La vie multilingue de "stress"
Dans le cadre de la formation pluriTAL 2016-2017, notre groupe de travail a choisi comme sujet du projet de premier semestre de traiter la notion de "stress". Pour résumer le contenu du projet, il suffit de décrire les différentes étapes que nous avons parcourues depuis ces derniers mois:
◍ Récolter manuellement des pages web contenant une ou plusieurs occurrences du thème choisi (le "motif")
◍ Élaborer un script en langage bash
◍ Analyser le résultat par "Le Trameur", développé par notre enseignant, M. Serge Fleury.
◍ Élaborer un site montrant nos résultats.
Notre projet se fait en quatre langues et cinq écritures:





Étapes
- Choix d’un thème sur lequel travailler
- Constitutions de fichiers d’URLs
- Réalisation d’un script en bash
- aspiration des pages
- dump des contenus textuels
- récupération de l’encodage suivi d’un transcodage si nécessaire
- création de contextes textuels et html (merci minigrep)
- écriture des résultats dans un tableau html
- Segmentation des textes en chinois avec Stanford Word Segmenter
- Utilisation du logiciel le Trameur et d’iTrameur
- graphes de co-occurences
- (optionnel) récupérer les fichiers statistiques qu’on pourra utiliser pour créer les nuages de mots
- Création de nuages de mots
- Réalisation de ce site web, pour présenter nos résultats (ce qui a demandé un apprentissage des langages html et css)
Outils
1.LeTrameur
Le Trameur est un logiciel de textométrie, nous l’avons principalement utilisé afin de repérer les co-occurents des mots en lien avec le stress. Cette étape nous a également permis de nous rendre compte de l’importance des données collectées. Les dumps des articles étaient pollués par un certain nombre de données textuelles qui ne présentait pas d’intérêt pour nous (menus de navigation des pages web, listes d’articles mis en avant sur la page...). L’analyse avec le Trameur nous a montré qu’afin d’obtenir des analyses satisfaisantes, il est nécessaire de nettoyer les fichiers constituant notre corpus (automatiquement, de préférence).
2.Le choix des URLS
Nous avons choisi de collecter des URLs d’articles de presse, afin de constituer un corpus plus homogène. Pour constituer le corpus en anglais, les sites ont été sélectionnés en faisant attention à varier les régions
3.Le nuage des mots
Pour créer les nuages de mots, nous avons utilisé plusieurs outils: WordItOut, Word cloud generator
4.Segmentation du chinois
Le chinois est une langue très différente que les langues européennes, parce qu'il y pas de espaces entre les mots, donc quand on analyse le chinois il faut segmenter les mots en avance. Pour la segmentation, c'est Marine qui a trouvé l'outil Stanford Word Segmenter. C'est un logiciel développé par Université Stanford qui est le leader dans le domaine de TAL, donc c'est un outil très fiable, cependant, il reste encore des mots mal séparés, sa performance est moins pertinente sur le sinogramme traditionnel :il a y des faux mots, c'est-à-dire des phrasés sont traités comme des mots, ça influence un peu le résultat.
5.Langage Bash
C'est une sorte de boîte à outils, très puissante mais aussi très exigeante, qui nous est proposée pour faire nos premiers pas en programmation. Le Bash (Bourne-Again SHell), langage du shell UNIX, permet de travailler en ligne de commande ou bien dans des programmes élementaires constitués de commandes de ce langage, les scripts. Pourtant, ce langage n'a pas toujours très bonne presse auprès des programmeurs : peu portable, pas assez abstrait (ses données sont réputées "non typées"), il souffre de la comparaison avec les langages dédiés à la programmation tels que la famille des C, le Javascript, le Python et consorts qui sont effectivement plus spécialisés, donc plus puissants. Pourtant, cela reste un outil très pratique qui a connu une évolution progressive au cours de ses diverses versions, et pour peu qu'on soit assez familier avec ses subtilités, il sait se montrer très utile, un peu à la manière d'un couteau suisse.
Une alternative était de recourir au programme "Gromoteur" développé par M. Kim Gerdes, un autre de nos enseignants. C'est un peu le nec plus ultra par rapport à nos besoins, car il fonctionne de manière similaire et donne des résultats beaucoup plus avancés, avec toutes sortes de pré-traitements ; nous avons cependant préféré la démarche "do it yourself" consistant à mettre en place nos propres outils rudimentaires pour tenter d'aboutir à des résultats à peu près équivalents.
6.Le script
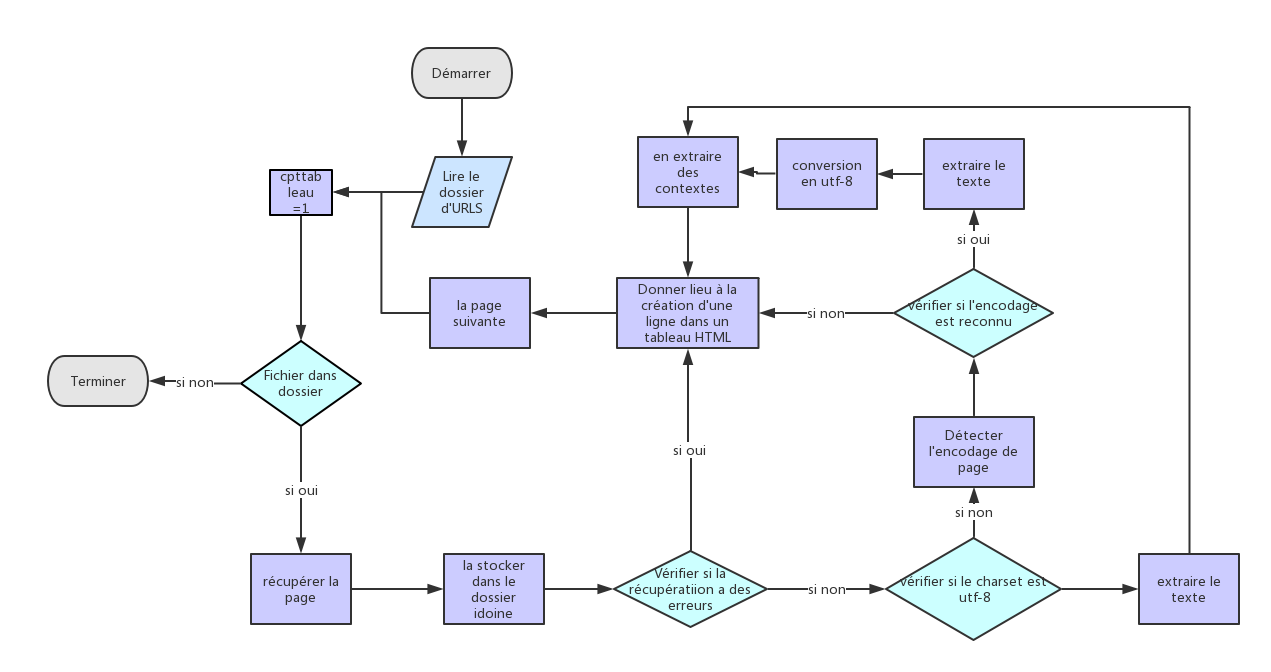
Comme c'est la première fois d'écrire un programme, au début c'est très difficile :les commandes inconnues, le script d'exemple a l'air très compliqué...Pour moi, le plus important est de comprendre le script, construire un diagramme pour le script est un bon choix, il nous aide de comprendre la logique(cliquez pour l'agrandir):
Puis il faut trouver un bon éditeur à écritre notre propre script, et j'ai utilisé textewrangle au début, ça m'a apporté des difficultés : pas de mémoire des noms de variables, pas de couleurs à distinguer commandes et variables...Après, j'ai connu Atom qui est un éditeur pas mal, un bon éditeur facilite beaucoup le travail.
