
Notre analyse faite avec Le Trameur.
Analyses
Avec l’aide du logiciel Le Trameur et Itrameur sur internet, nous avons pu analyser nos fichiers dump et nos fichiers de contextes en français et en anglais afin de savoir comment pourrait être réparti notre mot "obésité" / "obesity" dans les deux langues, et ainsi, savoir quel est sa représentation, avec quels autres mots peut-on le retrouver ? Par quels autres mots, lemmes, notre mot peut-il être influencé ?
Nous avons donc essayer de répondre à ses questions à l’aide de ces logiciels.
À l’aide de Itrameur en ligne, nous avons commencé par analyser plus généralement notre mot obésité/obesity avec les fichiers dump.
Nous avons tout d’abord voulu savoir quels mots accompagnant le mot « obésité » (en français) étant sur-représentés dans notre corpus des dump. Voici le résultat :


On peut aussi ajouter le fait qu’il faudrait que notre corpus soit nettoyer à la main afin de ne pas retrouver comme surreprésentation des phénomènes qui ne sont pas des mots (comme des étoiles, des signes de ponctuation) et donc qui peuvent parfois fausser un peu l’analyse ainsi que l’interprétation.
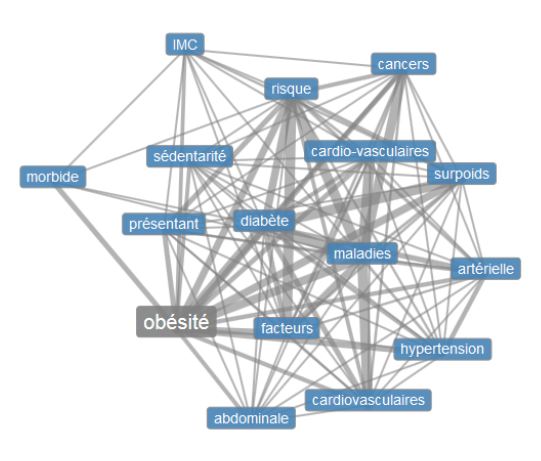
Par la suite, nous avons effectuer un graphe des cooccurrences dans chaque langue afin d’avoir un meilleur visuel plus attractif et dynamique :


Ces derniers montrent quand même par quels mots ils sont connectés, tel un « organigramme ».
Nous avons aussi procédé à une carte des sections dans chaque fichier dump afin de savoir comment étaient répartis les mots recherchés.
Voici un exemple pour chaque langue :


Cette carte des sections nous permet de voir dans quelle partie du dump est situé notre mot et donc comment il est réparti dans chaque partie.
Enfin, toujours avec nos fichiers dump, nous avons fait les spécificités totales du fichier, donc à quelle fréquence l’on retrouve chaque mot du fichier. Le résultat reste un peu brouillon car nous le logiciel a du parcourir tout le fichier afin de représenter chaque mot, voire chaque caractère. De ce fait, comme dit précédemment, vu que notre fichier n’est pas nettoyer à la main, certains caractères peuvent venir fausser un peu le résultat, comme ici les numéros, et donc le résultat reste très illisible.



Nous allons voir s’il en est de même pour l’anglais.

Nous allons donc par la suite analyser ces formes maximales à l’aide de la carte des sections, des fréquences et pour finir les concordances.
Commençons par la carte des sections :


Voici le résultat pour le français :



Grâce à notre fichier « contextes » où le mot choisi est déjà isolé, on peut voir que le mot est assez régulièrement réparti dans tous les fichiers.
Ce qui permettra par la suite de faire une analyse un peu plus détaillée.
De ce fait, on peut se focaliser sur le fréquence de la forme lemme choisie, qui est ici « obésité » et « obesity ».
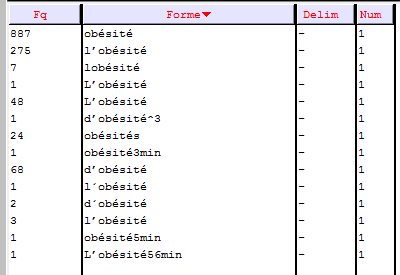

