Analyses de corpus avec iTrameur
Hypothèses pour l'analyse du mot "élection" :
Avant de commencer l'analyse avec itrameur, on s'attendait à trouver dans les résultats :
- une forte cooccurrence des mots "élection", "présidentielles" et "2022" dans les trois langues.
- des noms propres : les noms des candidats à cette élection, ainsi que différents thèmes associés aux différents noms.
- des mots relatifs à la politique et au vote, comme "candidat", "programme", "vote", "politique", mais aussi des mots exprimant de la subjectivité et des opinions.
- les dates des élections, et des chiffres relatifs aux sondages.
- un lien entre la chronologie des articles et l'annonce des candidatures.
Les urls ayant étés récoltés au fil du semestre et étant principalement des articles de presse, ils se trouvent globalement dans un ordre chronologique de parution dans nos fichiers concaténés. Ainsi, nous pouvons chercher si des tendances se créent ou s'effacent en fonction du temps.
Les premiers articles datent de l'été 2021 et les derniers de janvier 2022.
Anglais
Pour commencer nos analyses, nous avons chargé le corpus CORPUS_CONTEXTE_EN. Il faut noter que le corpus chargé dans iTrameur doit être au format txt brut et encodé en UTF-8.
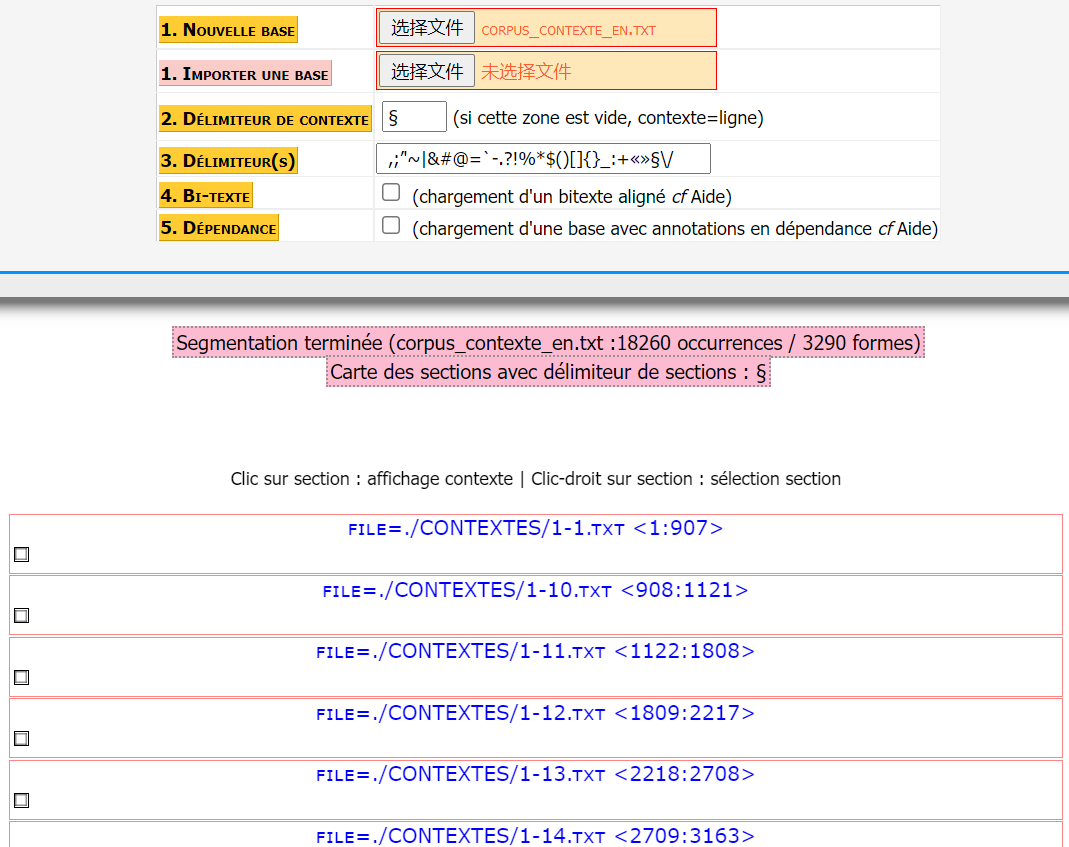
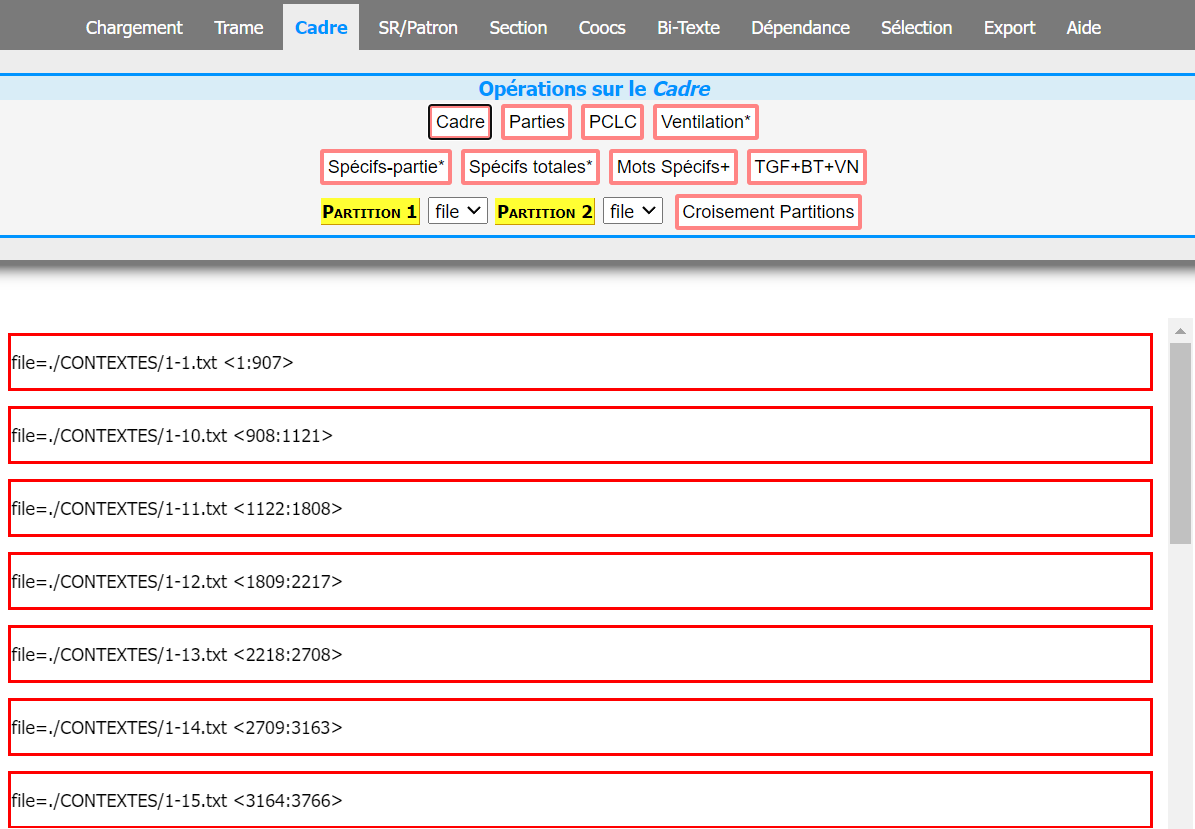
Nous avons vu que la carte des sections est apparue automatiquement et tout avait l’air normal. Après avoir chargé le corpus, nous avons également vérifié si le corpus a été vraiment bien chargé en regardant la structure du copus dans l’onglet “cadre”. Voilà la structure de notre corpus en anglais.