7.Le site
C'est aussi la première fois de construire un site. Ça semble peut-être que c'est facile puisqu'on peut trouver pas mal de modèles de site sur Internet, ce que l'on doit faire est juste d'ajouter le contenu. Mais juste comme le script de bash, il faut comprendre le script de modèle en avance pour qu'on puisse ajouter le contenu dans la bonne place d'une bonne manière, de plus, si on veux ajouter styles, il faut apprendre plus de commandes de CSS et HTML, par exemple, j'ai dépensé beaucoup de temps à trouver une façon de mettre le script dans une page web, de plus, plein de détails à régler et à vérifier. Heureusement il y a un site qui donne des instructions de connaissances de construction de site web: W3School
8.Problème des sites chinois
A partir du tableau de sinogrammes simplifiés, on observe que les encodages de presque une moitié des sites sont gb2312, c’est bien différent que la situation des sites en autres langues, y compris les sites de sinogrammes traditionnels: leurs encodages sont presque tous utf-8.
GB2312 est le nom Internet enregistré pour un jeu de caractères officiels de la République populaire de Chine, utilisé pour les caractères chinois simplifiés, publié en 1985. GB est l'abréviation de Guojia Biaozhun, qui signifie Standard National en chinois. Alors que GB2312 couvre plus de 99% des caractères de l'usage contemporain, des textes historiques et de nombreux noms restent hors de portée. Mais pour les sites de presse ou de nouvelles, ça déjà suffit. Les caractères dans GB2312 sont disposés dans une grille 94x94 (comme dans ISO 2022), et le codepoint à deux octets de chaque caractère est exprimé dans la forme kuten (ou quwei), qui spécifie une rangée (ku ou qu) et la position de la Caractère dans la ligne (cellule, ten ou wei).Donc on sait que dans GB2312, un caractère tient deux octets.
L'encodage UTF-8 est apparu en 1996, c'est un codage de caractères informatiques conçu pour coder l'ensemble des caractères du "répertoire universel de caractères codés", défini par Unicode. UTF-8 est un encodage de longeur variante, c'est-à-dire que les longeurs de code sont diférentes, pour les caractères chinois, chaque caractère utilise généralement 3 octets, et pour des caractères plus anciens rarement utilisé, ils utilisent eventuellement 4 octets.
En comparant encodage UTF-8 et GB2312, on peut trouver la raison de l'utilisation populaire de GB2312 en Chine: GB2312 correspond aux besoins d'utilisation quotidienne en utilisant moins d'octets pour chaque caractère que UTF-8(GB2312: 2octets/caractère, UTF-8 3octets/caractère); d'autre côté, GB2312 est apparu plus tôt que UTF-8, donc il y a des sites construits avant 1996 qui préfèrent de continuer utiliser l'encodage qu'ils utilisent depuis longtemps, pour un grand site web, c'est difficide de changer l'encodage.
9.Les spécificités du script synthétique
Notre intention était de se réapproprier le programme générique construit sur la base fournie par les enseignants et de présenter quelque chose d'un peu plus personnel qui permettrait aussi d'utiliser les spécificités de Bash. Et nous avons plutôt réussi cette tâche, semble-t-il, puisque le second script fonctionne tout autant. Il sera certes plus ardu à comprendre, car il met en pratique des éléments un peu avancé de la syntaxe Bash, mais en même temps, la compréhension de la structure sous-jacente paraît moins compliquée, justement grâce à cet effort de synthèse.
Plusieurs points distinguent cette seconde version :
- Il ne s'agit plus d'un programme interactif. Plutôt que de saisir les paramètres au clavier après le lancement du script, il faut un fichier d'initialisation qui contient deux lignes avec les informations en question : l'emplacement du fichier d'URLs sur la machine et le motif (pour en compter les occurrences); la première section du corps du programme consiste à vérifier qu'il y a bien un et un seul argument passé au script en ligne de commande qui pointe vers un fichier lisible et conforme. Si toutes ces conditions sont vérifiées, le script s'exécute normalement en affichant sur la console des messages sur le traitement de chaque URL, puis termine avec quelques lignes de résultat et renvoie un code de sortie 0 qui indique que tout s'est déroulé correctement.
- En ce qui concerne l'aspect synthétique, il repose principalement sur la simplification de la structure logique du script initial ; en effet, celui-ci propose une série de tests sur chaque URL pour vérifier successivement si l'aspiration de la page s'est bien passée, si l'encodage d'origine a été reconnu et si c'est de l'UTF-8 ou non. La plupart de ces tests sont imbriqués les uns dans les autres avec des blocs correspondants de lignes de résultats, si bien que la structure générale du script d'origine est plutôt lourde et difficile à appréhender. Notre parti pris pour résoudre ce problème a été de tout simplifier en recourant à des fonctions et des variables (on a tout "paramétrisé").
