
des textes aux graphes
Objectif BAO4:
Avec la BAO4 on achève notre projet. Son objectif principale est la visualisation sous forme de graphe des relations de dépendance entre unités lexicales (extraites dans la BAO3bis). Padagraph, l'outil qui nous permettera de visualiser nos données sous forme de graphe a été mis en place par M.Pierre Magistry. Afin qu'il puisse construire le graphe, il est nécéssaire de lui donner un fichier csv où on va spécifier les sommets, les noeuds et les relations entre éléments léxicaux. On va donc mettre en place un script python en gré de filtrer et organiser les données d'une telle façon. Ensuite, on va envoyer le csv au serveur directement à travers le terminal avec la ligne de commande suivante: 'python BAO4.py | curl -X POST -H 'Content-Type: text/csv' --data-binary @- \"https://padagraph.magistry.fr/post_csv/annacolli-nsubj\" '. On changera à chaque fois le nom du graphe.Le script python qu'on présente ici complète les script présentés dans la BAO3bis. Comme pour la BAO3bis, on vous présentera d'abord le script dans sa version base et on dédiera une section dans la partie 'explication' pour les améliorations possibles. En effet, comme montre la première photo, le graphe sans aucun type de filtres est quasi illisible et très bruité.On vous présentera aussi un script très similaire dont la sortie n'est pas un csv mais un fichier texte. Ainsi on sera en gré de le comparer aux script python, XSLT et XQuery de BAO3bis.
Voilà le fichier en entrée:
Voilà les script python :
PYTHON script base - sortie csv pour Padagraph
PYTHON script base - sortie txt
PYTHON script amelioré - sortie csv pour Padagraph
Voilà les fichiers txt:
sortie txt - obj - internationa
sortie txt - nsubj - international
******************************************** Rendez vous aux graphes en bas de page! ******************************************************
Les scripts commentés: PYTHON

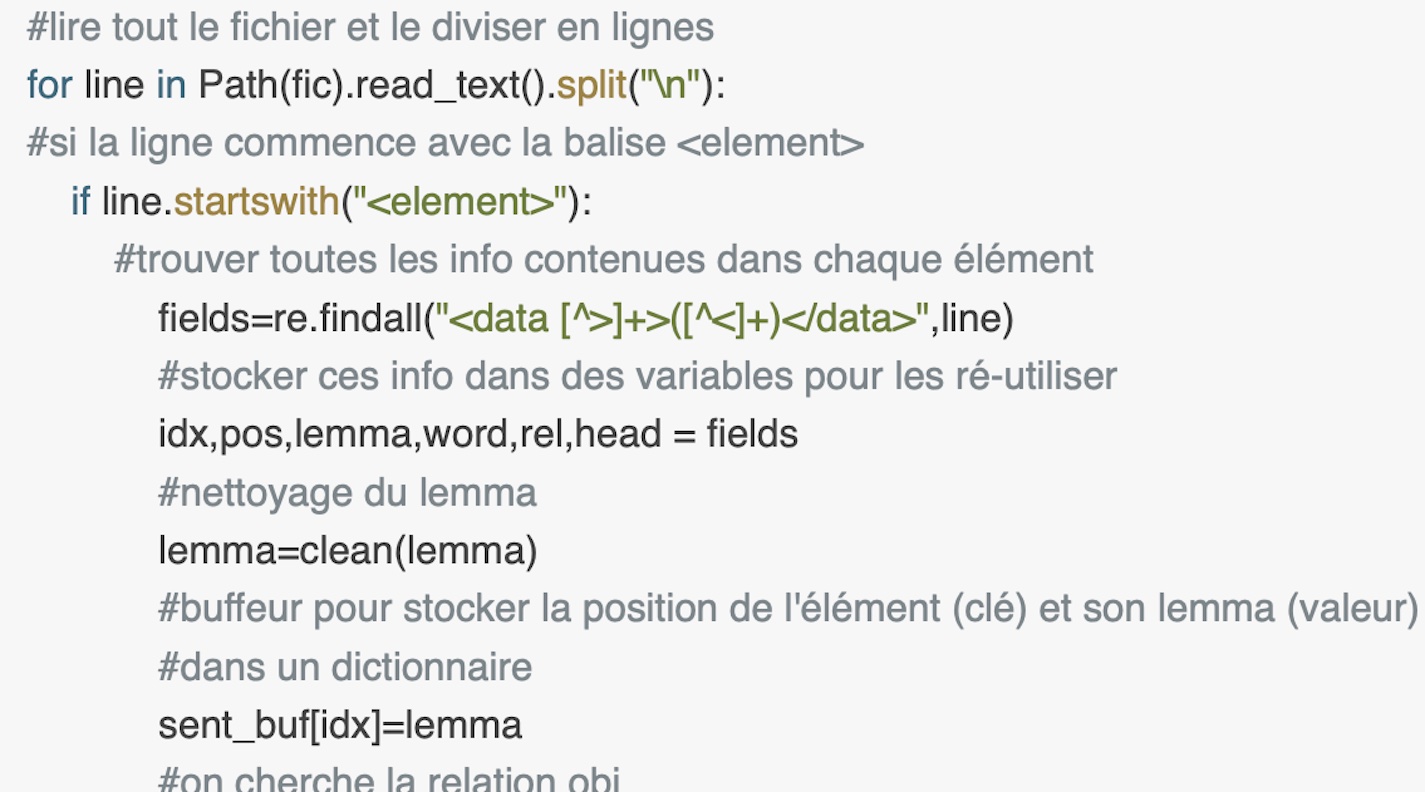


Script principal :
On commence par initialiser toutes les variables dont on aura besoin :
- 2 variables buffer (sent et obj) qui vont se vider à chaque tour de boucle et qui ont le role de 'entrpôt temporaire' pour les objets qu'on va répérer.
- La variable couple, de type set() (un ensemble de 'types') qui contiendra les couples dépendant-gouvernor.
- La variable gouvernors qui contiendra les gouvernors.