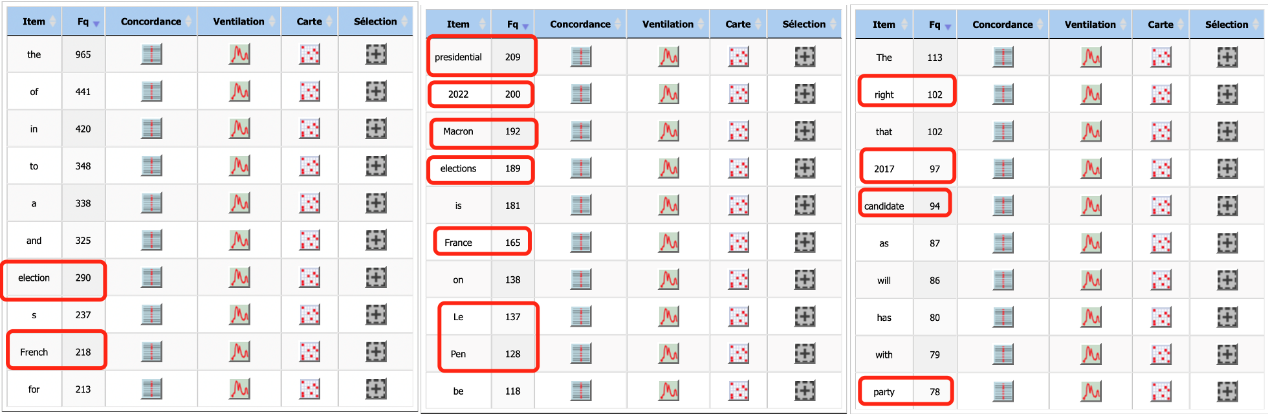
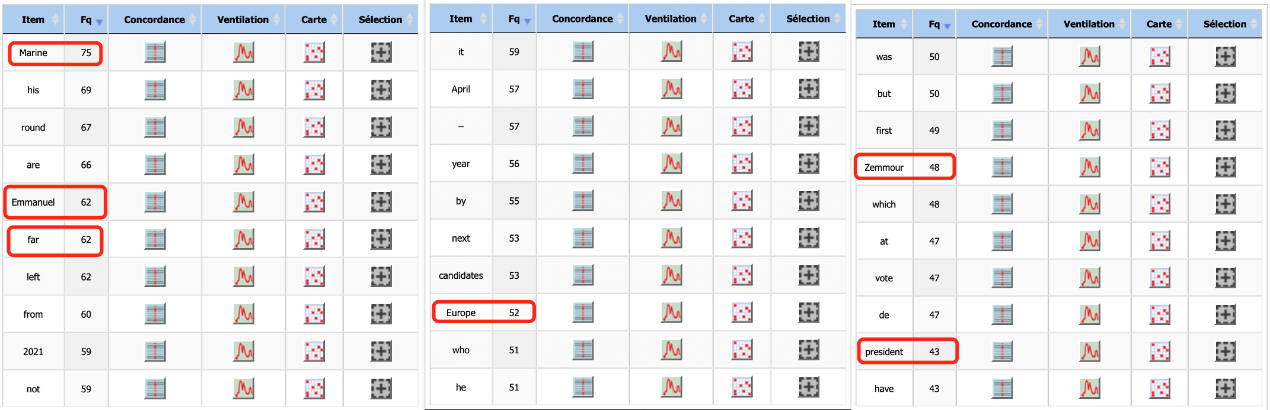
On a observé la fontionnalité de l’Itrameur « dictionnaire » pour avoir une idée sur le noyau du corpus en voyant les mots classés par ordre décroissant selon leur fréquence. Vu que tous nos corpus sont basés sur l’élection présidentielle française de l’année 2022, il est normal de trouver les mots les plus fréquents comme « election », « French », « presidential » et « 2022 ». En plus de ces mots-là, on a constaté le nom des candicats, comme « Macron », « Le Pen », « Zemmour », etc. Le champ lexical portant sur la politique, par exemple (right, left, party, candidate) a une fréquence assez importante également.
Selon le dictionnaire, nous savons déjà que Emmanuelle Macron reste en tête par rapport à ses concurrents, tandis que Marine Le Pen qui se place au deuxième rang jouit une large popularité également. Afin de comparer leur fréquence absolue dans chaque partie de notre corpus, nous avons employé la fonctionnalité « ventilation », le graphe ci-dessous est notre résultat. Selon ce graphe, nous avons constaté que Zemmour est apprécié par certains journaux et la fréquence de son nom a dépassé celle de Macron dans plusieurs articles de presse.
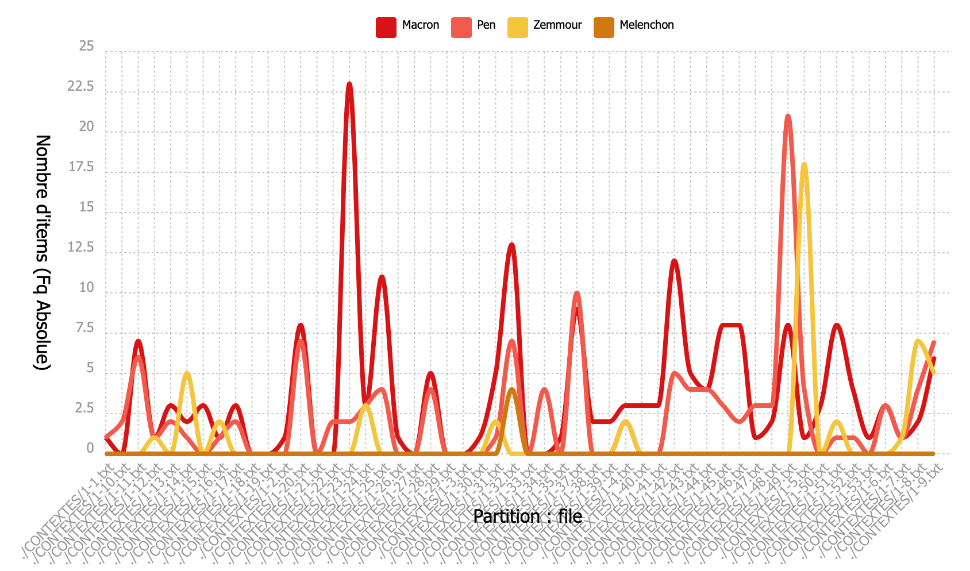
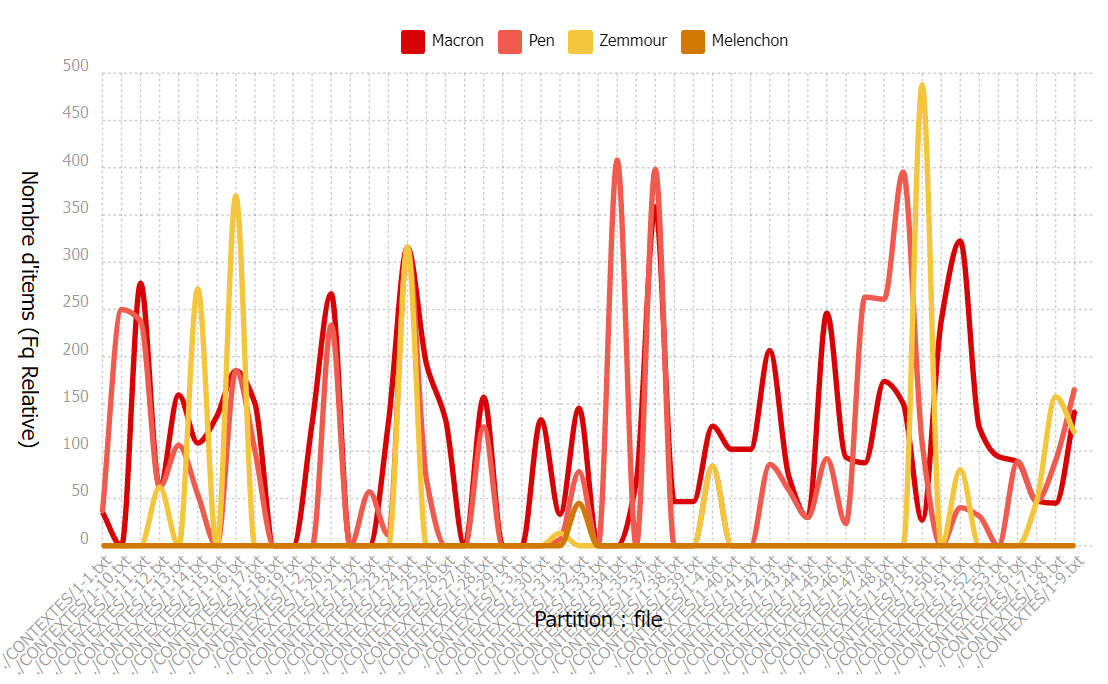
En raison des tailles différentes des parties de notre corpus, nous ne pouvons pas simplement comparer la fréquence absolue du nom des candidats dans chaque partie. Nous nous sommes ensuite penchés sur la fréquence relative de nos motifs en observant le graphe suivant et trouvé que, pour les 20 premières parties qui ont une fréquence relativement basse, la fréquence absolue basse ne signifie pas que cette partie s’intéressent moins aux candidats de la Présidentielle, ceci est dû à leur taille petite. En plus, nous pouvons déduire que les candidats sont largement parlés dans les parties qui ont une fréquence relative hausse que les autres parties qui décrivent peut-être plus sur le processus de l’élection plutôt que les candidats.