La première fonction sert à vérifier l'encodage d'un fichier passé en argument et renvoie la variable contenant cette information ; il faudrait toutefois l'améliorer car elle repose sur le résultat de la commande 'file' qui n'est pas toujours très fiable.
La seconde regroupe tous les traitements de sortie qui permettent de récupérer le contenu textuel de la page web ciblée, l'intégrer au corpus, compter les occurrences du motif et donner l'index (liste de tous les mots du texte et leur fréquence absolue).
Les tests successifs sont remplacés par une instruction de branchement 'case' qui vérifie le résultat de la fonction d'encodage et selon les trois cas de figure possibles (pas reconnu/UTF-8/autre), effectue les traitements nécessaires : l'écriture des résultats dans le tableau final et le cas échéant, la conversion au format UTF-8 et l'ajout des données au corpus. Du coup, le bloc qui génère une nouvelle ligne du tableau n'apparaît qu'une fois dans le script en fonction du branchement.
- En dernier lieu, cette version alternative traite un peu différemment l'arborescence du projet dans la mesure où elle vérifie la présence des dossiers de résultats (aspirées, dumps, contextes et tableaux) et les crée si besoin. Elle ne regroupe pas tous les résultats dans un tableau unique mais en ajoute un par fichier d'URLs traité et ajoute les fichiers aspirée, dump et contexte de chaque URL dans un dossier de résultats identifié par fichier d'URLs (les fichiers d'index sont placés dans le même dossier que les dumps); de même, les noms de fichier ont été un peu plus explicités que les simples références à leur valeur d'indexation. La mise en forme des tableaux est aussi un peu différente : la colonne "dump initial" a été supprimée car rendue obsolète, comme celle de "statut curl", jugée redondante et on a rajouté deux lignes de résultats avec les liens vers les fichiers globaux ainsi que le nombre total d'occurrences relevées.
10.Le script "nettoyeur"
C'est l'outil le plus rudimentaire mais il a le mérite d'accomplir soigneusement sa tâche. Il purge le corpus en éliminant ce qu'on lui demande et accepte des expressions régulières (du moins celles reconnues par 'sed' car il est construit autour de cette commande). Dans les fichiers de dump global, il peut y avoir en effet beaucoup d'informations inutiles et de toute façon il est impératif, avant d'entamer les analyses, d'éliminer toutes sortes de mots grammaticaux (articles, pronoms, prépositions, etc.) qui pourraient fortement compromettre les résultats. Le script fonctionne de la manière suivante : on indique le fichier cible comme argument du script et on obtient en sortie deux nouveaux fichiers, un pour le fichier filtré et un fichier "crible" qui contient l'ensemble des formes supprimées dans le fichier source (qui reste intact).
