Analyses sur lancsbox en fonction des langues :
Nous avons décidé d’explorer un autre outil qui permet lui aussi de faire des analyses textométriques sur des données en .txt : lancsbox. Voir ici pour plus de détails.
Il s’agit d’un logiciel développé par l’Université de Lancaster qui :
- Permet de travailler avec des corpus existants (téléchargeables en anglais) ou avec ses propres corpora (à l’aide de l’onglet « corpora »)
- Supporte des analyses textométriques dans beaucoup de langues différentes
- Annote automatiquement les données brutes avec leurs catégories grammaticales
Il intègre sept outils différents qui permettent de faire plusieurs types d’analyses sur un mot pôle ou plusieurs mots pôles recherchés :
KWIC (Key Word In Context) : il permet de rédiger un concordancier, c’est-à-dire un tableau avec les contextes plus ou moins larges
-GraphColl : il permet d’afficher sous forme de graphe les collocations
-Whelk : il calcule la fréquence absolue et la fréquence relative du terme souhaité et sa répartition dans le corpus. Il reprend aussi le contexte produit avec KWIC
-Words : il permet de faire des analyses plus précises sur les fréquences des mots, des lemmes et des catégories grammaticales aussi sous forme de graphe
N-grams : il permet d’analyser les bigrammes et les trigrammes
Text : il permet d’aller plus en profondeur en ce qui concerne le contexte jusqu’à l’affichage de la totalité d’un fichier indiqué
-Wizard (new!!) : il permet de produire aisément des rapports personnalisés exploitables en format .docx ou .html avec les outils présentés
Une autre fonctionnalité (disponible pour tous les outils mentionnés) que nous avons trouvée très intéressante et pratique pour nos objectifs d’analyse, est la possibilité de rechercher plusieurs termes à l’aides des expressions régulières.
 |
Ici, par exemple, on voulait rechercher les termes « università » et « Università » suivi de n’importe quel caractère (par exemple : università?, università’’, università’) puisqu’en italien il n’y a pas d’espace après un mot et avant les signes de ponctuation.
Pour plus d’informations, il est possible de télécharger le manuel et avoir accès à des vidéos explicatives très claires via ce lien ou en lisant ce court article.
Nous avons trouvé ce logiciel réellement riche et complet, avec une interface relativement simple à utiliser si on tient compte des nombreuses fonctionnalités qu’il présente. Nous n’avons pas réussi à expérimenter et à utiliser tous les outils disponibles. Pour le moment, nous nous sommes arrêtées au niveau basique. Cela a néanmoins été une très belle occasion de découvrir un nouvel outil intéressant dont on approfondira sûrement la connaissance et les fonctionnalités par la suite.
Voici quelques exemples de recherche et analyses possibles dans nos différentes langues d’étude :
Nous avons choisi d’utiliser uniquement les fichiers avec les contextes et non les fichiers avec les dump-text.
NB : Lors du téléchargement des corpora, il est important de ne pas charger le fichier qui contient les différents fichiers concaténés (celui utilisé pour les analyses avec Itrameur), mais de charger les fichiers individuellement. Sinon, certaines analyses ne seront pas valides puisque dans le cas du fichier concaténé, il sera considéré comme un seul grand fichier et pas un ensemble.