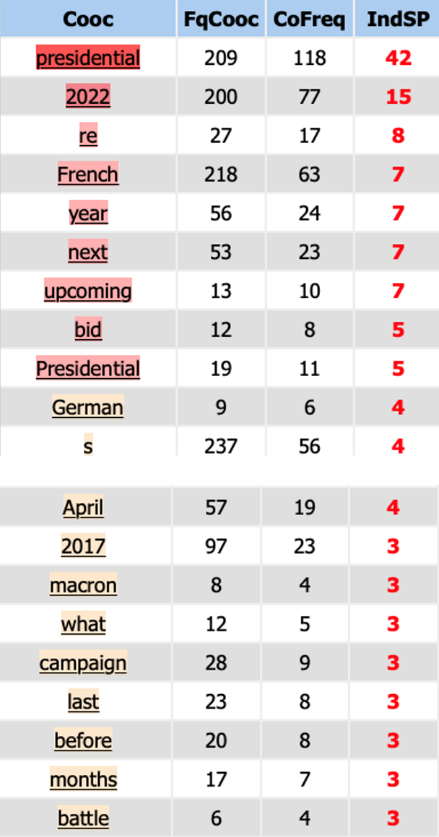
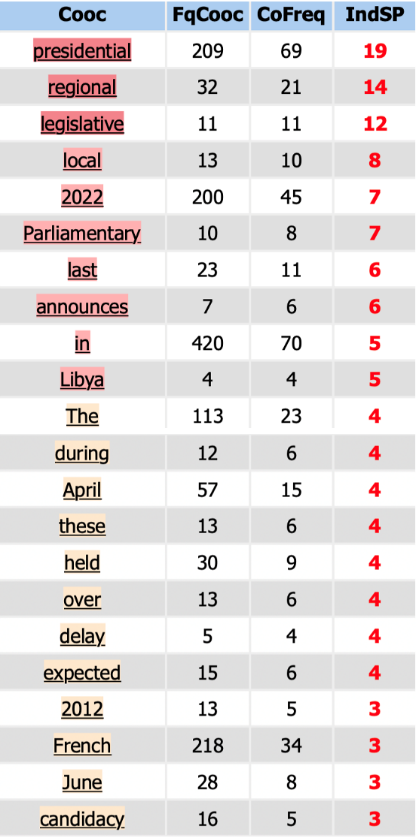
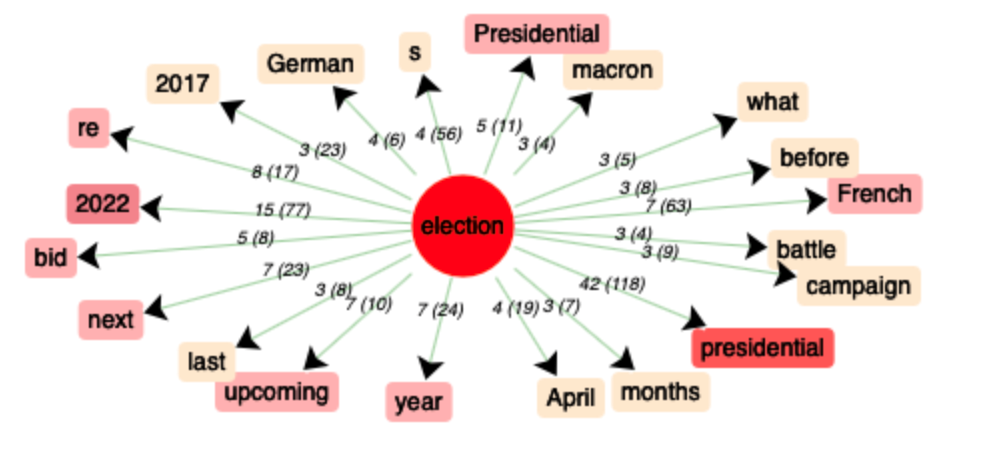
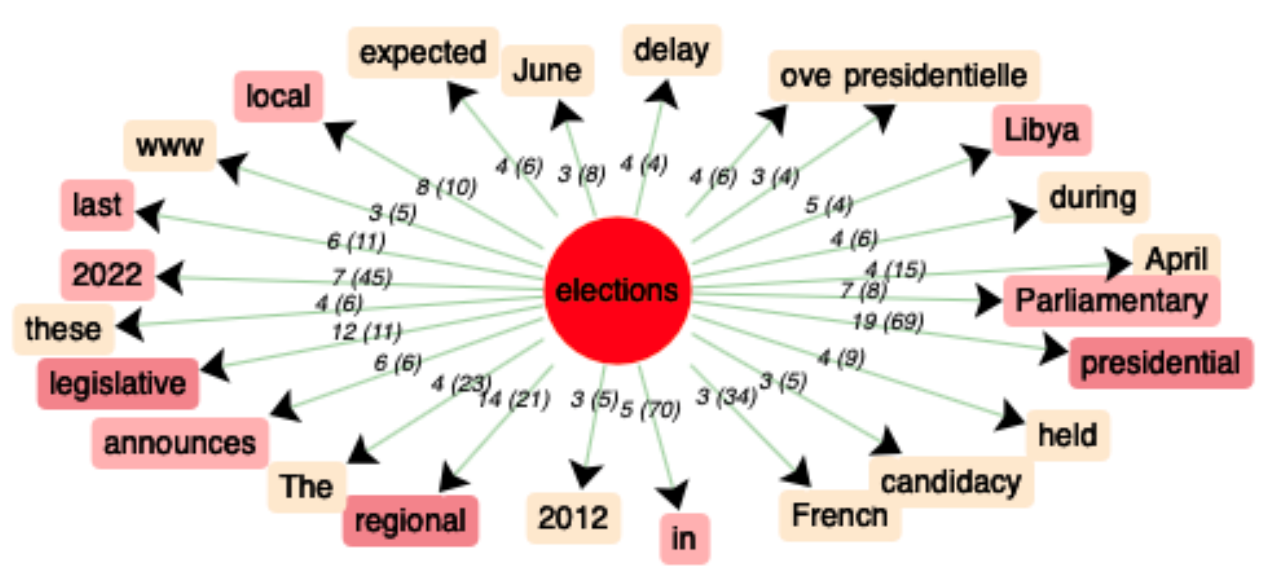
En cliquant sur l’onglet “Coocs”, nous avons pu trouver les cooccurrents du mot-clé“election”avec leur fréquence ainsi qu’un nœud-coocurrence qui est la représentation graphique des résultats, nous avons remarqué que « presidential », « 2022 », « French » sont des mots qui apparaissent le plus souvent autour du mot « election ». Du fait que « election » au pluriel possède une fréquence importante, nous avons analysé « elections » également et trouvé que « election » et « elections » partage des cooccurrents assez similaires, mais « elections » concerne d’autres types d'élections comme « regional elections », « Parliamentary elections », qui ne nous intéresent pas.
 |
 |
 |
 |
Français
Sans compter les mots grammaticaux, les mots les plus fréquents dans nos pages web sont "présidentielle" et "2022" avec 2610 et 2435 occurences. Le mot "élection" en a bien moins avec 1514 occurences au total. On trouve "France" avec 1540 occurences, la plupart du temps dans les noms de régions ou de journaux. Le lemme "candidat" est présent plus de 2000 fois également ; c'est le thème le plus abordé dans tous ces articles.
"2022" fait référence à la date de l'élection présidentielle, et "2021" est aussi présent 1414 fois, mais se rapporte à la date de parution de la majorité des articles.
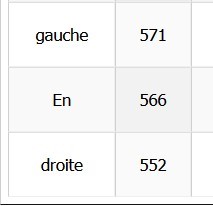
Les mots "gauche" et "droite", se référant aux bords politiques, ont pratiquement le même nombre d'occurences (la différence n'étant pas significative, car pouvant venir du choix des articles).
On trouve comme prévu des mots relatifs au thème des élections parmi les mots les plus fréquents : campagne, candidat(e)(s), candidature, politique, premier / second tour, vote, président, France, français, primaire, débat, sondages, ministre...
