
extraction des patrons morphosyntaxiques
Objectif BAO3:
L'objectf principal de la BAO3 est l'extraction des patrons morphosyntaxiques et des relations de dépendence à partir des résultats étiquétés avec TreeTagger et Udpipe de la BAO2. Pour rendre les résultats plus clairs et lisibles j'ai décidé de diviser la BAO3 en deux parties :
- BAO3 (extraction des patrons morphosyntaxiques) (page actuelle).
- BAO3bis (extractions des relations de dépendance).
On vous présente maintenant la BAO3 mise en place pour l'extraction de patrons morphosyntaxiques. Pour l'année 2021-2022 on a mis en place une compétition pour trouver le langage qui mieux arrive à accomplir la tâche d'extraction des patrons morphosyntaxiques à partir de l'étiquetage fait avec TreeTagger et Udpipe. Le langage testés (et donc les scripts produits) sont:
- Python
- Perl
- XSLT
- XQuery
Python et Perl, désormais les protagonistes de ce projet, sont affrontés par deux nouveaux concurrents: XSLT et XQuery. Si vous êtes curieux d'approfondir la connaissance de XSLT et XQuery est possible consulter le site du projet 'document structuré' où ils sont présenté d'une manière très approfondie. Afin que la compétition soit la plus correcte possible, on a séléctionné une liste de patrons de longueur différente à extraire:
- NOUN ADP NOUN ADP (NOM PREP NOM PREP)
- VERB DET NOUN (VERBE DET NOM)NOUN ADJ (NOM ADJ)
- ADJ NOUN (ADJ NOM)
- ADP DET NOUN
- NOUN VERB VERB
Les fichiers à partir desquels on extrait les patrons sont:
- Fichier XML sortie TreeTagger
- Fichier XML sortie Udpipe
NB pour XQuery et XSLT: Pour l'extraction avec XSLT et XQuery on a utilisé seulement les deux fichiers XML du moment que ces deux langages peuvent extraire du contenu textuel seulement à partir de fichiers balisés (donc en format XML).
NB pour perl et python: On a ajouté un script perl 'normalisationTT' (dont vous trouvez l'explication plus en bas) parce que les étiquettes de TreeTagger sont des abréviations à partir du français, tandis que celles de Udpipe proviennent de l'anglais. Pour lancer l'extraction des patrons d'un seul script (PERL/PYTHON script principal), vu que les différents patrons ont des longueurs différents, il était nécéssaire de pouvoir taper dans la ligne de commande dans le terminal seulement un type de patron à la fois. Pour créer donc une série de POS (un patron) valable soit pour les fichiers Udpipe, soit pour le fichier TreeTagger, on a du homogéniser les patrons du fichier TreeTagger à ceux choisis par Udpipe. Le choix de changer le fichier TreeTagger a été totalement arbitraire (on aurait pu faire le contraire). Pour le script a été choisi le langage perl parce que, étant moi moins à l'aise par rapport à python, j'avais envie de m'entrainer avec ce langage.
Voilà le fichier en entrée :
Voilà les script python et perl complets :
PERL script principal + fonction pour extraire du fichier XML TreeTagger + fonction pour extraire du fichier XML Udpipe
PYTHON script principal + fonction pour extraire du fichier XML TreeTagger + fonction pour extraire du fichier XML Udpipe
Voilà le fichier TreeTagger normalisé :
Voilà les fichiers de sortie perl:
- NOUN ADP NOUN ADP TreeTagger - perl NOUN ADP NOUN ADP Udpipe XML- perl
- VERB DET NOUN TreeTagger - perl VERB DET NOUN Udpipe XML- perl
- NOUN ADJ TreeTagger - perl NOUN ADJ Udpipe XML - perl
- ADJ NOUN TreeTagger -perl ADJ NOUN Udpipe XML- perl
- ADP DET NOUN TreeTagger -perl ADP DET NOUN Udpipe XML- perl
- NOUN VERB VERB TreeTagger -perl NOUN VERB VERB Udpipe XML- perl
Voilà les fichiers de sortie python:
- NOUN ADP NOUN ADP TreeTagger - python NOUN ADP NOUN ADP Udpipe XML - python
- VERB DET NOUN TreeTagger - python VERB DET NOUN Udpipe XML - python
- NOUN ADJ TreeTagger - python NOUN ADJ Udpipe XML - python
- ADJ NOUN TreeTagger -python ADJ NOUN Udpipe XML - python
- ADP DET NOUN TreeTagger -python ADP DET NOUN Udpipe XML - python
- NOUN VERB VERB TreeTagger -python NOUN VERB VERB Udpipe XML - python
Voilà les feuilles de style XSLT accompagné par les résultats d'extraction :NB: on a melangé la rêquete dans le fichier Udpipe et TreeTagger dans une seule feuille de style (géré à travers un when) pour faliciter la gestion des fichiers.
