Grâce à Tree-tagger, lors de l'ouverture de la base, un dictionnaire des lemmes est automatiquement généré. Ceci facilite notre tâche, plus besoin de reprendre l'expression régulière utilisée dans le script, on retrouve plus rapidement les deux traductions du verbe « devoir » dont nous souhaitons observer l'utilisation. En l'interrogeant, on trouve que « sollen » compte 275 occurrences, tandis que « müssen » en compte 229. A priori, on pourrait penser que « sollen » est à privilégier, mais la différence n'est pas très significative et pourrait être due aux textes sélectionnés. Tâchons de voir les emplois de ces deux verbes en contextes et de les expliquer : par exemple, est-ce qu'une forme ne serait pas privilégiée par rapport à l'autre dans certains sous-corpus ?
Voici donc la répartition de ces deux formes dans chaque sous-corpus :
MÜSSEN :
conditions d'utilisation et règlements intérieurs : 35
extraits de lois : 68
presse : 0
tutoriels : 14
SOLLEN :
conditions d'utilisation et règlements intérieurs : 51
extraits de lois : 107
presse : 0
tutoriels : 15
Voici également un graphe illustrant leur répartition :
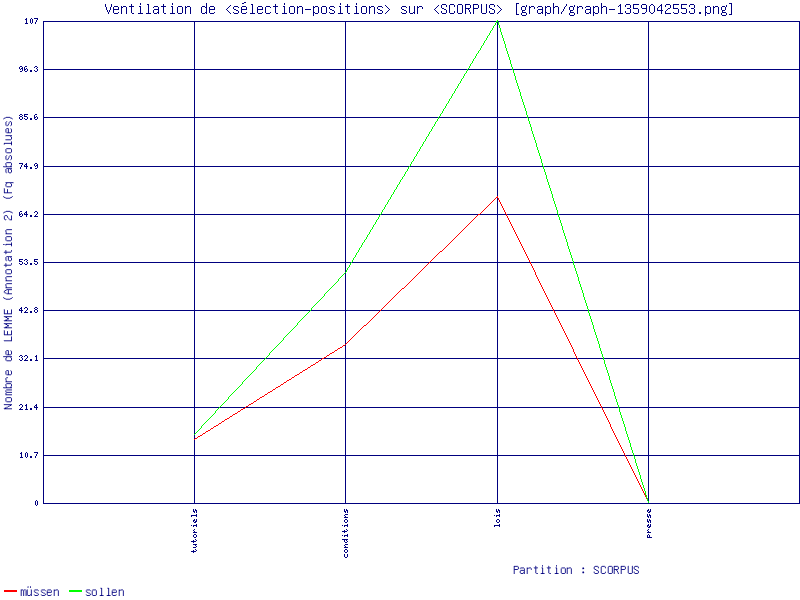
Il est étonnant de noter que le trameur ne trouve pas d'occurrences de ces deux verbes dans le sous-corpus presse. Pourtant, lorsqu'on se reporte au tableau de résultats et l'extraction de contextes réalisée par le mini-grep, aussi bien qu'egrep, on s’aperçoit qu'il existe bel et bien un certain nombre d'occurrences. Notre fichier DUMP-TOTAL est bon, la balise <SCORPUS=PRESSE> est bien placée et nous avons vérifié la présence de « sollen » et « müssen » dans le sous-corpus. Nous ne comprenons pas et décidons d'exclure ce sous-corpus pour la suite de notre étude.
Nous remarquons que les deux verbes ont à peu près le même nombre d'occurrences dans les trois sous-corpus, seul le sous-corpus de lois montre une vraie différence. Observons alors les concordances de ces deux formes pour essayer d'en comprendre l'usage.
Pour cette partie, nous décidons de plus travailler à partir du dictionnaire des lemmes, nous reprenons l'expression régulière utilisée dans le script, afin d'observer les différentes formes sous lesquelles se retrouve ces deux verbes. Un tri par formes puis un tri par sous-corpus nous ont permis de faire les observations suivantes :
- « sollen » est très souvent utilisé dans des structures infinitives, en particulier dans le sous-corpus d'extraits de lois.
- « sollen » est très souvent utilisé au subjonctif II, équivalent du conditionnel français, en particulier dans les conditions d'utilisations. En revanche, « müssen » apparait plutôt dans des formes conjuguées qui s'adressent au lecteur.
Ces remarques sont par ailleurs confirmées par l'observation des segments répétés :
werden sollen : 20
müssen Sie : 18
sollten Sie : 14
Nous pouvons donc conclure de cette brève analyse qu'en allemand, les verbes « müssen » et « sollen » sont deux façons d'exprimer l'idée de devoir aussi fréquente l'une que l'autre, mais ils ont des fonctions différentes. « Sollen » sert à exprimer une obligation moins forte, dans des tournures conditionnelles par exemple. C'est la tournure la plus fréquente dans les extraits de lois, mais « müssen » y est utilisé aussi. Nous concluons donc que l'emploi d'un verbe ou de l'autre ne dépend pas tant du registre, mais plutôt du degré d'obligation exprimée.