Concernant les candidats, les noms les plus fréquents (avec leur nombre d'occurences) sont :
Zemmour : 888Macron : 817
Le Pen : 624
Pécresse : 521
Hidalgo : 439
Mélenchon : 310
Jadot : 300
Taubira : 223
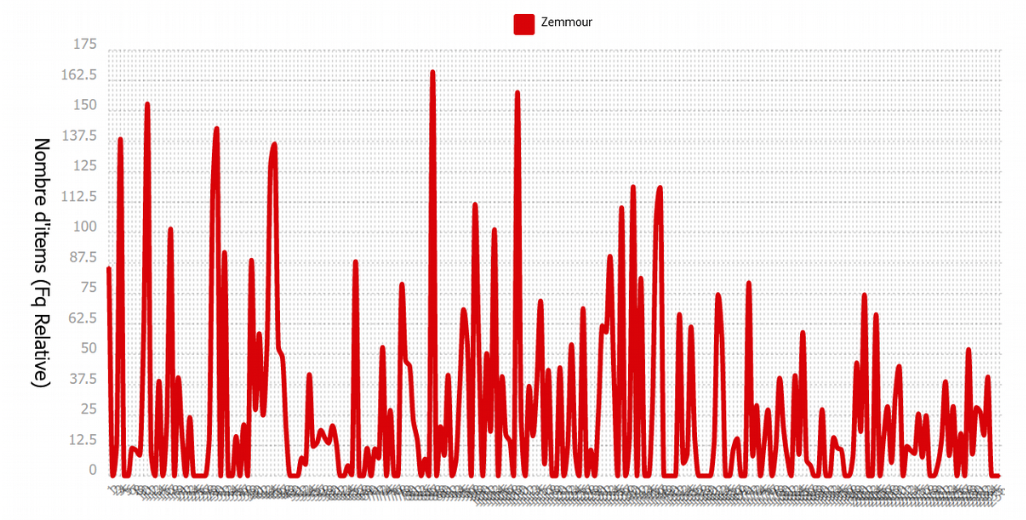
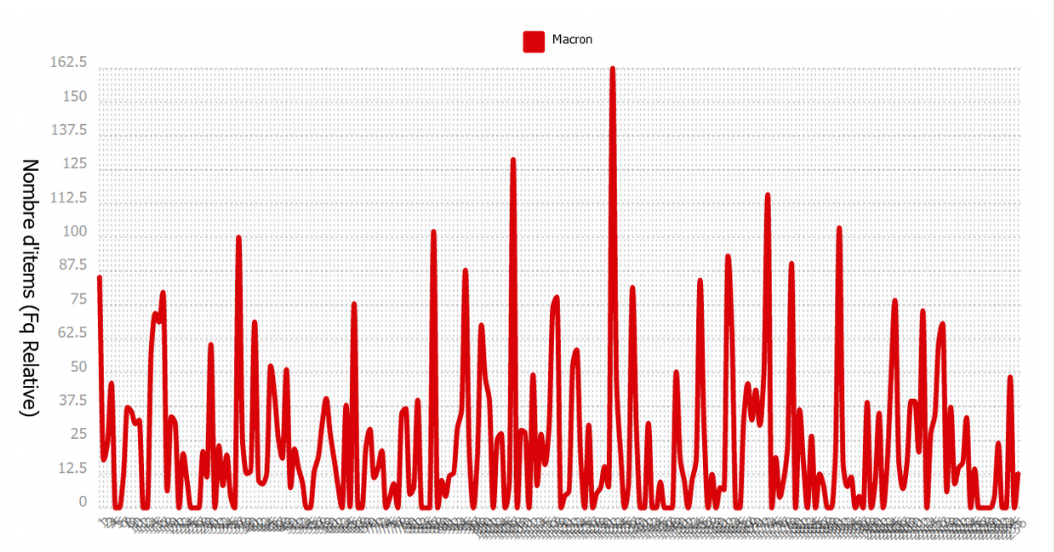
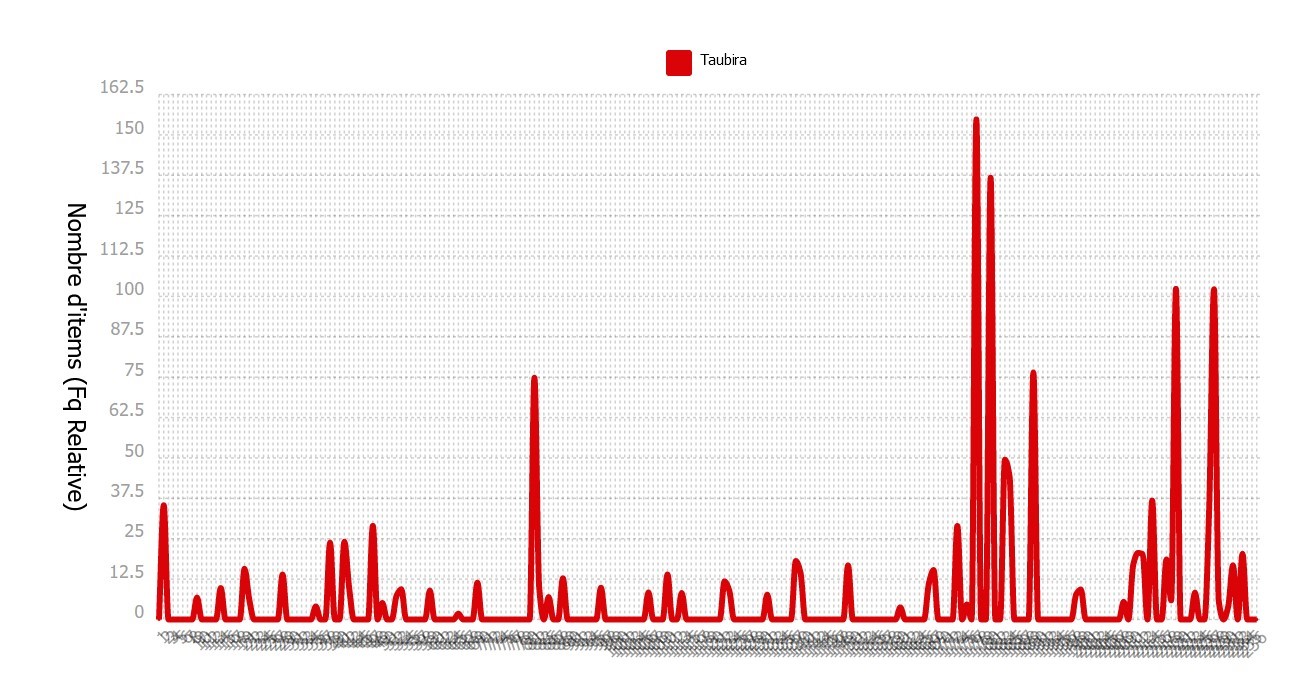
Lorsqu'on compare leurs fréquences, ici les fréquences relatives, on peut voir la différence entre les deux candidats les plus cités et ceux qui se sont déclarés candidats plus tard. Pour 'Zemmour' et 'Macron', on voit qu'ils ont été cités de manière très fréquente tout au long du semestre, dans tous les articles, et non pas à un moment particulier. Si on compare avec 'Taubira', qui a annoncé sa candidature en décembre, on voit que les articles citant sont noms sont beaucoup plus présents à partir d'une certaine date.
 |
 |
 |
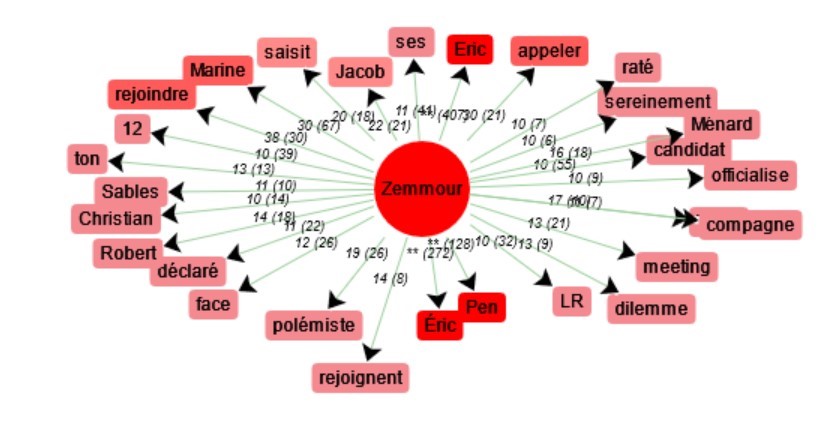
Pour tous les candidats, on peut regarder leurs cooccurrences : pour 'Zemmour', on voit une forte association de son nom avec celui de Marine Le Pen. On retrouve également le mot "polémiste", souvent utilisé pour le décrire. En revanche, 'Le Pen' est tout autant associée à Éric Zemmour qu'à Emmanuel Macron.