- NOUN ADP NOUN ADP - XSLT NOUN ADP NOUN ADP - TXT UP NOUN ADP NOUN ADP - TXT TT
- VERB DET NOUN - XSLT VERB DET NOUN - TXT UP VERB DET NOUN - TXT TT
- NOUN ADJ - XSLT NOUN ADJ - TXT UP NOUN ADJ - TXT TT
- ADJ NOUN - XSLT ADJ NOUN - TXT UP ADJ NOUN - TXT TT
- ADP DET NOUN - XSLT ADP DET NOUN - TXT UP ADP DET NOUN - TXT TT
- NOUN VERB VERB - XSLT NOUN VERB VERB - TXT UP NOUN VERB VERB - TXT TT
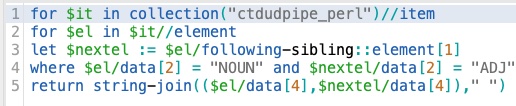
Voilà les commandes XQUERY sur BaseX accompagné par les résultats d'extraction :
- NOUN ADP NOUN ADP

 NOUN ADP NOUN ADP - TXT - TT NOUN ADP NOUN ADP - TXT - UP
NOUN ADP NOUN ADP - TXT - TT NOUN ADP NOUN ADP - TXT - UP - VERB DET NOUN

 VERB DET NOUN - TXT - TT VERB DET NOUN - TXT - UP
VERB DET NOUN - TXT - TT VERB DET NOUN - TXT - UP - NOUN ADJ
 NOUN ADJ- TXT - TT NOUN ADJ - TXT - UP
NOUN ADJ- TXT - TT NOUN ADJ - TXT - UP - ADJ NOUN

 ADJ NOUN- TXT - TT ADJ NOUN - TXT - UP
ADJ NOUN- TXT - TT ADJ NOUN - TXT - UP - ADP DET NOUN

 ADP DET NOUN - TXT - TT ADP DET NOUN - TXT - UP
ADP DET NOUN - TXT - TT ADP DET NOUN - TXT - UP - NOUN VERB VERB

 NOUN VERB VERB - TXT - TT NOUN VERB VERB - TXT - UP
NOUN VERB VERB - TXT - TT NOUN VERB VERB - TXT - UP
Les scripts commentés: PERL VS PYTHON
PERL:

PYTHON:


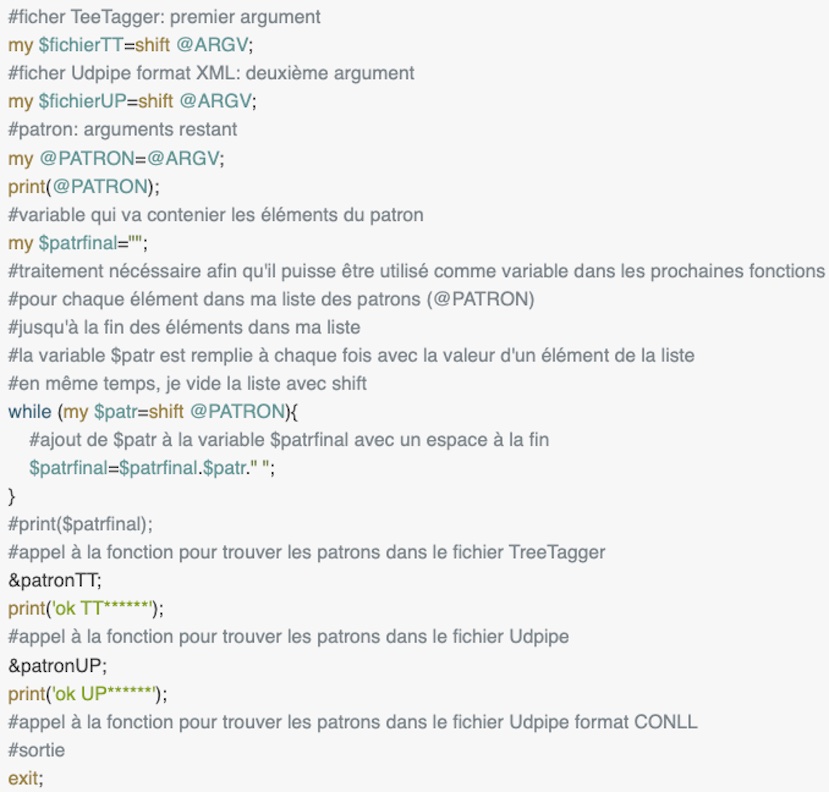
Les scripts principales
Script pour appeler les fonctions d'extractions des patrons à partir des fichiers Udpipe XML et TreeTagger XML. Ces deux scripts spéculaires sont les scripts principales pour l'extraction des patrons des fichiers XML de TreeTagger et Udpipe.
En perl, on englobe dans trois variables différentes les trois arguments donnés au programme (fichier TreeTagger, fichier Udpipe et liste de patrons). Ensuite, on transforme le patron (liste de POS) dans une string avec une lecture de chaque élément de la liste de POS à travers un while. Cette procédure est nécéssaire afin que le patron puisse être lu et compris par les programmes spécifiques d'extraction. En effet, le programme d'extraction des patrons du fichier TreeTagger (patronTT) et celui d'extraction à partir du fichier Udpipe (patronUP) sont appélés plus en base à l'intérieur des fonctions à l'aide de la fonction prédéfinie system(). Ils prennent en argument le fichier TreeTagger ou Udpipe et la liste (désormais une string) des POS. Dans la fonction dédiée à TreeTagger on appelle un programme adjonctif qu'on approfondira après pour homogéniser les noms des patrons du fichier TreeTagger à ceux donnés par Udpipe.
En python on procède de la même manière en commençant par stocker chaque argument dans une variabe à l'aide de sys.argv. Même en python on est obligé de transformer la liste (renversée) des patrons dans une string pour jouer le rôle de deuxième argument dans les fonctions (qui dans le script se trouvent au début selon les règles de python) patronTT et patronUP. Comme dans perl, ces fonctions appellent à travers os.system le programme pour l'exctration de Udpipe et les programmes de normalisation et extraction du fichier TreeTagger.
Le script de normalisation du fichier TreeTagger: only perl

Normalisation du fichier TreeTagger
Ce programme est nécéssaire pour homogéniser les noms des étiquettes des POS dans les fichiers Udpipe et TreeTagger. En effet, les étiquettes proposées par TreeTagger sont des abréviations des POS français (NOM, PREP...), au contraire, celles choisies par Udpipe sont des abréviations à partir de l'anglais (NOUN, ADP...).Comme on a vu dans la section précédent, le script général python et perl prend en argument les deux fichiers et une seule liste de POS: il est donc nécéssaire que les étiquettes présentes dans les deux fichiers soient les mêmes. On aurait pu résoudre le problème d'une autre façon en donnant au programme en argument deux listes de POS. Vu la longueur non figée des listes et donc l'impossibilité de donner des bornes, j'ai préféré la solution du programme en perl.Ce programme prend en argument le fichier TreeTagger qui est lu globalement et ensuite transformé dans une liste (< >). Ensuite, on emploie les expressions régulières (précédées par s qui opère la substitution entre le premier fragment et le deuxième) pour modifier les POS.