### Nous vous invitons à zoomer sur nos graphes pour ne pas perdre la vue :) ###
KWIC :
Voici des exemples de recherches en contexte avec nos mots :
- (italien) « università », « scuola »
 |
- (anglais) « covid », « Covid », « covid-19 », « Covid-19 », « COVID », « COVID-19 »
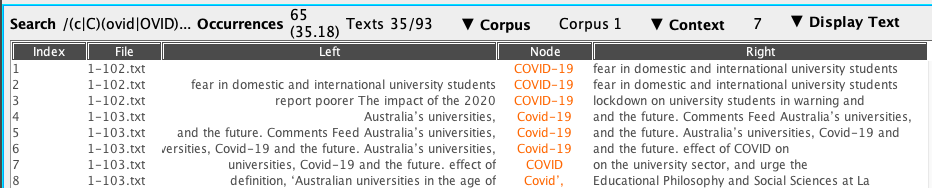 |
- (anglais) mots qui finissent par « emic » comme « epidemic », « pandemic »
 |
- (mandarin/chinois) « 大学 »|« 高校 »
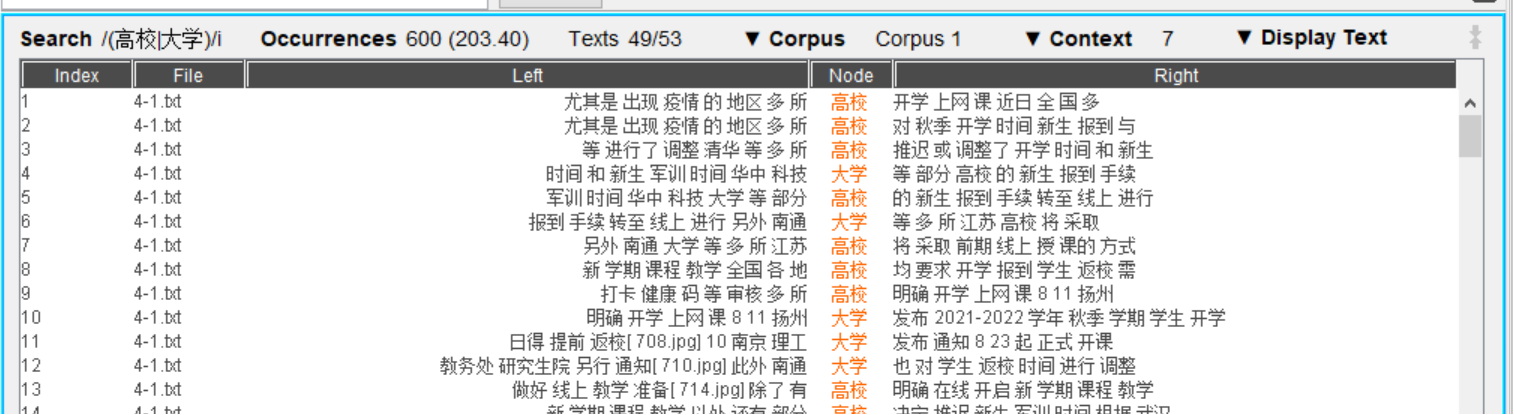 |
GraphColl :
Voici des exemples de collocations :
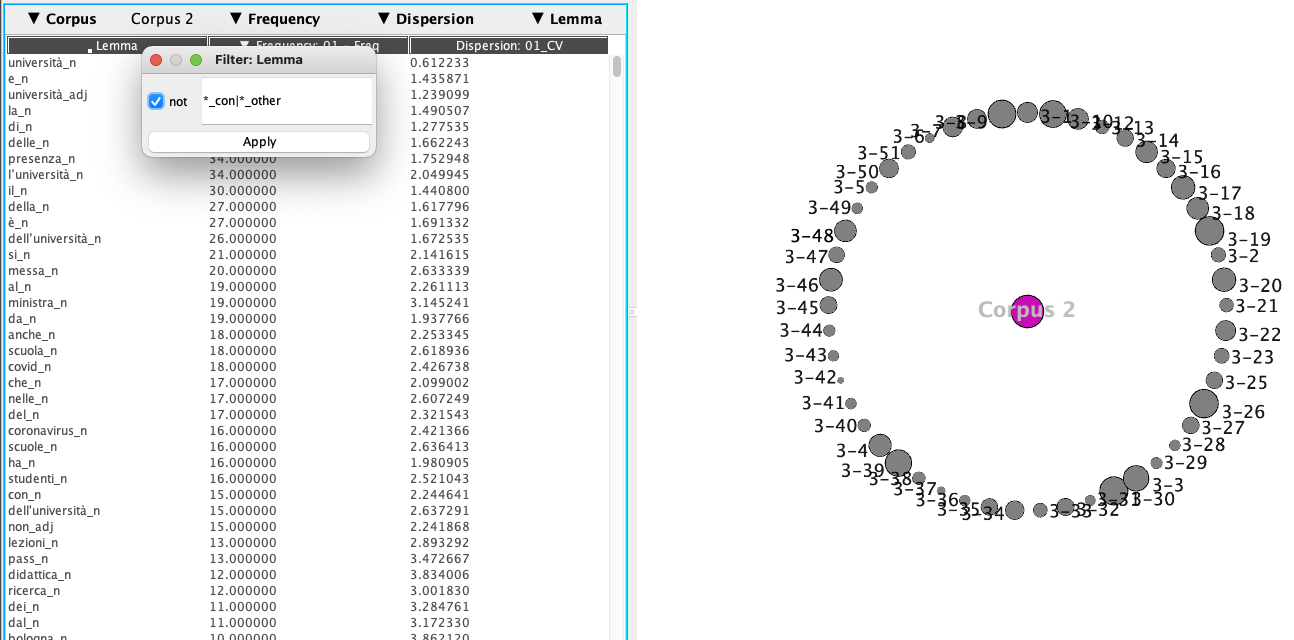
- (anglais) du mot « university » après avoir appliqué un filtrage nécéssaire pour rendre le graphe lisible : Dans le dernier onglet en haut à droite, nous avons choisi « lemma » qui permet d’afficher dans la colonne « collocate » les lemmes accompagnés par leurs catégories grammaticales (forme= lemma_POS). Nous avons donc appliqué un filtre en cliquant à droite sur la colonne « & » en disant que nous ne voulons pas (cocher la case « not ») afficher dans le graphe tous les lemmas (*)qui ont comme catégorie grammaticale « other » ou (|) « con » (conjonction) = *_other|*_con. Dans la colonne « Freq (coll.) » nous avons spécifié que nous voulions dans le graphe uniquement les termes qui ont une fréquence supérieure à 50.
 |
- (italien) des mots « università » et « Università » unis à celui des mots « scuola » et « scuole » :
 |
- (italien) À l’aide de lancsbox nous avons voulu proposer une analyse sur les termes étudiant/étudiants en italien sur la base de la même analyse proposée sur iTrameur avec le français : Voici les résultats pour l’italien « studente » (étudiant) et « studenti » (étudiants) en ayant éliminé de la liste des collocations les prépositions et les conjonctions.
