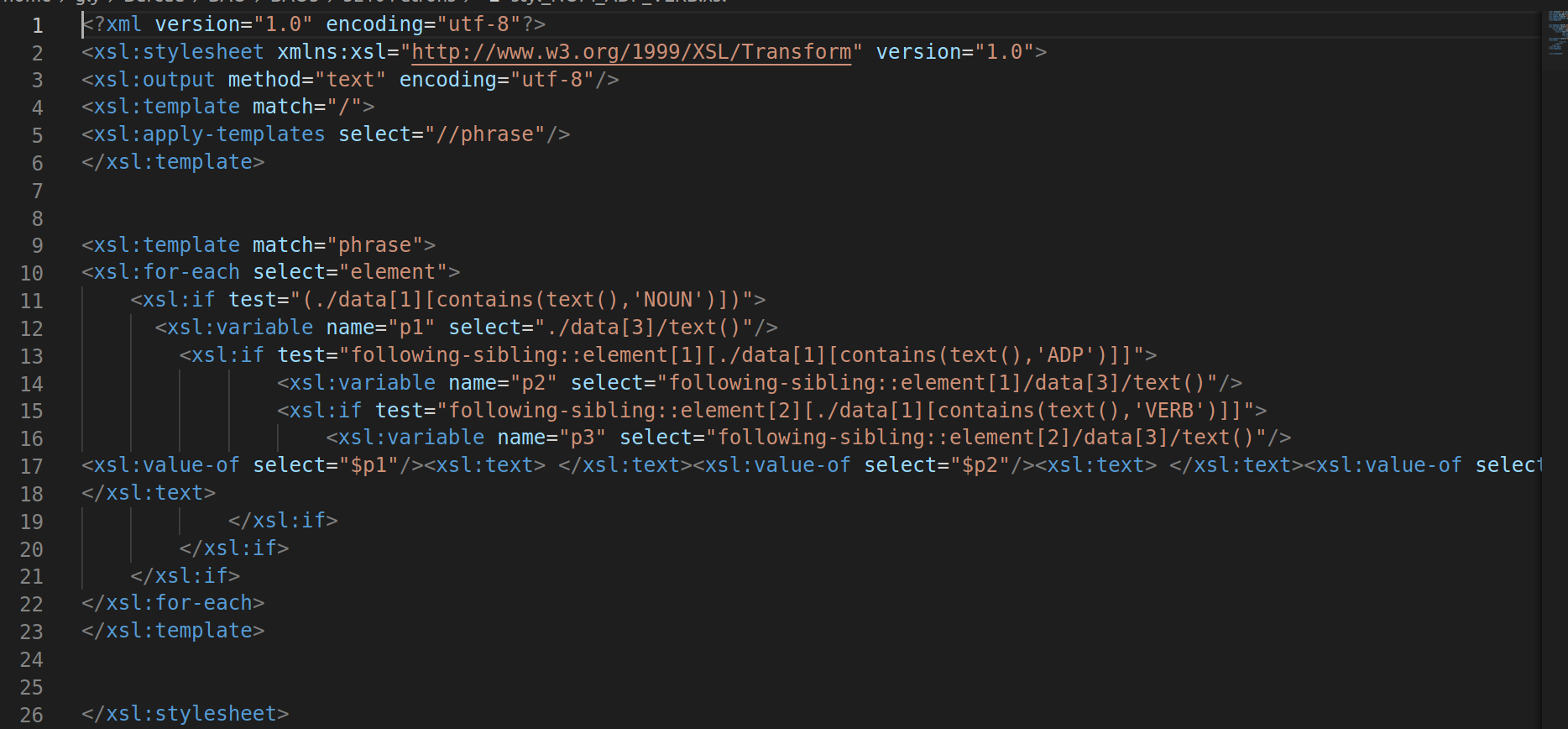
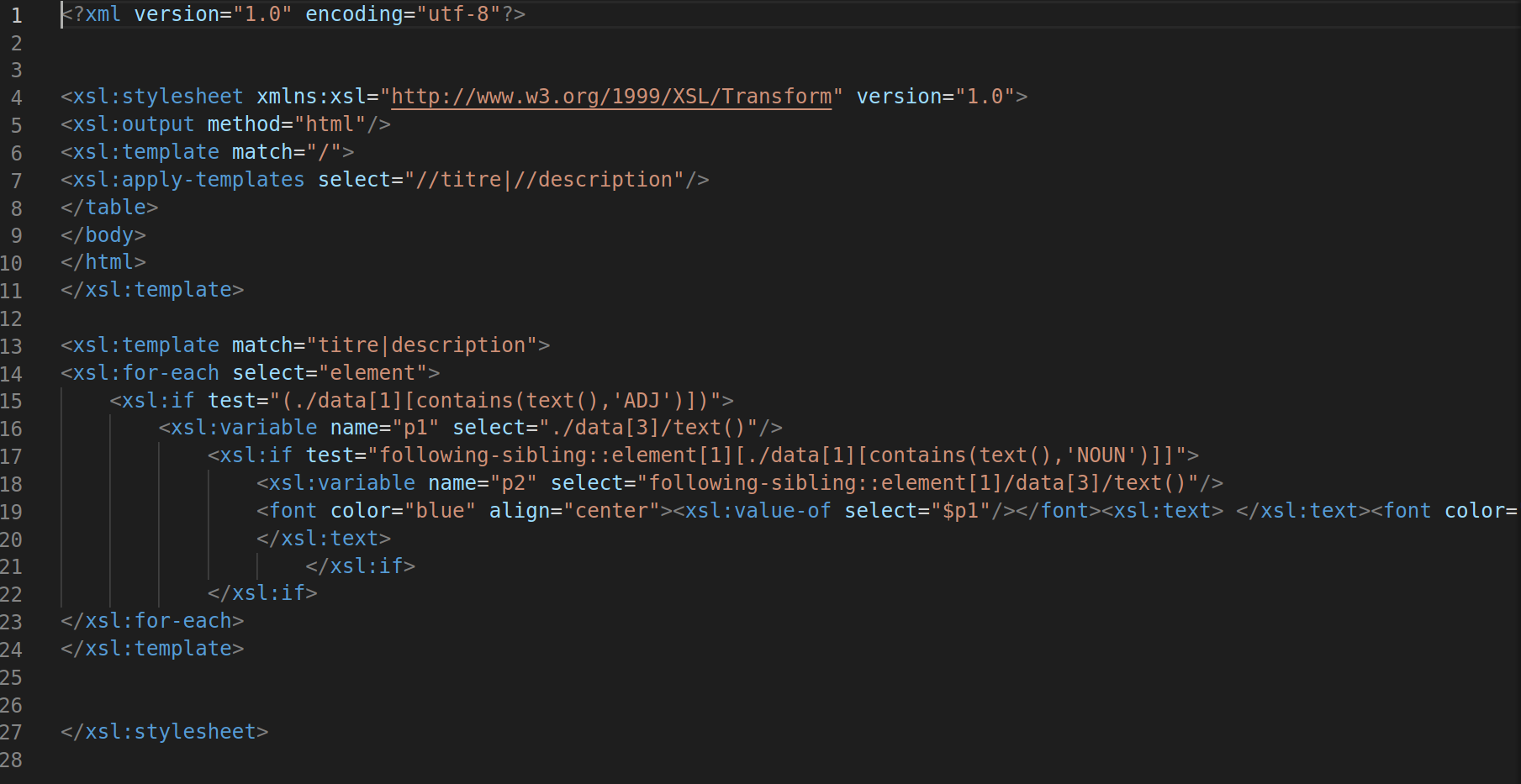
À faire attention vu que nous avons adapter les balises de TreeTagger au moment de la transformation CONLL-to-xml, il faut bien mettre le nom de la balise pour se situer sur la position exacte pour extraire les informations dont nous avons besoin.
par exemple, comparant à la sortie xml de Treetagger, celui de l'udpipe a une balise <id></id> de plus. Et elle porte la position du segment. Celles qui la suivent sont des balises <data> et il est facile de se tromper du numéro de la position dans la feuille de style. C'est pour cette raison que j'ai décidé de modifier et mettre en commun toutes les balises en forme <data>
Concernant l'adaptation de la feuille de style, il faut aussi bien observer les fichier xml d'entrée. Faut savoir si nous avons changer les balises <titre>et <description> ou nous avons fait le choix de les garder : par exemple pour les fichiers xml d'udpipe, dans l'objectif de bien découper la lecture du fichier au moment de l'extraction de la relation en python, j'ai changer tous les balises <titre> et <description> en <phrase>, il faut donc prendre en compte.