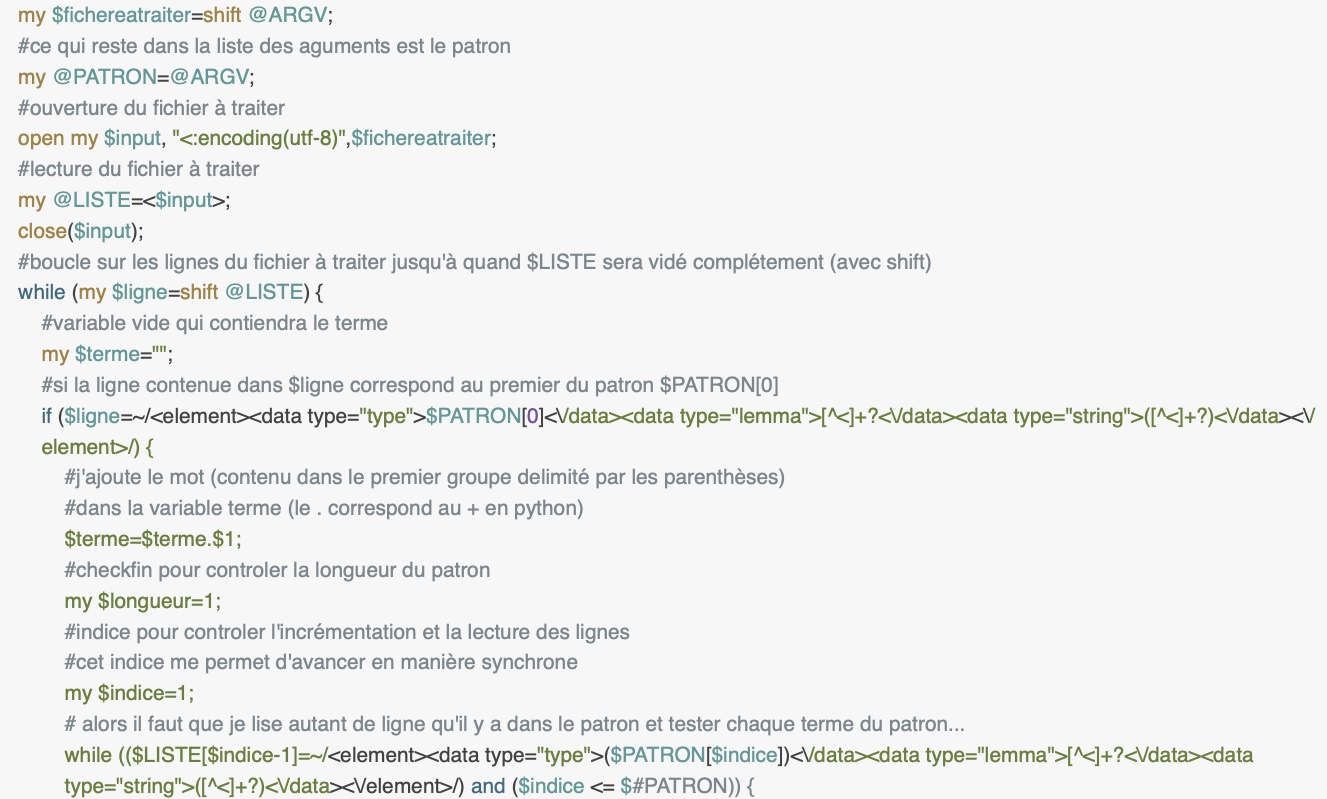
On a décidé d'expliquer un seul programme pour l'extraction des fichiers.En effet, la seul chose qui change légèrement entre les scripts pour le fichier Udpipe XML et le fichier TreeTagger XML sont les expressions régulières employées:
- Pour TreeTagger: <\element\><\data type="type"\>{tag}<\/data\><\data type="lemma"\>[^<]+?<\/data\><\data type="string"\>([^<]+?)<\/data><\/element\>
- Pour Udpipe:
[^<]+?<\/data>$PATRON[0]<\/data>[^<]+?<\/data>([^<]+?)<\/data>[^<]+?<\/data>[^<]+?<\/data><\/element>
où {tag} et $PATRON contiennent à chaque fois un élément différent de la liste des POS à tester.