 |
On remarque la présence de mots très techniques comme « personale », « studio » (étude), « casa » (maison), ou encore « accademico » (académique) et « universitario » (universitaire). Il s’agit de termes très liés au monde universitaire, au monde des étudiants, donc le résultat n’est pas du tout étonnant. Cependant, si on compare ce résultat à celui du français nous sommes frappées par le manque d’une thématique fondamentale : le bien être psychologique des étudiants. En effet, les termes concernant les besoins et les troubles psychologiques des étudiants ou les éventuels supports mis en œuvre pour faire face à la situation sont complètement absents, en quelque sorte cachés.
- (français) du mot « université » en excluant « other », « con », « prep », « cj » et en prenant en compte seulement les 20 premiers résultats de l’index (l’index général)
 |
- (chinois/mandarin) – « 大学 »/« 高校 »
 |
Dans la langue du chinois mandarin, les deux mots qui désignent université » ne s’écrivent pas du tout de la même manière, et en sachant qu’avec iTrameur, le mot « 大学 » est souvent lié avec les noms des universités, le graphe de ces résultats n’est pas intéressant pour savoir si sur lancsbox nous rencontrerons le même problème. Selon ce graphe et le tableau, nous pouvons observer que les résultats sont pareils que ceux d’Itrameur. Pour avoir un graphe lisible, nous avons fixé la valeur minimale de la fréquence à 15. Cependant, ayant eu des difficultés pour éliminer les ponctuations sur iTrameur, nous n’avons pas eu le même souci sur lancsbox, ce qui est un point avantageux.