Une particularité de ce script est qu'il comprend un document embarqué (Here-document) qu'il faut modifier pour constituer le filtre. En gros, il faut écrire spécifiquement le mot ou l'expression régulière que l'on veut nettoyer dans un espace prévu à cet effet (entre les lignes "LISTE_FILTRE"). Concrètement, nous avons dû procéder par affinements successifs pour constituer la liste de formes à filtrer ; il s'est avéré particulièrement pratique de partir d'un nuage de mots du dump global et de relever tout ce qui semblait superflu, et on a encore augmenté la liste en utilisant les premiers résultats donnés par le Trameur et en parcourant manuellement l'ensemble du document. Il est donc pratique de conserver cette liste dans un autre fichier qu'il suffit de copier-coller dans le script. Et voilà !
Le seul petit inconvénient, si l'on excepte le fait qu'il faut modifier la partie filtre du script à chaque usage au lieu de passer un fichier en argument, est qu'il est impératif de lancer le script depuis le même dossier que celui où se trouve le fichier cible.
Difficultés essentiels rencontrées :
Résoudre les problèmes d’encodage
Segmenter les corpus en chinois
Nettoyer les fichiers dumps pour enlever des informations superflues (résolu en partie seulement)
Problèmes engendrés à cause des différents systèmes d'exploitation: Windows, MacOs, Ubuntu
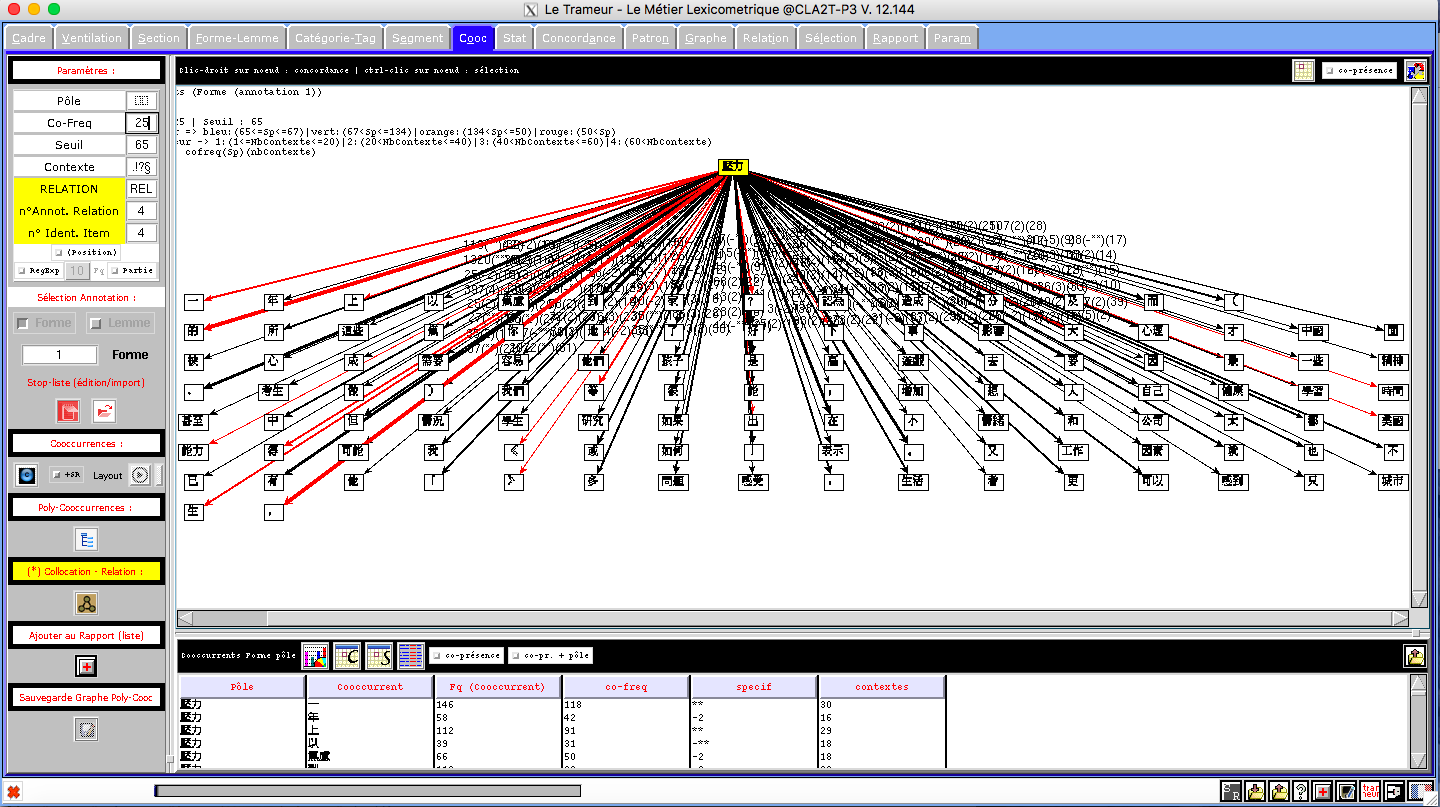
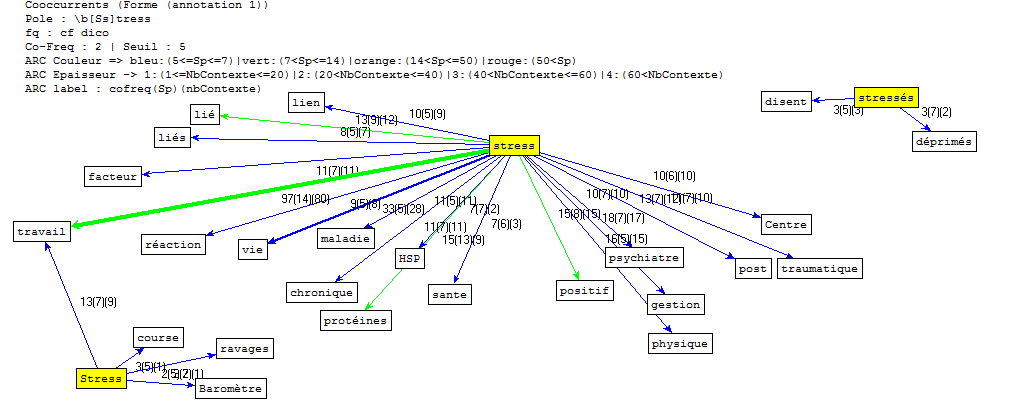
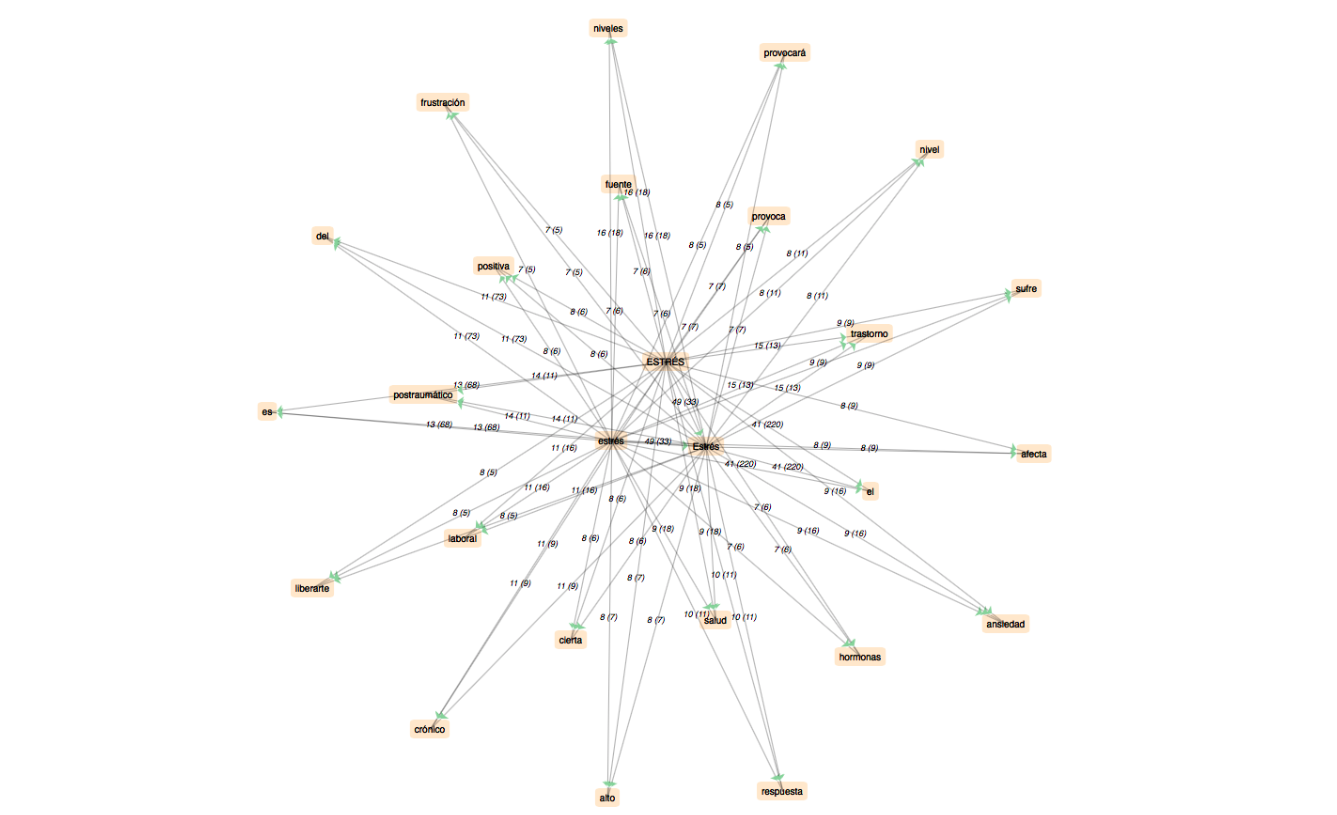
I.La présentation de Letrameur
L'essentiel du travail d'analyse est établi à l'aide du programme "Le Trameur", qui permet une approche aussi bien textométrique que lexicométrique (données quantitatives et qualitatives). Il s'articule autour des notions de "Trame" et de "Cadre", c'est-à-dire le repérage des différents niveaux hiérarchiques d'éléments dans le corpus (découpage et indexation des unités) et la représentation de l'organisation globale du corpus à travers ces niveaux. Ou encore, comme l'explique le site du Trameur :
La définition d'une Trame textométrique sur un corpus de textes permet de décrire les systèmes de zones qui correspondent aux contenants de l'analyse textométrique (parties, paragraphes, phrases, sections, chapitres, etc.). On peut rassembler les descriptions relatives aux systèmes de contenants dans une structure de données particulière, le Cadre textométrique.