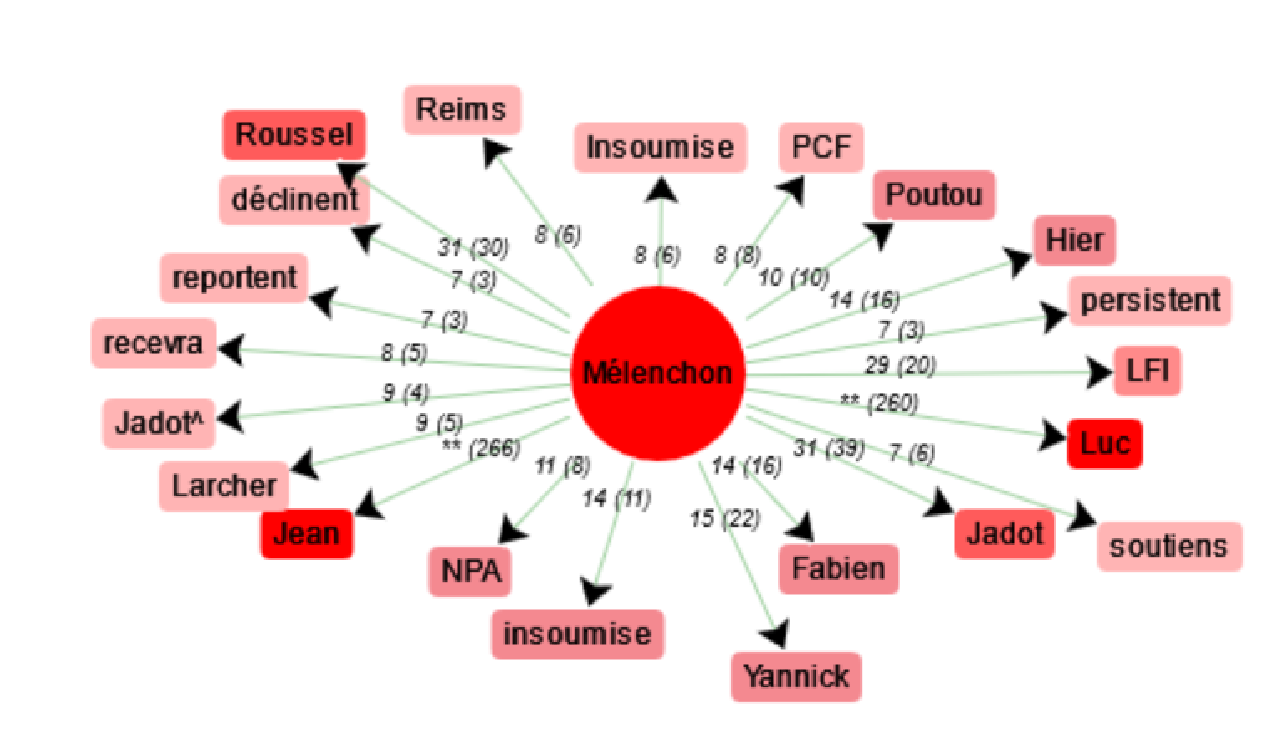
On peut alors comparer la cooccurrence de 'Mélenchon', dans laquelle on voit qu'il est cité avec des noms de personnalités et partis politiques de gauche.
Dans les cooccurrences, on peut aussi voir que les mots "élection" et "présidentielle" sont utilisés de manière quasi identique, puisqu'ils sont associés globalement aux mêmes mots.
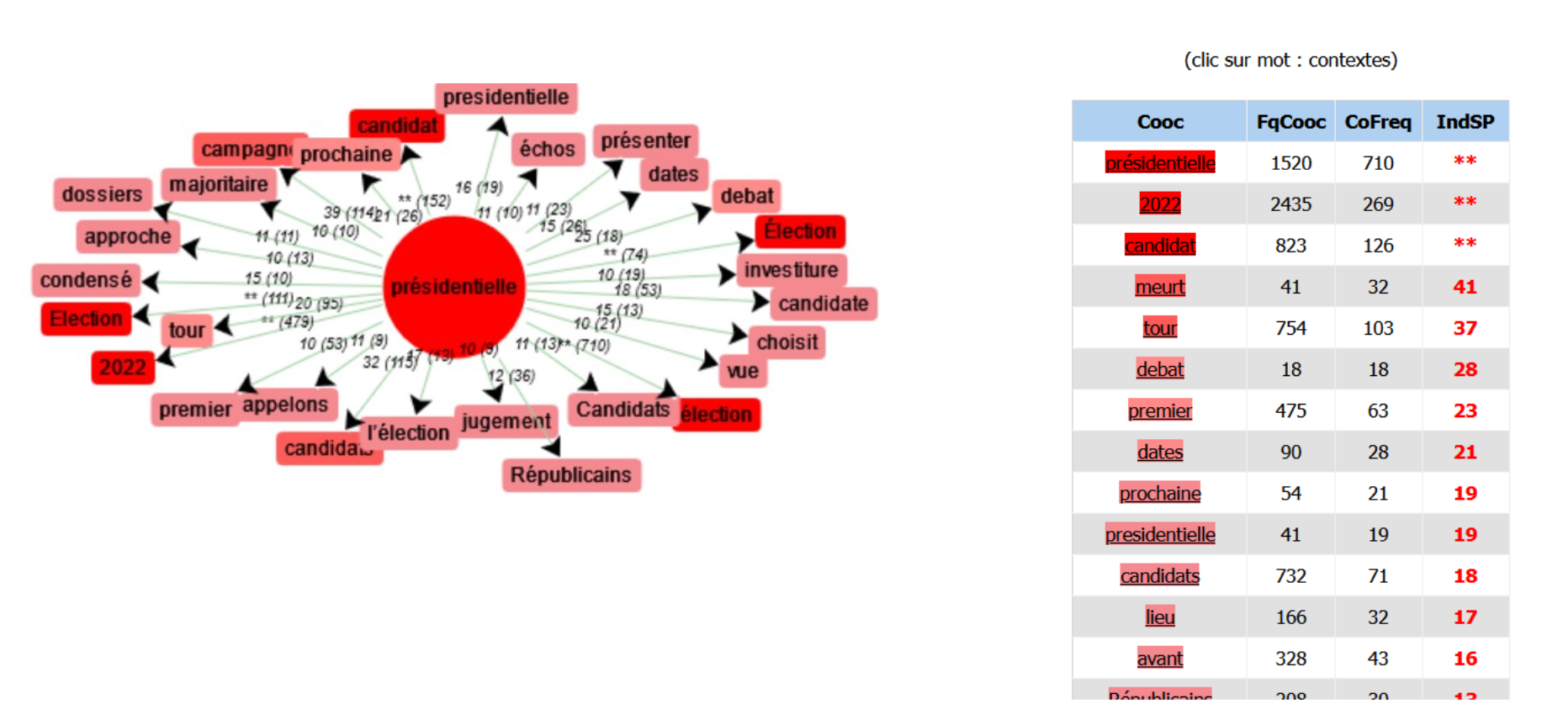
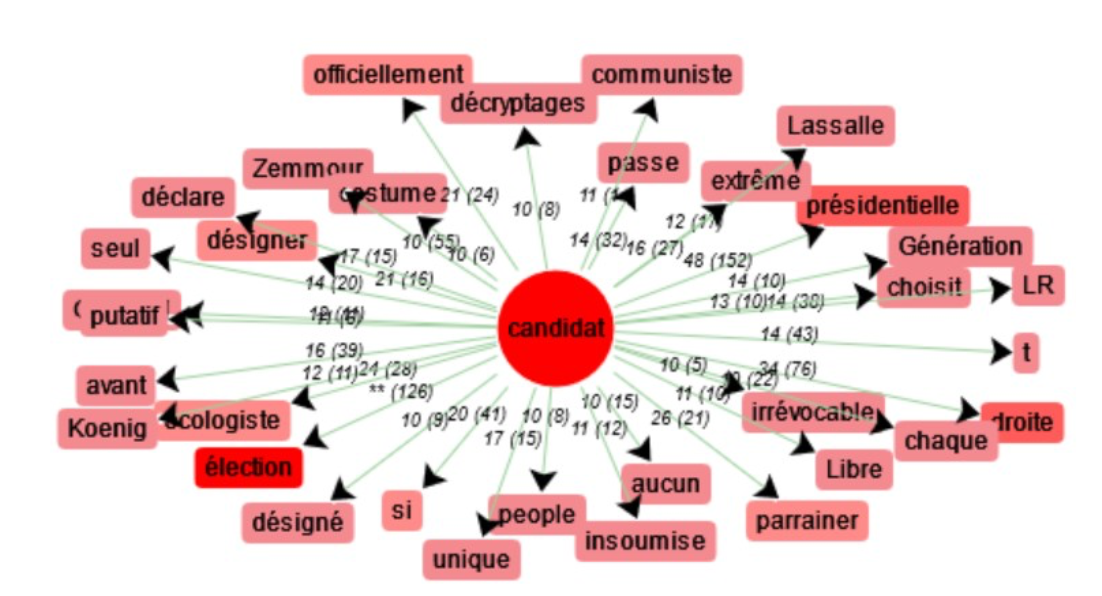
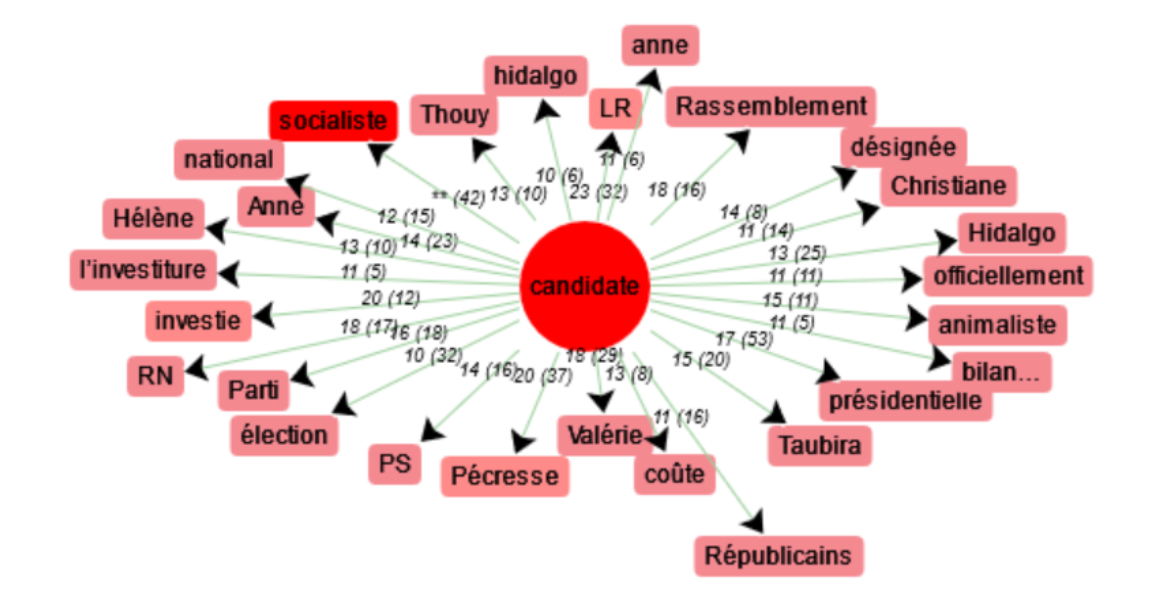
On peut également comparer les cooccurences des mots "candidat" et "candidate" :
Au masculin, le mot semble être plus associé à la droite, bien que l'on puisse voir les mots "communiste" et "insoumise". Le mot "droite" est lui-même présent, souvent utilisé dans la forumation "le candidat de (la) droite / d'extrême-droite".
