2- Notre Script
Voici un graphique pour illustrer les différentes étapes de notre script :
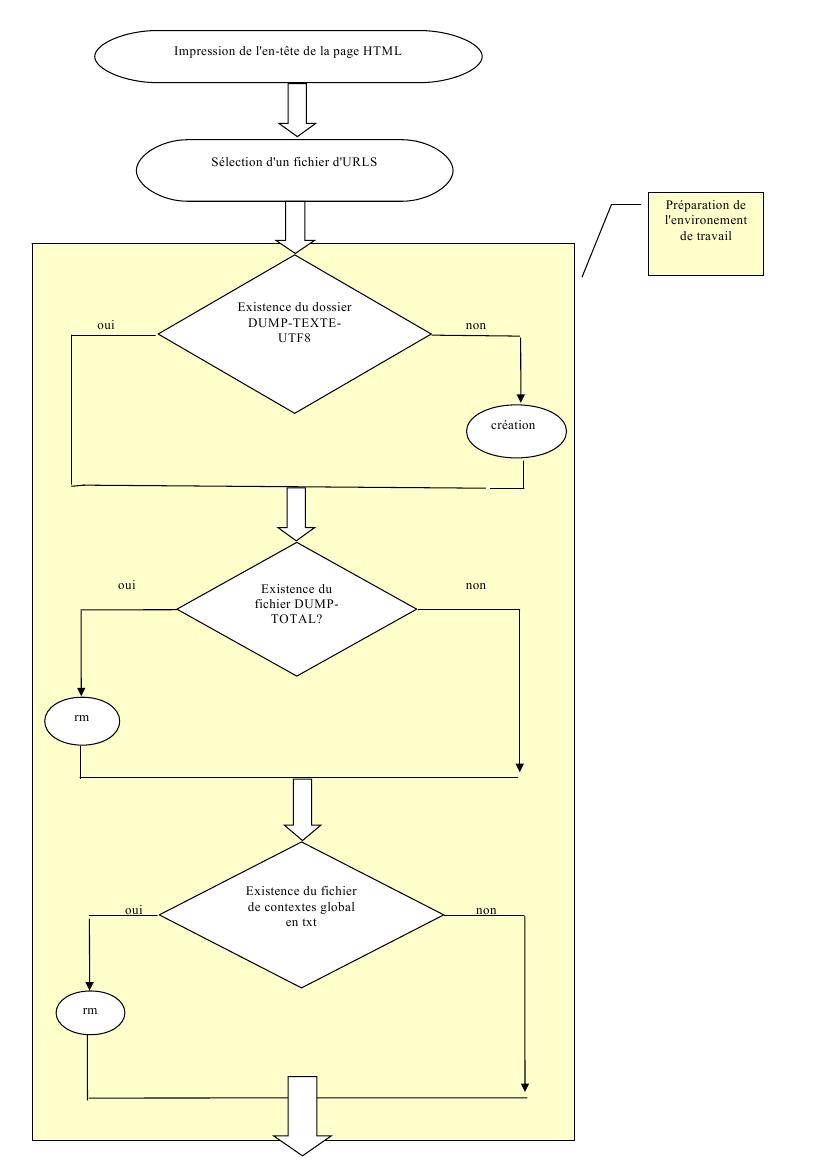
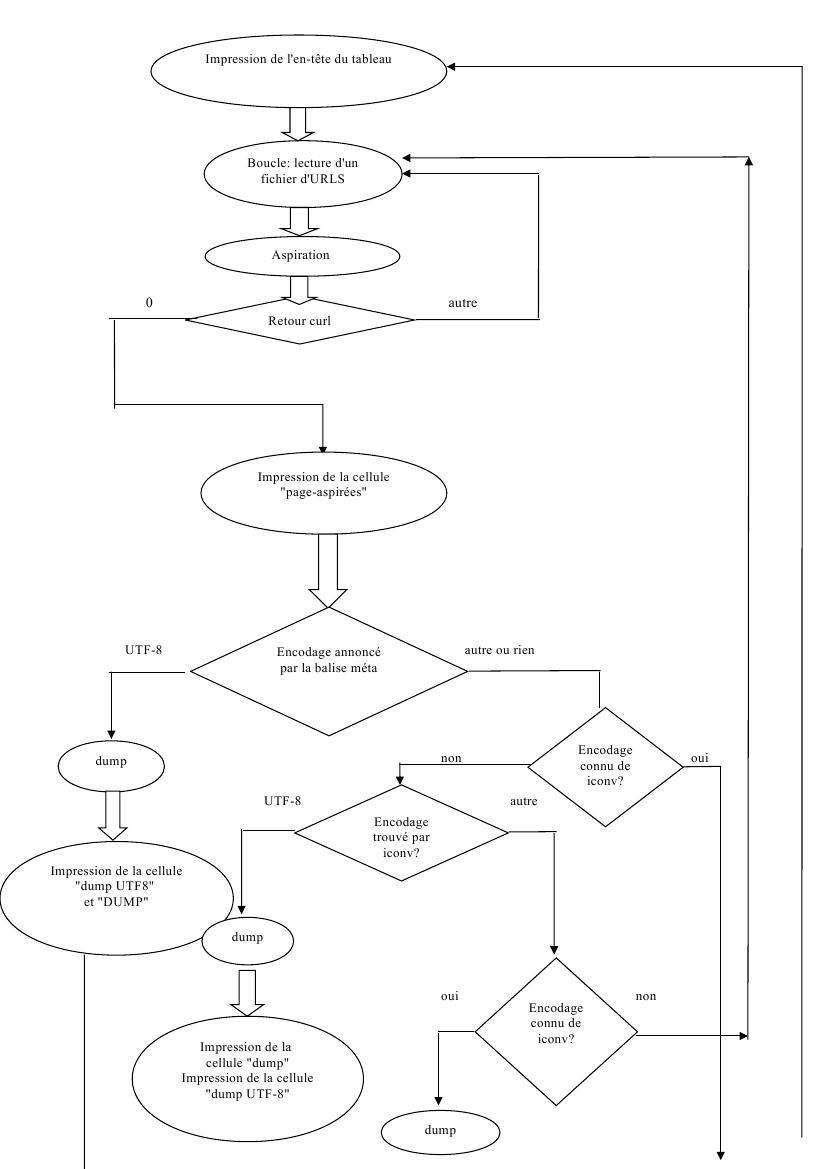
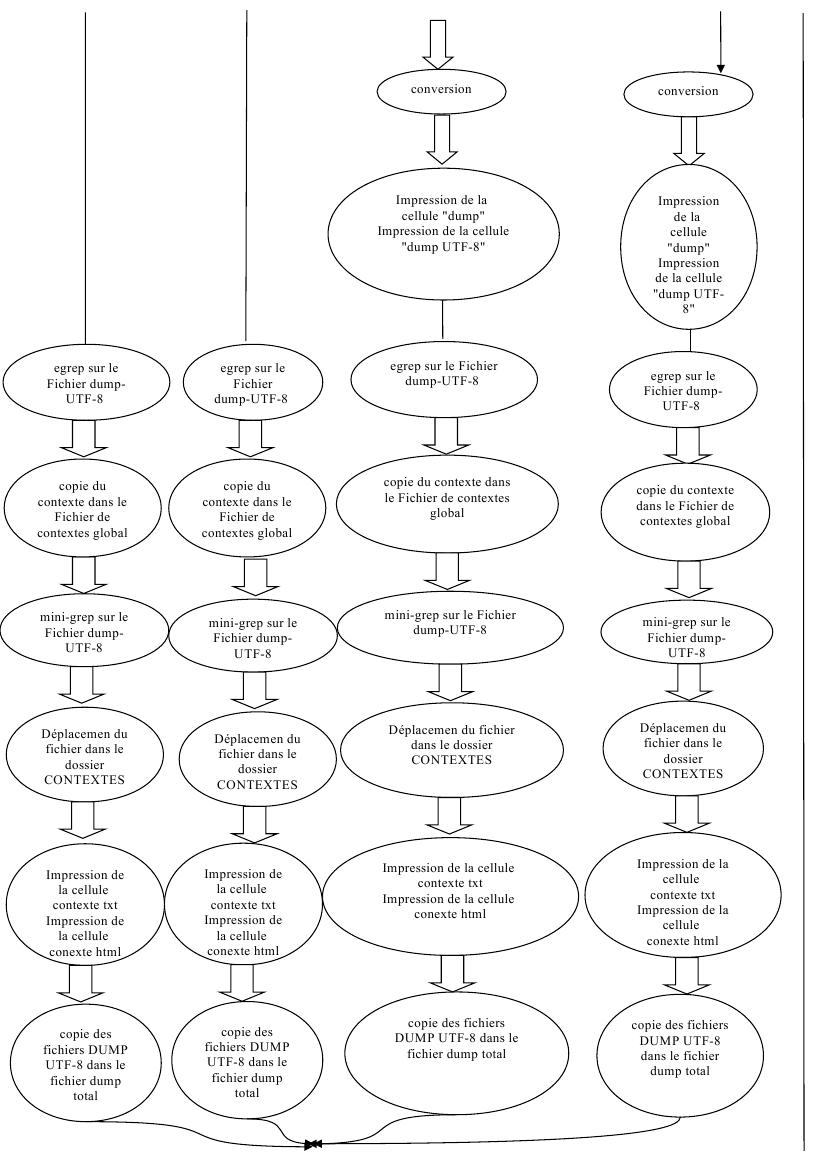
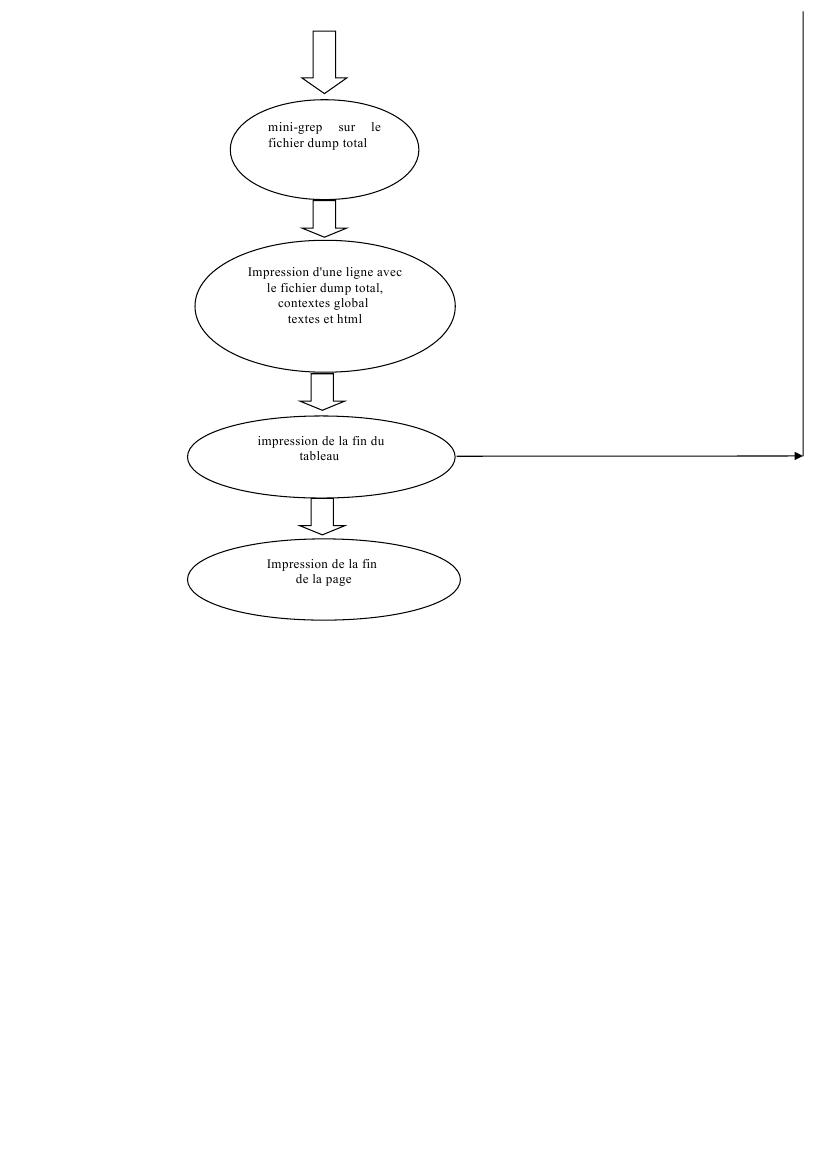
Préparation de l'environnement de travail :
Avant de commencer le corps de notre programme, nous apportons quelques modifications sur l'environnement de travail :
Pour faciliter l'exploitation des données récoltées, nous avons décidé de rassembler nos fichiers dump convertis ou récupérés en utf-8 dans un même dossier. Une simple ligne de commande avec mkdir suffit à créer ce dossier, mais pour ne pas créer de conflits, il faut avant tout vérifier l'existence de ce dossier à l'aide d'une clause if.