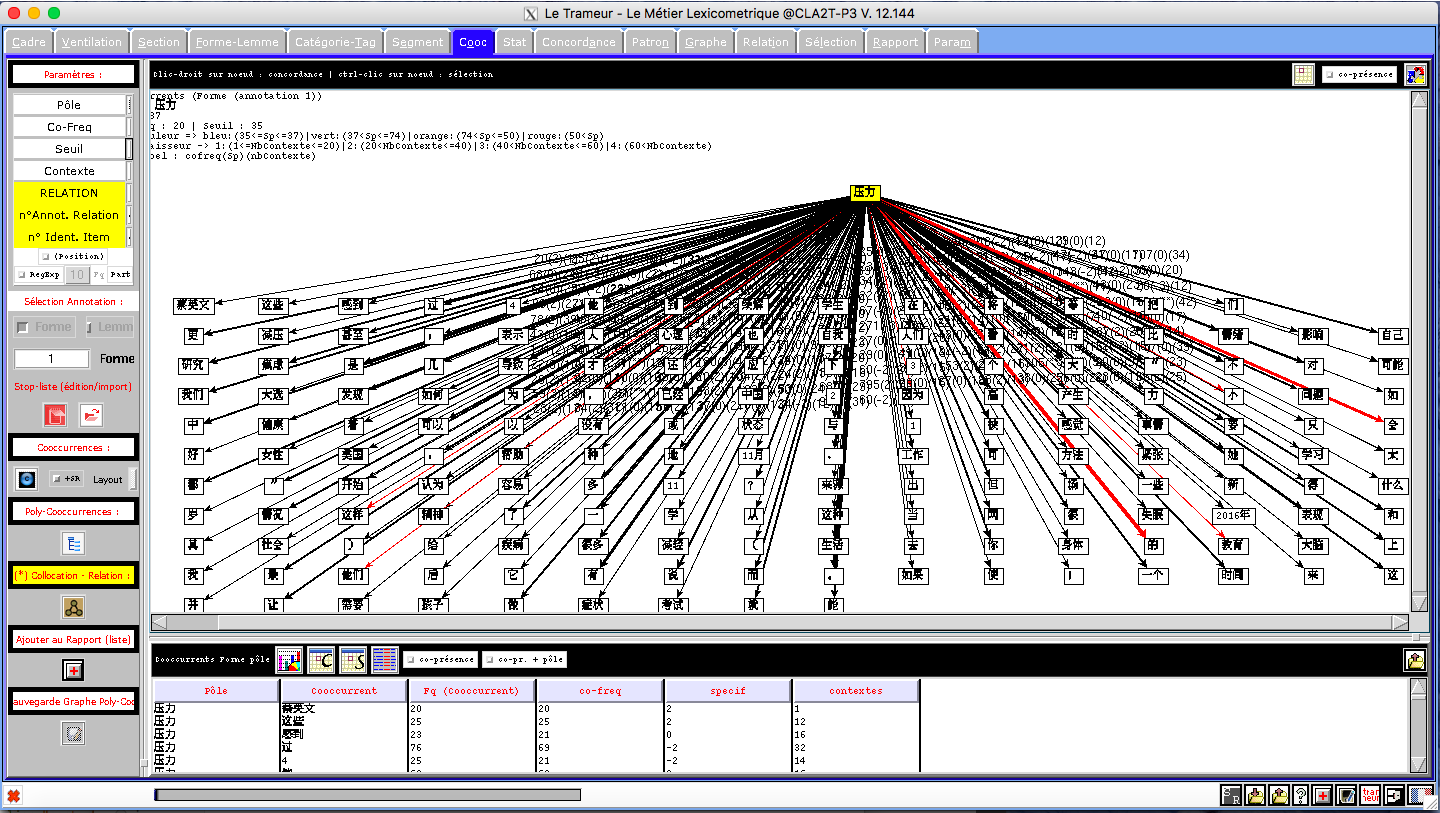
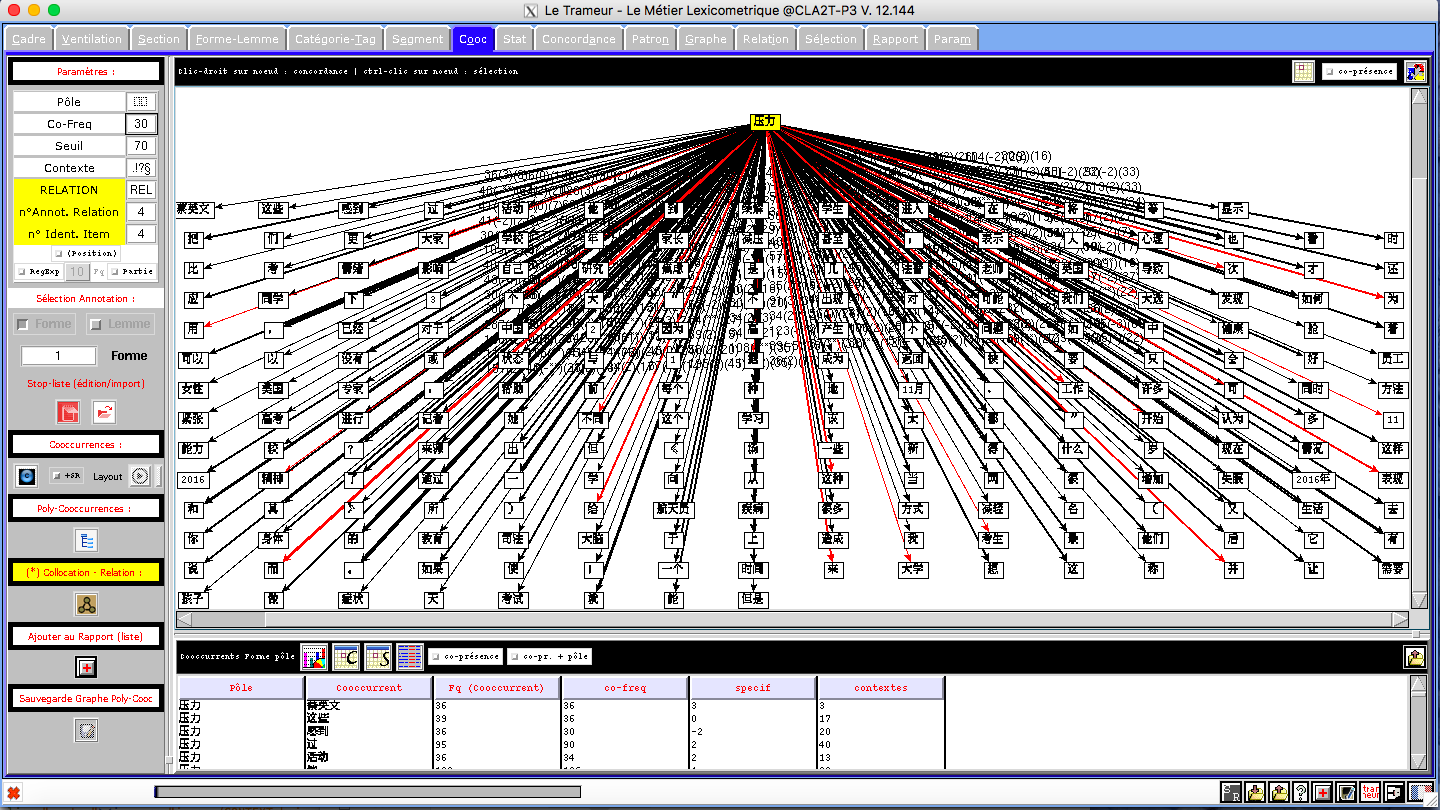
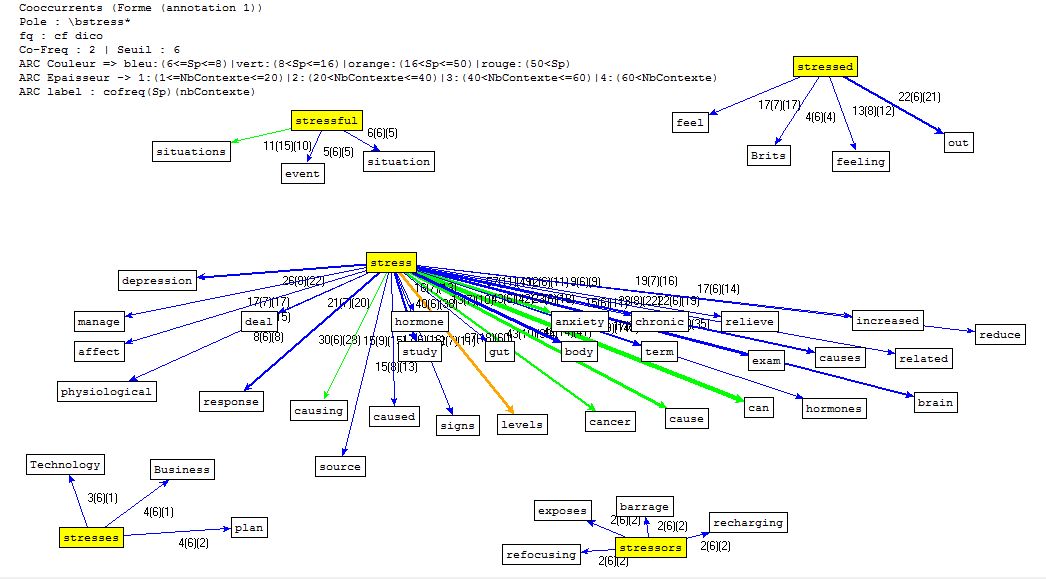
Du fait de ses très larges possibilités, le Trameur est un outil complet et complexe avec lequel il faut prendre le temps de se familiariser. Toutefois, la seule partie qui nous intéresse vraiment pour ce projet, c'est l'onglet "Cooc" qui gère les calculs des co-occurrents autour d'un "pôle" dans le corpus. Ce pôle bien sûr, ce sera notre motif et une fois définis les paramètres du calcul, on obtient la représentation des mots qui se rencontrent le plus fréquemment autour du motif (graphe de co-occurrents) ainsi qu'un tableau qui les liste.
À signaler qu'il existe également une version en ligne du Trameur, iTrameur qui regroupe certaines fonctionnalités du programme, notamment les nuages de mots et les graphes de co-occurrents.
II.Les résultats
*cliquez pour l'image originale
1). Chinois par Letrameur
a.Sinogramme simplifié(CONTEXT)
b.Sinogramme simplifié(DUMP)
c.Sinogramme traditionnel(CONTEXT)
d.Sinogramme traditionnel(DUMP)
2). Chinois par Itrameur
a.Sinogramme simplifié(CONTEXT)
b.Sinogramme simplifié(DUMP)
c.Sinogramme traditionnel(CONTEXT)
**Dans l'image, on peut voir plusieurs pôles en tant que les dérivées de "壓力(stress)", mais on sait qu'un mot chinois n'a pas de dérivation. Donc pourquoi ce résultat? En fait, ce sont de faux mots dérivées qui sont effectivement des phrases, par exemple: un pôle est 應對壓力(se faire face au stress), c'est une phrase composant de deux mots: 應對(se faire face à) et 壓力(stress). Selon moi, ce problème est peut-être de l'origine du logiciel de segmentation qui segmente ces phrases comme un mot.
