Ce site vous présente un projet du cours de "Programmation et projet encadré", dans le cadre du master 1 Traitement Automatique des Langues de Paris III/Paris X/INALCO.
Il s'agit d'un projet consistant à mettre en œuvre une chaîne de traitement textuel automatique afin de traiter des données multilingues que l'on a récupérées sur internet. Le traitement est procédé par plusieurs paliers, dont la conversion d'encodages.
Dans la deuxième phase on constitue les "nuages", alias appliquer des outils informatiques sur nos données, pour ensuite pouvoir les analyser et répondre à des objectifs linguistiques ciblés.


Pourquoi le "patriotisme"? Selon le Wikipédia, le patriotisme désigne le dévouement d'un individu envers son pays qu'il reconnait comme étant sa patrie, mais il existe toujours les différentes voix sur ce sujet, ce qui m'intéressent beaucoup. .
Ce projet concerne un thème du mot "patrotisme" vu sous les angles passés et futurs des Français, des Américains, et des Chinois. On va analyser les similitudes et différences de leurs points de vue sur le "patriotisme" selon les nuages qu'on aura obtenus Il s'agit de 3 langues en travail: le français, l'anglais, et le chinois, et d'environ 300 URLs. Afin d'obtenir un résultat objectif, on a choisit autant que possible les URLs d'origine différente.
En vue de la finalité du projet, à savoir qu'il y a peu d'ambiguïté du "patriotisme", la détection automatique des contextes linguistiques est assez satisfaisante.
Afin de classer les futurs résultats, il nous a fallu créer un tableau en HTML à l’intérieur de notre script bash.