- La variable deps qui contientra les dépendants.
La dernière partie du programme est complétement dédiée à la sortie qui peut se présenter :- sous forme de CSV à envoyer au serveur padagraph - sous forme de txt.
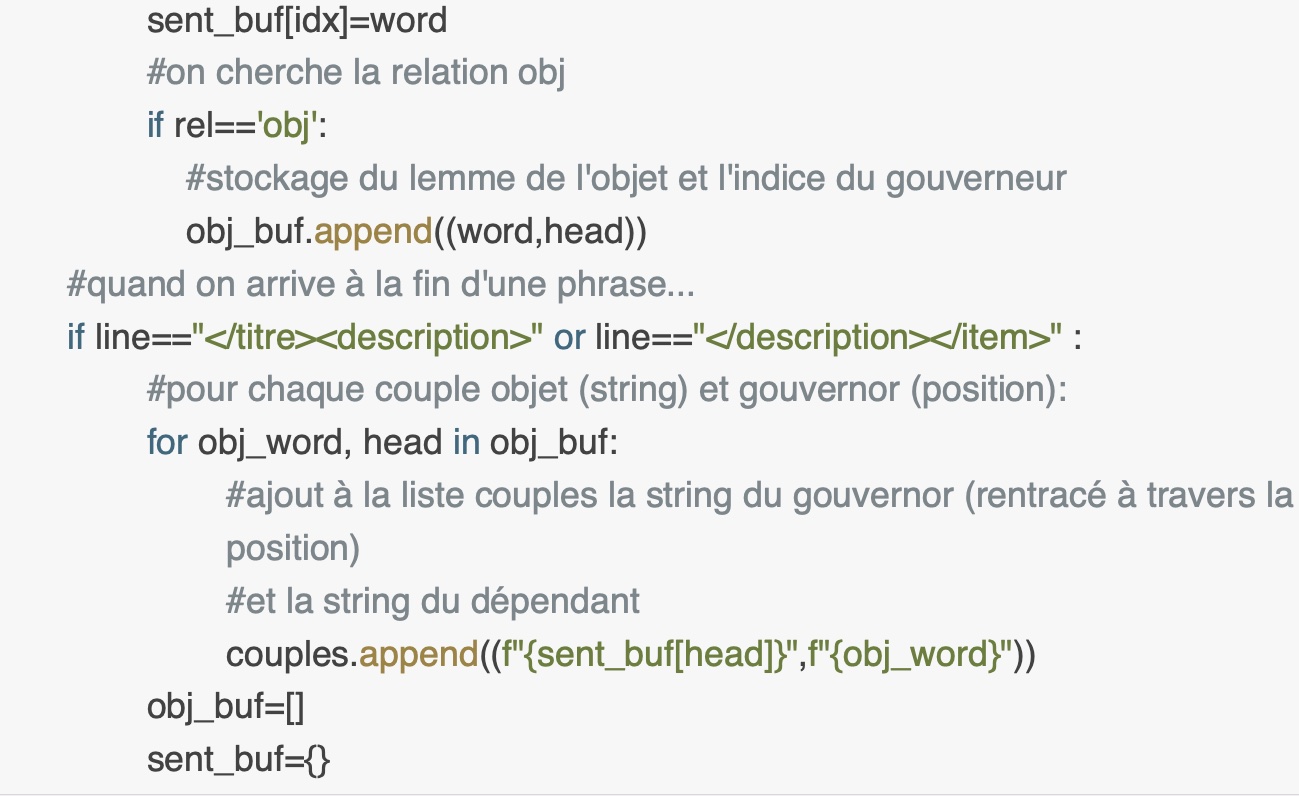
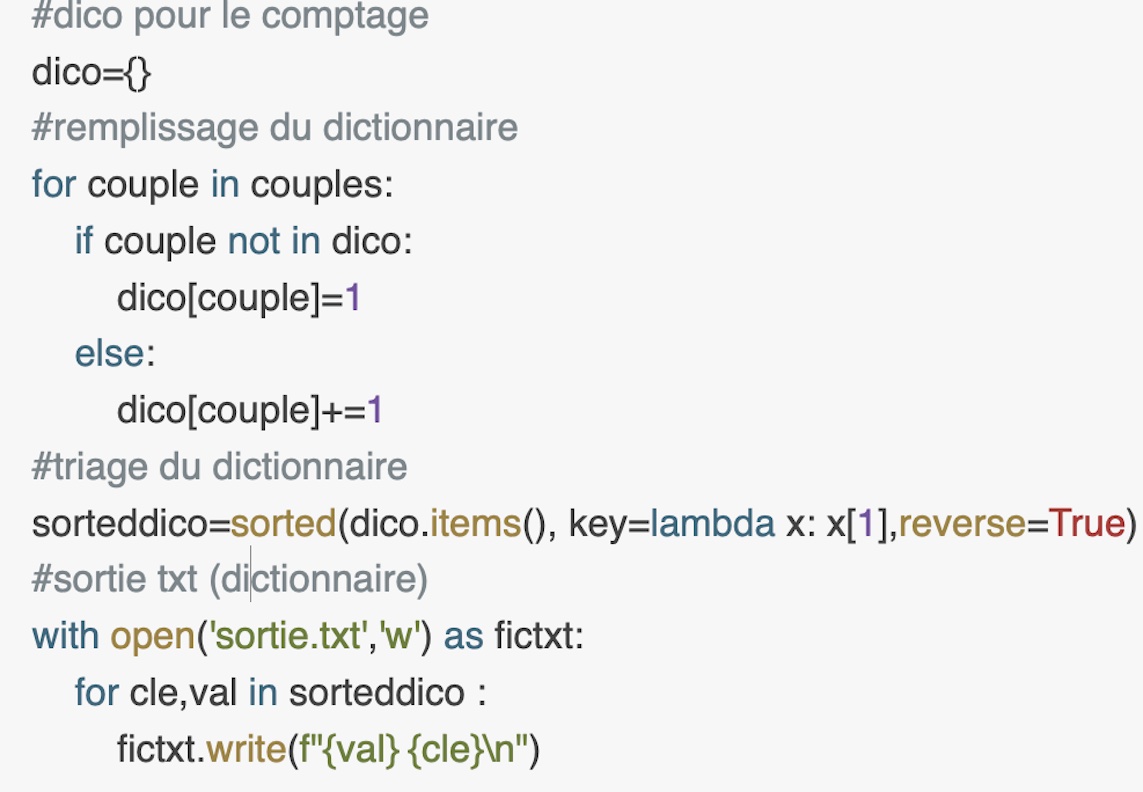
Sortie txt:
Pour la sortie txt est nécéssaire faire certains changements:- changer le type d'objet 'couples' en list: en effet, l'objet 'set()' est un ensemble et donc il prendre en compte une seule couple par type (et pas toutes les occurrences de chaque couple dépendant-gouvernor). En le transformant en list on pourra compter les occurrences de chaque couple comme en perl (modifier la fonction d'ajout d'éléments dans un set ('add()')en 'append()')- enlever les variables 'gouvernors' et 'deps' parce qu'on aura besoin seulement de la liste 'couples' pour la sortie.- changer 'lemme' avec 'word'. Pour avoir une sortie comparable à celle de perl, on s'intéressera à la string et pas au lemme.- enlever la fonction de nettoyage. Elle n'est pas nécéssaire pour une sortie txt et les mots seront plus lisibles.- enlever la sortie csv et ajouter une sortie txt.