Nous allons ensuite regarder les résultats du mot « 高校 ».
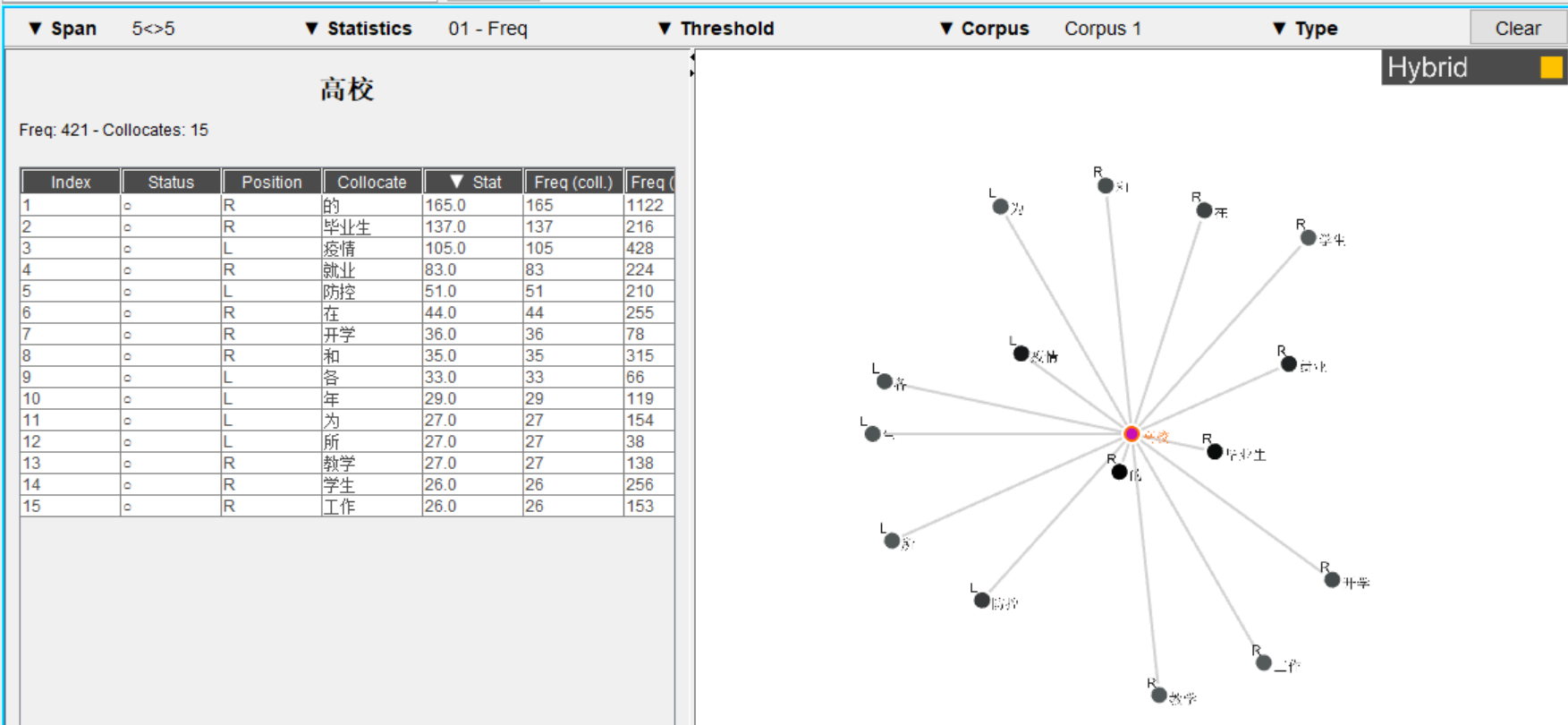 |
Pour ce deuxième mot, il a une fréquence plus haute, donc nous avons mis la fréquence minimale à 25.