Pour constituer les fichiers qui rassemblent tous les dumps en utf-8 et tous les fichiers de contextes en txt, nous utilisons l'opérateur « >> ». C'est-à-dire que les dumps ou les contextes vont s'accumuler même à chaque fois qu'on relance le programme. Puisque la constitution de ces fichiers s'effectue au sein d'une boucle, nous n'avons pas d'autre choix que de les réinitialiser avant cette boucle, c'est-à-dire la boucle 2 de notre programme, celle qui concerne le traitement des URLS une à une. Pour cela, nous vérifions leur existence dans une clause if, et nous les effaçons le cas échéant.
Aspiration :
Nous avons découvert au premier lancement de notre script, que certaines urls étaient des redirections. Pour réussir à les aspirer, nous avons ajouté l'option -L à la commande curl pour pouvoir remonter jusqu'à la page désirée.
Afin de ne pas perdre de temps à poursuivre le traitement des pages dont l'aspiration s'était mal passée, nous avons utilisé le retour curl pour les détecter. L’inconvénient de cette technique est qu'elle ne détecte pas les pages qui affichent une erreur du type erreur 404. En effet, à partir du moment où une page a été aspirée, même affichant un message d'erreur, le retour curl est différent de 0 et donc la page n'apparait pas en anomalie dans le tableau et est traitée comme les autres pages.
Détection de l'encodage des pages :
Nous avons eu des problèmes avec le chinois lors de la détection de l'encodage des pages. Initialement, notre script cherchait l'encodage des pages en interrogeant file avant la balise meta. Mais nous nous sommes aperçues que file détectait en iso-latin bon nombre de pages dont la conversion en utf-8 échouait après. En observant les balises meta de ces pages, nous avons remarqué qu'en réalité, elles étaient pour la plupart encodées en GB2312, plus une en BIG5 et une ou deux en GB18030.
Pour dumper correctement les pages, il nous a donc fallu revoir notre script et faire en sorte que la détection de l'encodage se fasse d'abord en interrogeant la balise meta, puis par file si le résultat obtenu n'est pas satisfaisant. Le risque pour nous est alors de récupérer une mauvaise information et de ne pas réussir notre dump sur les autres langues si jamais certaines balises sont mal renseignées.
Mais l'extraction d'information à partir des balises meta nous a réservé quelques surprises. Par exemple, on trouve parfois deux balises meta charset. Elles indiquent parfois la même information. Dans ce cas, la variable $encodageDeLaMeta qui sert à déterminer comment traiter la page, comment la dumper et s'il est nécessaire de la convertir peut prendre une valeur telle que « utf-8 utf-8 ». Il est facile de régler ces cas là grâce à la commande « sort -u ». Mais dans des cas où les deux balises expriment une information différente, comme pour l'URL 65 de l'allemand avec une balise indiquant « utf-8 » et une autre indiquant « UTF-8 », nous sommes obligées de laisser la main à l'étape avec iconv. La page se trouve alors traitée comme une page encodée autrement qu'en UTF-8:dumpée puis convertie !
De plus les informations ne sont pas exprimées d'une manière uniforme dans ces balises : l'encodage des pages peut aussi être exprimé avec des majuscules, des minuscules, des barres obliques : « utf-8 », « UTF-8/ »etc. Nous avons donc dû tenir compte de la casse dans l'expression de la condition sur l'encodage des pages, et ajouter une disjonction : « utf-8 || UTF-8 ». Nous avons enlevé les barres obliques à l'aide d'un pipe « tr -d \ » lors de l'extraction d'information de la balise meta.
Nous avons concentré la résolution des problèmes liés à l'expression des balise meta charset à l'utf-8. Pour les autres encodages, nous laissons la main à iconv ou encore à file dans les étapes suivantes.
Dump :
Nous nous sommes aperçues qu'il valait mieux effectuer le dump à partir des pages aspirées et stockées localement. En effet, certaines URLS qui avaient été correctement aspirées rendaient un dump vide. Nous soupçonnons que cela est dû à des redirections : l'option -L de curl permet d'aspirer ces pages malgré tout, mais lynx n'accède pas à ces pages. Travailler sur les pages en local règle donc ce problème et fait gagner du temps lors du traitement du script.