Les images présentent les différences les plus remarquables de la sortie txt par rapport à la sortie csv pour le serveur. Il est possible de consulter la totalité du script au début de la page en cliquant sur le bouton.


Améliorations possibles
Pour avoir des résultats plus ciblés et des graphes plus lisibles, il est possibles de faire des améliorations et notamment des filtrer les éléments pris en compte.
En outre, sur padagraph on a la possibilité d'ajouter un poids aux relations selon leur fréquence d'occurrence. Les relations qui sont plus fréquentes auront un poids majeur par rapport à celles qui sont présentes une seule fois et le lien visuel sur le graphe sera moins éloigné plus le poids est grand. Pour définir le poids d'une relation on crée un dictionnaire avec tous les éléments de la liste 'couples' (transformée en liste, noter que dans le script 'base' elle est un set() mais vue que le set() est un ensemble on n'aura pas d'occurrences) comme clés (des tuples) et leur nombre d'occurrences comme valeur. Ensuite, dans la création du csv, en particulier dans le remplissage des case des 'relations' on ajoutera l'attribut 'weight' où on inserera la valeur du dictionnaire liée à sa clé. On pourra aussi ajouter un filtre en plus (comme on a fait dans certains graphes) pour faire afficher seulement les relations qui ont un poids supérieur ou inférieur à une valeur donnée.
Graphes obj:
à la une - général

Voilà le graphe des relations 'objet' sur la rubrique 'à la une'. On remarque des noyaux autour des jours de la semaine 'mardi', 'lundi'; ce résultat est attendu vu que dans cette rubrique toutes les nouvelles 'flash' sont ressemblées. Les autres termes présents sont très hétérogènes et différents, un autre indice de l'hétérogéneité des nouvelles qu'on retrouve dans cette rubrique.