PERL:
PERL
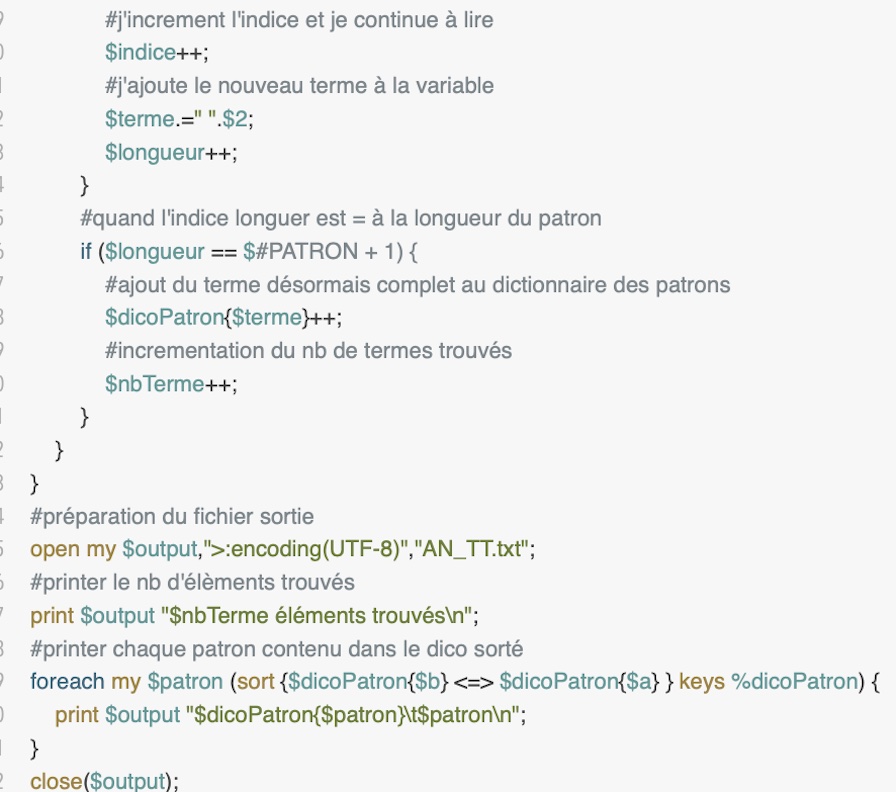
Dans perl on commence par ouvrir, lire intégralement et stocker dans une liste le fichier en input; aussi la liste de POS réçue on la stocke dans une variable. Ensuite, à l'intérieur d'un while qui prend en considération une par une toutes les lignes, on test, à travers un if, si la ligne matche avec une regex qui réproduit exactement toutes les balises qu'on trouve normalement dans une ligne
PYTHON:

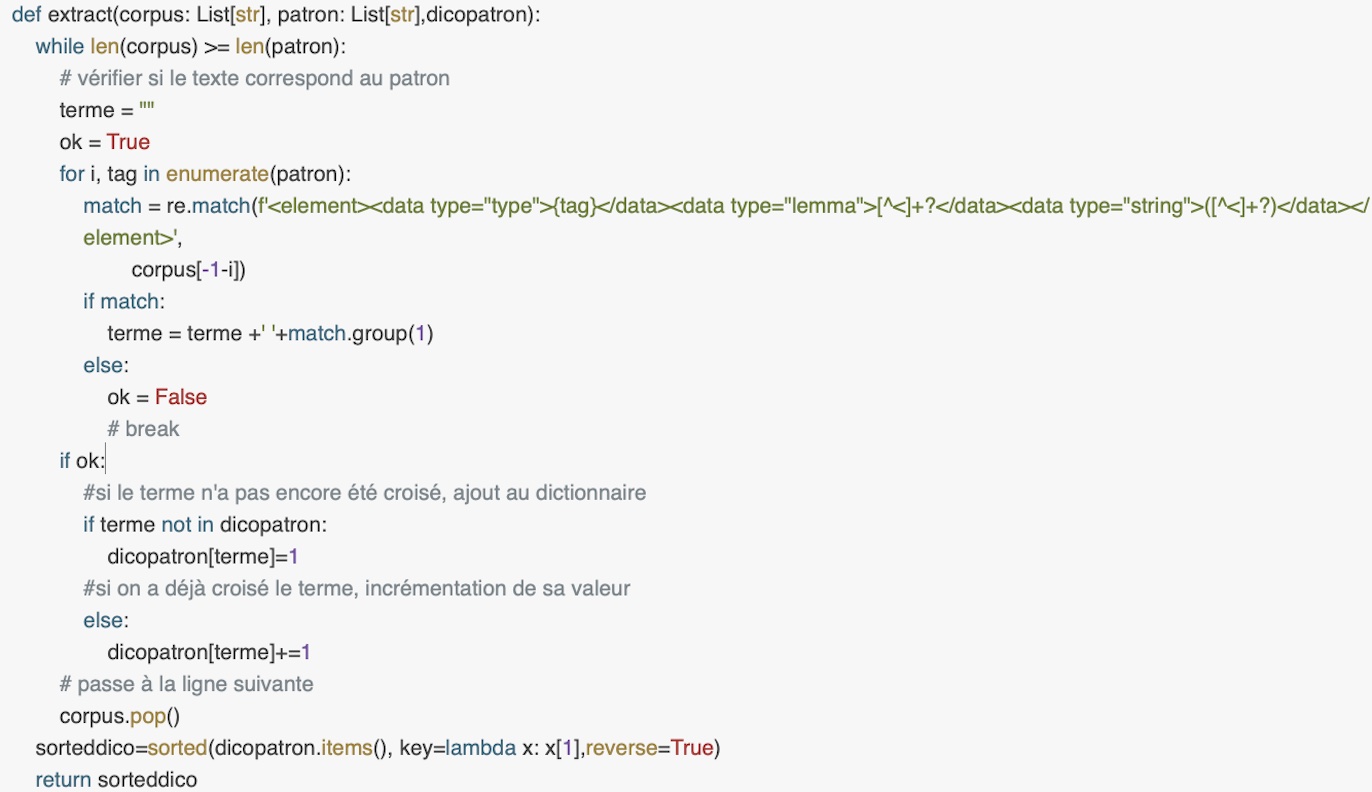
PYTHON
En python on a différentes façon de procéder. On a choisi d'utiliser la méthode qui emploie une liste renversée des POS du patron à tester sur une autre liste renversée qui contient la totalité du corpus. On initialise aussi un dictionnaire qui contiendra la liste finale des termes dont les POS, en ordre, correspondent au patron indiqué. Ensuite, on ouvre le fichier de sortie et on appelle la fonction extract, le 'cœur' du programme, qui prend en argument le fichier stockée dans une liste, la liste des patrons et le dictionnaire vide. Comme en perl, on emploie un while sur la liste corpus et on initialise une variable vide où stocker le terme et un boolean nommé 'ok' avec une valeur 'True' par défaut. À différence de perl, ici, à travers une boucle sur la liste des patrons, on peut tester, à travers un re.match où on change à chque fois la ligne prise en compte, si l'ordre de la liste des POS correspond bien à une séquence réelle de termes. Si le match est complet, donc si une séquence effective de termes correspond à la séquence de POS proposé par le patron, alors on ajoute le terme à la variable. Il suffit qu'on seul élément ait un POS différent de celui qu'on s'attend selon la liste des POS pour que le boleean se transforme en 'False' et que le programme s'arrete. En effet, seulement si le boolean est True donc 'if ok' (sous intendu: is True), on ajoute le terme au dictionnaire (s'il n'a jamais été rencontré) ou sa valeur est incrementée (s'il est déjà présent dans le dictionnaire). Vu qu'on est toujours dans un while sur un corpus entier, à la fin on utilise pop pour passer à la ligne suivante. Finalement, le dico trié sera le résultat de ma fonction qui sera ensuite imprimé sur le fichier de sortie à travers une boucle.