La commande wget nous a permis d’automatiser l’aspiration des pages des différentes URLs sélectionnées, ainsi que leur enregistrement sur le disque local, dans le répertoire PAGES-ASPIREES préalablement créé.
La commande lynx permet de récupérer le contenu textuel de la page aspirée et une redirection vers un fichier texte sauvegarde ces données dans le répertoire DUMP.
Avant de récupérer les contextes voulus du mot "sens" par la commande egrep, il nous a fallu définir les motifs propres à chaque langue.
Concaténer les fichiers dump et les fichiers texte des contextes où apparaît le mot "sens" et les conduire dans différentes applications qui font des "nuages".
Cliquer pour voir la version claire
.png)
.png)
.png)
-----LES TABLAUX DES DONNEES-----
Tableau de liens Trameur Chinois
C'est avec le chinois qu'on a obtenu des résultats perplexes. Etant que "langue isolante", le chinois est différent de la plupart des langues, la segmentation nous pose beaucoup de problèmes.
On peut voir que dans l'image au droit certains mots sont incorrectement segmentés, et qu'ils ne présentent pas une bonne pertinence les uns entre les autres. Un autre problème est que certaines ponctuations ne sont pas connues par le Trameur.
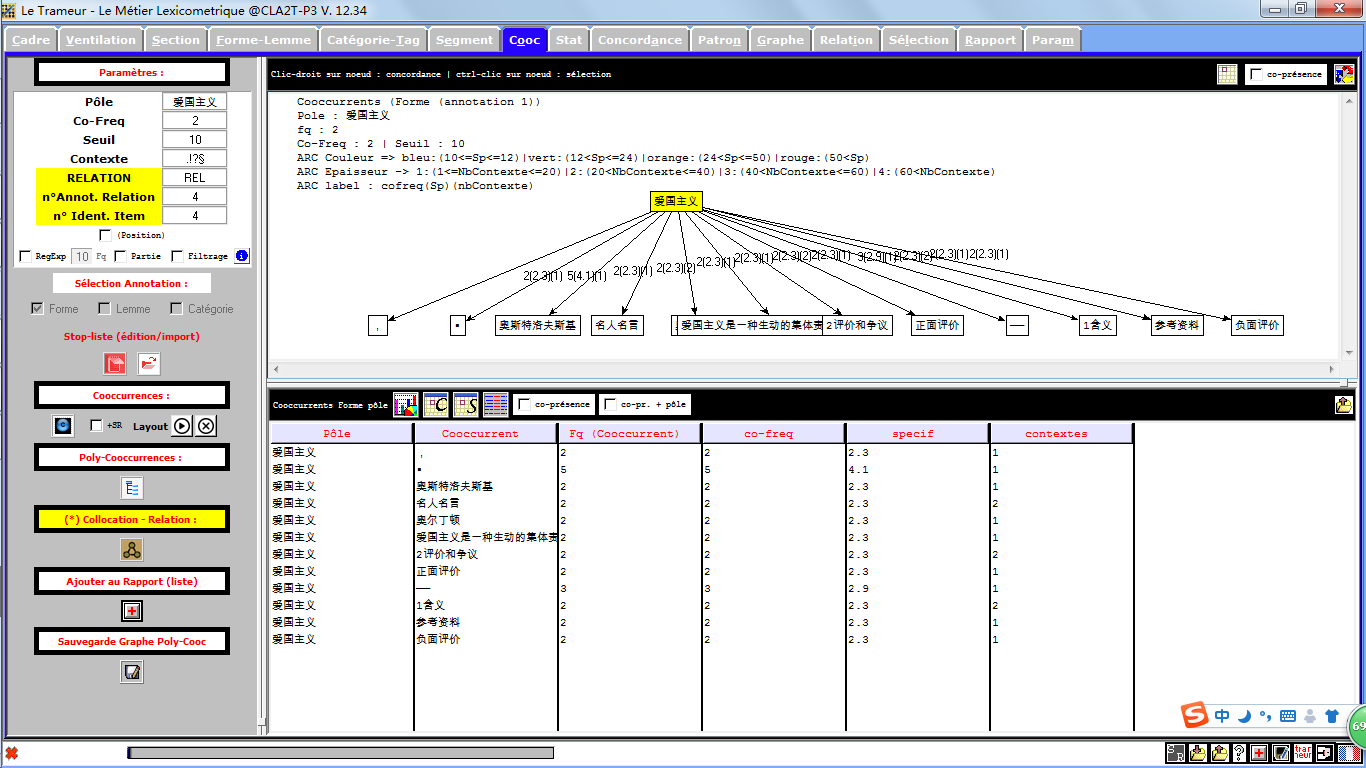
Worditout Chinois
Afin d'avoir un résultat satisfaisant et de rencontrer le moins fréquentemment possible le problème de segmentation, on a conduit seulemrnt les mots fréquentés qu'on a trouvés dans le document "index globaux".
Dans le nuage des mots, tous les mots sont correctement affichés, le problème de segmentation n'a pas émergé. Néanmoins, les mots sont serré comme dans une boîte de sardine, il manque d'esthétique.

