
étiquetage du texte
Objectif BAO2:
L'objectif de la BAO2 est l'étiquetage automatique du texte extrait avec la BAO1.Pour l'étiquetage on a utilisé les programmes TreeTagger et Udpipe.Comme d'habitude on a produit deux scripts (perl et python).Les fichiers de sortie principales en commun entre les deux scripts:
- Analyse TreeTagger en format XML (transformé à travers un script fourni en cours)
- Anlayse Udpipe en format CONLL
- Analyse Udpipe en format XML (transformé à travers un script python écrit par moi même sur la base d'un script fourni en cours). NB: vous trouverez 2 scripts de transformation en XML: ils sont idéntiques et ils changent seulement au niveau de noms des fichiers traités; le premier est à intégrer au script perl, l'autre au script python.
En plus, il y a les fichiers (txt et xml) sorties du traitement SpacyUdpipe (bibliothèque python) qu'on retrouve seulement dans le script python.
Voilà les script complets :
PYTHON script principal + PYTHON fonction d'extraction
Voilà les fichiers de sortie:
perl-TreeTagger-XML(3208) perl-UDPIPE-CONLL(3208) perl-UDPIPE-XML(3208)
python-TreeTagger-XML(3208) python-UDPIPE-CONLL(3208) python-UDPIPE-XML(3208)
python-SpacyUdpipe-TXT(3208) python-SpacyUdpipe-XML(3208)
Les scripts contiennent toutes les fonctions présentées dans la BAO1 (parcours,nettoyage,extraction du texte), pour cette raison on presentera ici seulement les nouvelles parties ajoutées pour l'étiquetage du texte à travers UDPIPE et Treetagger.
Les scripts commentés: PERL VS PYTHON
PERL:
PYTHON:

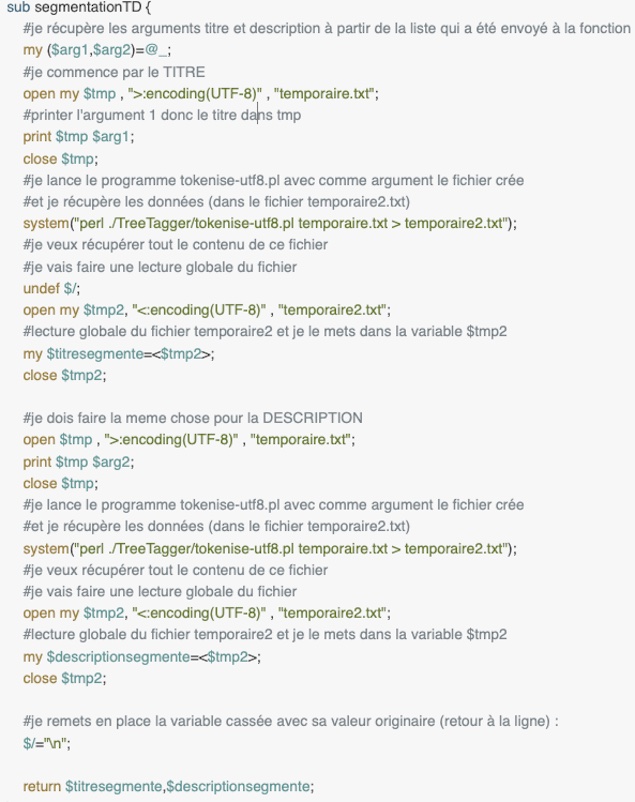
Segmentation des titres et des descriptions
Cette fonction en perl et en python permet de segmenter les textes extraits des titres et des descriptions pour les préparer à l'analyse avec TreeTagger. En effet, TreeTagger, au contraire de Udpipe, pour fonctionner a besoin de recevoir un texte déjà tokenisé. Cette fonction appelle un programme perl de tokenisation fourni par le packet TreeTagger. Le résultat de cette fonction, entouré des balises 'titre' et 'description', est imprimé (print) dans un fichier pre-corpus qui sera le fichier d'entrée pour TreeTagger. Pour la préparation du fichier d'entrée en txt pour Udpipe on n'a pas besoin de faire la segmentation, pour cette raison on imprime directement les titres et les descriptions nettoyés dans un fichier pre-corpus en txt.
