
Le Projet
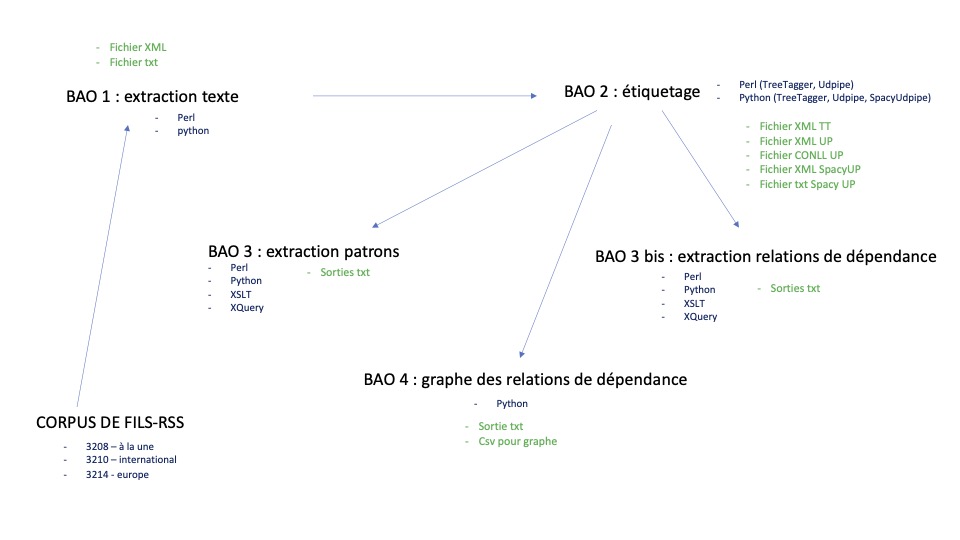
(en bleu les outils pour le traitement, en vert les sorties)
Read-me :
Ce site ressemble les 4 boîtes à outils produites dans le cadre du cours de Programmation et Projet encadré.Les programmes présentés ont été crées d'une manière collaborative pendant les séances avec M.Serge Fleury et M.Pierre Magistry. Ces programmes ont été ensuite améliorés et intégralement commenté avant d'être presentés sur le site. Il y a aussi des programmes inédits dont la création a été considérée nécéssaire pendant le processus de traitement pour aboutir un résultat optimal.
Après cette présentation générale, vous pouvez vous rendre dans la page principale où vous pouvez vous déplacer dans les pages dédiées aux différentes BAO.Dans chaque page vous trouverez:
- Une petite introduction à la BAO presentée
- Les scripts utilisés
- Le(s) fichier(s) d'entrée de la rubrique 3208 (à la une)
- Les fichiers de sortie de la rubrique 3208 (à la une)
- Explication détaillée des scripts centrée sur la comparaison entre perl et python (on expliquera seulement les parties les plus importantes du script, pour avoir une explication détaillée du programme entier il y a le script commenté!) (parfois il sera nécéssaire de zoomer un peu, ou plutot de télécharger le script complet!)
- Remarques événtuels sur les résultats obtenus
- Le(s) fichier(s) sortie d'autres rubriques
On a décidé de présenter les fichiers sortis d'autres rubriques en bas de page pour une consultation plus claire et lisible du site.
Ce qu'on va faire :
Le projet Boîtes à Outils, produit dans le cadre du cours 'Programmation et Projet encadré 2', est une chaîne de traitement textuel semi-automatique sur des données textuelles. Cette chaîne de traitement se déroule sur 4 étapes :
- on part avec l'extraction à partir du corpus des données.
- on étiquette les données textuelles extraites d'un point de vue morphosyntaxique à l'aide de TreeTagger et Udpipe
- Grâce à l'étiquetage fourni aux données textuelles, on peut extraire des patrons morphosyntaxiques choisis et des éléments en relation de dépendance.
- Finalement, on ajoutera une composante visuelle avec la réprésentation graphique des relations de dépendance à l'aide de Padagraph.
Le corpus de travail :
Fils RSS du journal Le Monde
Le corpus avec lequel on a travaillé est en soi une arborescence de fils RSS du journal Le Monde archivés une fois par jour à 19h00 pendant un an. Pour cette raison, les données sur lesquelles on a travaillées se réfèrent à l'année 2021.
NB: chaque fils RSS (fichier XML) de notre corpus est accompagné par un fichier HTML, crée pour compter les mots dans les fichier XML, et un fichier txt qui réprésente le fichier en entier. On n'est pas intéréssés à ces deux types de fichiers: on s'intéressera seulement au fichier XML.
... Mais c'est quoi un fils RSS?
Le format RSS (Really Simple Syndication) permet de décrire synthétiquement le contenu d'un site web dans un fichier structuré à l'aide de XML. Il est constamment mis à jour et il contient donc toujours les dernières informations émises. Pour cette raison, il s'agit d'un format utilisé par les journaux pour signaler les mises à jour.
Sa structure interne:
Chaque fils RSS a une structure dite arborescente (voir cours de documents strcturés!!):
- Élément racine appélé RSS.
- Channel: description permanente et générale du canal
- Titre du fils
- Link
- ... autres informations ...
- Item: chaque item décrit un article
- titre
- lien direct vers l'information
- description
- date et heure
Pour notre projet on s'intéressera seulement aux contenus textuels de titre et description des différents items.
Les rubriques
Les fils-rss de Le Monde comptent de différentes rubriques thématiques.On a décidé de traiter et analyser dans le quatre bào 3 de ces rubriques:
- à la une (3208)
- international (3210)
- europe (3214)
En effet, on pense qu'on pourrait faire des analyses intéressantes (surtout dans BAO3, BAO3bis et BAO4) sur ces sujets centrales du journal Le Monde.
Les outils :
Le traitement a été mis en place à l'aide de différentes langages de programmation :
- Perl
- Python
Et pour la BAO3 et BAO3bis aussi :
- XSLT
- XQuery
Tous les BàO sont écrites soit en perl soit en python.En effet, on voulait avoir la possibilité de comparer ces deux langages pour avoir un retour réel et pratique soit sur leurs résultats, soit sur les similarités et les différences de leur 'syntaxe'.En outre, étant déjà à l'aise avec python et ne connaissant pas encore le langage perl, le fait de pouvoir double-écrire les scripts nous a permis d'apprendre plus vitement le nouvel langage et developper nos connaissance de python
En ce qui concerne XSLT et XQuery, ils ont été proposées comme alternatives à python et perl dans la BAO3 et BAO3bis. On leur a dédié un projet entier dans le cadre du cours 'documents structurés' et il a été intéressant de voir une leur application pratique dans une chaîne de traitement semi-automatique et une comparaison pratique avec Python et Perl.