Tagxedo Chinois
Comme on a fait avec le Worditout, on y conduit seulemrnt les mots fréquentés qu'on a trouvés dans le document "index globaux".
Au contraire de Worditout, le nuage est vraiment joli mais les mots sont totalement mal segmentés en étant tous coupés en caractère, le Tagxedo ne connaît pas les mots chinois. Mais on a encore remarqué que les caractères, censées aussi comme des mots en chinois, représentent un lien étroit entre le pays et le parti.

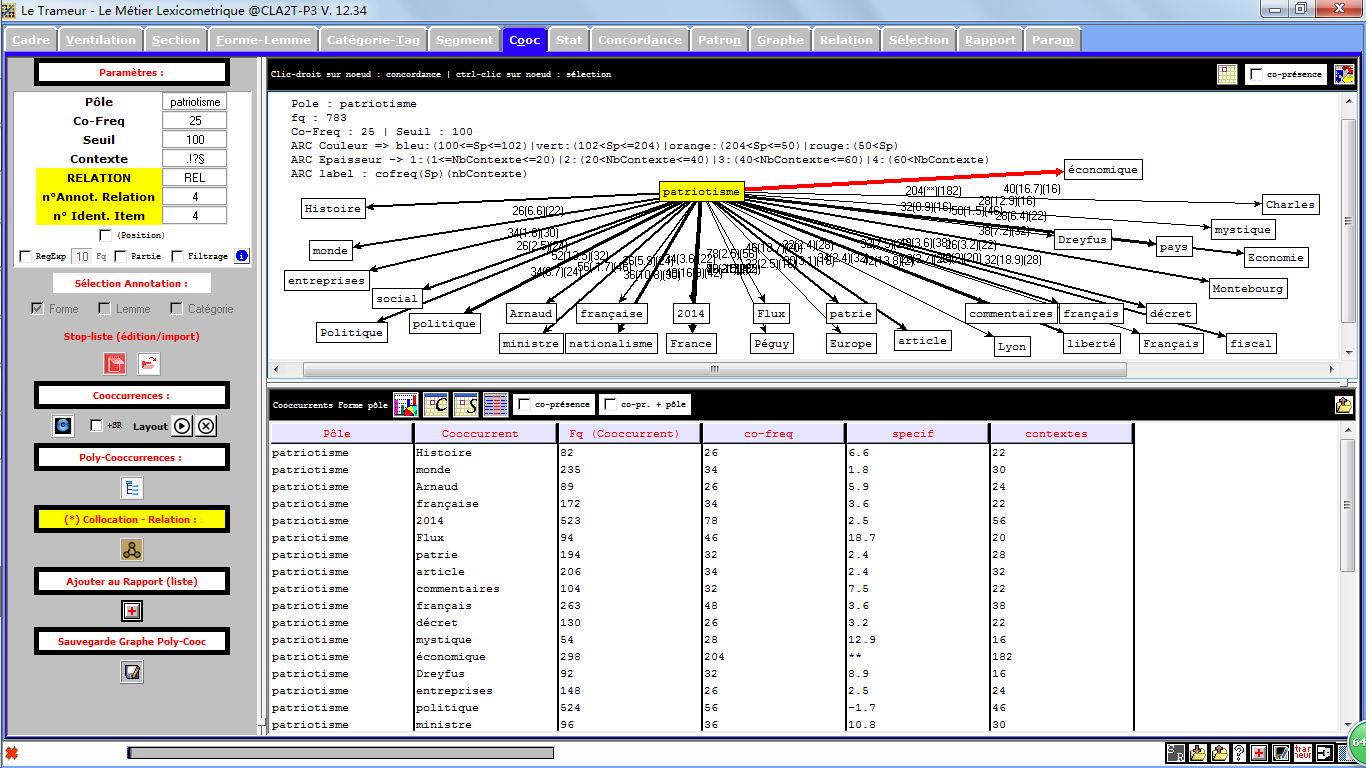
Trameur Français
Un total success avec le Trameur quand on traite le français. Sauf que l'exclusion des mots peu corrélatifs on a vraiment fait dépenser pas mal de temps.
Dans l'image au droite, les lignes entre le pôle et les mots fréquentés sont plus gros et parmi lesquelles celle qui lie le pôle et le mot le plus fréquenté est rouge, on voit que ce mot est "économique".
Worditout Français
Le nuage des mots est clair et accetable, mais tous les mots ont juste deux tailles, ce qui ne représente pas exactement la fréquence des mots.
On rend compte que le résultat n'est pas exactement le même que celui de Trameur, voire il existe une grande différence entre les deux, il s'agit probablement d'une question d'algorithme.

Tagxedo Français
Esthétique et clair, ce nuage fait avec Tagxedo est plus logique qu niveau de la représentatoin de fréquence des mots.
Ce nuage est similiare de celui-ci produit par Worditout au niveau des mots les plus fréquentés, les mots fréquentés sont "national","politique","gurre"... il s'agit probablement de deux algorithmes resemblables, mais, évidemment, celui de Tagxedo est meilleur.

Imagechef Anglais
Théoriquement, le traitement sur anglais doit être le plus facile étant donné qu'il n'existe pas le problème de segmentation ni un grand travail de transformation d'encodage. Cependant, quand on faisait le tableau beaucoup de problèmes ont montré, il y a seulement 20 URLs qui fonctionnent bien.
On rend compte qu'il existe beaucoup de répétitions pour certains mots, néanmoins ces mots ne sont pas forcément les mots les plus fréquentés