NB: dans le script, la fonction est déclarée avant sont appel, pour voir l'ordre originel il faut télécharger le script complet présent en début de page.
Les autres rubriques :
Comme vous pouvez lire plus en bas dans l'onglet 'remarques', les résultats des extractions avec XSLT et XQuery étaient très similaires à ceux proposés par perl et python mais plus couteux en termes d'espace et de temps. Pour cette raison, en ce qui concerne les autres rubriques analysées, on a décidé de présenter ici seulement les sorties python et perl
International - 3210
Voilà les fichiers de sortie perl:
- NOUN ADP NOUN ADP TreeTagger - perl NOUN ADP NOUN ADP Udpipe XML- perl
- VERB DET NOUN TreeTagger - perl VERB DET NOUN Udpipe XML- perl
- NOUN ADJ TreeTagger - perl NOUN ADJ Udpipe XML - perl
- ADJ NOUN TreeTagger -perl ADJ NOUN Udpipe XML- perl
- ADP DET NOUN TreeTagger -perl ADP DET NOUN Udpipe XML- perl
- NOUN VERB VERB TreeTagger -perl NOUN VERB VERB Udpipe XML- perl
Voilà les fichiers de sortie python:
- NOUN ADP NOUN ADP TreeTagger - python NOUN ADP NOUN ADP Udpipe XML - python
- VERB DET NOUN TreeTagger - python VERB DET NOUN Udpipe XML - python
- NOUN ADJ TreeTagger - python NOUN ADJ Udpipe XML - python
- ADJ NOUN TreeTagger -python ADJ NOUN Udpipe XML - python
- ADP DET NOUN TreeTagger -python ADP DET NOUN Udpipe XML - python
- NOUN VERB VERB TreeTagger -python NOUN VERB VERB Udpipe XML - python
Europe - 3214
Voilà les fichiers de sortie perl:
- NOUN ADP NOUN ADP TreeTagger - perl NOUN ADP NOUN ADP Udpipe XML- perl
- VERB DET NOUN TreeTagger - perl VERB DET NOUN Udpipe XML- perl
- NOUN ADJ TreeTagger - perl NOUN ADJ Udpipe XML - perl
- ADJ NOUN TreeTagger -perl ADJ NOUN Udpipe XML- perl
- ADP DET NOUN TreeTagger -perl ADP DET NOUN Udpipe XML- perl
- NOUN VERB VERB TreeTagger -perl NOUN VERB VERB Udpipe XML- perl
Voilà les fichiers de sortie python:
- NOUN ADP NOUN ADP TreeTagger - python NOUN ADP NOUN ADP Udpipe XML - python
- VERB DET NOUN TreeTagger - python VERB DET NOUN Udpipe XML - python
- NOUN ADJ TreeTagger - python NOUN ADJ Udpipe XML - python
- ADJ NOUN TreeTagger -python ADJ NOUN Udpipe XML - python
- ADP DET NOUN TreeTagger -python ADP DET NOUN Udpipe XML - python
- NOUN VERB VERB TreeTagger -python NOUN VERB VERB Udpipe XML - python
Remarques :
Les résultats :
En analysant les résultats d'extraction des patrons des fichiers de la rubrique 'à la une' on remarque une similarité diffuse. Les langages arrivent à extraire plus ou moins tous de la même façon les patrons recherchés. On n'a pas donc un langage gagnant pour notre compétition d'un point de vue purement qualitative des résultats. En outre, la longueur des patrons n'influence pas les prérformances des langages.
Les langages :
En ce qui concerne l'utilisation pratique des langages, leur prise en main, on doit reconnaître la supériorité de perl et python. En effet, avec ces deux langages il est possible de changer aisément le patron recherché depuis la ligne du terminal sans devoir changer le script à l'intérieur. On agit extérieurement en changeant seulement les arguments donnée au programme qui, au fond, reste toujours le même.Au contraire, pour faire des requête en XSLT et XQuery il est nécéssaire de créer une feuille de style ou une requête sur basex apposite pour chaque type de patron à rechercher. Le processus est donc chronophage et risque d'occuper un espace cosidérable de mémoire. En plus, en perl et python le comptage automatique des éléments répéré peut être aisément intégré au programme. Au contraire, en XSLT et XQuery il est nécéssaire de le faire dans un deuxième temps en tapant une requête sur la ligne de commande (avec sort | uniq -c | sort -r).