Words :
Voici les fréquences des mots :
- (italien)
 |
Whelk :
- (italien) voici les résultats pour les mots « Università » et « università » : - Mots en contexte dans les textes en ordre croissant - Fréquences - (click sur le mot en orange) contexte large du mot
 |
 |
- (chinois/mandarin)
 |
Text :
- (anglais) Mot « university » en contexte sur un texte annoté avec les lemmas et les catégories grammaticales (onglet « display », selectionner « All annotation »)
 |
- (chinois/mandarin) – mêmes configurations
 |
N-grams :
- (français) les trigrammes ordonnés par ordre décroissant de fréquence : -Pour décider de la taille des n-grams, cliquer sur l’onglet « Grams » et sélectionner la taille souhaitée. -Si on recherche un ou plusieurs termes dans la barre de recherche qui s’affiche en haut, les lignes qui contiennent tels termes sont mises en évidence
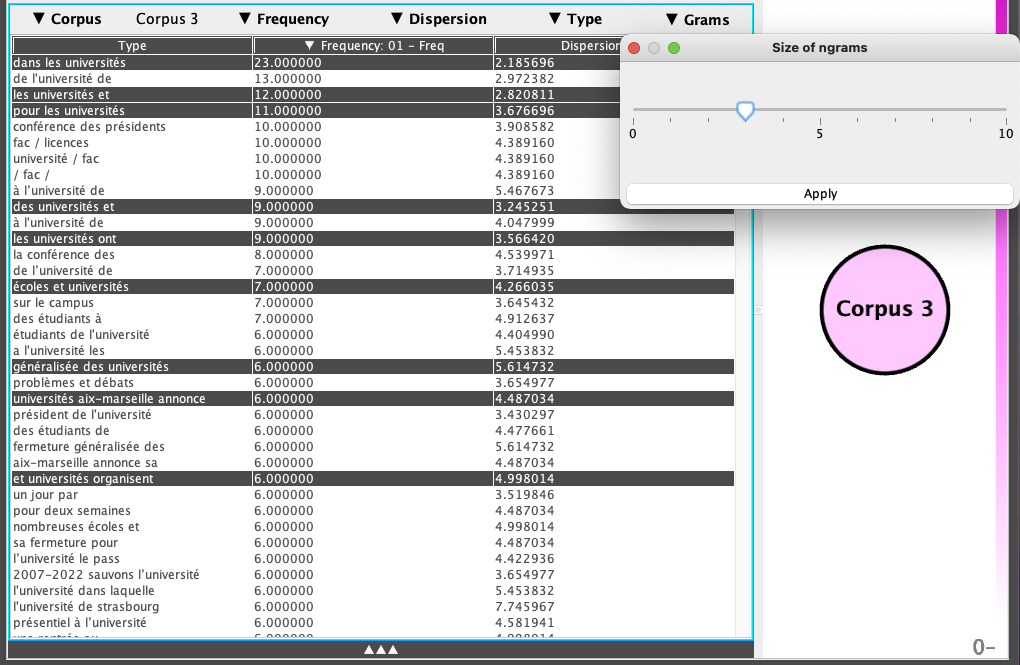 |
Pour avoir plus d’informations sur les motifs sans regarder les contextes annotés, nous avons décidé d’élargir la valeur jusqu’au 5 pour mieux comprendre le motif et son contexte. Voici les résultats du mot « 高校 ».