Zoom : campagne et mesure
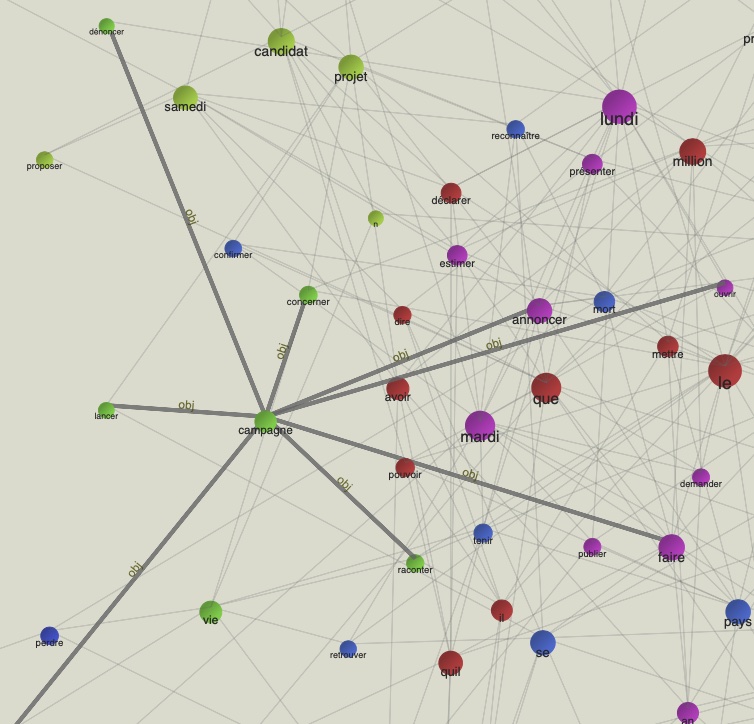
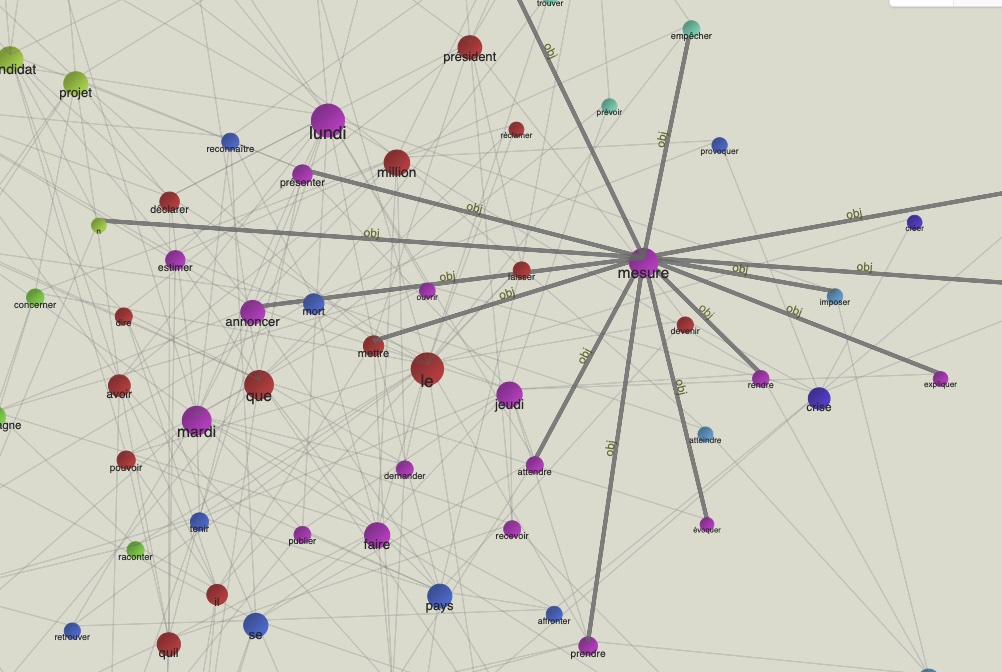
Voilà deux 'zoom' sur les noyaux 'campagne' et 'mésure', des mots clés de la période 2021 qui renvoient, le premier à les éléctions présidentielles d'avril 2022 et le deuxième à la situation pandémique et aux mésures sanitaires conséquentes.
International - général

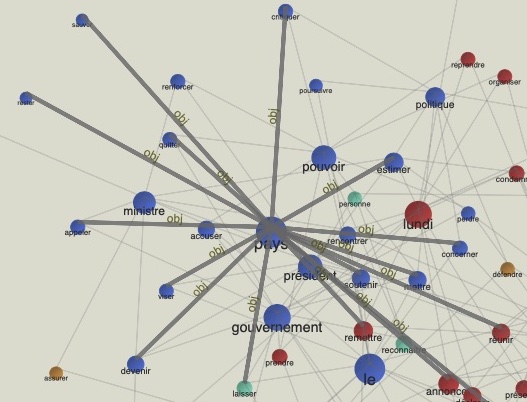
Dans le graphe de la rubrique International on remarque d'un nombre de noyaux les uns à coté des autres: président, pays, gouvernement. On n'est pas étonné par ce résultat, vu que la majorité des nouvelles internationales rélèvent de la politique. On vous propose donc plus en bas un zoom sur le noyau 'pays'
Zoom : pays
Europe - général

Aussi dans le graphe de cette rubrique on retrouve beaucoup de noyaux liés au domaine de la politique. Les noyaux très visibles de 'droit' et 'enquête' attirent notre attention : quelque chose se passe en Europe...peut être Brexit!