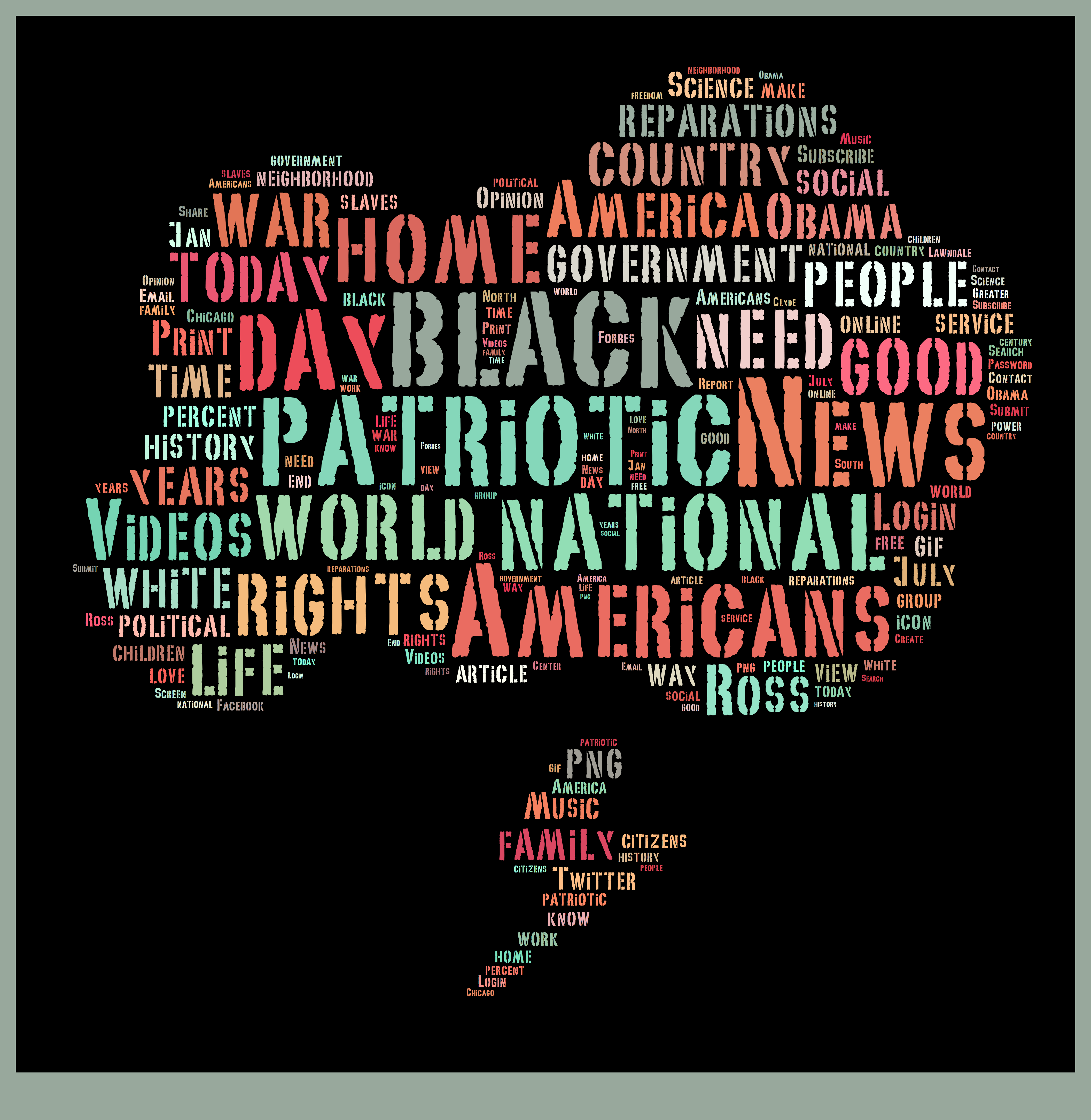
Worditout Anglais
Même problème avec la version française, tous les mots ont juste deux tailles, et ce qui ne représente pas exactement la fréquence des mots.
Un mot inattendu ici est "black", alias "noire". On infère que le statu quo des noires en Etats-Unis a tiré de plus en plus d'attention.

Tagxedo Anglais
On rend compte que sauf le chinois, les autres deux langues marchent très bien avec le Tagxedo. Le nuage est clair et esthétique, mais ce qui est bizzare est que le mot le plus fréquent n'est pas "patriotism".
Après la comparaision avec les nuages produit par Worditout et Imagechef, on a trouvé que le Tagxedo est le meilleur à traiter les langues flexionnelles.
http://www.google.fr
http://fr.search.yahoo.com/
http://www.google.com
http://www.google.com.hk

TAN Chang (voir le blog du travail)