
extraction du texte
Objectif BAO1:
On veut récupérer automatiquement tout le contenu textuel (titre et description) de chaque item. Pratiquement, on va parcourir toute l'arboscence en cherchant les fichiers de la rubrique à laquelle on est intéréssé, on va traiter chaque fichier. On utilisera donc un appel récursif du programme soit en perl soit en python.
Voilà le script complet :
PYTHON script principal + PYTHON fonction recursive
Voilà les fichiers de sortie:
Les scripts commentés: PERL VS PYTHON
PERL:

PYTHON:

Parcourir l'arborescence des fichiers
Cette fonction en perl et en python permet de parcourir d'une façon recursive l'arborescence des fichiers présents dans le répértoire de fils RSS 2021.
En Perl on fournit à la fonction le chemin vers l'arborescence avec shift.Ensuite, on utilise opendir et readdir pour parcourir et lire l'arborescence.Grâce à une boucle foreach sur une liste contenante tous les éléments de l'arborescence on peut traiter chaque élément de l'arborescence (dossier et fichier) à la fois.
- S'il s'agit d'un dossier (if (-d $file)), on re-lance avec ce dossier en argument la même fonction (= voilà la puissance de la recursivité)
- S'il s'agit d'un fichier (if (-f $file)) on peut commencer le traitement d'extraction.
En Python la fonction apparaît plus courte, mais fait les mêmes actions. On fournit à la fonction non seulement le dossier 2021 à parcourir, mais aussi les fichiers de sortie, la rubrique et la liste vide pour éviter les doublons (tous ces arguments, sauf le dossier, seront passé à la fonction pour l'extraction. Comme en perl, aussi en python, pendant la boucle sur toute l'arborescence.
- Si on croise un dossier (if sub.is_dir()) on relance la fonction parcours avec ce dossier en argument.
- Si on croise un fichier (if sub.is_file()) on s'assure qu'il soit de type xml et qu'il contient le code de la rubrique à laquelle on s'intéresse. Dernièrement on lance la fonction pour le traitement de l'extraction.
PERL:

PYTHON:
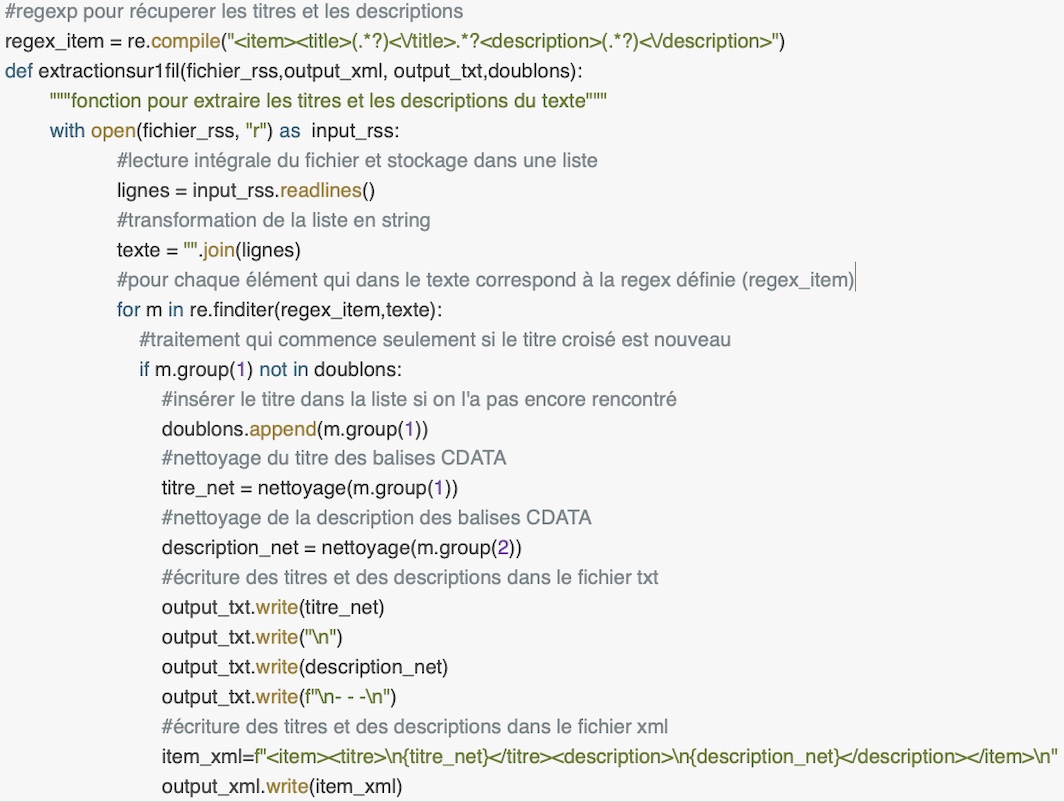
Extraction
Cette fonction en perl et en python permet de extraire le contenu textuel des titres et des descriptions.
En Perl on ouvre le fichier concerné et on le lit intégralement en le stockant dans une liste avec my $ligne=<\fichier_à_lire\>. Ensuite pendant une boucle foreach sur la liste crée, on extrait les contenus textuels des lignes qui correspondent à la structure décrite par la regex (balise item+balise title avec contenu textuel + balise description avec contenu textuel+balise item fermante). On controle que l'article soit traité pour la première fois afin qu'il n'y soit pas des doublons et on nettoye le texte des balises CDATA. Finalement on écrit ce qu'on a obtenu dans les fichiers de sortie txt et xml.
En Python la procédure est exactement la même. On lit et on stocke le contenu textuel dans une liste à laide de readlines et ensuite grâce à une boucle for sur la liste on extrait les lignes correspondantes à la regex définie précedemment à travers re.compile qui permet de stocker le pattern dans une variable. Seulement si l'article est nouveau, on extrait les deux contenus textuels à l'aide de m.group et ensuite on les nettoye des balises CDATA. Finalement on remplit le fichier txt et xml.
PERL:

PYTHON:

Nettoyage du texte
Cette fonction en perl et en python permet de nettoyer le contenu textuel extrait (titres et descriptions) des balises <\![[CDATA]]\> qui interfèrent. Il s'agit d'une sorte de commentaire dont le contenu textuel, à cause de la présence des balises, n'est pas pris en compte par le parser.On substitue aussi les "&" avec des "E" parce que ces éléments pourront poser problèmes dans la création des fichiers en XML.
En Perl on fournit à la fonction deux arguments: le contenu des titres et des descriptions.Ensuite, on utilise les regex et la fonction de substitution s/expression_initiale/expression_changée/ pour nettoyer.
En Python on nettoye de la même manière. On donne à la fonction le texte qui est ensuite nettoyé grâce à re.sub(expression_initiale,expression_finale,où l'appliquer)
Les autres rubriques :
International - 3210
perl-TXT (3208) perl-XML (3208)
python-TXT (3208) python-XML (3208)