
extraction des relations de dépendance
Objectif BAO3bis:
La BAO3bis fait partie de la BAO3, mais j'ai préféré lui dédier une section à part pour rendre plus claires et accessibles les résultats et les explications des scripts.
L'objectif principal de la BAO3bis est d'extraire à partir du fichier Udpipe en format XML tous les items connectés dans une relation de dépendance donnée.Comme pour l'extraction des patrons morphosyntaxiques, on a mis en place une compétition entre langages.On utilisera:
- Perl
- XSLT
- XQuery
Dans cette BAO Python a été mis de côté parce qu'il sera le protagoniste de la BAO4: extractions des relations de dépéndance avec une sortie visuelle sous forme de graphe.
Le fichier d'entrée sera exclusivement le fichier annoté avec Udpipe (utilisé aussi pour l'extraction des patrons morphosyntaxiques) parce que dans l'annotations proposée par TreeTagger le répérage des relations de dépendance n'est pas proposé.
NB : On proposera le script dans sa version 'base' (répérage de tous les éléments liés par une relation de dépendance donnée) et dans la section d'explication on indiquera aussi les paramètres à changer pour faire des requêtes plus ciblées en s'appuyant sur des POS ou des lemmes particuliers.On vous montrera les résultats de la requête 'base' et aussi des sorties plus spécifiques.
Voilà le fichier en entrée:
Voilà le script perl :
Voilà les fichiers de sortie perl:
Voilà les feuilles de style XSLT accompagné par les résultats d'extraction :
Voilà les commandes XQUERY sur BaseX accompagné par les résultats d'extraction :
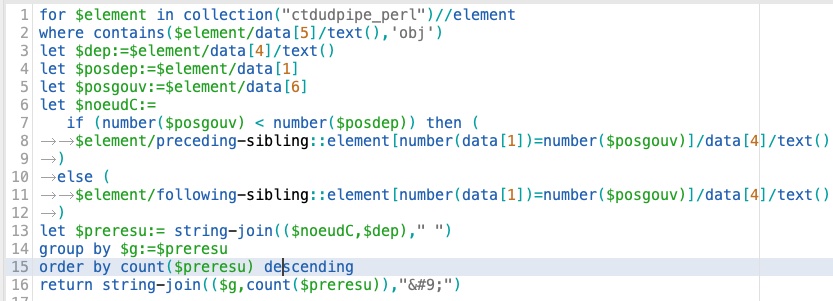
Pour explorer une autre relation: changer 'obj' avec la sigle de la relation souhaitée dans la deuxième ligne de requête
Les scripts commentés: PERL
Appel de la fonction:

Fonction:
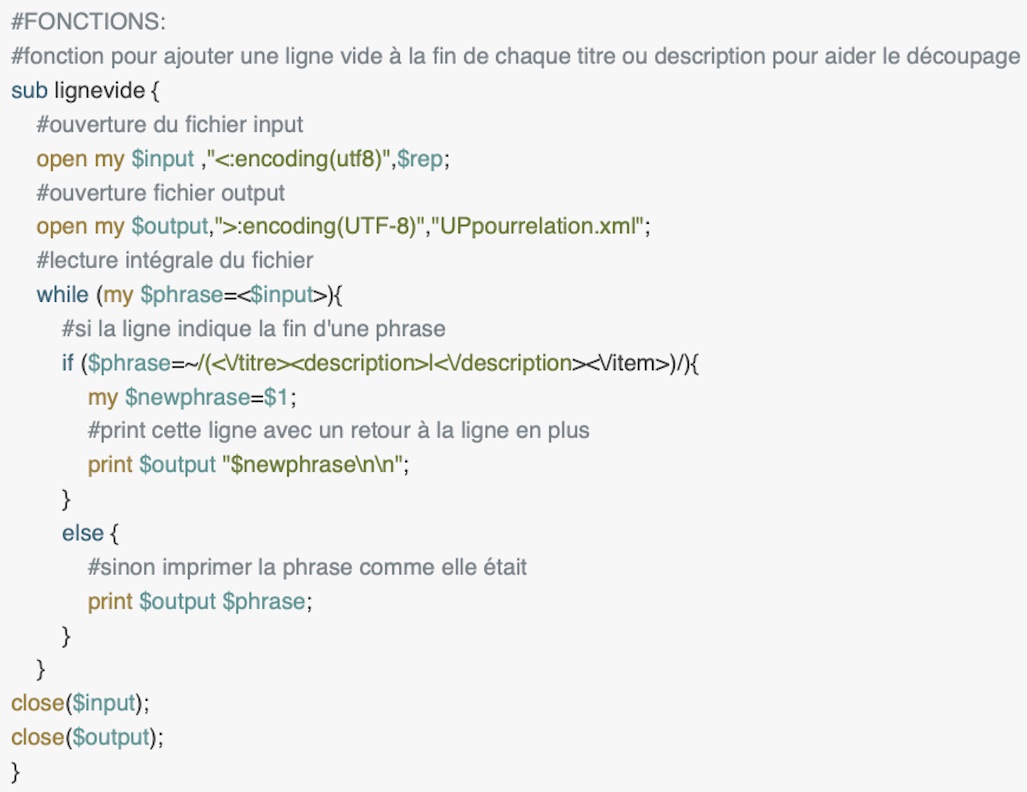
Ajouter une ligne vide :
Cette fonction est appelé en début de programme, après l'affectation des variables 'répertoire' (fichier à lire) et 'relation' (relations de dépendance à explorer). Elle est sert à insérer dans le fichier XML Udpipe une ligne vide entre chaque titre et description pour pouvoir ensuite réinitialiser la variable prédéfinie $/. Cette variable sert à diviser le texte en phrases et par défaut elle considère le retour à la ligne (\n) comme séparateur. Dans notre cas, garder le retour à la ligne comme indice de fin de phrase causera un résultat incorrect parce que chaque ligne, donc chaque item (ensemble de lemma,string,POS,relation) sera considéré comme une phrase indépendante des autres. Pour nous c'est fondamentale d'avoir l'ensemble des items qui composent une phrase (c'est-à-dire un titre ou une description) et surtout une division entre phrases. En effet, pour pouvoir répérer l'élément gouvernor à partir du dépendant, le programme, à travers une boucle for, va chercher l'indice indiqué à la fin de la ligne du dépendant à l'intérieur de la phrase. Si on essaye de ne pas diviser le texte en phrases et de le considérer donc comme une seule grande ligne, le programme répérera sous le nom de 'gouvernor' tous les éléments du texte qui ont l'indice indiqué à la fin de la ligne du dépéndant.On sait (source) que si $/ vaut '' '' alors on passe en mode 'paragraphe' et perl va séparer le texte en paragraphes. Perl considère comme paragraphe chaque morceaux de texte divisé par des lignes vides. C'est pour cette raison qu'on ajoute une ligne vide à la fin de chaque titre et description, ainsi perl considérera chaque ensemble d'items compris entre les balises 'titre' ou 'description' comme des paragraphes indépendants, donc des éléments dans lequelle faire dérouler des boucles indépendentes les unes des autres.
Pour ajouter une ligne vide, pratiquement, on ouvre le fichier en entrée et un fichier vide pour la sortie. On lit intégralement le fichier d'entrée et si la phrase finit par la fin de la balise titre unie au début de celle de description ou à la fin de la balise description ensemble à celle du début d'item, on imprime la phrase dans le fichier de sortie suivi par deux retours à la ligne. Si la phrase ne matche pas, on l'imprime dans le fichier de sortie sans la changer. Le fichier de sortie 'UPpourrelation.xml' sera le nouveau fichier d'entrée pour les traitements successifs.
Script principal:


Le script principal :
Après avoir ajoutée une ligne vide à la fine de chaque titre et description, on commence par lire le nouveau fichier 'UPpourrelation.xml' et le stocker dans une liste (@LIGNES). Ensuite, on découpe chaque titre ou description en elements et on commence le traitement avec une boucle qui lira, à chaque fois, toutes les lignes du titre/description du début à la fin (jusqu'à quand la variable i ($i) sera égale à la longueur de la liste, donc jusqu'à la fin de la liste). Si la ligne en position 'i' contient la relation qu'on cherche (emploie d'une regex), alors on stocke dans des variables: la position de l'élément (qui est donc le dépendant), la position du gouvernor et la forme du dépendant. On test si le gouvernor se trouve avant ou après le dépendant (en comparant les deux positions).S'il se trouve avant, on demarre une boucle qui va se terminer à la valeur de $i. Au contraire, s'il se trouve après, la boucle partira de la position successive à $i et terminera à la fin du titre/description. À l'intérieur de ces deux boucles les traitements sont pareils: si l'élément (ligne) dans la position $k contient en première position (comme 'id') ce qu'on avait reconnu avant comme la position du gouvernor, alors on a bien trouvé le gouvernor du dépendant séléctionné et on stocke donc sa forme dans une variable. Finalement, vu qu'on connait maintenant la forme du dépendant et du gouvernor on les stocke comme 'clés' dans un dictionnaire (si c'est la première fois qu'on croise la couple) ou on increment leur valeur. En perl est possible faire cette opération de remplissage du dictionnaire avec une seule ligne, on n'a pas besoin de distinguer: s'il a déjà renacontré la couple il va incrémenter la valeur, sinon il va tout seul l'insérer dans le dictionnaire.Une fois terminé la boucle sur la totalité du fichier, grâce à l'emploi du dictionnaire, on pourra imprimer sur un fichier sortie chaque type de couple gouvernor-dépendant (selon la relation souhaitée) accompagnée par sa fréquence d'apparition.

Améliorations possibles:
Il est possible de modifier le script pour avoir des résultats plus ciblés et précis, ou pour faire des requêtes spécifique, en se concentrant seulement sur certains POS voire lemmes en relation les uns avec les autres.Dans les exemples presentés ici, on s'est concentré d'abord sur les lemmes NOUN (dépendant) et VERB (gouvernor) et puis on a précisé le lemme du verbe avec le verbe 'porter'. On va préciser le lemme et le POS souhaités dans la position correspondante dans la ligne.
Remarques :
Les résultats :
Comme pour l'extraction des patrons, on remarque des résultats très proches entre les 3 langages utilisés. SI on compare, par exemples, les premières relations obj des 3 fichiers résultats, les types d'occurrences et leur nombre sont idéntiques.
En ce qui concerne la prise en main des différents langages d'extraction, toutes les remarques faites pour l'étiquetage des patrons sont valables
Dans ce cas, vu que seulement l'étiquetage Udpipe propose un répérage des relations de dépendance, on peut pas faire un retour comparé avec TreeTagger.Pour cette raison, on se limite à une évaluation qualitative des résultats.On retrouve la confusion remarquée aussi pour les patrons avec le présentatif 'voici' qui est considéré un verb.
Les autres rubriques
Si on compare les résultats de la rubrique 'à la une' avec ceux des rubriques 'international' et 'Europe' on voit que les premiers résultats sont idéntiques. On peut donc supposer, soit que les articles de ces trois rubriques soient pour la majorité les mêmes, soit que les tornures journalistiques utilisées dans ce type d'articles soient similaires.