Pour générer la feuille de style, nous utilisons xsltproc. Il prend en argument la feuille de style, le fichier d'entrée et il suffit de mettre > pour créer et écrire dans la fichier de sortie.
Xquery (BaseX)
Le téléchargement du BaseX est assez simple si on travaille sous système Ubuntu: il suffit d'insérer la ligne de commande suivante:
sudo apt-get install basex
Les requêtes suivent la même logique que les feuille de style en xslt, il suffit de l'adapter selon le nom du fichier et des variables.
Il faut toujours faire attention le nom du répertoire et le nom du fichier.
Car arrivant à cette étape, nous avons déjà beaucoup de fichiers et de dossiers.
BÀO 3 - <2> Extraction des relations
Solutions :
- Perl
- Python
- Xslt(feuille de style)
- Xquery(BaseX)

Ligne de commande pour lancer le programme:
python3 BAO3_upxml_relation.py ./BAO2/BAO2_Py_udpipe3210.xml "obj" 3210
(On se situe dans le répertoire BAO)
Ici nous voyons l’avantage d'avoir toutes les balises unifiées:
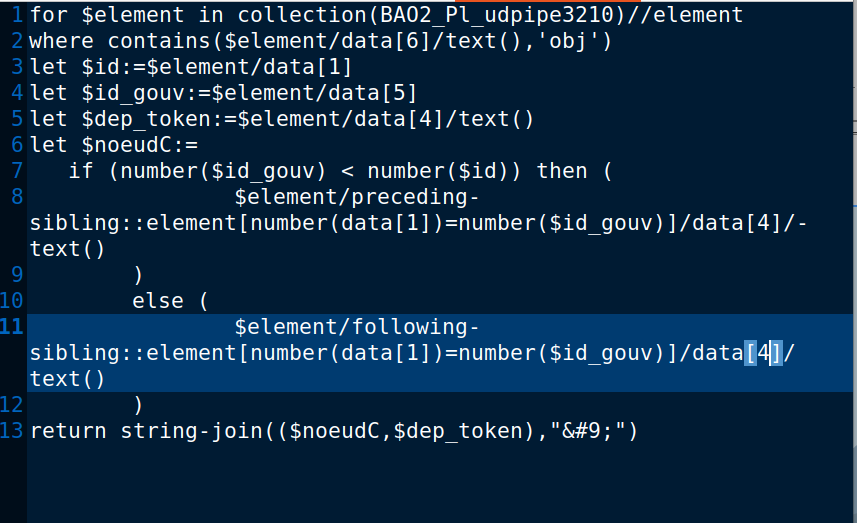
dans une version précédente j'ai mis <id></id> au lieu de <data type="id"></data> pour indiquer la position du segment. Cela ne posait pas problème pour les autres traitement, mais pour utiliser re.findall il n'est pas possible de récupérer une fois toutes les variables car nous demandons 6 variables mais pour les balises<data> il n'y a que 5 . Il faut utiliser re.match pour récupérer <id> , ce qui crée une étape de plus et plus de possibilité d'avoir des erreurs.