On peut donc dire que nos fichiers contextes représentent tous les deux à peu près de la même façon le mot choisi. De ce fait, l’analyse ne devrait pas être faussée à cause d’un écart d’occurences.
Pour aller un peu plus loin, on peut se concentrer sur la fréquence en contexte afin d’observer plus précisément la répartition du mot dans le fichier :

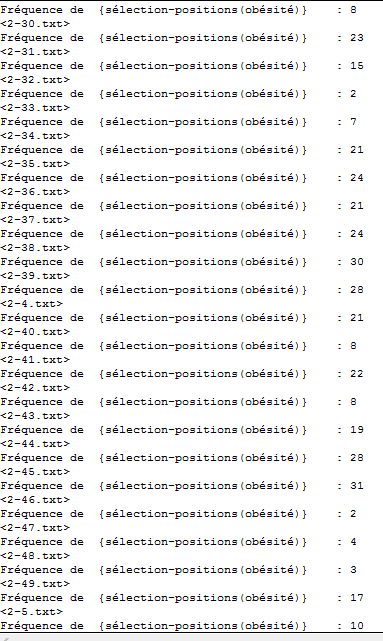


Dans quel partie de la phrase notre mot se trouve-t-il ? Qu’est-ce qu’il peut y avoir avant et après ?
Dans ce cas, on peut directement aller voir quel parti du discours peut se trouver à côté du mot, mais l’on peut aussi directement regarder les concordances.
Voici le résultat (en français puis en anglais) :





Enfin, pour élargir notre analyse, nous avons choisi comme forme lemme un synonyme très proche dans les deux langues du mot obésité, afin d’avoir une autre représentation.
Ce dernier est : « surpoids », « overweight »
Nous avons donc concentré une dernière analyse sur ce terme afin de faire une comparaison :
Nous sommes allées voir directement à l’aide de la forme lemme les concordances associées :
Voici le résultat pour le français puis l’anglais :







Complément
Par la suite, nous avons été sur le site de l'université de Leipzig. Ce site permet de faire une concordance de mots à l’aide des corpus présents dans le site. Nous avons décidé d'analyser nos mots avec ce copus car nous trouvons intéressant de faire une comparaison avec le résultat de l'analyse de notre corpus.
Voici le résultat pour les deux langues : 
 Nous pouvons donc constater que le résultat de l'analyse faite avec le corpus de l'université de Leizpig est similaire à ce que nous avons pu trouver.
Nous pouvons donc constater que le résultat de l'analyse faite avec le corpus de l'université de Leizpig est similaire à ce que nous avons pu trouver.
Conclusion
Notre analyse sur les logiciels Le Trameur et Itrameur nous ont permis de voir comment été représenté le mot « obésité » et « obesity » à l’aide des URLS prises sur internet.
En effet, on peut se rendre compte qu’à travers chaque pays, chaque culture, le mot n’est pas forcément interprété de la même manière.
Cependant, les occurrences des mots choisis semblent avoir une signification assez similaire dans les langues différentes. On peut voir cela grâce aux concordances dans notre analyse. On a pu faire des rapprochements entre certains mots dans deux langues qui sont, dans chaque cas, des synonymes du mot principal. De ce fait, on peut quand même se poser la question suivante :
Un corpus comme celui-ci suffit-il pour conclure que la représentation du mot est similaire dans les deux pays ?
On a souvent des « prérequis » sur la question. De ce fait, on peut s’imaginer que le mot « obesity » serait plus présent dans les corpus américains plutôt que français, sûrement moins touchés par ce phénomène.
Si on s’en tient aux analyses faites ci-dessus, la seule observation que l’on peut faire, c’est que les deux pays sont touchés : on trouve, avec un même nombre d’urls choisis dans les deux langues, quasiment la même répartition du mot de départ. Par ailleurs, le synonyme « surpoids »/ « overweight » est beaucoup plus flagrant en français car sa représentation est plus élevée.