d.Sinogramme traditionnel(DUMP)
3).Anglais par letrameur
a.DUMP
4).Anglais par itrameur
a.DUMP
5).Français par letrameur
a.DUMP
4).Français par itrameur
a.DUMP
4).Espagnol par itrameur
a.DUMP
Comme cela avait été prévu par nos enseignants, il ne nous aura pas été possible d'aller au bout des analyses que nous aurions voulu faire, faute de temps. Nous nous étions, il est vrai, donné des objectifs un peu ambitieux dans la méthodologie que nous avions préalablement définie. Il s'agissait initialement de croiser les résultats de quatre analyses différentes, dont deux utilisaient deux variantes des corpus (avec et sans les mots du champ lexical du stress) et les deux autres portaient sur la recherche de mots dans des constructions syntaxiques particulières. À défaut, nous nous contenterons de présenter les observations que nous pouvons déduire de la recherche des co-occurrents en comparant les données fournies par les quatres langues, c'est-à-dire le minimum de ce que l'on peut faire avec le Trameur mais aussi le cœur de ce qui est attendu du projet.
Les premières conclusions à tirer concernent en fait la phase de nettoyage. Il n'est pas superflu de rappeler l'importance de cette étape, car elle est bien sûr déterminante pour les analyses. En fonction de la composition du filtre, on peut obtenir des résultats très différents ; il faut garder en tête qu'il n'est pas toujours possible d'éliminer toutes les "scories" que l'on souhaite, car à moins de dresser une liste exhaustive - ce qui revient au même que de purger manuellement le fichier - il faut recourir à des expressions régulières qui peuvent se montrer un peu "gourmandes" et l'on se retrouve avec un filtrage trop restrictif qui va même retirer du contenu que l'on aurait souhaité conserver. C'est une question d'ajustement, en fin de compte.
Du point de vue de l'interprétation, il faut reconnaître que les résultats ne sont moins parlants qu'on aurait souhaité ; il aurait certainement été profitable de procéder à une analyse quantitative approfondie. En effet, le logiciel d'analyses, le Trameur, permet d'exporter différents formats de types de résultats. Afin de mitiger ces conclusions, il faut reconnaître que le choix de types d'URLs sélectionnées et les différences de tailles de corpus peuvent avoir une incidence sur la comparaison absolue des résultats entre eux ; nous nous estimons cependant satisfaits de constater l'aboutissement de notre travail à des données qui pour ainsi dire, parlent d'elles-même.
I. Chinois
Les sinogrammes simplifiés et sinogrammes traditionnels sont les deux ensembles de caractères standards du chinois écrit contemporain.Comme ces deux écritures sont utilisées par gens de différentes régions, j'analyse ces deux écritures séparemment en comparant l'un à l'autre.
1.Les sinogrammes simplifiés
Les sinogrammes simplifiés sont utilisés en République populaire de Chine et à Singapour. La simplification de sinogrammes commence dans les années 90s au but de faciliter leur apprentissage et à créer un alphabet phonétique à base de litres latines. La simplification des sinogrammes est définie par huit règles formulées par Qian Xuanton en 1992.
Grace à ces règles, après la simplification, les caractères chinois gardent encore leurs caractéristiques, c’est pourquoi les utilisateurs de sinogrammes simplifiés peuvent reconnaître presque tous les sinogrammes traditionnels. Ce système de l’écriture tient une place importante dans la culture chinoise, parce que malgré les nombreuses langues parlées en Chine, les sinogramme simplifié restent très compréhensible par toute la population, donc on peut dire qu'ils symbolisent l’unité national.
1.1 Sur Stress
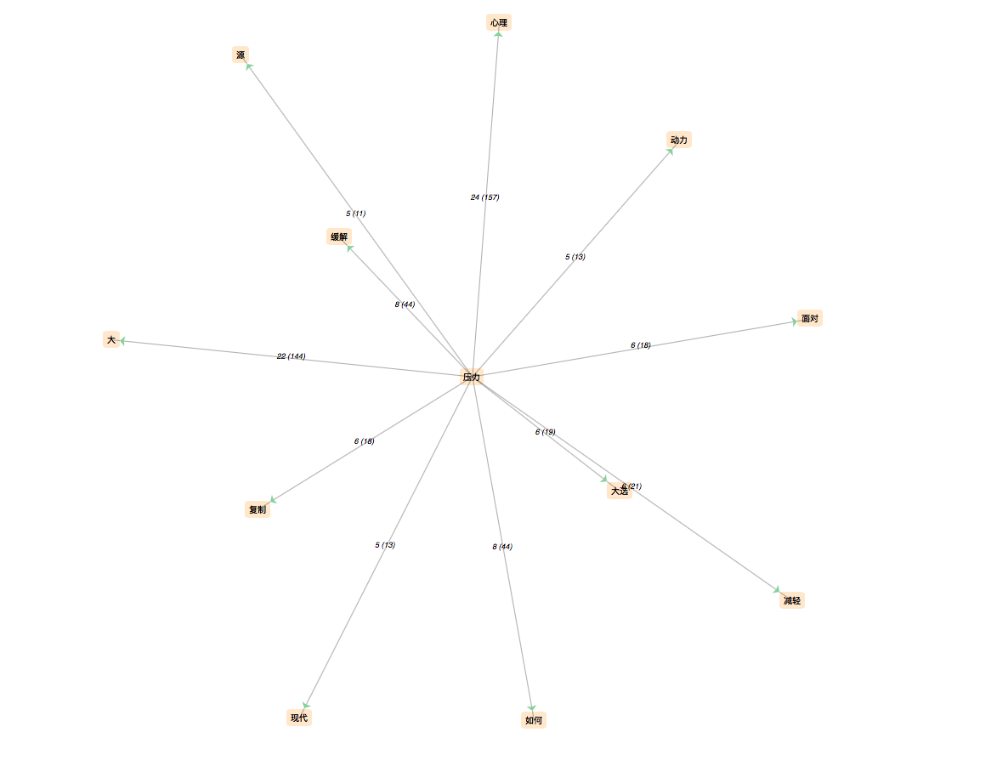
Quant au résultat à partir des fichiers contexte, les mots les plus fréquentés sont : 心理(psychologie), 影响(influence), 自己(soi-même), 导致(donduire à), 可能(possibilité), 如何(comment), 产生(produire), 问题(problème), selon ces mots, on peut découvrir que atour de mot clé, ce sont généralement des discussions sur ce problèmes:le domanie concerné est la psychologie, la discussion met l'accent sur les influences du stress, la cause du stress, et des hypothèses sur les possibilités des causes. Cepandent, on ne peut pas avoir une impression concrète sur le stress selon ce résultat :on ne sait aucun détail de discussion, mais on peut savoir que pour le stress, les chinois le prennent comme un problème psychologique personnel, et ils cherchent des faire des hypothèses pour résoudre ce problème et pour trouver les causes.