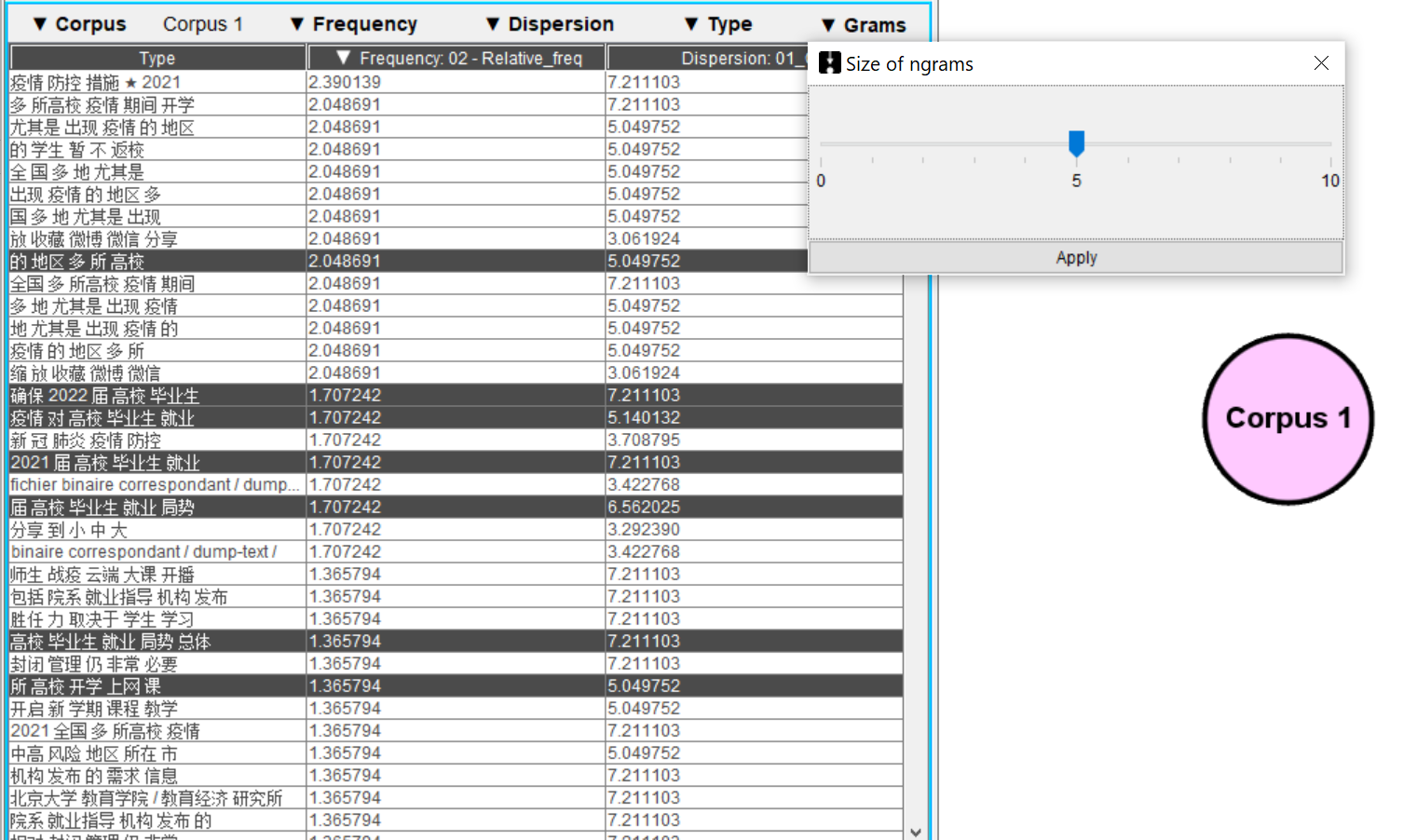 |
Wizard :
- (français) petit aperçu du "report" que nous avons créé automatiquement à l’aide de l’outil wizard en faisant les choix suivants :
 |
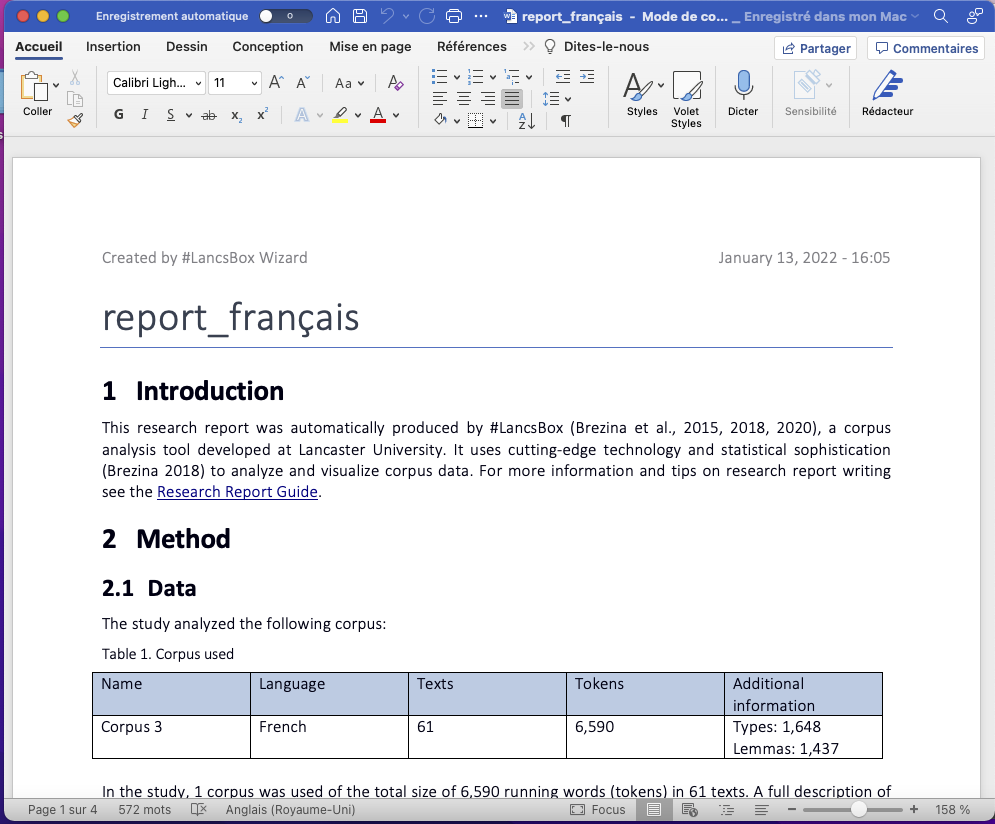 |
Pour conclure, les analyses proposées étant très similaires à celles faites sur Itrameur, nous avons obtenu des résultats proches de ceux obtenus précédemment pour chaque langue. Nous pouvons tout de même remarquer quelques variations en ce qui concerne les graphes des « collocations » donc les « cooccurrents ». Sur lancsbox, nous nous sommes limitées aux analyses des contextes et si nous comparons, dans le cas de l’italien par exemple, le graphique des cooccurrents fait avec iTrameur et celui fait sur lancsbox, nous pouvons voir que dans le deuxième cas, il y a beaucoup plus de résultats. Parmi ces mots, notre attention a été attirée par les termes « telematiche » (« à distance »), « coronavirus » et « didattica » (didactique) qui renvoient clairement aux mesures d’enseignement à distance pratiquement absentes dans les résultats d’iTrameur.
En outre, nous avons trouvé le retour au texte proposé indispensable pour des analyses textométriques et simple à effectuer sur lancsbox avec un rapide « click » sur le mot souhaité.
Analyser nos données avec un outil différent nous a donné la possibilité de découvrir un nouveau logiciel qu’il serait possible d’exploiter à l’avenir mais aussi de faire ressortir un autre point de vue à partir de nos analyses et surtout de nuancer nos positions et conclusions.