En Perl on appelle la fonction sur les titres et les descriptions nettoyés. Ces deux éléments, contenus dans une liste (@_), seront les arguments de la fonction . Ensuite, on fera deux traitements autonomes mais similaires, premièrement sur le titre et deuxièmement sur la description. On appellera donc la fonction 'tokenise-utf8.pl' sur deux contenus textuels à la fois. On utilise une variable tampon ($tmp) pour stocker l'argument qu'on traite et on imprime son contenu textuel sur un fichier tampon (temporaire.txt). Ce fichier est ensuite envoyé au programme de segmentation. Le résultat envoyé provient de la lecture intégrale du fichier de sortie du programme de segmentation.Dans le script intégrale est possible voir que la création du fichier XML à envoyer à TreeTagger a lieu après le nettoyage avec les résultats de cette fonction de segmentation.
En Python aussi on appelle la fonction sur les titres et les descriptions nettoyés. En ce cas, la fonction prend un seul argument qui est à la fois un titre et une description donc on appelle le programme de tokénisation sur un seul contenu textuel à la fois. La procédure avec la variable tampon et les fichiers temporaires est la même.Comme pour perl, dans le programme intégrale il est possible voir que la création du fichier XML à envoyer à TreeTagger a lieu après le nettoyage avec les résultats de cette fonction de segmentation.