Au féminin, on retrouve plus de noms propres, ceux des candidates à l'élection, et malgré la présence de "LR" et "RN", la tendance politique est plutôt à gauche, avec comme première cooccurrence, le mot "socialiste", qui est également utilisé dans la formule "la candidate socialiste".
Au pluriel, le mot est neutre et évoque globalement l'ensemble des candidats. On retrouve tout de même le mot "gauche", aussi utilisé dans les phrases telles que "les candidats de gauche".
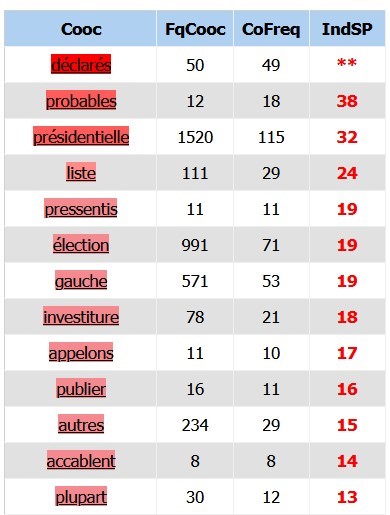
On retrouve des informations auxquelles on pouvait facilement s'attendre, comme le mot "avril" qui fait référence à la date des élections, (les dimanches 10 et 24 avril 2022), et le mot sondage, utilisé avec des formulations telles que "selon un nouveau sondage réalisé par l'institut...". On y voit également le mot "coude" qui est utilisé dans l'expression "au coude à coude" lorsqu'il est question des intentions de vote.
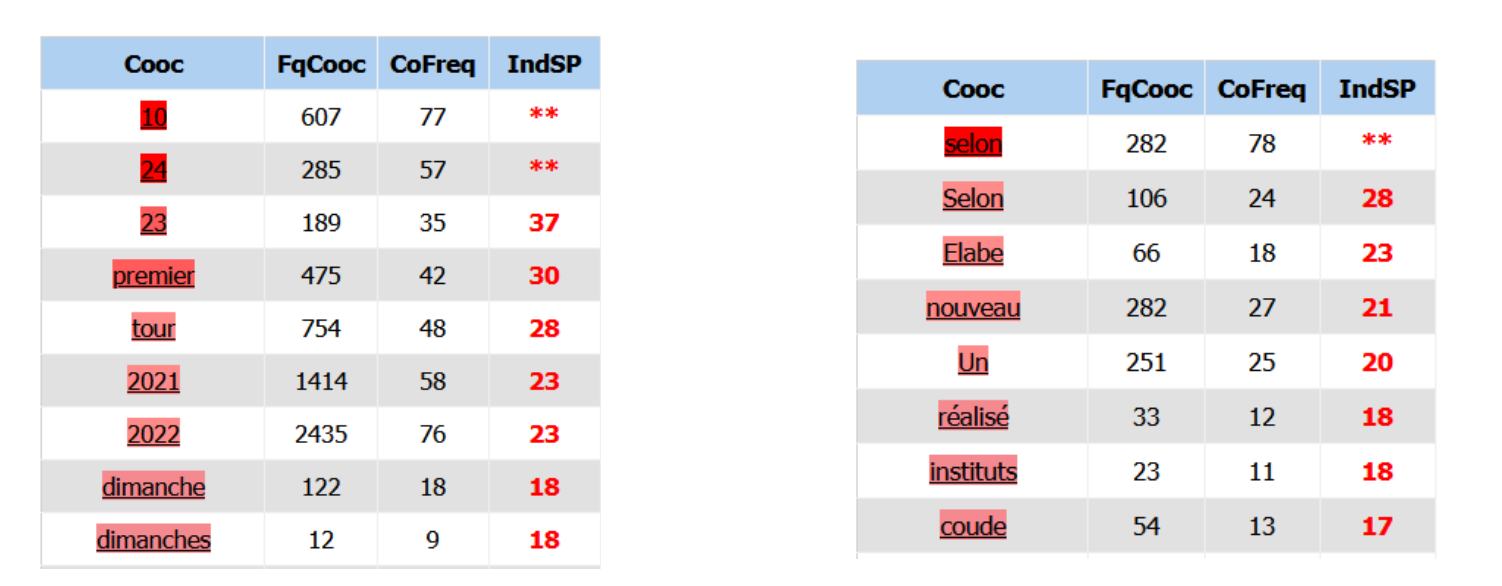
Sans surprise également, dans les segments répétés, on retrouve principalement sur toutes les premières pages des noms et prénoms de candidats, et différentes associations des mots "élection présidentielle 2022".
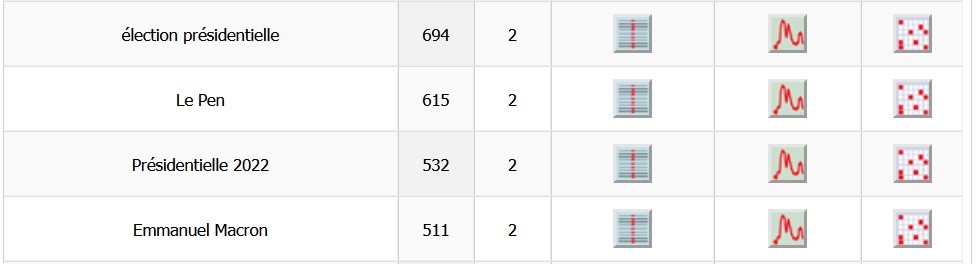
Chinois
Pour le corpus en chinois, nous avons également commencé par la vérification du chargement et de la structure du corpus.
Ensuite nous nous sommes penchées sur le dictionnaire pour regarder les mots les plus fréquents dans la partie chinoise. Comme dans les corpus anglais et français, ce n’est pas étonné de trouver les mots les plus fréquents comme « 法国 » (la France), « 总统 » (président), « 大选 » et « 选举 » (élection), « 2022年 » (l’année de 2022) et « 马克龙 » (Macron).
Encore une fois, « Macron » a apparu plus que « Le Pen » et « Zemmour ». Nous avons regardé la concordance de « Macron » pour avoir le cœur net.