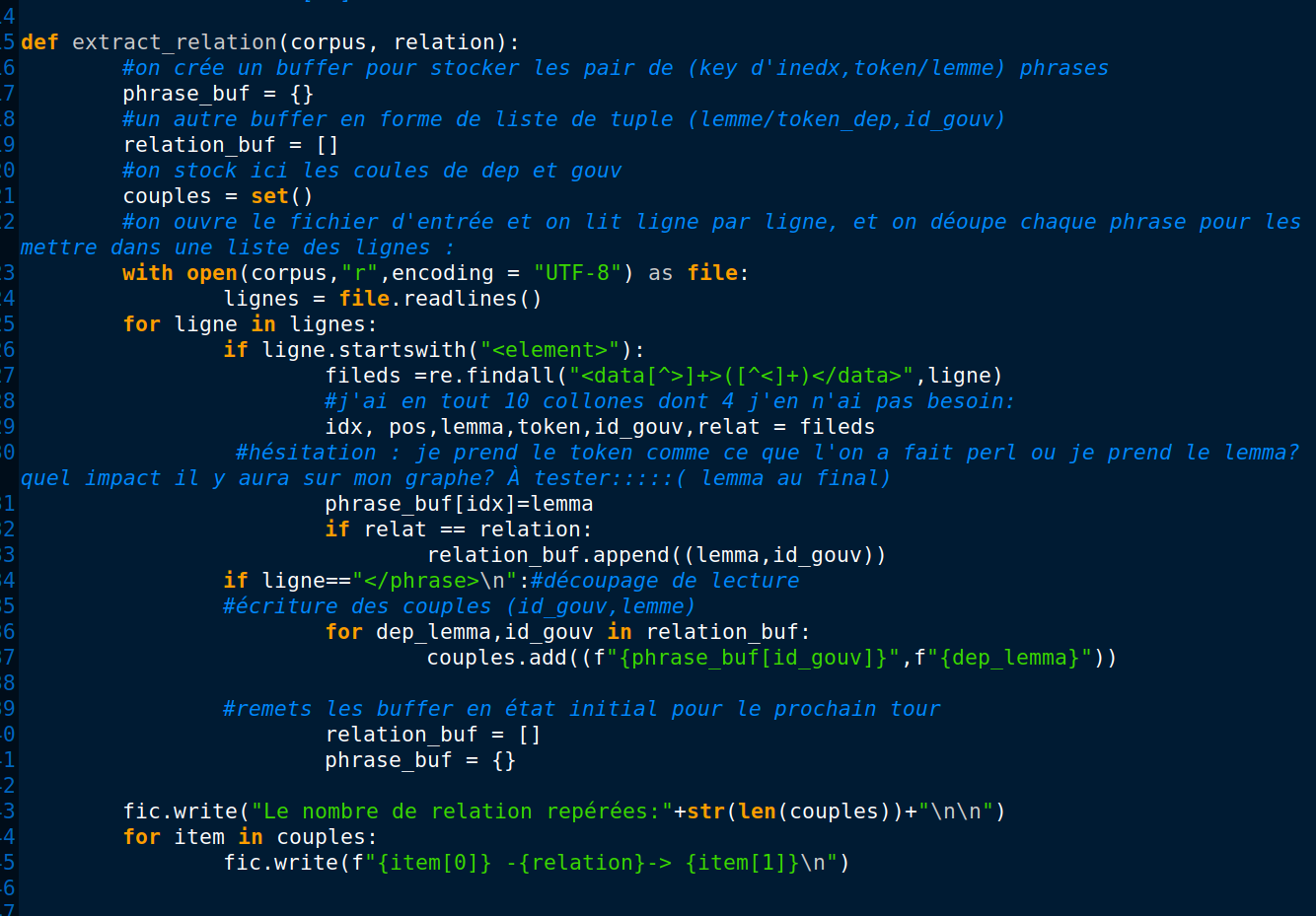
Ligne de commande pour lancer le programme:
perl Bao3_upxml_relation.pl ./BAO2/BAO2_Pl_udpipe3210.xml "obj" 3210
(On se situe dans le répertoire BAO)
Ce programme en PERL se différencie du script en Python pour extraire les segments qui ont une certaine relation de dépendance, PERL demande plus d'étape pour être soigneux.
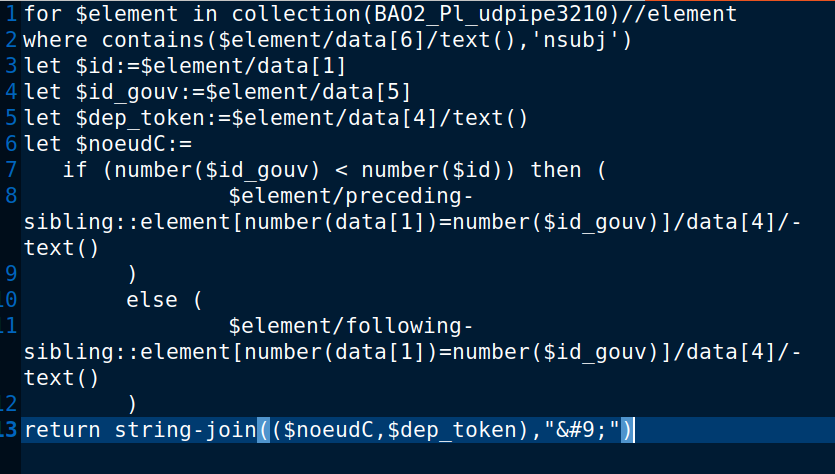
Deux situations possible quand on lit une ligne et trouver la relation que porte ce segment est "obj/nsubj":
- L'id de son gouverneur est plus petit que le sien, ainsi on sais que son gouverneur se situent avant lui. Le système va donc avancer du nombre de lignes entre eux.