PERL:
PYTHON:
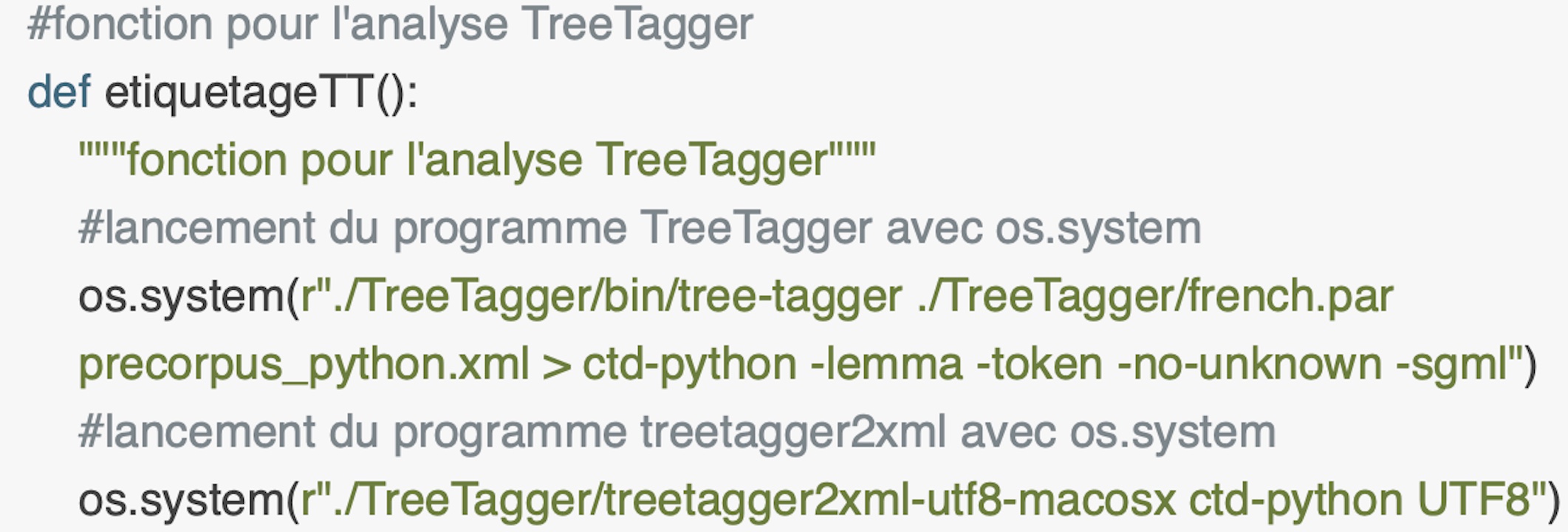
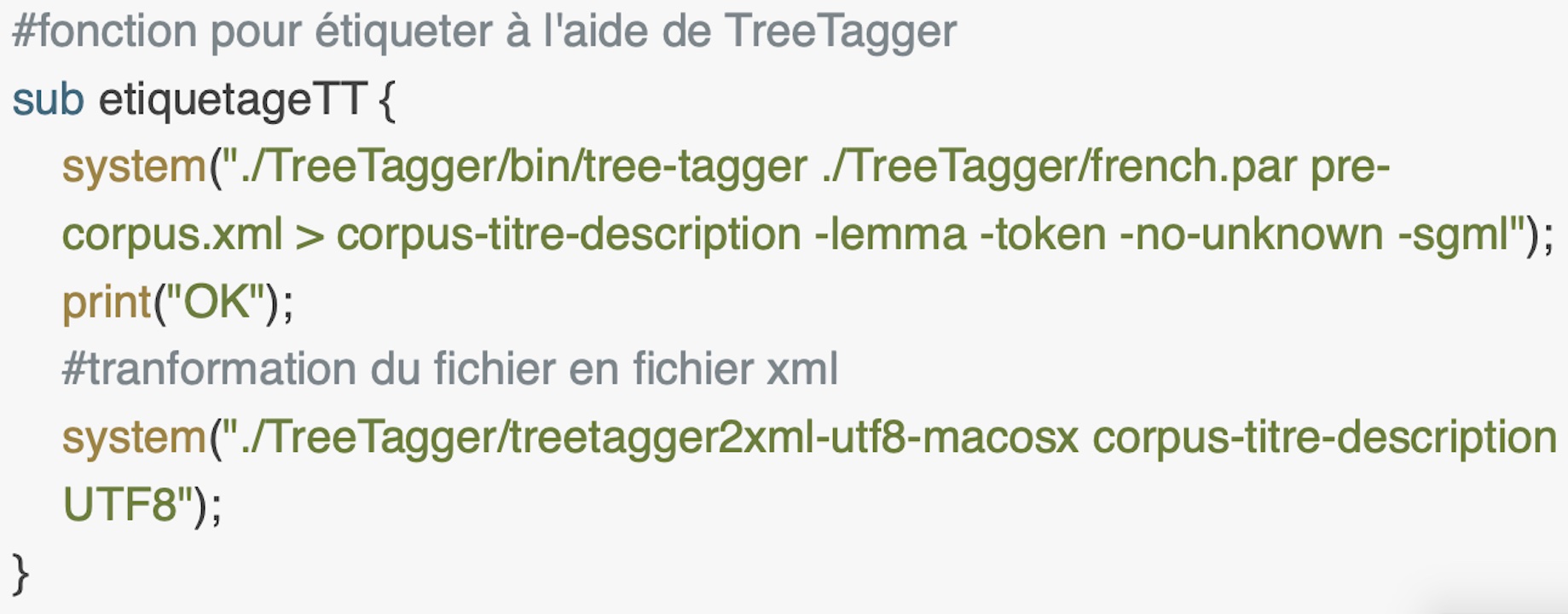
TreeTagger
Cette fonction en perl et en python permet d'appeler le programme externe TreeTagger pour l'étiquetage automatique des POS.Treetagger pour fonctionner a besoin de :
- Un fichier paramètre contenant un modèle de langue.
- Un texte en entrée déjà tokenisé avec un mot par ligne.
Les options qu'on a ajouté :
- + -lemma = affiche les lemmes
- + -token= affiche les mots
- + -no-unknown=affiche la forme graphique du mot s'il n'arrive pas à identifier son lemme
- + -sgml=il ne prend pas en compte les balises dans l'étiquetage.
Ensuite on va transformer le résultat en format XML avec le programme TreeTagger2xml fourni en cours pour ensuite faire une extraction morphosyntaxique (voir BAO3).Ce programme prend a arguments : le fichier qu’on veut transformer et l’encodage du fichier en question.
En Perl on appelle les programmes externes à l'aide de la fonction system en lui donnant tous les arguments nécéssaires et en ajoutant toutes les options nécéssaires exactement comme dans une ligne de commande.
En Python, 'system' est susbitué par os.system mais le fonctionnement est exactement le même.