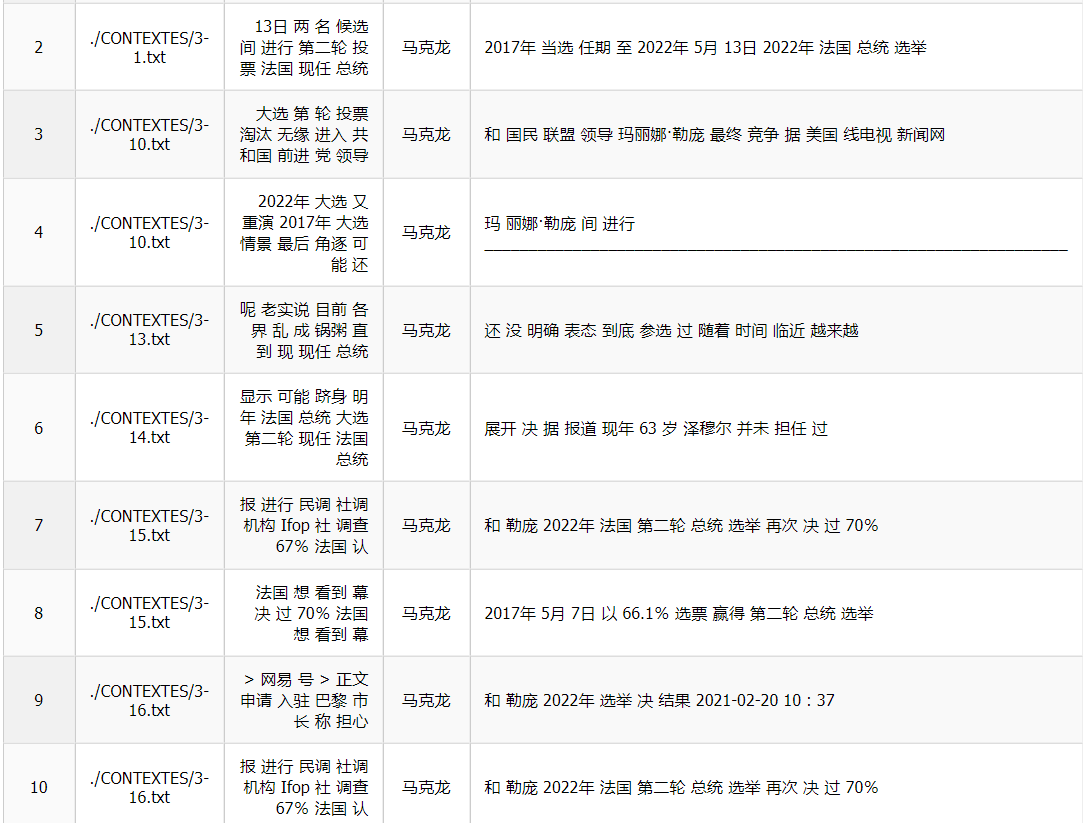
Nous avons constaté que « Macron » a été mentionné à la fois comme le président actuel de la France qui pouvait apparaître tout seul dans le corpus et comme le candidat pour l’élection présidentielle de l’année 2022 qui a souvent apparu avec le nom des autres candidats.
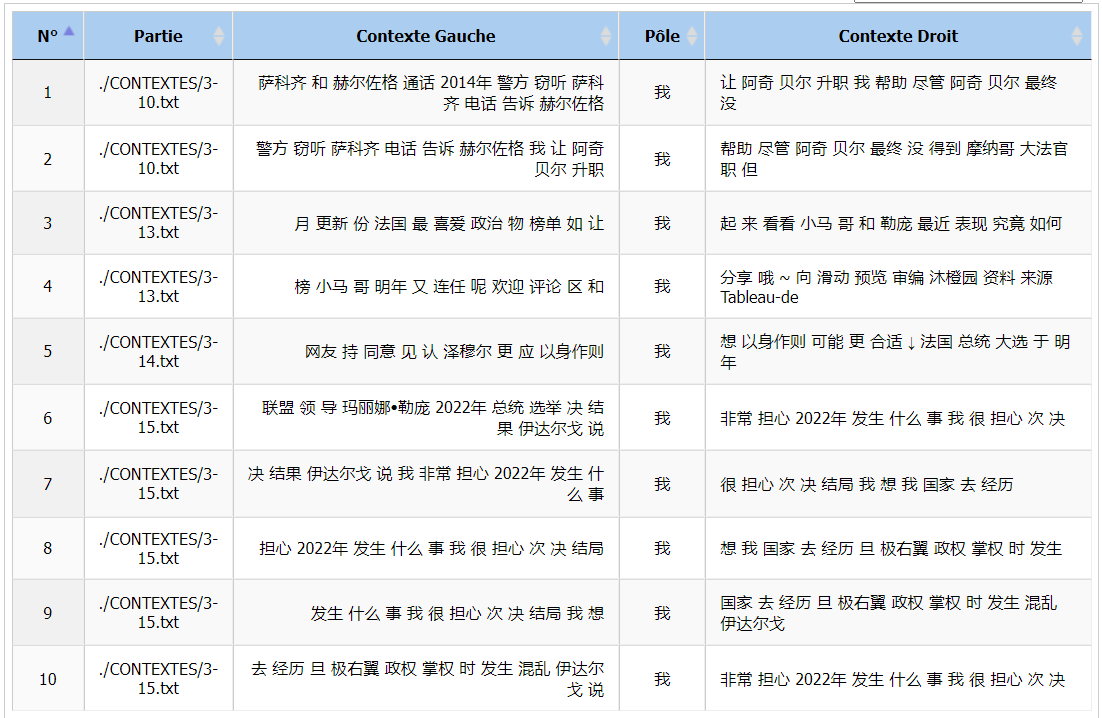
Nous avons remarqué que « 我 » (je/moi) faisait aussi partie des mots les plus fréquents et nous avons décidé de regarder les contextes de ce token. « 我 » dans le corpus a souvent apparu dans les discours directs qui sont moins utilisés dans les corpus anglais et français.
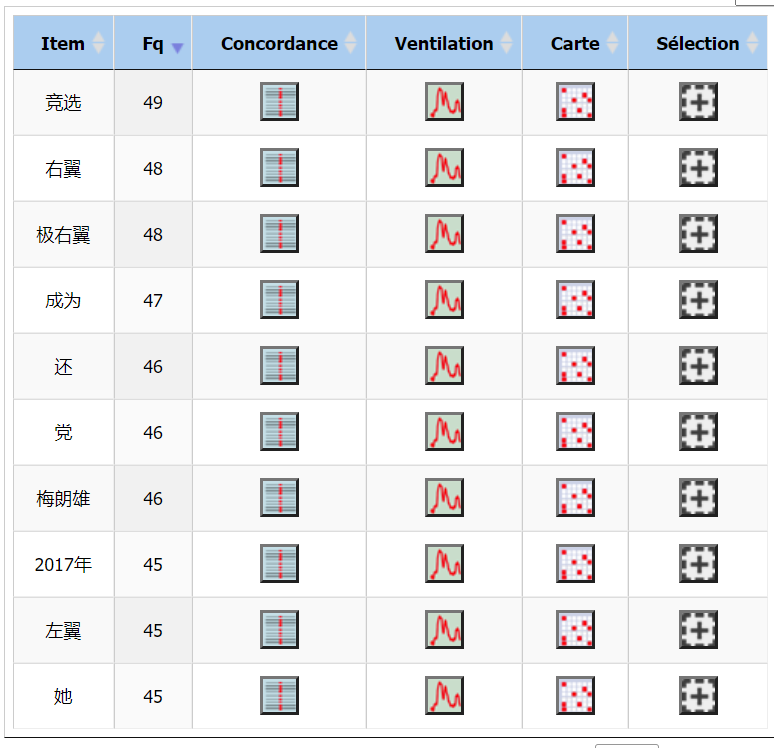
Comme dans les corpus en anglais et en français, nous avons trouvé les items fréquents sur les partis : « 右翼 » (la droite), « 极右翼 » (l’extrême droite), « 党 » (parti), « 左翼 » (la gauche)...
Dans l’onglet “SR/Patron”, l’opération “segments répétés” nous permet d’obtenir les segments répétés du corpus selon leur fréquence absolue. Dans le corpus chinois, nous avons constaté des segments intéressants : « 小马哥 » (frère Xiao Ma) qui est un surnom amical souvent utilisé par les chinois pour indiquer le président de la République française. Quand les médias chinois utilisent ce surnom, nous supposons que leur attitude envers Macron est plutôt positive et qu’ils ne sont probablement pas les médias officiels.
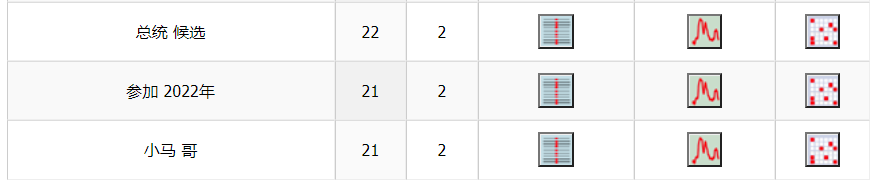
Voilà les cooccurrents du pôle « 选举 » (élection). Le plus fréquent est l’item « 总统 » qui veut dire « président » (nom) ou « présidentiel » (adjective) en chinois. Nous pouvons voir aussi « 2022年 » (l’année de 2022) , « 过程 » (processus), « 背景 » (contexte), « 播报 » (diffusion/diffuser), « 4月 » (Avril), « 第二轮 » (le deuxième tour), « 大区» (région), « 市镇 » (municipalité)... tout comme dans notre analyse en nuages de mots. D’après ces mots, nous supposons que les médias chinois se focalisent plutôt sur comment déroulera l’élection, puisque le processus de l’élection présidentielle en France n’est pas pareil que celui en Chine et que le peuple chinois s’intéresse au déroulement de l’élection.