Le résultat des fichiers Dump est plus intéressant, les mots les plus fréquentés sont bien différents que ceux du résultat de Contexte: 学生(élève),学校(école), 考(试)(examen),老师(enseignant), 同学(camarades),le résultat est très pertinent: le mot stress est mentionné le plus souvent pour les élèves chinois en raison des études, dans l'image de Wordclouds, on peut observer aussi des mots assez grands lié au thème d'étude: 教育(éducation), 高三(Terminale), 分数(points). Par conséquent, j'ai deux hypothèse pour ce résultat: les élèves chinois sont les gens les plus stressés en Chine; on se soucie le plus au problème du stress des enfants, et je suis portée à la dernière, puisque selon mes connaissances de la société de Chine, la conccurrence dans le domaine de travail est bien rigoureuse, et les adults ont aussi des problèmes du tress, mais par apport aux enfants, les adults ont plus de moyens à régler ce problème. De plus,la situation des élèves en Chine est un peu spéciale, la Chine est le pays le plus peuplé, chaque année des millions d'élèves participent au bac, et juste quelques dixaines milles de gens peuvent accéder à une université au premier niveau, pour des provinces très peuplé, le taux d'accès à une bonne université peut être 5%(Renminwang). D'une part, cette situation incite les enfant à travailler dur, d'une autre part, elle apporte le problème de stress.
2.Les sinogrammes traditionnel
Les sinogrammes traditionnels sont aujourd'hui utilisés à Hong Kong, Macao, Taïwan et certaines communautés chinoises expatriées, particulièrement celles originaires des pays précédemment cités ou qui émigrèrent avant la large adoption des caractères simplifiés dans la République Populaire de Chine.Pour ces régions les sites sont presque tous en utf-8, peut-être c'est parce que au 20e sciècle, elles ont plus de concatct avec les pays étrangers que la Chine continentale. Ça facilite la collection des ressources et le procédé d'analyse. Le seul problème est le logiciel de segmentation de Standford ne fonctionne pas très bien sur les sigogrammes traditionnel.
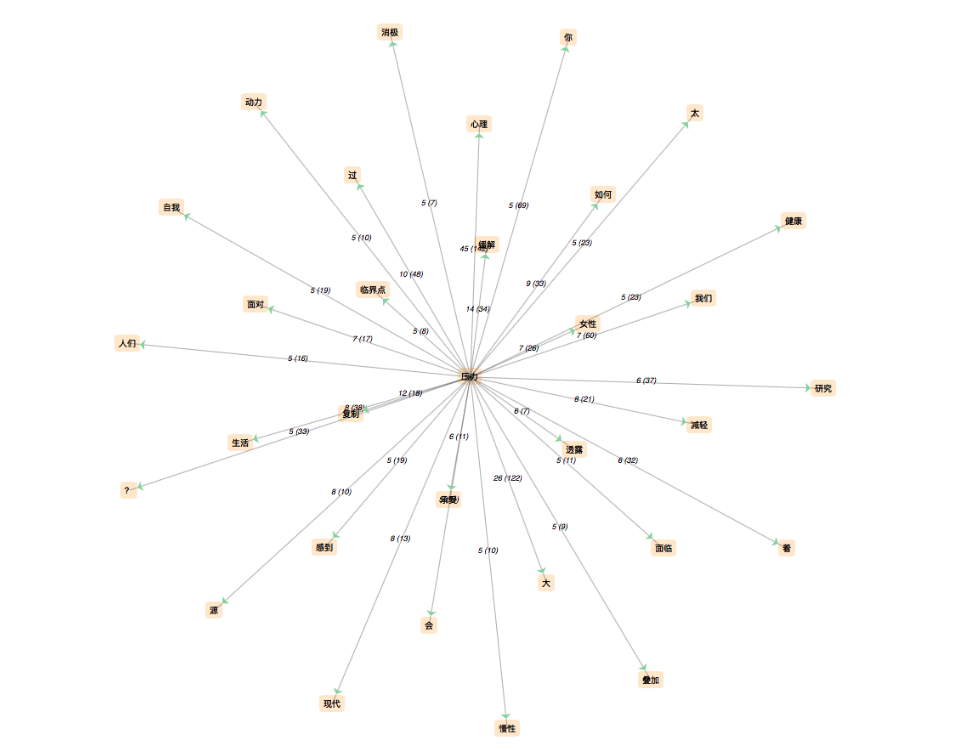
2.2 Sur stress
Dans le cas de sinogramme traditionnel, les résultats de Dump et de Contexte sont proches: le mot le plus fréquenté est "焦慮(angoisse)" qui est un entiment généralement causé par le tress, et il y a aussi des mots très fréquentés: 認為(penser), 面對(se faire face à), 研究(recherches), 健康(santé), un peu différent que dans les sinogrammes simplifiés qui traitent le stress dans le domaine de psychologie, le stress est plutôt un problème lié à la santé, et on peut aussi trouver l'occurence 患者(patient)dans le résultat, et je pense que à partir de ces occurrences, on peut observer que les gens ont une attitude positive au problème: ils choisissent se faire face au problème au lieu de le négliger, et il y a ausse des recherches sur ce problème, donc on peut savoir que les gens cherchent à comprendre ce problème ou à le résoudre. Les mots 考生(candidat à l'exament) 留學生(étudiant à l'étranger) sont aussi présentés dans la liste des occurrences les plus présentés, donc on peut savoir que les gens se concentrent plutôt aux élèves à l'étranger et à qui ont un examen, donc on peut supposer que les élèves ne sont pas généralement assez stressé que les élèves de Chine continentale parce que la société discute ce problème sur un groupe plus caractérisé.