PERL:

PYTHON:

Udpipe
Cette fonction en perl et en python permet d'appeler le programme externe Udpipe pour l'étiquetage automatique des POS et des relations dépendances entre les éléments (avec le répérage des positions des relatifs gouvernors). Cela réprésente un plus par rapport à TreeTagger qui sera utile dans la BAO3bis.Udpipe pour fonctionner a besoin de :
- Un fichier paramètre contenant un modèle de langue.
- Un texte en entrée en format txt, non tokenisé.
Les options qu'on a ajouté:
- + --tokenizer=presegmented = nécéssaire pour dire au programme qu'il ne doit pas segmenter les phrases en unités encore plus petites
- + --tag=tagging
- + --parse=parsing
Pour ensuite faire une extraction morphosyntaxique (BAO3), on va transformer le résultat en format XML avec un programme python écrit par moi-même sur la base d'un programme fourni en cours.Ce programme n'a pas d'arguments parce que les noms des fichiers à traiter sont déjà écrits dans le programme. Aller plus en bas pour l'explication en détail de ce programme.
En Perl on appelle les programmes externes à l'aide de la fonction system en lui donnant tous les arguments nécéssaires et en ajoutant toutes les options du cas exactement comme dans une ligne de commande.
En Python system est susbitué par os.system mais le fonctionnement est exactement le même.
Les scripts commentés: JUST PYTHON
PYTHON:
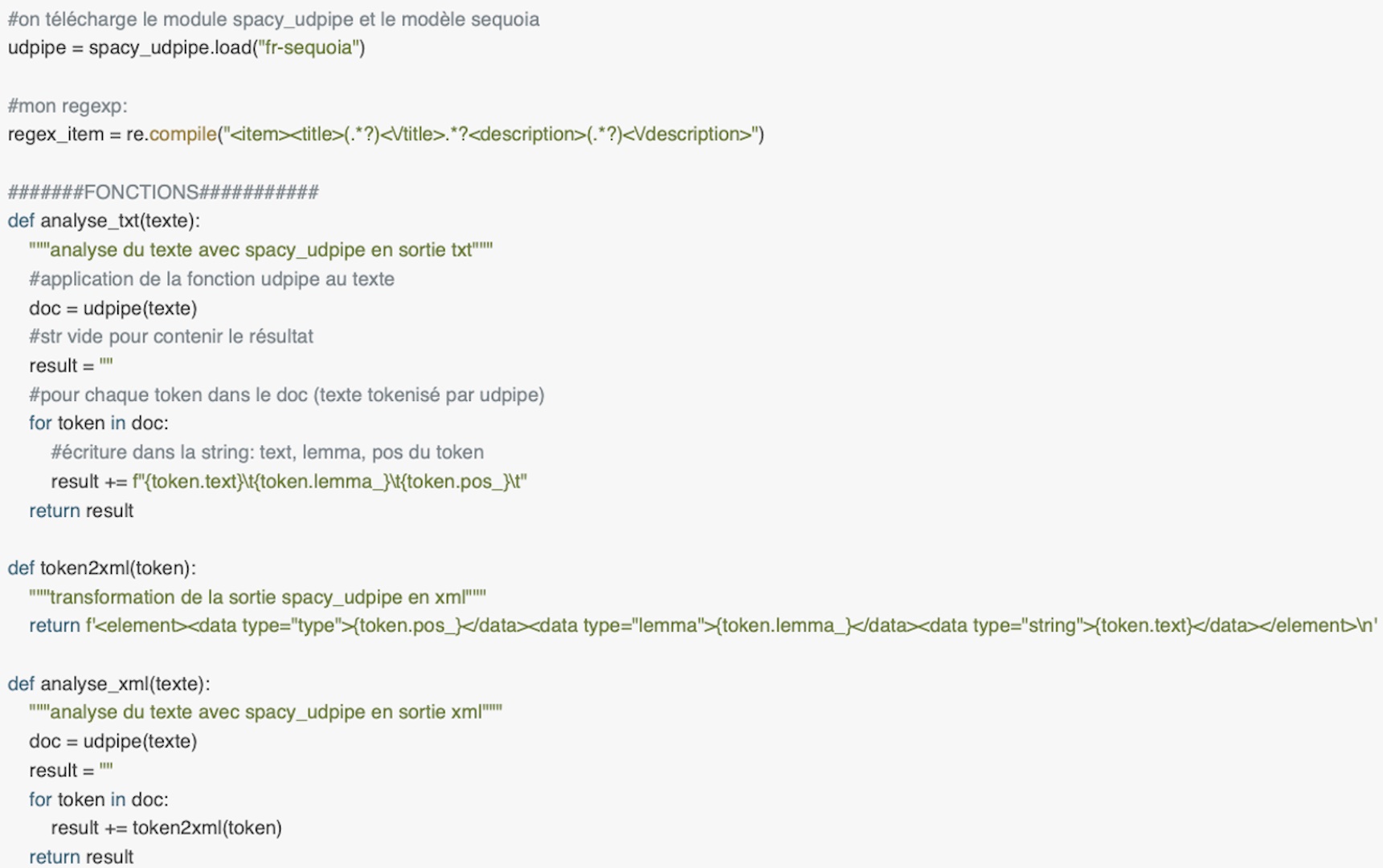
SpacyUdpipe
Il s'agit d'un packet qui 'wrap' la pipeline udpipe.