- Si son gouverneur est plus en bas , soit son id est plus grand, il faut parcours les phrases suivantes.
XSLT (feuille de style)
Ici nous ne prenons que le fichier xml d'UDpipe comme corpus à traiter, il faut donc faire attention ce qu'on fixe au début comme balise, comme nous avons mentionné précédemment, pour évider les confusions et la complexité causées par les balises de phrases trop variées, nous avons changer <titre> et <description> en <phrase>, il faut donc bien se baser sur <phrase> pour lire la balise suivante, soit <element>.
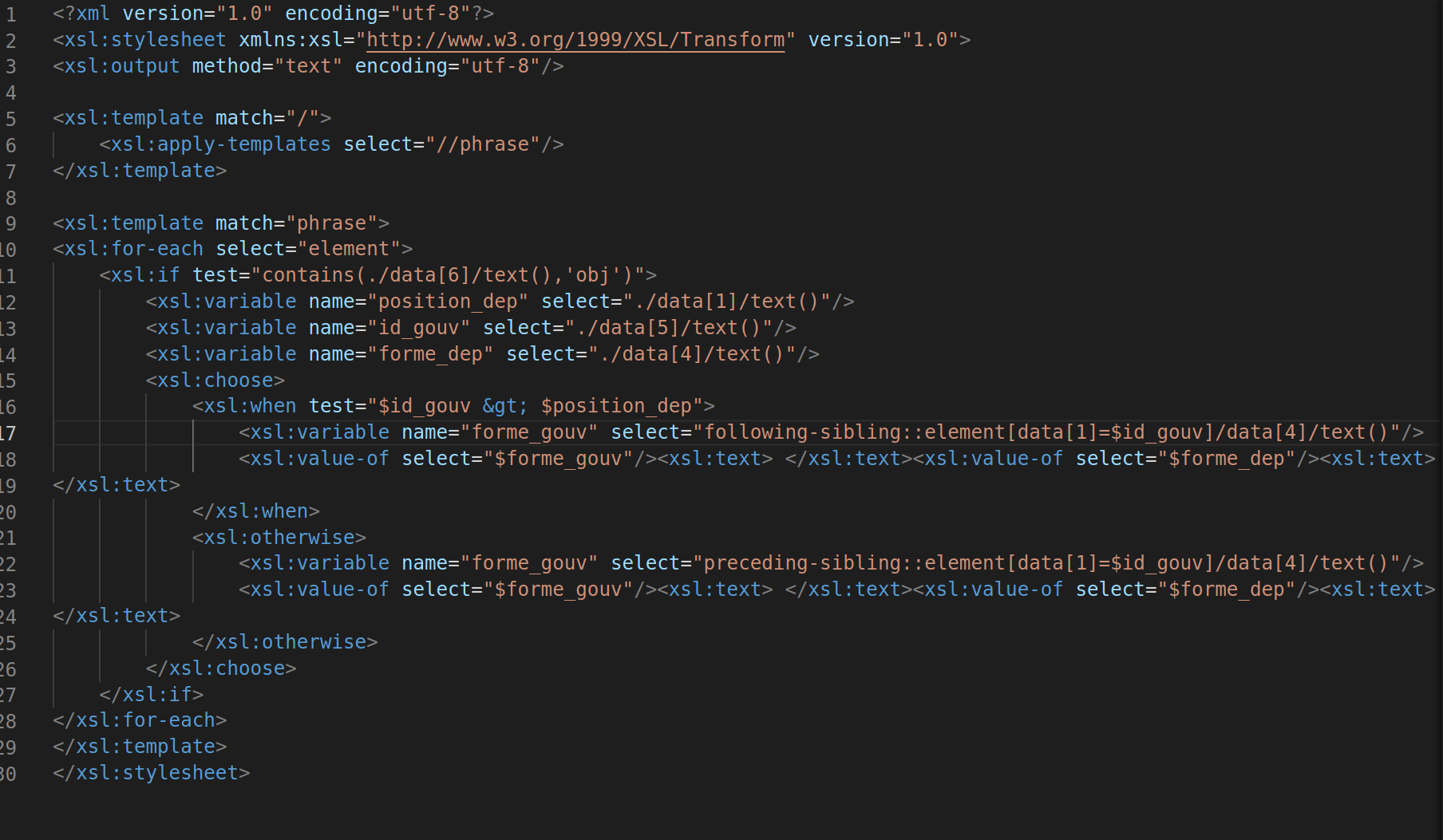
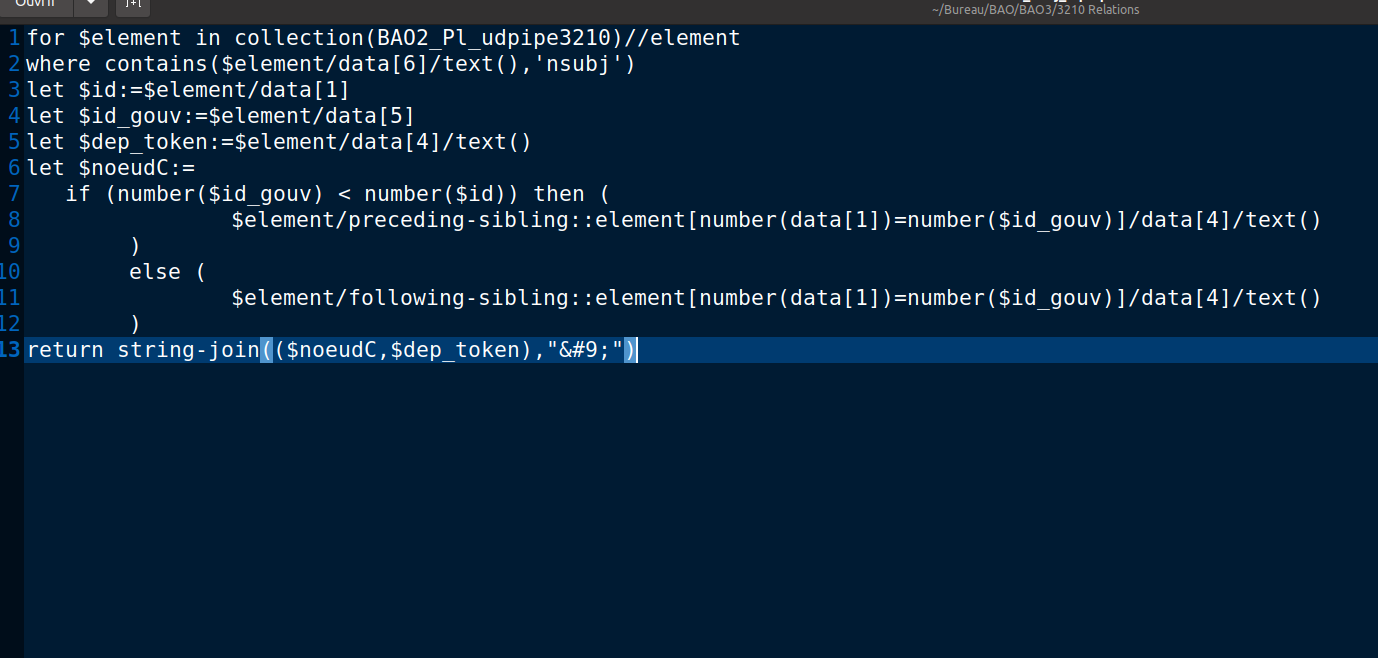
Xquery (BaseX)
Les requêtes suivent la même logique que les feuille de style en xslt, il suffit de l'adapter selon le nom du fichier et des variables.
Il faut toujours faire attention le nom du répertoire et le nom du fichier.
Car arrivant à cette étape, nous avons déjà beaucoup de fichiers et de dossiers.
created with
Best Website Builder .