On peut donc conclure que, bien que XSLT et XQuery soient deux langage performants, ils ne sont pas les plus convénables à insérer dans une chaine de traitements semi-automatique.
L'étiquetage (retour sur la BAO2) :
Un résultat sécondaire donnè par la BAO3 a été un retour par rapport à la qualité des étiquetages faits par TreeTagger et Udpipe dans la BAO2 (on voit bien la logique de la 'chaîne'). En effet, pour évaluer réellement les résultats de la BAO2 à la fin de la BAO2 on aurait du lire intégralement ses fichiers de sortie (...un travail infini!); grâce aux résultats de la BAO3 on a pu voir clairement les différences entre les fichiers TreeTagger et Udpipe dans un contexte plus limité.
- NOUN ADP NOUN ADP : en général, l'étiquetage est correct soit de la part de TreeTagger, soit de Udpipe. Il y a peu de différences et peu d'ambiguités.
- VERB DET NOUN : en général, l'étiquetage est correct. On remarque quelques problèmes d'étiquetage avec les présentatifs ('voici ce qu'il' pour Udpipe) et avec l'expression 'd'ici', classifié comme verbe, pour TreeTagger. En outre, on remarque que soit pour TreeTagger, soit pour Udpipe les préposition coupée comme 'd'' qui précèdent le verbe sont partie intégrante du verbe.
- NOUN ADJ: même en ce cas on remarque un étiquetage correct, mais similairement au cas précédent, on voit que les article avec apostrophe sont considérés par les deux étiqueteurs comme faisant partie du nom.
- ADJ NOUN: l'étiquetage est saitisfaisant, on remarque que la mjorité des différences de résultats est causè par le fait que Udpipe considère les numéraux comme '1er' des adjectifs
- ADP DET NOUN: Avec ce patron on voulait tester au fond les deux étiqueteur. En effet, on sait qu'en français, quand les prépositions 'à' et 'de' (les plus diffusées) sont suivi d'un article détérminatif masculin, une fusion entre les deux a lieu. On remarque que TreeTagger a bien compris le fusionnement et qu'il ne répère que des prépositions suivies d'un article détérminatif féminin ou indéterminatif. Au contraire, on voit dans les résultats de Udpipe des formes incorrectes comme 'de le'. En explorant ces formes en contexte dans le fichier intégrale, on remarque une particularité de l'étiquetage udpipe: les prépositions à et de fusionnées avec les articles déterminatif (au et du) sont découpée. Dans le fichier final on trouve donc 3 lignes qui décrivent la préposition fusionnée: une ligne avec 'du' comme préposition, suivie d'une autre avec 'de' comme préposition et finalement une ligne avec 'le' comme déterminant. Pour cette raison, dès qu'on lui demande de trouver les ADP suivies d'un DET, il répère toutes les couples de 'de + le' ou 'à + le'.
- NOUN VERB VERB: grâce à ce patron on a pu rrmarquer une autre différence substantiale entre les deux étiqueteurs. On remarque que les résultats sont très différents dans ce cas. En en alysant à fond les deux fichiers étiquétés on voit que Udpipe étiquete différemment les auxiliares et les verbs. Dans TreeTagger, au contraire, tous les verbes sont marqués comme 'VERB' (à la suite de notre normalisation, mais si on regarde dans le fichier TreeTagger avec l'étiquetage originelle, on remarque quand-même la sigle 'VER' aussi pour les auxiliaires). Pour cette raison, dans les résultats de l'extraction de TreeTagger on trouve aussi toutes les formes de NOUN AUX VERB qui ne sont pas prises en compte dans l'extraction à partir de Udpipe.