Comme pour Udpipe, il est nécéssaire de télécharger un modèle ('fr-sequoia'). Ensuite, on applique la pipeline au texte pour le tokeniser, lemmatiser et étiqueter automatiquement. On lance une boucle (pour chaque token dans le doc) sur l'ensemble du document pour récuperer :
- token.text=renvoie les mots
- token.lemma_=renvoie les lemma
- token.pos_=renvoie les POS.
On les affiche dans un document au format txt (et pas CONLL).On transforme aussi la sortie de spacyudpipe en format XML à travers une fonction qui ressemble les text,lemma,pos avec les balises nécéssaires.
Les scripts commentés: PYTHON+PERL
PERL/PYTHON


udpipe2xml AVEC titreVSdescription
Cette programme permet de transformer la sortie Udpipe en format CONLL dans un fichier en format XML. Cette sortie est nécéssaire pour le traitement qu'on fera dans la BAO3, BAO3bis et BAO4. En effet, même si on a déjà la sortie XML de TreeTagger, on veut avoir aussi la possibilité d'extraire les relations et non seulement les POS des éléments (seulement l'analyse avec Udpipe permet le répérage des relations et des relatifs gouvernors).En ce qui concerne la conception de cette nouvelle sortie on a essayé de la rendre la plus similaire possible à celle de TreeTagger. On a décidé de choisir entre toutes les informations contenues dans le CONLL et garder seulement celles qui nous pourront être utiles pour l'extraction dans BAO3 et BAO4.
- Le POS et le mot serviront pour l'extraction des patrons morphosyntaxiques
- L'id, la relation et la position du gouvernor pour l'extraction des relations de dépendance
- Toutes les balises seront utiles pour la construction et l'amélioration des graphes dans la BAO4.
Voilà les différentes éléments balisés:
- Balise 'article' dans laquelle est contenu la totalité du fichier
- Balise 'item' qui contient la totalité d'un article (titre+description)
- Balise 'titre' qui contient le titre
- Balise 'description' qui contient la description
- Balise 'element' qui contient la phrase
- Balise 'data type=id' qui contient la position du mot dans la phrase
- Balise 'data type=type' qui contient le POS
- Balise 'data type=lemma' qui contient le lemme
- Balise 'data type=string' qui contient le mot
- Balise 'data type=rel' qui contient la relation syntaxique dont l'élément fait partie
- Balise 'data type=gouv' qui contient la position du gouvernor de l'élément en question.
Les autres rubriques :
International - 3210
perl-TreeTagger-XML(3210) perl-UDPIPE-CONLL(3210) perl-UDPIPE-XML(3210)
python-TreeTagger-XML(3210) python-UDPIPE-CONLL(3210) python-UDPIPE-XML(3210)
python-SpacyUdpipe-TXT(3210) python-SpacyUdpipe-XML(3210)
Europe - 3214
perl-TreeTagger-XML(3214) perl-UDPIPE-CONLL(3210) perl-UDPIPE-XML(3214)
python-TreeTagger-XML(3214) python-UDPIPE-CONLL(3214) python-UDPIPE-XML(3214)