Zoom : pays
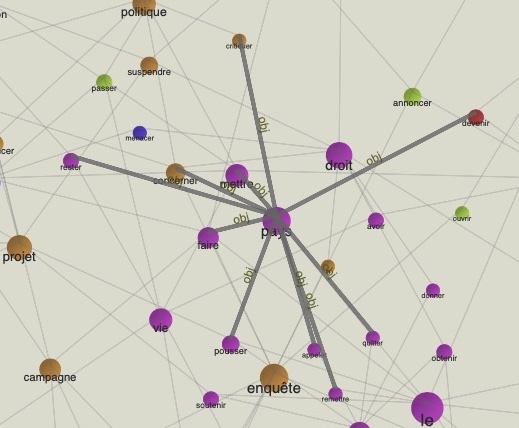
En suivant les suggestions jaillies pendant la lecture du premier graphe, on peut remarquer deux verbes clés liés au noyau 'pays': rester et quitter. On peut donc deviner que beaucoup de nouvelles portent sur la question Brexit et sur la crise interne qu'elle a causé.
Graphes nsubj:
Pour les graphes portants sur la relation 'nsubj' on a essayé d'améliorer les graphes en suivant les suggestions présentées dans l'onglet 'améliorations possibles'
En particulier, on a utilisé la stoplist et le poids, en excluant de la relation toutes les couples avec un poids inférieur à 1 (toutes les mots dont la relation a lieu une seule fois en total). Comme vous pouvez remarquer, dans le graphe les gouvernors et dépendants avec un poids mineure de 1 apparaissent mais ils ne sont pas liés entre eux parce qu'on a exclus leurs relations.
à la une :

Zoom : président
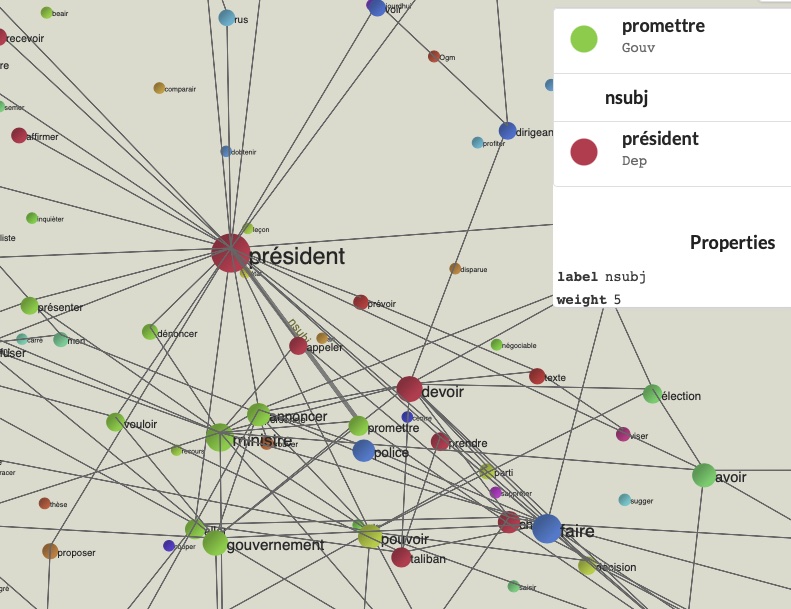
On peut séléctionner le mot 'président' et si on clique sur la relation avec un élément voir son poids. La rélation entre président et 'promettre' a un poids de '5' donc assez élévé.
Internationale
En regardant la sortie txt on peut déjà remarque des relations entre éléments variées, similaires à celles de 'à la une', très générales et difficilement renvoyables à des événements précis. On voit parmi les premiers résultats une relation très fréquente entre Vladimir et Poutine. Bien qu'il s'agit d'une relation nsubj érronée, on peut retenir la grande fréquence de ce nom à l'intérieur des nouvelles de cette rubrique. Un indice des tensions russes dont on voit les conséquences maintenant.