 |
 |
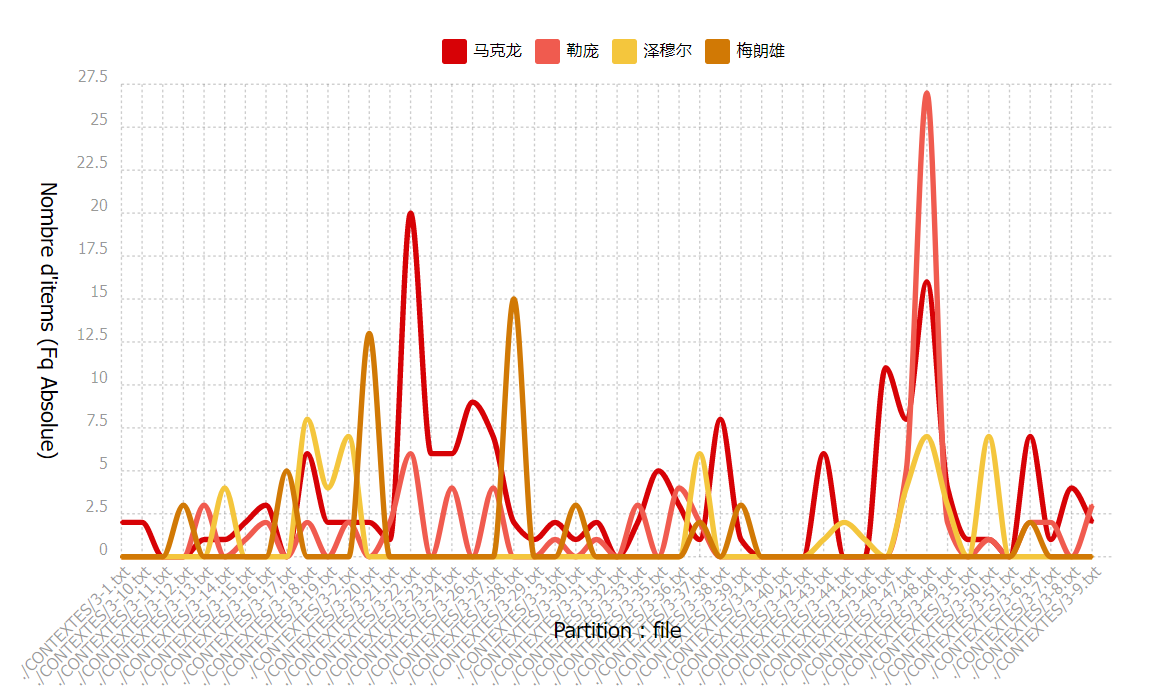
Un graphique de ventilation nous permet de visualiser la fréquence d’un ou des pôles choisis dans le corpus. Voilà le graphique de ventilation des pôles « 马克龙 » (Macron), « 勒庞 » (Le Pen), « 泽穆尔 » (Zemmour) et « 梅朗雄 » (Melenchon).
 |
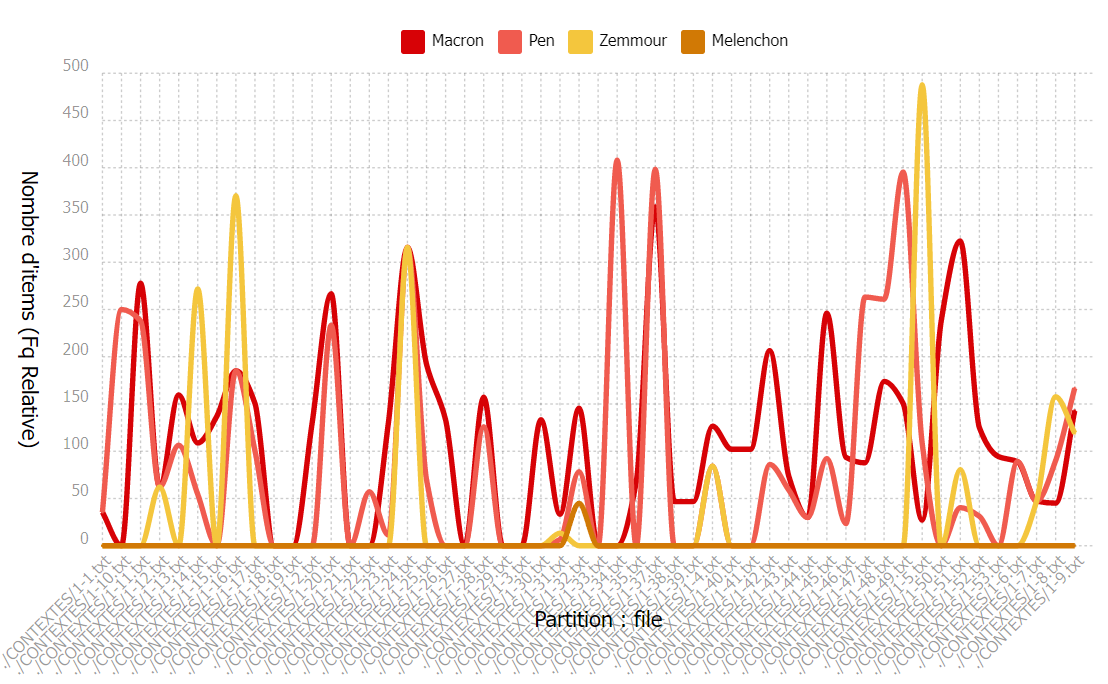 |
Selon le graphique de ventilation en fréquence absolue, nous avons remarqué que Macron est mentionné le plus par les médias chinois par rapport aux autres candidats, et Marine Le Pen se place au deuxième rang, avant Zemmour et Mélenchon, tout comme les informations indiquées dans le dictionnaire. Nous avons constaté la même tendance dans les deux graphiques pour le corpus en anglais.
Vu que la taille des textes est différente, il semble plus pertinent de regarder le graphique de ventilation en fréquence relative. Le nombre d’occurrences des items dans la partie est mis en rapport avec la taille des textes.
Conclusion
En conclusion, on peut voir que la majorité des hypothèses se sont révélées vraies. Il n'y a pas vraiment eu d'éléments inattendus lors de l'analyse, la majorité des mots et segments répétés les plus fréquents étaient des noms de candidats ou mots en rapport direct avec l'élection. Contrairement à une hypothèse, les candidats n'avaient en fait jamais leurs noms associés aux chiffres des sondages.
De même, aucun mot exprimant de réelle subjectivité n'est ressorti dans les analyses. En chinois, la présence du mot "je/moi" aurait pu montrer l'expression d'opinions, mais il est uniquement contenu dans des discours rapportés. Il semble qu'aucune page web dans aucune des langues n'utilise d'éléments de langage exprimant directement un avis sur les candidats ou leur programme par exemple.
L’occurrence chronologique des noms des candidats a été moins visibles que ce à quoi nous nous attendions. Cela est probablement la conséquence d'un des problèmes rencontrés dans l'analyse de notre corpus : les textes n'ont pas été assez bien nettoyés. En effet, beaucoup d'informations provenant d'autres articles et autres informations présentes sur la page sans rapport avec le texte visé sont restées dans les fichiers de l'analyse, et les autres titres sont considérés comme faisant partie de l'article que nous récupérons.
Cela a mené à différents problèmes, par exemple, en français, on trouve le mot "meurt" parmi les plus utilisés avec le mot "élection" à cause d'une seule page web qui répétait le titre de son article "que se passe-t-il si un candidat meurt avant l'élection ?" à de nombreuses reprises. De même, en utilisant les tout derniers fichiers concaténés, on voit que "Macron" est en cooccurrence forte avec le mot "emmerder", simplement de par les articles toujours récents proposés sur les pages, et qui sont différents à chaque fois que l'on télécharge la page. On a également pu trouver une forte fréquence du mot "covid" en français, indépendamment des dates de publication des articles, mais ne l'avons pas utilisé dans l'analyse car il est probable qu'il ne fasse en réalité pas toujours partie de l'article principal.
Les corpus ne sont pas de tailles équivalentes, cependant nous pouvons tout de même comparer l'occurrence des mots proportionnellement. En français, on a vu que les mots "droite" et "gauche" étaient utilisés aussi fréquemment l'un que l'autre. En anglais, on voit que "right" est bien plus fréquent que "left", mais cela est simplement dû aux différentes significations de "right". On peut donc estimer qu'il n'y a pas de différence notable concernant la fréquence des noms communs en rapport avec les élections. On voit aussi que le mot "Europe" est parmi les mots les plus fréquents en anglais, on estime que c'est un des sujets les plus abordés dans les articles anglais, contrairement aux articles français et chinois.
La différence entre les langues se trouve dans la fréquence des candidats : là où ils sont variés en français, on n'en voit presque exclusivement que trois en anglais et en chinois. Pour le français, c'est Zemmour qui est majoritairement présent, puis Macron suivi de Le Pen. En anglais et en chinois on a d'abord Macron, puis Le Pen, et Zemmour bien plus loin. Ces informations semblent logiques, puisqu'on remarque également qu'en anglais et en chinois, le mot "2017" est beaucoup plus ressorti qu'en français, où il n'était pas du tout fréquent. 2017 est l'année des dernières élections présidentielles en France, lors desquelles Macron et Le Pen étaient au second tour. Il semble alors qu'en français, les articles se concentrent sur les actualités des candidats à la présidentielle de 2022, là où en anglais et en chinois on évoque la prochaine élection par la rétrospective de la précédente.