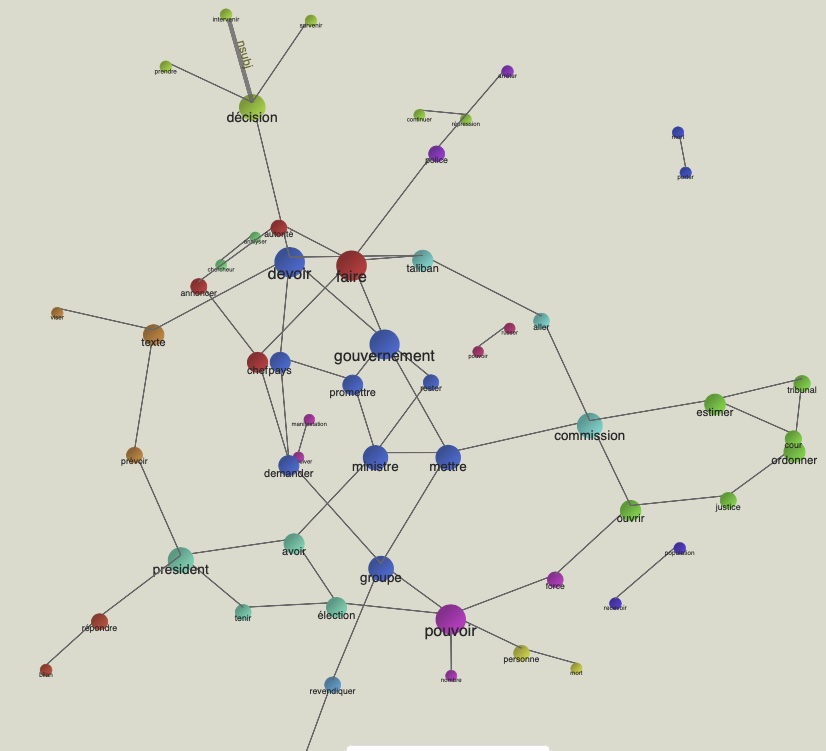
Pour la production de ce graphe on a décidé de rendre la sortie encore plus propre en indiquant que afin qu'un lien entre deux éléments apparaisse sur le graphe il faut que son nombre d'occurrences soit compris entre 1 et 3 pour éviter des relations trop générales et donc pas intéressantes
Europe
En regardant la sortie txt on peut remarquer des sorties plus spécifiques par rapport à les autres rubriques analysées. Il y a beuacoup de références à la Brexit (post-Brexit, Royame-uni) et aux devoirs de l'UE (beaucoup de 'doit'). On retrouve même ici des références à la Russie.
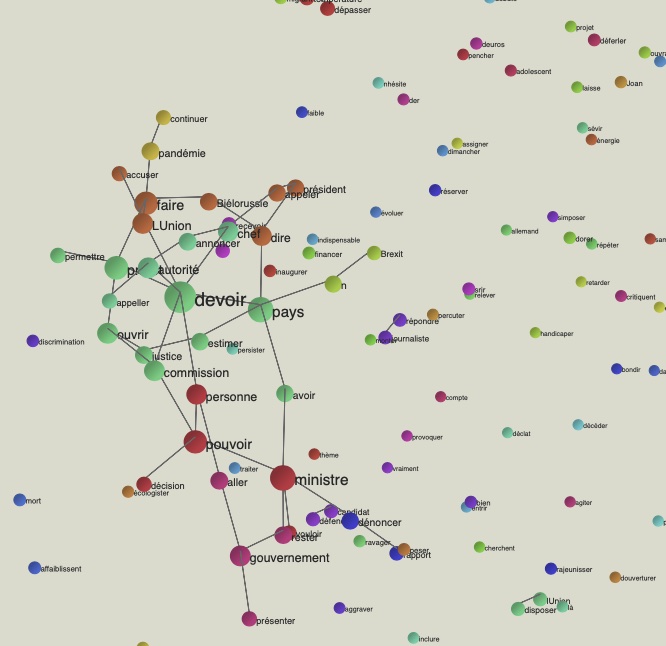
Dans cette image on voit clairement la centralité du mot 'devoir'